0. Intro
이번 장에서는 Object Detection 아키텍처의 핵심 요소인 Neck과 Feature Pyramid Network(FPN)에 대해 심도 있게 살펴보겠습니다. 이 두 가지 개념은 현대 Object Detection 시스템의 성능을 크게 향상시키는 중추적인 역할을 하므로, 이들의 원리와 중요성을 명확히 이해하는 것이 매우 중요합니다
1. Neck
1.1 overview
History
🤔Neck 이 무엇이고 왜 필요한가?
Neck은 object detection 모델에서 backbone과 head 사이에 위치하는 중요한 구성 요소!!
Neck의 주요 역할과 필요성은 다음과 같습니다:
- 다양한 스케일의 특징 통합
Low-level의 feature map: 선, 점, 기울기 등의 세부 정보와 작은 객체 표현에 유리
High-level의 feature map: 객체의 의미론적(semantic) 정보와 큰 객체 표현에 유리
Neck을 통해 이 두 가지 정보를 모두 활용하여 다양한 크기의 객체 탐지 성능 향상 - 정보 손실 방지
Backbone의 마지막 feature map만 사용하면 중간 단계의 정보가 손실됨
Neck을 통해 중간 단계의 feature map도 활용하여 정보 손실 최소화 - 특징 재구성 및 강화
하위 level의 feature는 semantic 정보가 약하므로 상위 feature와의 정보 교환 필요
Top-down, bottom-up 경로를 통해 다양한 level의 feature를 재구성하고 강화 - 스케일 불변성 향상
다양한 스케일의 feature를 통합하여 객체 크기 변화에 강인한 탐지 가능 - 모델 성능 향상
Feature의 재구성과 통합을 통해 전반적인 object detection 성능 향상
👉따라서 Neck은 backbone에서 추출한 다양한 level의 feature를 효과적으로 통합하고 재구성하여 head에서 더 나은 객체 탐지를 수행할 수 있도록 돕는 중요한 역할을 합니다.
High level의 feature map

Low level 의 feature map

👉 High level 과 low level 의 feature map의 조화를 통해, 다양한 크기의 객체를 더 잘 탐지한다.
기존의 ObjectDetection 의 문제점은 작은 객체를 어떻게 잘 포착할 것인가? 하는 문제가 있었는데, Neck 을 통해 작은객체도 잘 잡을 수 있게 되는 것
🤔 그냥 backbone의 feature를 neck에 통과시키지 말고 바로 RPN으로 가면 되는거 아닌가?
👉 그러면 정보의 양과 질이 부족해진다.
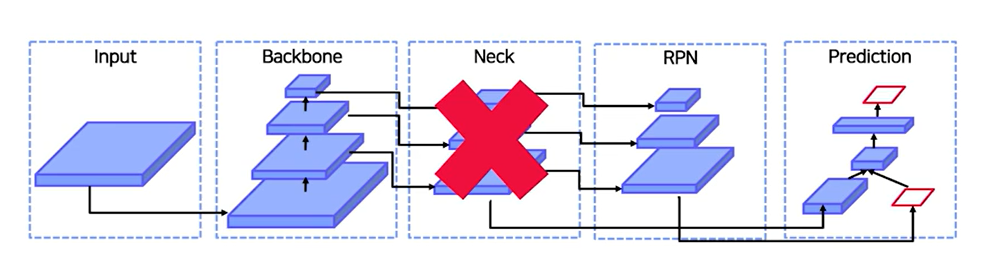
low level 에는 semantic 정보가 부족한데, high level에서는 localization 정보가 부족한 편이다. 따라서 high level 에서는 semantic정보를 low level 로 전달, low level 에서는 localization 정보를 high level 로 전달 -> 이렇게 함으로써, 정보를 풍부하게 만들어주는 것임.
-> 하위 level의 feature 는 semantic 이 약하므로 상대적으로 semantic이 강한 상위 feature 와의 교환이 필요.
1.2 FPN(Feature Pyramid Network)
FPN도 대체로 4가지 종류가 있다.
① Featurized image pyramid
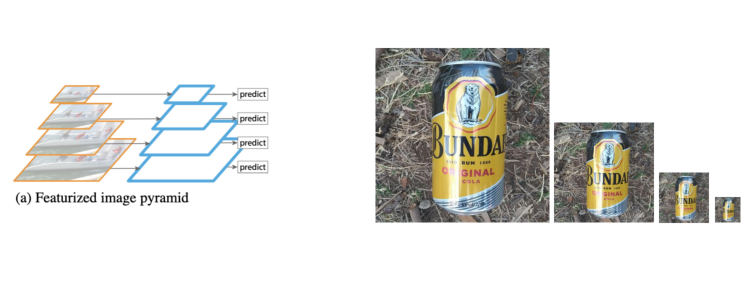
이미지 자체의 사이즈를 조절하여 feature 를 뽑아내는 경우.
② Single feature map

마지막 feature map으로 prediction 을 하자는 예
③ Pyramid feature hierarchy
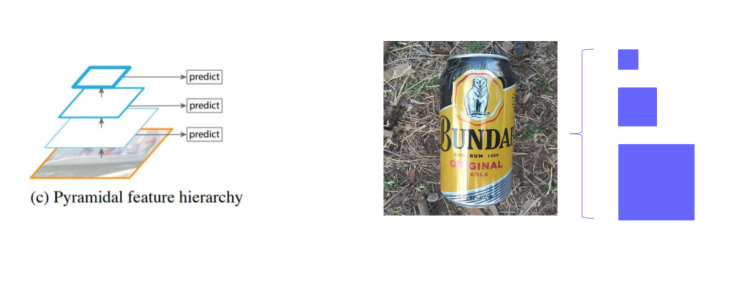
중간중간의 feature map을 활용을 하자는 것.(뒤에 배울 SSD모델에서 사용할 방법)
④ Feature Pytramid Network
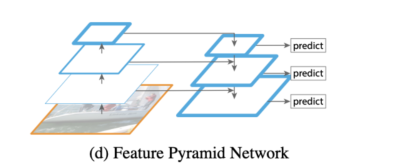
high levle 에서 low level 로 semantic 정보 전달필요 -> 따라서 top-down path way 추가.
-> Pyramid 구조를 통해서 high level 정보를 low level 에 순차적으로 전달.
- Low level = Early stage = Bottom
- high level = Late stage = Top
Bottom-up
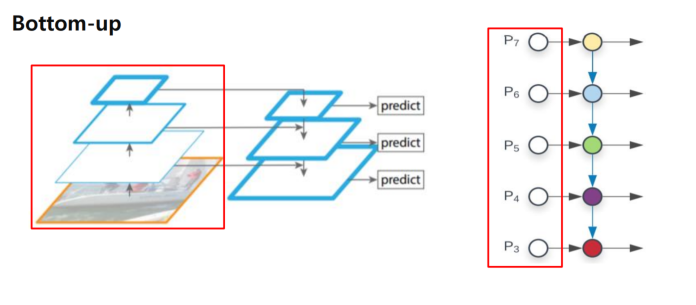
Top-down
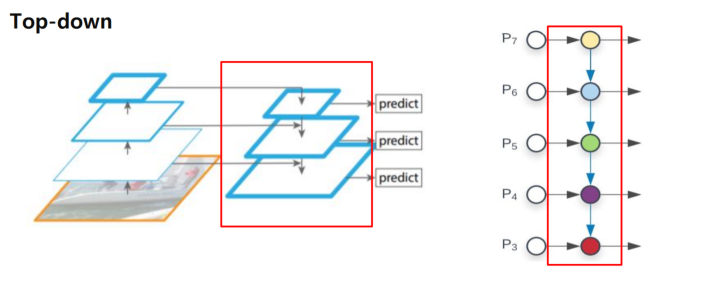
🤔 Bottom-up 과 Top-down을 섞어줘야 하는데 어떻게 하면 섞어줄 수 있을까?
👉 그 방법이 바로 Lateral Connections!
Lateral connections
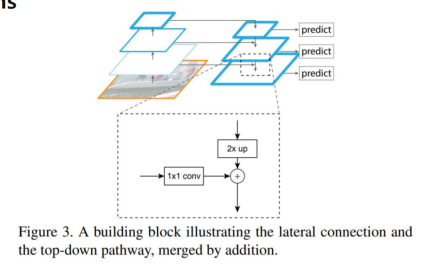
Top-down 에서 나오는 거는 1x1 conv 를 진행하고, Botton-up 에서는 2x up을 진행한다.
예시를 들어보자
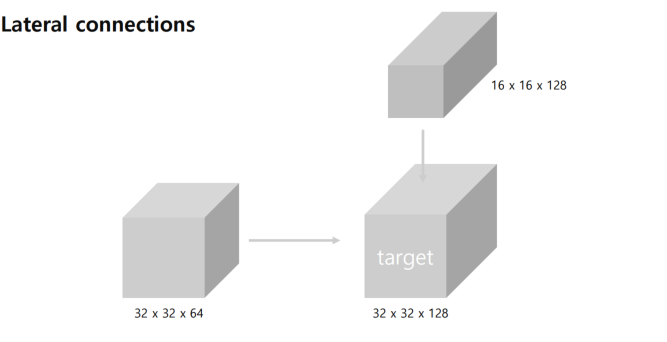
왼편은, Bottom-up 에서 나온 feature map 으로 32x32x64 -> channel 이 부족
위편은, Top-down 에서 나온 feature map 으로 16x16x128 -> size가 부족.
그래서 Bottom-up에서 나온 것은 1x1 conv로 채널만 늘릴 수 있다.
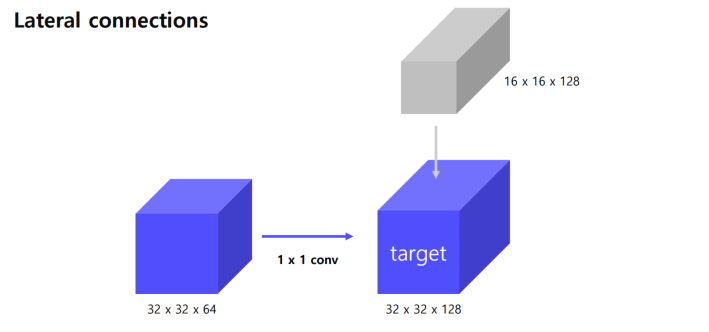
반면에 top-down 은 upsampling을 진행을 해서
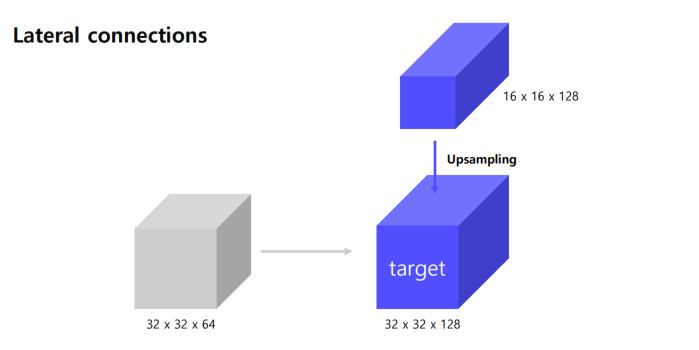
32x32 shape을 맞춰줌.
🤔 upsampling 을 어떻게 한다는 것일까?
👉 최근접 이웃 upsampling을 한다.
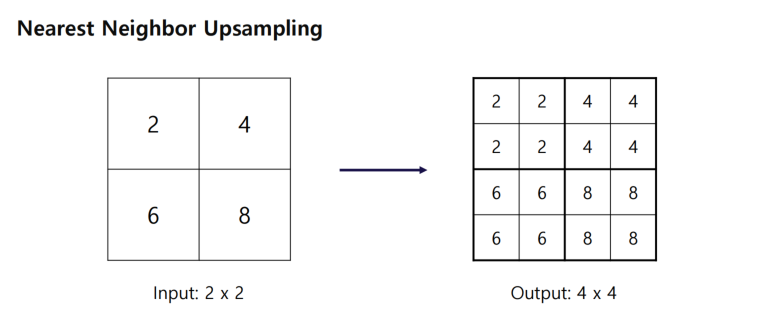
같은 이웃끼리를 세포증식하듯이 증식시켜놓았다.
Pipeline
BackBone
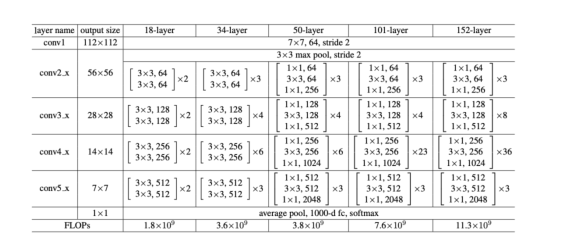
이 이미지는 FPN에서 ResNet을 어떻게 BackBone 으로 활용되는지 설명. 4개의 stage 가 존재한다.
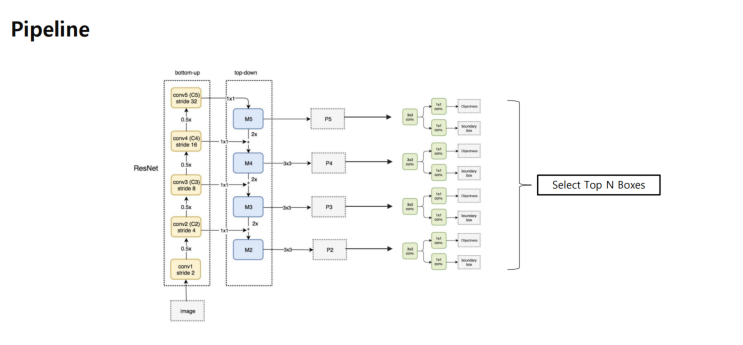
이미지를 각 stage 마다 뽑아냈고,Feature Pytramid Network 방식으로 뽑아냈다.여러개의 RoI 에서 nms를 적용해서 1,000개의 RoI 를 선택.
그런데 RoI가 어느 stage 에서 왔는지 mapping 하는 과정이 필요한데,이는
공식으로 선택.
- : RoI가 할당될 피라미드 레벨
- : 기준 레벨로, 일반적으로 4로 설정
- : 각각 RoI의 너비와 높이
- 224 : ImageNet 사전 학습에 사용되는 표준 이미지 크기
👉즉, 스케일을 조정(해서 RoI 크기를 단일 값으로 나타내고 -> 224 로 나누어서 Imagenet 표준크기와 비교 -> 후에 로그스케일을 하여 선형적으로 변환 -> 마지막으로, 하여 기본피라미드 레벨을 설정.
성능
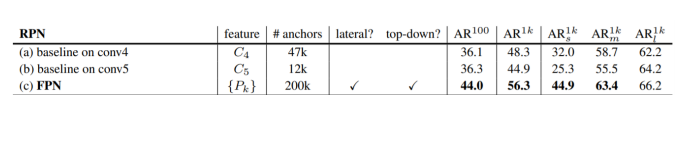
모든 부분에서 FPN의 성능이 우수함을 볼 수 있다.
Code
① Build laterals : 각 feature map 마다 다른 채널을 맞춰주는 단계
laterals = [lateral_conv(input[i]) for i, lateral_conv in enumerate(self.lateral_convs)]② Build Top-Down : channel 을 맞춘 후 top-down 형식으로 feature map 교환
for i in range(3,0,-1): #피라미드 상위 레벨로부터 하위 레벨로 내려가는 과정
prev_shape = laterals[i-1].shape[2:] # 이전 레벨 크기 저장(단 shape[2:]로 높이와 너비만)
laterals[i-1] += F.interpolate(laterals[i],size = prev_shape) #현재 레벨의 특징 맵을 이전 레벨의 크기로 보간(interpoliation)함.③ Build outputs : 최종 3x3 convolution을 통과하여 RPN으로 들어갈 feature 완성
outs = [self.fpn_convs[i](laterals[i]) for i in range(4)]1.3 Path Aggregation Network (PANet)
1.3.1 FPN 이 가지는 문제점.
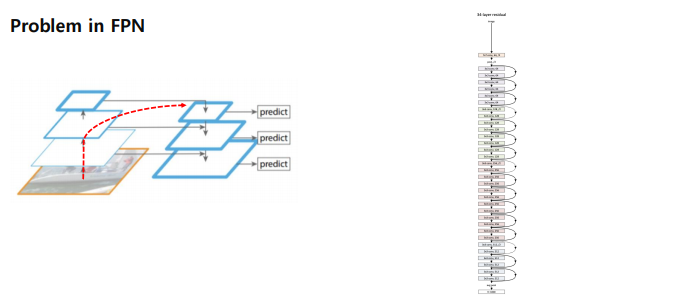
왼쪽편 stage로 보면 매우 짧아보이는데, 오른편 실제 backbone을 보면 매우 길다. 따라서 bottom-up 하는 과정에 있어서 low level 에 있는게 제대로 전달이 될 수 있는가? 하는 문제가 발생한다.
1.3.2 극복방안
① Bottom-up Path Augmenation(bottom-up에서 하나 더 추가)
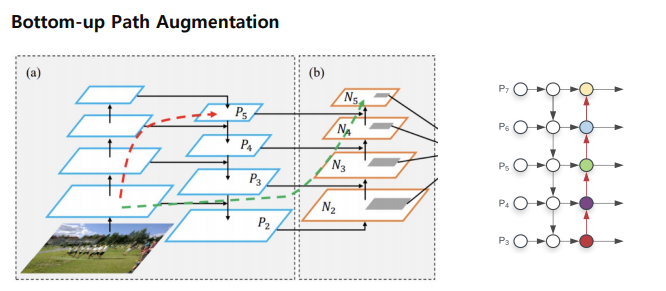
맨 처음에 bottom-up을 하는데 top-down을 하고 만든 4개의 feature map에 한해서, 다시 정보를 전달하는 것. low level 에 있는 정보를 다시 한 번 더 high level 에 전달해주자는게 여기 핵심.
② Adaptive Feature Pooling(다양한 크기의 입력 이미지나 객체에 대해 효과적으로 특징을 추출하는 방법)
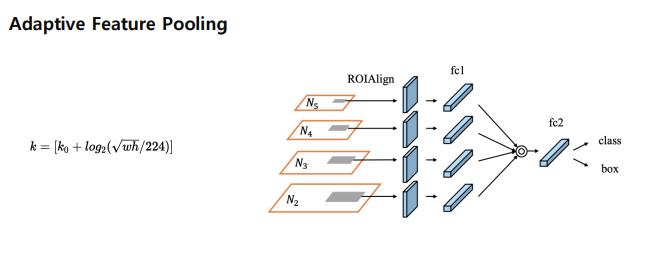
모든 feature map 으로부터 RoI_projection 을 하자. FPN에서는 RoI의 stage를 하나만 정해서 사용했는데, 그러기엔 나머지 stage를 버리기엔 아깝다. 나머지도 뽑아내자가 Adaptive feature pooling
- ROIAlign: 입력 이미지에서 관심 영역(ROI)을 정렬하고, 해당 영역을 고정된 크기의 피처 맵으로 변환합니다. 이는 ROI의 크기에 따라 적절한 레벨의 피처 맵을 선택하여 정확한 위치 정보를 유지한다.
Code
① Add bottom-up
for i in range(3):
inter_outs[i+1] += self.downsample_convs[i](inter_outs[i])② Build outputs : FPN과 마찬가지로 학습을 위해 3x3 convolutional layer 통과
outs = []
outs.append(inter_outs[0])
outs.extend([
self.pafpn_convs[i-1](inter_outs[i]) for i in range(1,4)
])2. After FPN
여기서는 4가지의 FPN모델에 대해서 알아본다.
2.1 DetectoRS
논문 : https://arxiv.org/abs/2006.02334
2.1.1 Motivation
RoI 풀링을 여러번 하고, 반복적으로 무언가를 하면 좋은 성능이 나오나? 에서 motivation 을 얻었다고 합니다.
2.1.2 주요 구성
Recursive Feature Pyramid(RFP)
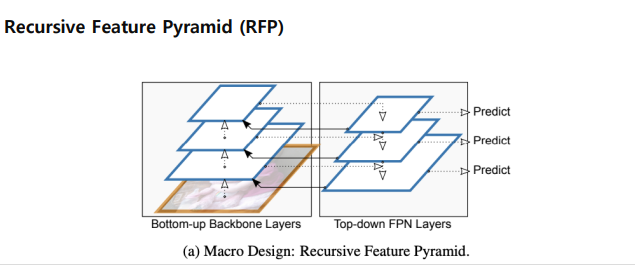
FPN을 말 그대로 Recursive 하게 진행.
그림을 자세하게 보면, Top-down FPN으로부터 bottom-up backbone layer 로 다시 한번 더 진행.
feature pyramid 를 반복하긴 반복하는데, 맥만 반복하는게 아니라, 맥정보를 다시 backbone에 전달하여 backbone 도 맥정보를 이용해서 다시 한번 학습하게끔 한다.
-> 백본을 건드리기때문에, 학습하는 속도가 정말 많이 느리다.
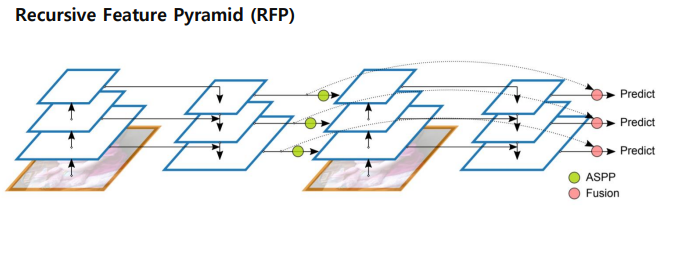
- : 단계 에서의 출력 피처 맵
- : 단계 에서의 FPN 연산을 나타내며, 상위 레벨 피처 맵 와 현재 레벨의 입력 를 결합
- :단계 에서의 입력 피처 맵으로, 이전 단계의 출력 을 바탕으로 백본 네트워크를 형성.
ASPP(Atrous Spatial Pyramid Pooling)
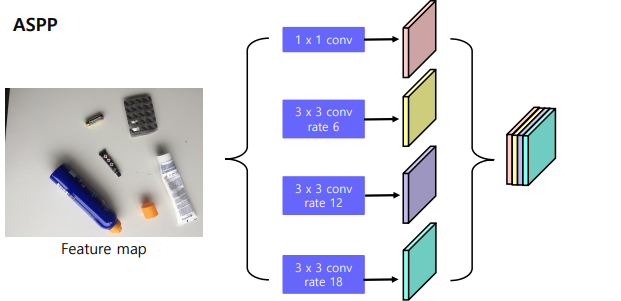
FPN의 정보를 백본에 넘겨줄때 단순하게 넘기는 것이 아니라 ASPP 라는 방법을 사용.
-> receptive field 를 늘릴 수 있는 방법.
자세히 살펴보면,
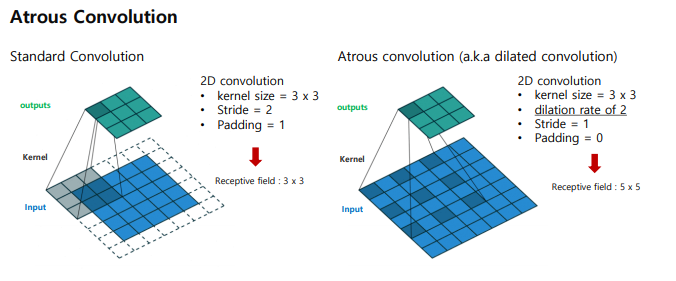
원래(standard convolution)은 receptive field 가 3x3 이라면, Atrous convolution은 5x5 로 기존에 비해서 늘어났다. output은 3x3으로 똑같을지라도 보는 범위가 늘어났다.
(참고로 astrous 는 '새까만' 의미로 적은게 아니라, 프랑스어 "à trous"에서 유래되었으며 이는 '구멍이 있는'이라는 뜻이다. 이 기법은 필터가 입력 신호를 샘플링할 때 일정한 간격을 두고 샘플링하여 더 넓은 문맥 정보를 얻을 수 있게 한다.)
정리하면, 하나의 feature map에서 pooling 을 진행하긴 진행하는데, rate를 여러가지로 두어서 receptive field 를 키워나가면서 pooling을 진행하고 마지막에 concat을 해서 진행하는것.
결국 ASPP를 하는 이유는, Receptive field 를 키워나가기 위함이다.
2.2 Bi-directional Feature Pyramid (BiFPN)
논문 : https://arxiv.org/abs/1911.09070v7

효율성을 위해서 feature map이 한 곳에서만 오는 feature map 노드들을 없앰.
그래서
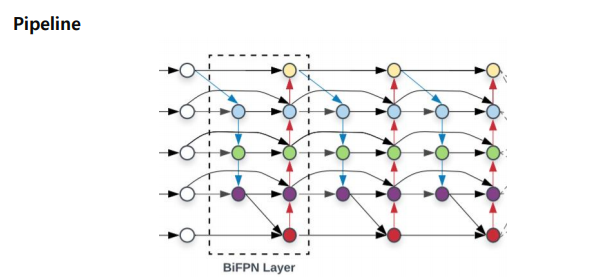
이렇게 반복적으로 쌓을 수 있음.
Weighted Feature Fusion
- FPN과 같이 단순 summation 을 하는 것이 아니라, 각 feature 별로 가중치를 부여한 뒤 summation.
- feature별 가중치를 통해 중요한 feature 를 강조하여 성능 상승.

그림을 자세히 살펴보면, 단순합을 하는 것이 아니라 가중치를 두어서 를 구함을 알 수 있다.
weightd를 학습가능한 매개변수로 두어서 함.
2.3 NASFPN
논문 : https://arxiv.org/abs/1904.07392
2.3.1 motivation
기존의 FPN,PANet은 일방향 pathway summation 인데 이보다 더 좋은 방법이 없을지? 에서 출발한다. -> FPN 구조를 NAS(Neural architecture search)를 통해서 찾자! 라는 마음.
2.3.2 모델구조
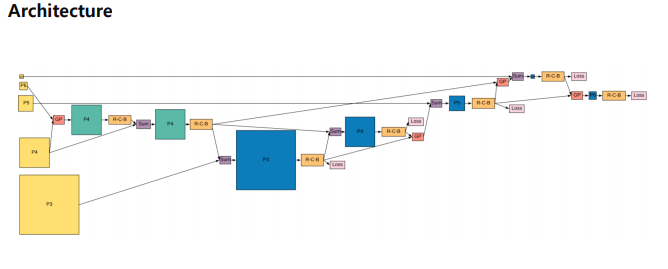
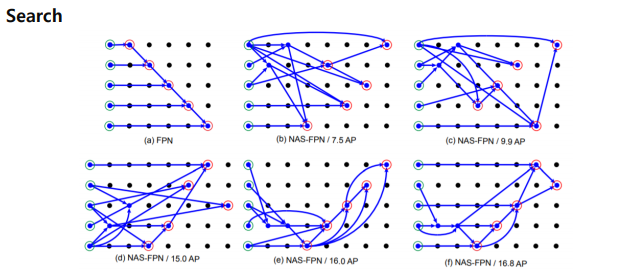
신경네트워크를 썼을때, 어떻게 다른지 알려준다.
2.3.3 성능
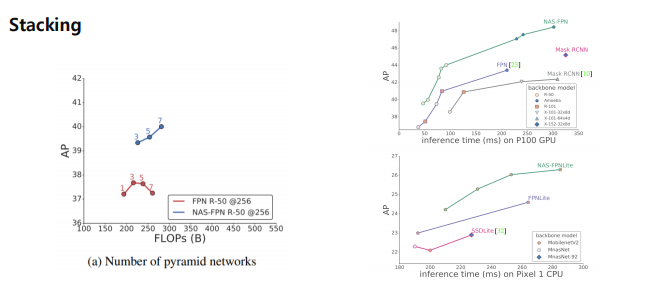
성능이 기존의 FPN 보다 좋다.
2.3.4 한계점
-
CO dataset, ResNet 기준으로 찾은 architecture 이므로 범용적이지 못함.
-
High search Cost:
다른 dataset 이나 backbone에서 가장 좋은 성능을 내는 architecture를 찾기 위해 새로운 search cost 가 발생함.
2.4 AugFPN
논문 : https://arxiv.org/abs/1912.05384
2.4.1 motivation
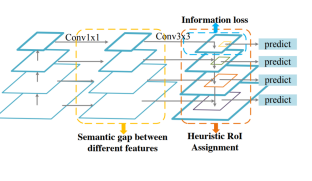
FPN이 가지는 문제점은
- 서로 다른 level의 feature 간의 semantic 차이
- highest feature map 의 정보손실
- 1개의 feature map 에서 RoI 생성
2.4.2 주요 구성
Residual Feature Augmentation
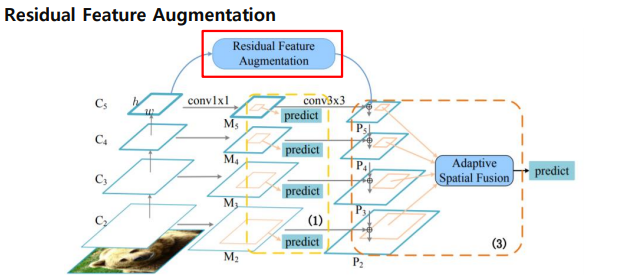
마지막 stage P5같은 경우에는 기존채널이 줄어들어서 information loss 이슈가 있음. 이를 보완해줄 방법이 있어야 하는데 이를 Residual Feature Augmentation을 통해서 보완.
m6 를 만들어주고 P에 top-down 정보를 추가하게 함.
어떻게 m6 를 만드는가??
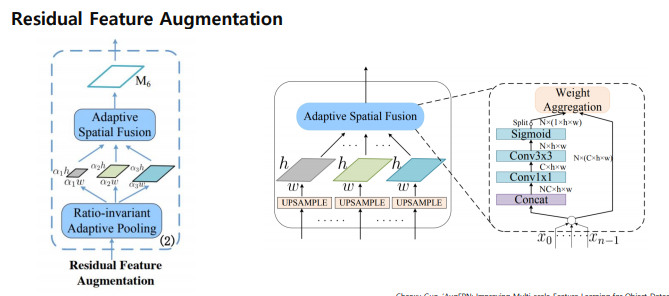
동일한 size 로 upsampling -> N개의 feature 에 대해 가중치를 두고 summation -> 3개의 feature map을 Concat 하고 Nx(1xhxw)의 값을 구함 , 이때 Nx(1xhxw)는 spatial weight를 의미
-> Nx(1xhxw)를 각 N개의 feature 에 곱해 가중 summation
Soft RoI Selection

stage mapping 없이 모든 feature map으로부터 RoI projection 을 실행함.
PANet에서 모든 feature map을 이용했지만, max pool 하여 정보손실 가능성은 여전히 존재 -> 이걸 해결하기 위해서 Soft RoI selection
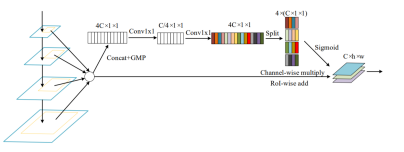
모든 scale의 feature에서 RoI Projection 진행 후 RoI pooling -> Channel-wise 가중치 계산 후 가중합을 사용 -> PANet의 max pooling을 학습가능한 가중 합으로 대체
4C 채널만 맞춰주고
즉, AugFPN의 핵심 알고리즘은 feature map은 간단하게 max pooling 은 정보손실 발생-> 단순 summation하는것은 말이 안되고 가중합을 해야하는데 가중치를 뽑아내는 과정이 Soft RoI selection
3. 참고자료
1) Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao, “YOLOv4: Optimal Speed and Accuracy of Object Detection”
2) Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie, “Feature Pyramid Networks for Object
Detection”
3) Mingxing Tan, Ruoming Pang, Quoc V. Le, ‘EfficientDet: Scalable and Efficient Object Detection”
4) 갈아먹는 Object Detection, [7] Feature Pyramid Network
5) Siyuan Qiao, Liang-Chieh Chen, Alan Yuille, ‘DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous
Convolution’
6) Golnaz Ghaisi, Tsung-Yi Lin, Ruoming Pang, Quoc V. Le, ‘NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object
Detection”
7) Chaoxu Guo, ‘AugFPN: Improving Multi-scale Feature Learning for Object Detection”
8) Jonathan Hui, Understanding Feature Pyramid Networks for object detection (FPN
- Feature Pyramid Networks for Object Detection
https://arxiv.org/abs/1612.03144 - Path Aggregation Network for Instance Segmentation
https://arxiv.org/abs/1803.01534 - DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution
https://arxiv.org/abs/2006.02334 - EfficientDet: Scalable and Efficient Object Detection
https://arxiv.org/abs/1911.09070v7 - NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
https://arxiv.org/abs/1904.07392 - AugFPN: Improving Multi-scale Feature Learning for Object Detection
https://arxiv.org/abs/1912.05384
