0. Intro
그전까지 2 Stage Detectors는, ① 객체가 있을 법한 후보 영역을 찾고 -> ② 그 object 가 무엇인지 classification 하는 2가지 단계를 거쳤다.
이제 1 Stage Detector 에서는 이러한 과정없이 한 번에 통과할 수 있도록 해본다.
1. 1 stage Detectors
1.1 BackGround
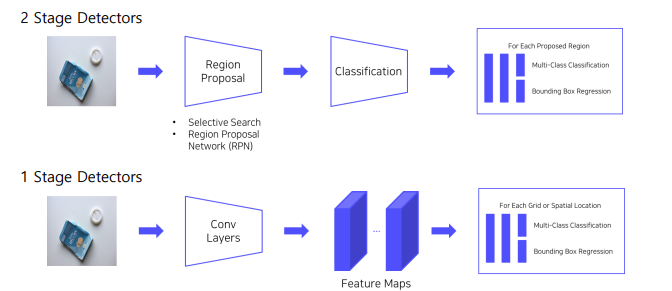
2 stage Detectors
- RCNN,FastRCNN, SPPNet, FasterRCNN
-> 모두 localization 후 Classification
👉 따라서 속도가 매우 느림. real time 에 부합하지 않음.
1 stage Detectors
-
Localiztion, Classification 이 동시에 진행
-
전체 이미지에 대해 특징 추출, 객체 검출이 이루어짐 → 간단하고 쉬운 디자인
-
영역을 추출하지 않고 전체 이미지를 보기 때문에 객체에 대한 맥락적 이해가 높음
👉 따라서 속도가 real time 에 부합(Real time detection)
1.2 History
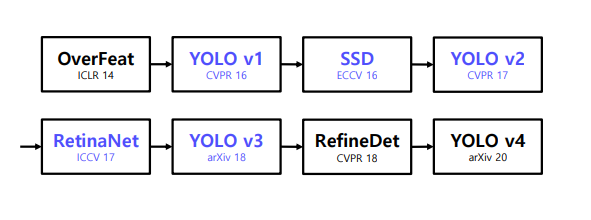
1 Stage detector 로 YOLOv1 이 나왔고 -> 그리드 작은거 탐지 및 정확도 향상을 위해 SSD 출범 -> 더 빠르고 정확한 모델을 위해 YOLOv2 ->
2. YOLO v1
You Only Look Once
논문 Yolo survey : https://arxiv.org/abs/2304.00501
2.1 Overview
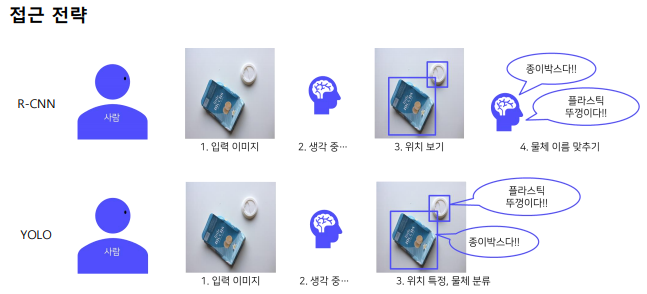
Yolo는 Region Proposal 단계가 아예 없다.
👉 전체 이미지에서 bounding box 예측과 클래스를 예측하는 일을 동시에 진행
- 이미지,물체를 전체적으로 관찰하여 추론
2.2 Pipeline
Network
GoogLeNet의 변형
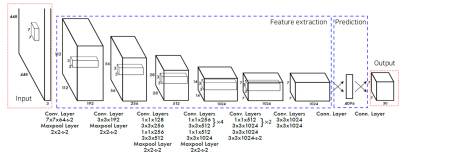
- 24개의 Convolution layer ->특징 추출
- 2개의 Fully Connected layer -> box 좌표값 및 확률 계산
순서
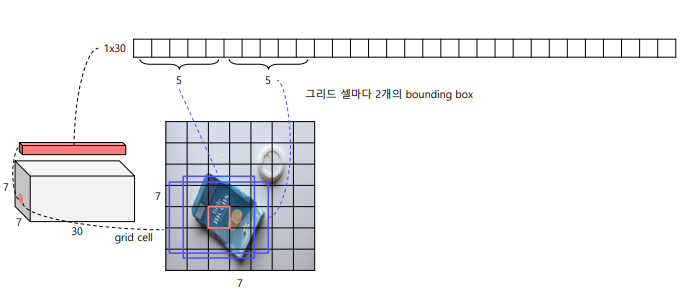
① 입력 이미지를 S x S 그리드 영역으로 나누기(여기서는 S =7)
② 각 그리드 영역마다 B개의 Bounding box 과 Confidence score 계산(B =2)
- 신뢰도(confidence) =
③ 각 그리드 영역마다 C개의 class 에 대한 해당 클래스일 확률 계산
Conditional class probability =
자세한 pipeline
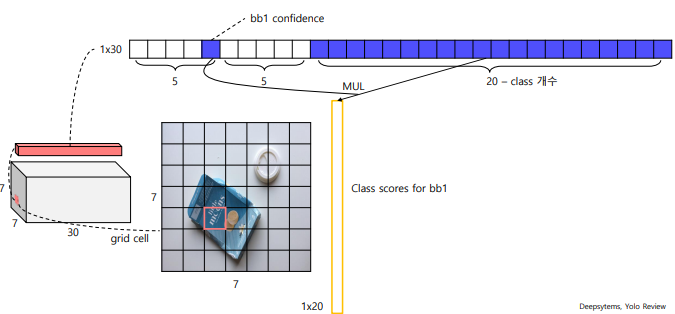
하나의 그리드는 채널이 30개를 가지고 있다.
🤔 왜 30개일까요?
👉 bounding box갯수와 class 갯수의 정보를 담고 있다.
처음 5,5개는
1. x - 그리드 셀 중심 x좌표
2. y - 그리드 셀 중심 y좌표
3. w - Bbox 너비
4. h - Bbox 높이
5. c – Bbox confidence score
이렇게 2개씩 해서 10개를 담고 있고(즉, 그리드 셀마다 2개의 bounding box)
나머지 20개에는 class 갯수
첫 번째 bounding box의 confidence가, 첫번째 class일 확률,.. ,20번째 클래스일 확률. 이렇게 나오게 된다.
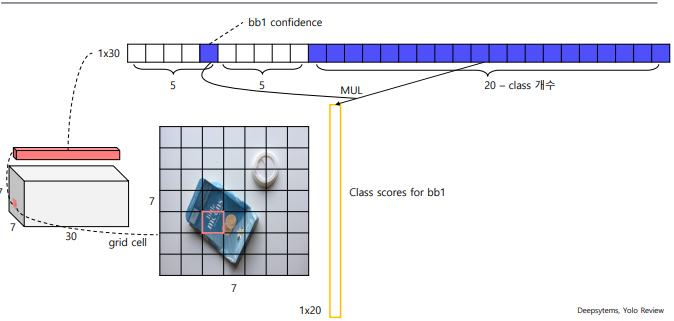
마찬가지로 2번째 bounding box의 confidence 가 1,...,n 번째 클래스일 확률 이렇게 계산할 수 있게 된다.

이렇게 모든 그리드에 대해서 inference 를 수행하게 되면
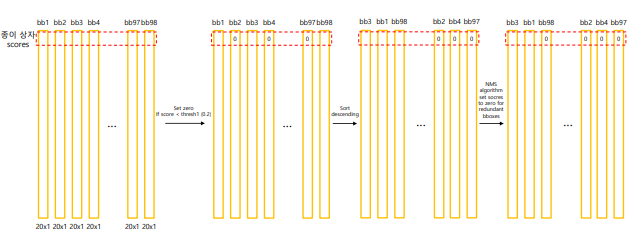
total 7 x 7 x 2 =98 개의 bboxes 가 생기게 된다.
바운딩 박스 선택과정
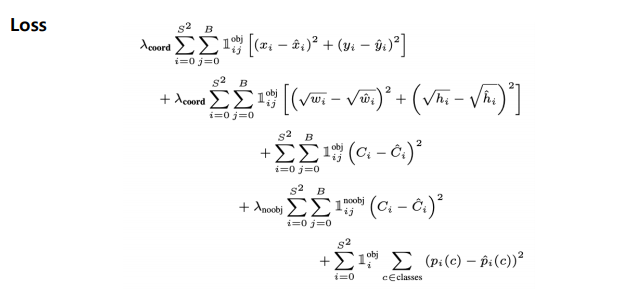
① 바운딩 박스 예측:
각 그리드 셀은 여러 개의 바운딩 박스를 예측합니다. 이때, 각 바운딩 박스는 객체의 위치와 크기, 그리고 신뢰도 점수를 포함합니다.임계값(threshold)이 넘는 것만 살려줌
② 점수 기반 정렬(sort descending):
예측된 바운딩 박스들은 신뢰도 점수에 따라 정렬됩니다. 높은 점수를 가지는 바운딩 박스가 우선적으로 고려됩니다.
③ 비최대 억제(NMS) 적용:
중복된 탐지를 제거하기 위해 NMS 알고리즘이 적용됩니다. 이는 겹치는 바운딩 박스 중에서 가장 높은 신뢰도를 가진 하나만 남기고 나머지를 제거하는 과정입니다.
YOLO Loss
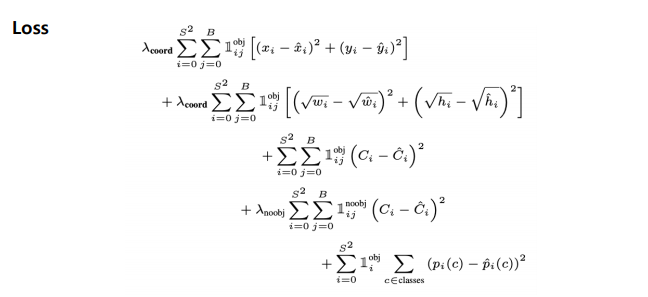
Loss 가 상당히 복잡하게 되어 있는거 같은데, 이를 분해해서 Localization loss + Confidence loss + Classification loss 로 나누어서 보면 쉽게 이해할 수 있다.
YOLO (You Only Look Once) 손실 함수는 세 가지 주요 구성 요소로 이루어져 있습니다:
① Localization Loss
Localization loss는 예측된 경계 상자(bounding box)의 위치와 크기의 정확도를 측정합니다.

- : localization loss의 가중치를 조절하는 하이퍼파라미터
- : 경계 상자 중심점의 실제 좌표
- : 경계 상자 중심점의 예측 좌표
- : 경계 상자의 실제 너비와 높이
- : 경계 상자의 예측 너비와 높이
② Confidence Loss
Confidence loss는 객체의 존재 여부와 예측의 정확도를 평가합니다.

- : 실제 confidence 점수
- : 예측된 confidence 점수
- : 객체가 없는 경우의 confidence loss 가중치
③ Classification Loss
Classification loss는 객체의 클래스 예측 정확도를 측정합니다.
- : 클래스 c에 대한 실제 확률
- : 클래스 c에 대한 예측 확률
전체 YOLO 손실 함수
YOLO의 전체 손실 함수는 위의 세 가지 손실을 결합하여 다음과 같이 표현됩니다:
이 손실 함수는 객체 탐지의 여러 측면(위치, 존재 여부, 클래스)을 동시에 최적화하여 YOLO 모델의 성능을 향상시킵니다.
2.3 Results
- Faster R-CNN에 비해 6배 빠름.
- 이미지 전체를 보기 때문에 클래스와 사진에 대한 맥락적 정보를 담고 있다.
- 물체의 일반화된 표현 학습.
-> 사용된 dataset 이외의 도메인에 대한 이미지에 대한 좋은 성능을 보인다.
3. SSD(Single Shot Detector)
논문 : https://arxiv.org/abs/1512.02325
3.1 Overview
YOLO의 단점
-
7 x 7 그리드 영역으로 나눠 Bounding box prediction 진행 -> 따라서 그리드보다 작은 크기의 물체 검출 불가능.
-
신경망 통과하여 마지막 feature 만 사용 -> 정확도 하락.
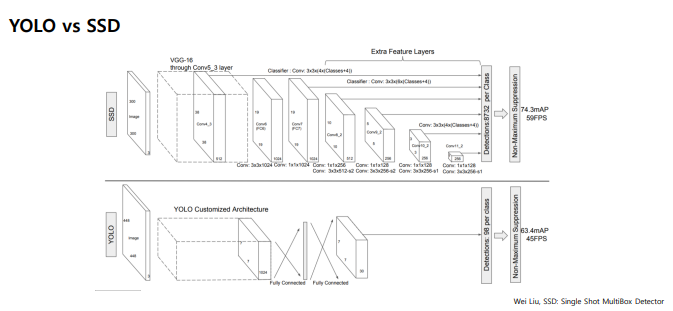
YOLO vs SSD
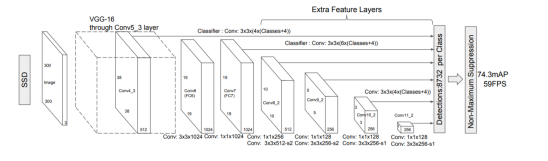
| 특성 | YOLO | SSD |
|---|---|---|
| 아키텍처 | 단순, 맞춤형 | VGG-16 기반, 복잡함 |
| 속도 | 45 FPS | 59 FPS |
| mAP | 63.4 | 74.3 |
| 특징 | 전체 이미지 컨텍스트 사용 | 멀티 스케일 특징 맵 사용 |
| 객체 크기 처리 | 제한적 | 다양한 크기 처리 가능 |
SSD 특징
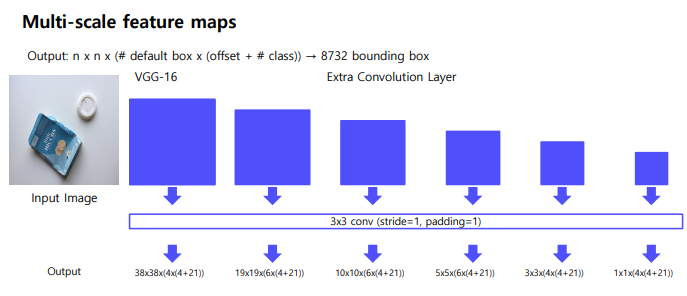
- Extra convolution layers에 나온 feature map들 모두 detection 수행
-- 6개의 서로 다른 scale의 feature map 사용
-- 큰 feature map (early stage feature map)에서는 작은 물체 탐지
-- 작은 feature map (late stage feature map)에서는 큰 물체 탐지 - Fully connected layer 대신 convolution layer 사용하여 속도 향상
- Default box 사용 (anchor box)
서로 다른 scale과 비율을 가진 미리 계산된 box 사용
3.2 Pipeline
Network
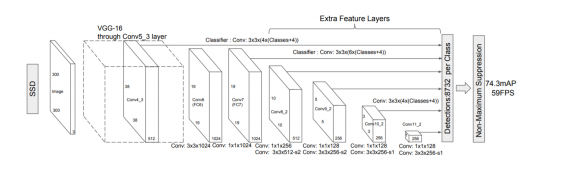
- VGG-16(backbone) + Extra Convolution layers
- 입력 이미지 사이즈 300 x 300
Multi-scale feature maps
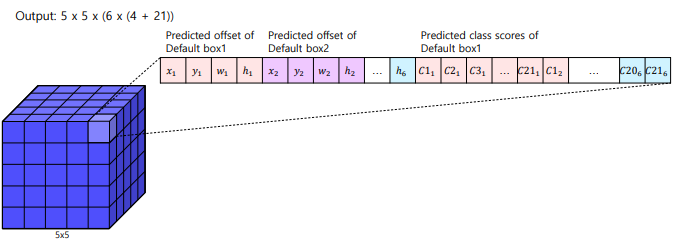
5x5x256 을 -> 5x5xC(C = )으로 해야함.
에 대해서 설명ㅎㅎ
-
: 앵커 박스(anchor box)의 개수
각 특징 맵 위치마다 여러 개의 앵커 박스를 사용합니다.앵커 박스는 서로 다른 크기(scale)와 비율(aspect ratio)을 가집니다. -
Offsets: 바운딩 박스 오프셋 값의 개수
일반적으로 4개의 값을 사용합니다 (x, y, width, height).이 오프셋은 앵커 박스를 조정하여 실제 객체 위치를 더 정확하게 예측하는 데 사용됩니다.
(offset 이라고 하는 이유가,기본 박스(anchor box)와 실제 객체의 위치를 더 잘 맞추기 위해 예측된 바운딩 박스의 조정값을 의미함) -
: 분류할 클래스의 수
배경 클래스를 포함한 전체 클래스 수입니다.
Multi-scale feature maps:
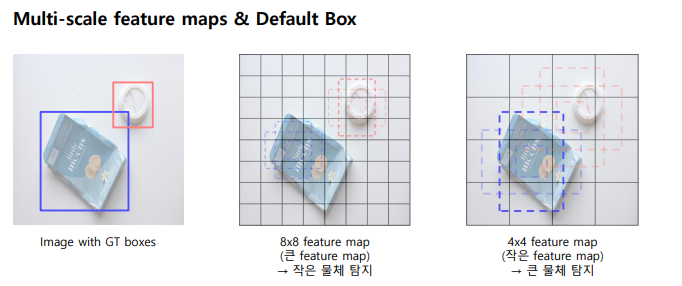
SSD는 여러 크기의 특징 맵을 사용하여 물체를 탐지합니다. 각 특징 맵의 셀은 여러 개의 기본(default) 박스를 가지고 있으며, 각 박스에 대해 오프셋과 클래스 점수를 예측
Default Box
feature map의 각 cell 마다 서로 다른 scale, 비율을 가진 미리 정해진 box 생성
-> FasterRCNN의 anchor box 와 유사함.
Multi-scale feature maps & Default Box
Training
- Hard Negative Mining 수행
- Non Maximum suppression 수행
Loss Function
- : 디폴트 박스와 실제 객체 간의 매칭 여부를 나타내는 인덱스
- : 클래스 확률을 나타내는 예측 값
- : 예측된 바운딩 박스의 좌표
- : 실제 객체의 바운딩 박스 좌표
- : 매칭된 디폴트 박스의 수
- : localization loss에 대한 가중치.
① Localization loss (Smooth L1)
localization loss는 예측된 바운딩 박스와 실제 객체의 바운딩 박스 간의 차이를 측정
- : 디폴트 박스 가 매칭된 경우 1, 아니면 0
- : 실제 바운딩 박스의 정규화된 좌표 및 크기
② Confidence loss (Softmax)
where
- : 예측된 클래스 확률
- : 긍정/부정 매칭 박스
4. YOLO Follow-up
4.1 YOLO v2
기존과 Better 한 점
① Batch normalization
② High resolution classifier
-
YOLO v1 : 224x224 이미지로 사전 학습된 VGG를 448x448 Detection 태스크에 적용
-
YOLO v2 : 448x448 이미지로 새롭게 finetuning
③ Convolution with anchor boxes
- Fully connected layer 제거(속도를 느리게 하는 원인 제거)
- YOLO v1 : grid cell의 bounding box의 좌표 값 랜덤으로 초기화 후 학습
- YOLO v2 : anchor box 도입
- K means clusters on COCO datasets
- 좌표 값 대신 offset 예측하는 문제가 단순하고 학습하기 쉬움
④ Fine-grained features
- 크기가 작은 feature map은 low level 정보가 부족
- Early feature map은 작은 low level 정보 함축
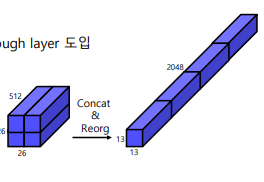
- Early feature map을 late feature map에 합쳐주는 passthrough layer 도입
- 26x26 feature map을 분할 후 결합
26 x 26 x 512 -> 13 x 13 x 2048 로 늘려줍니다. 이렇게 채널수를 늘려주면 더 많은 추상적이고 복잡한 특징을 학습할 수 있게 합니다.
⑤ Multi-scale training - 다양한 입력 이미지 사용 {320, 352, …, 608}
⑥ Backbone model
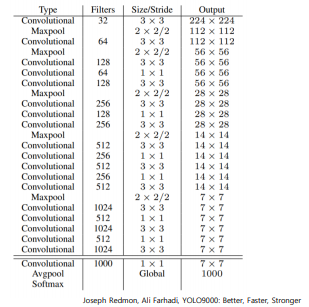
- GoogLeNet → Darknet-19
⑦ Darknet-19 for detection
- 마지막 fully conected layer 제거
- 대신 3x3 convolution layer로 대체
- 1x1 convolution layer 추가
4.2 YOLO v3
Darknet - 53
- Skip connection 적용
- Max pooling x, convolution stride 2사용
Multi-scale Feature maps
- 서로 다른 3개의 scale을 사용 (52x52, 26x26, 13x13)
- Feature pyramid network 사용
-> High-level의 fine-grained정보와 low-level의 semantic 정보 얻음.
5. RetinaNet
1 stage detector 가 가지고 있는 고질적인 문제점(class imbalance)을 해결한 모델.
5.1 Overview
1 Stage Detector Problem
① Class imbalance
1 stage는 S x S 그리드로 나누어서 탐지하는데, 대부분의 영역은 배경영역으로
객체영역인 Positive sample 보다 배경영역인 Negative sample영역이 압도적으로 많다.
② Anchor Box 대부분 Negative sample
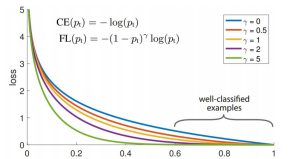
5.2 Focal loss
논문 : https://arxiv.org/abs/1708.02002
새로운 loss function
👉 Cross entropy loss + scaling factor 을 합친 loss function
-> 쉬운 예제에는 작은 가중치 어려운 예제에는 큰 가중치를 둬서, 결론적으로 어려운 예제에 집중하게끔 하는 loss function
- 는 클래스에 대한 모델의 예측 확률입니다.
- 는 클래스 불균형을 조정하기 위한 가중치 팩터입니다.
- 는 focusing 파라미터로, 쉬운 예제의 영향을 줄이는 정도를 조절합니다.
FocalLoss는특히객체탐지작업에서배경클래스와객체클래스간의극심한불균형을효과적으로다룰수있어,one-stage탐지기의성능을크게향상시켰습니다
6. 참고자료
1) Hoya012, https://hoya012.github.io/blog/Tutorials-of-Object-Detection-Using-Deep-Learning-first-object-detection-using-deep-learning/
2) 갈아먹는 Object Detection, https://yeomko.tistory.com/13
3) Deepsystems, https://deepsystems.ai/reviews
4) https://herbwood.tistory.com
5) https://arxiv.org/pdf/1506.02640.pdf (You Only Look Once: Unified, Real-Time Object Detection)
6) https://arxiv.org/pdf/1512.02325.pdf (SSD: Single Shot MultiBox Detector)
7) https://arxiv.org/pdf/1612.08242.pdf (YOLO9000: Better, Faster, Stronger)
8) https://pjreddie.com/media/files/papers/YOLOv3.pdf (YOLOv3: An Incremental Improvemen)
9) https://arxiv.org/pdf/1708.02002.pdf (Focal Loss for Dense Object Detection)
10) https://github.com/aladdinpersson/Machine-Learning-Collection/tree/master/ML/Pytorch/object_detection
