0. Intro
Detection 부분에서는 속도와 처리가 효율적(efficient)하게 이루어줘야 한다.
이를 위해 Effecient Detection 이 나왔다..!!
1. Efficient in Object Detection
1.1 Scaling
Model Scaling
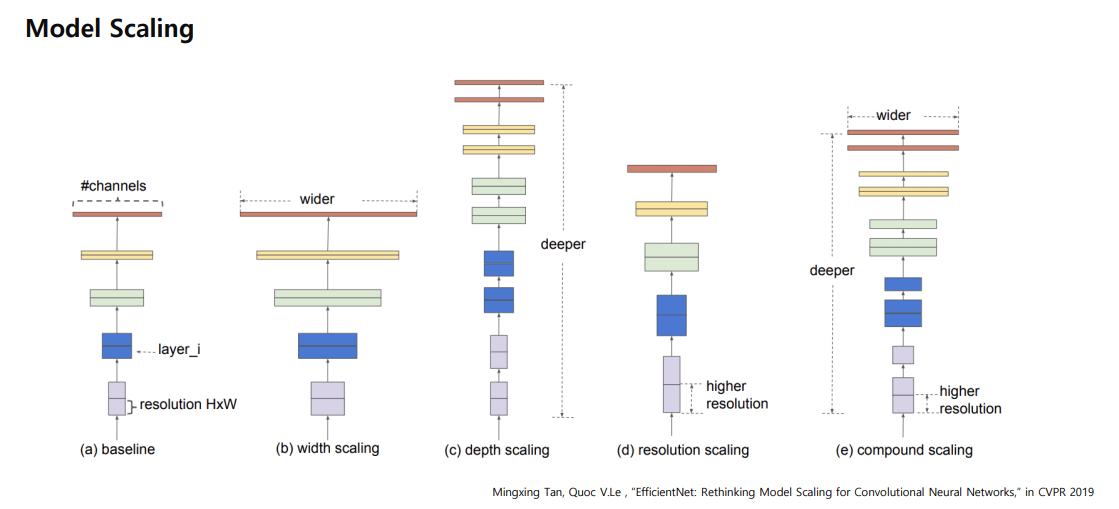
모델을 쌓는 것을 Model Scaling 이라고 하는데, 기존 연구들은
Baseline 모델이 있을 때 3가지 방향으로 scale up 했다.
첫번째로 Depth scaling : 모델을 깊게
두번째로 width scaling : 채널을 깊게
세번째로 resolution scaling : 큰 이미지를 넣는 것.
마지막으로 compound scaling : 모델,채널, 이미지 까지 모두 넣는것.
① Width Scaling
Wide Residual Networks(WRNs)에서 네트워크의 너비를 늘리는 방법을 의미합니다. 이는 네트워크의 깊이를 증가시키는 대신 각 레이어의 필터 수를 늘려 성능을 향상시키는 접근 방식입니다.
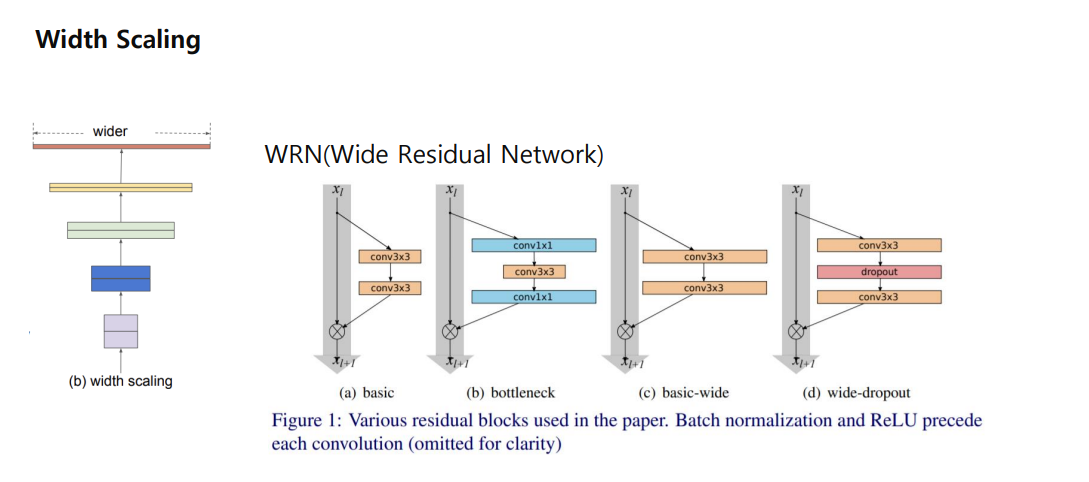
네트워크의 width를 스케일링하는 방법은 작은 모델에서 주로 사용됨 (ex. MobileNet, MnasNet ) 더 wide한 네트워크는 미세한 특징을 잘 잡아내는 경향이 있고, 학습도 쉬움 하지만, 극단적으로 넓지만 얕은 모델은 high-level 특징들을 잘 잡지 못하는 경향이 있음
(a) Basic
Basic Residual Block는 가장 단순한 형태의 residual block입니다. 두 개의 3x3 합성곱 레이어가 연속적으로 배치되어 있으며, 입력과 출력 사이에 직접적인 연결(스킵 연결)이 있습니다. 이 스킵 연결은 입력을 그대로 출력에 더해주는 역할을 하여, 네트워크가 학습해야 할 것이 입력과 출력 간의 차이(잔차)만으로 줄어듭니다23.
(b) Bottleneck
Bottleneck Block은 네트워크의 계산 효율성을 높이기 위해 설계되었습니다. 이 구조는 1x1, 3x3, 1x1 합성곱 레이어로 구성됩니다. 첫 번째 1x1 합성곱은 차원을 축소하고, 3x3 합성곱은 주요 특징을 추출하며, 마지막 1x1 합성곱은 차원을 다시 확장합니다. 이러한 구조는 깊은 네트워크에서 자주 사용되며, 계산량을 줄이면서도 깊이를 유지할 수 있게 합니다46.
(c) Basic-Wide
Basic-Wide Block은 기본 블록의 너비를 확장한 형태입니다. 각 합성곱 레이어에 더 많은 필터를 사용하여 너비를 증가시킵니다. 이는 네트워크의 표현력을 높이고, 깊이를 줄이면서도 성능을 향상시키는 데 도움이 됩니다56.
(d) Wide-Dropout
Wide-Dropout Block은 Basic-Wide 블록에 드롭아웃을 추가한 형태입니다. 드롭아웃은 과적합을 방지하기 위해 사용되며, 합성곱 레이어 사이에 적용됩니다. 이는 네트워크가 더 일반화된 성능을 발휘하도록 돕고, 특히 깊이가 깊어질수록 특징 재사용 감소 문제를 완화하는 데 유용합니다
Depth Scaling
네트워크 깊이를 늘려가면서, 성능 향상
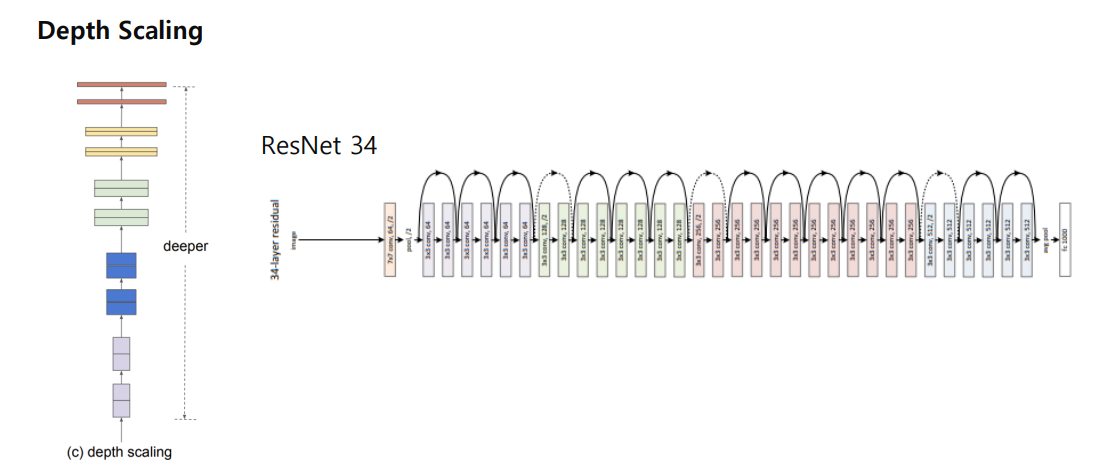
네트워크의 깊이를 스케일링하는 방법은 많은 ConvNet 에서 쓰이는 방법 DenseNet, Inception-v4• 깊은 ConvNet은 더 풍부하고 복잡한 특징들을 잡아낼 수있고, 새로운 태스크에도 잘 일반화됨 하지만 깊은 네트워크는 gradient vanishing 문제가 있어 학습이 어려움
Resolution Scaling
- 고화질의 input 이미지를 이용하면 ConvNet은 미세한 패턴을 잘 잡아낼 수 있음
- 최근 Gpipe는 480x480 이미지를 이용하여, ImageNet 에서 SOTA를 달성함
1.2 Background
🤔 더 높은 정확도와 효율성을 가지면서 ConvNet 크기를 키우는 방법은 없을까?
👉 EfficientNet팀의 연구는 네트워크의 폭(width), 깊이(depth), 해상도(resolution) 모든
차원에서의 균형을 맞추는 것이 중요하다는 것을 보여주었다. 그리고 이러한 균형은 각각의 크기를 일정한 비율로 확장하는 것으로 달성할 수 있었다
2. EfficientNet
논문 : https://arxiv.org/abs/1905.11946
2.1 등장배경
- 파라미터 수가 점점 많아지고 있고 ConvNet 은 점점 더 커짐에 따라 정확해지고 있다.
- 점점 빠르고 작은 모델에 대한 요구 증가.
(예를 들어, 음식 이미지를 찍었을때 칼로리가 몇인지 말해주는 서비스가 있는데 사진찍고 나서 나오는데 1분이상 걸린다면, 이 서비스를 이용하지 않을 것이다.) - 효율성과 정확도의 trade-off 를 통해 모델 사이즈를 줄이는 것이 일반적
- 큰 모델에 대해서는 어떻게 모델을 압축시킬지가 불분명함
👉 위 논문은 아주 큰 STOA ConvNet의 efficiency 를 확보하는 것을 목표로 하고 ,
이는 model scaling을 통해 목표를 달성.
2.2 Scale up
-> width, depth, resolution scaling up (위에 참조)
2.3 Accuracy & Efficiency
① 목적 함수:
목표: 모델 의 정확도(Accuracy)를 최대화하는 것이 목적입니다.
는 모델을 나타내며, 이 모델은 파라미터 , , 에 의해 결정됩니다.
- : 깊이(Depth)를 나타내며, 모델이 얼마나 깊은지(층의 개수)를 의미할 수 있습니다.
- : 너비(Width)로, 모델의 각 층에서 사용하는 필터나 노드의 개수를 나타낼 수 있습니다.
- : 해상도(Resolution)를 나타내며, 입력 데이터의 해상도 크기(픽셀 수)를 의미할 수 있습니다.
- 목적: 주어진 (d), (w), (r)에 따른 모델의 정확도를 최대화하는 파라미터를 찾는 것입니다.
② 모델 정의:
모델 구조: 이 식은 모델 의 구성 방식을 나타냅니다. 각 (i)-번째 층(layer)의 구성 요소들이 결합되어 최종 모델을 형성하는 구조입니다.
-
: 각 층을 결합하는 연산을 나타내며, (s)개의 층(layer)을 포함한 모델 구조를 의미합니다.
-
): (i)-번째 층에서 깊이 (d)에 따라 정의된 필터 또는 변환을 의미합니다.
-
-번째 층의 활성화 함수 또는 연산 블록을 의미합니다. 이 함수는 입력 데이터를 변환하는 역할을 합니다.
-
): (i)-번째 층에 주어지는 입력 데이터의 특성을 나타냅니다.
- : 해상도(Resolution), 입력 데이터의 픽셀 해상도를 나타냅니다.
- ): 각각 (i)-번째 층에서 사용되는 입력의 높이(height)와 너비(width)를 나타냅니다.
- : 모델의 너비(Width)로, 층에서 사용하는 필터 또는 노드의 개수를 조정합니다.
- ): (i)-번째 층에서의 채널 수(channels)를 나타냅니다.
Better Efficiency
③제약 조건 1:
메모리 제한: 모델 )가 사용하는 메모리의 양이 목표 메모리 한도(target_memory)를 넘지 않아야 한다는 제약 조건입니다.
모델의 깊이 (d), 너비 (w), 해상도 (r)는 모델이 사용하는 메모리에 직접적인 영향을 미치므로, 이 파라미터들을 조정하여 메모리 사용량을 제한해야 합니다.
④ 제약 조건 2:
연산량 제한(FLOPS): 모델이 수행하는 연산량(Floating Point Operations Per Second, FLOPS)이 목표 FLOPS 한도(target_flops)를 넘지 않아야 한다는 제약 조건입니다.
모델의 복잡도는 연산량과 직접적으로 관련되며, (d), (w), (r)와 같은 파라미터들이 이를 결정하는데 중요한 역할을 합니다. 이 제약을 통해 모델의 연산 복잡도를 제한할 수 있습니다.
Observation
- 네트워크의 폭, 깊이, 혹은 해상도를 키우면 정확도가 향상된다.하지만 더 큰 모델에 대해서는 정확도 향상 정도가 감소한다.
- 더 나은 정확도와 효율성을 위해서는, ConvNet 스케일링 과정에서 네트워크의 폭, 깊이, 해상도의 균형을 잘 맞춰주는 것이 중요하다
👉 d,w,r 을 균형있게 맞추어 보자.
Compound Scaling Method
모델의 성능을 최적화하기 위해 모델의 깊이 , 너비, 해상도를 균형 있게 동시에 확장(scaling) 하려는 접근. 이 방식은 세 가지를 동시에 조절함으로써 더 효율적인 모델 확장을 가능하게 한다.
-
depth scaling: )
여기서 는 모델의 깊이 는 깊이를 조절하는 scaling factor. 는 전체 스케일링 단계의 지표로 모델이 얼마나 크거나 작은지를 결정하는 변수. 로 설정되어 있어 깊이는 항상 증가하거나 유지됨. -
width:)
-
resolution: )
subject to(제약조건):
이 식은 깊이(α), 너비(β), 해상도(𝛾) 간의 균형을 맞추기 위한 제약조건입니다. 이 제약 조건은 모델의 복잡도를 과도하게 증가시키지 않으면서도 각 요소의 적절한 비율을 유지하게 합니다. 이 식을 통해, scaling 시 각 요소가 비슷한 비율로 증가하도록 설계됩니다
2.4 EfficientNet
- MnasNet에 영향을 받음<- 최대화 하는 것을 목표.
🤔 는 어떻게 찾을까?
👉 Step 1,2 단계를 거치면서 찾는다.
① Step 1
- 로 고정
- 를 small grid search 를 통해 찾는다.
- under constraint of
② Step 2
- 를 상수로 고정
- 다른 를 사용하여 scale up
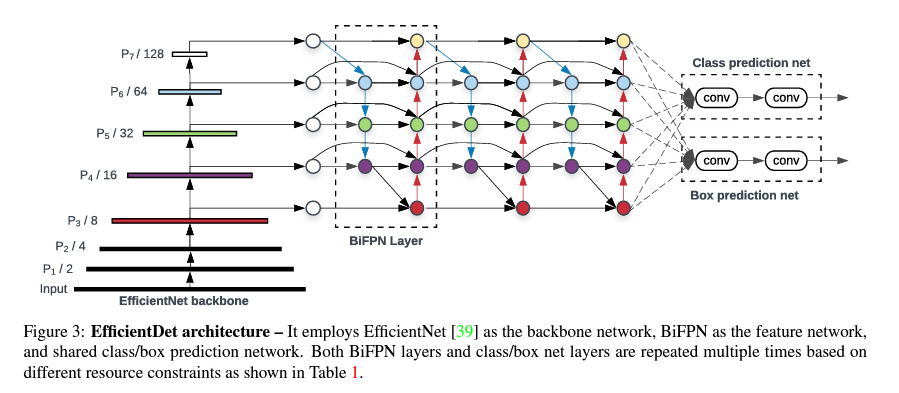
3. EfficientDet
논문 : https://arxiv.org/abs/1911.09070
EfficientNet 구조를 ObjectDetecion 에 그대로 적용.
3.1 등장 배경
회상을 위해 기존 object detection 의 모델 구조를 살펴보자.
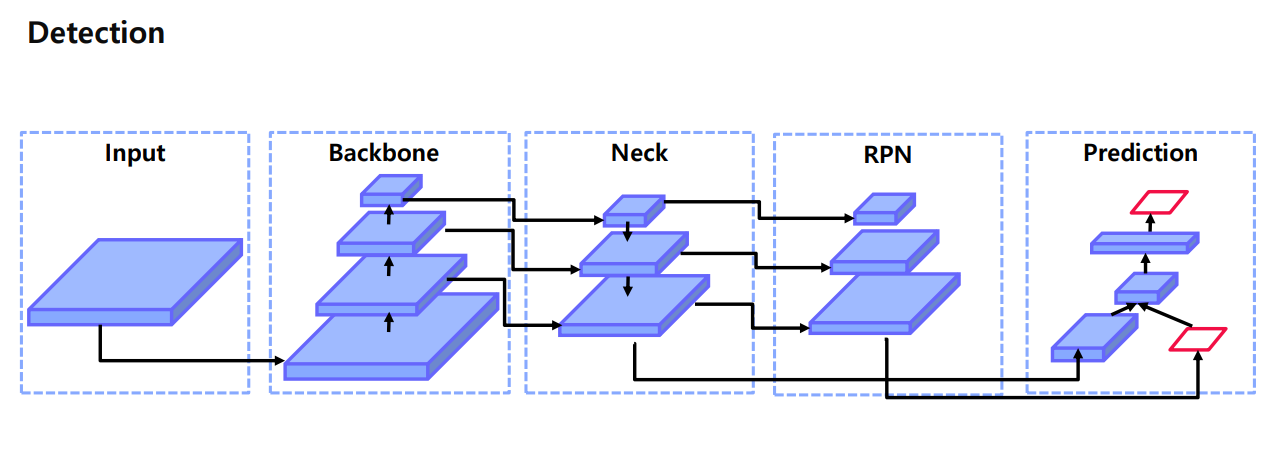
OD는 실생활에서 사용하기 위해서는 real-time 을 맞추어야 한다
따라서 object detection 은 특히 속도가 중요하다.
3.2 Challenge
1) Efficient Multi - scale feature fusion
- EfficientDet 이전에는 multi-scale feature fusion을 위해 FPN,PANet, NAS-FPN 등 Neck 사용
- 하지만 대부분의 기존 연구는 resolution 구분 없이 feature map을 단순 합
👉 따라서 이 문제를 다루기 위해 EfficientDet 팀은 각각의 input을 위한 학습 가능한 웨이트를 두는 Weighted Feature Fusion 방법으로 BiFPN(bi-directional feature pyramid network)를 제안
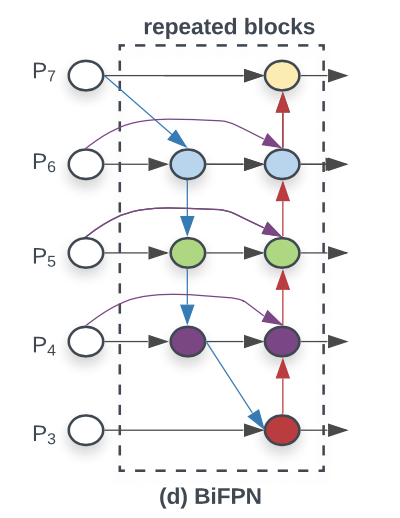 위 모델 특징:
위 모델 특징:
- 하나의 간선을 가진 노드는 제거
- Output 노드에 input 노드 간선 추가
- 양방향 path 각각을 하나의 feature Layer로 취급하여, repeatedblocks 활용
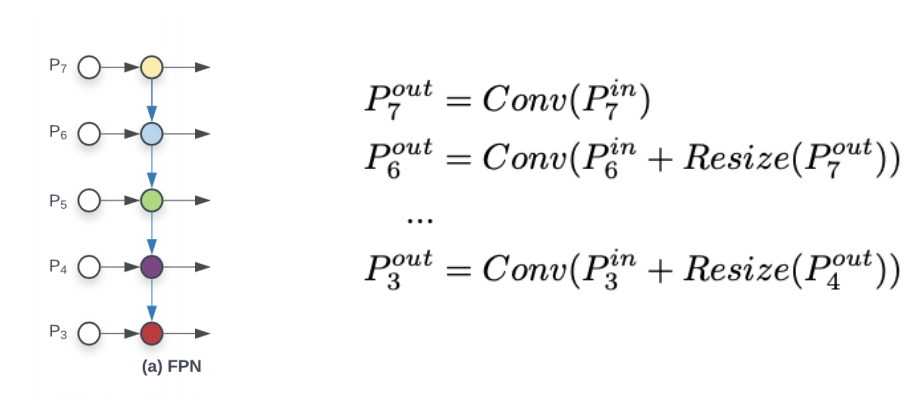
- EfficientDet은 여러 resolution의 feature map을 가중 합
- FPN의 경우 feature map의 resolution 차이를 Resize를 통해 조정한 후 합
- BiFPN의 경우 모든 가중치의 합으로 가중치를 나눠줌.
- 이 때 가중치들은 ReLU를 통과한 값으로 항상 0 이상
- 분모가 0이 되지 않도록 아주 작은 값 𝜖을 더해줌
2) Model Scaling
EfficientNet 은 Compound scaling 방식제안
-
Backbone : EfficientNet B0 ~B6
-
BiFPN network : 네트워크의 width(= # channels)와 depth(= #layers)를 compound 계수에 따라 증가시킴
은 채널 수(너비) 를 나타내고,
은 네트워크의 레이어 수(깊이) -
Box/class prediction network
-
Input image resolution
4. 참고자료
1) Mingxing Tan, Quoc V.Le , “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks,” in CVPR 2019
2) Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition, 2015
3) Mingxing Tan, Ruoming Pang, Quoc V.Le , “EfficientDet: Scalable and Efficient Object Detection
4) Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao, “YOLOv4: Optimal Speed and Accuracy of Object Detection”
5) Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie , “Feature Pyramid Networks for Object Detection”
7) Sergey Zagoruyko, Nikos Komodakis, Wide Residual Networks
