0. Intro
2 stage detector에서 더 나아간 모델들에 대해서 공부해보자.
1. Cascade RCNN
1.1 Contribution
FastR-CNN에 대해서 다시 한번 살펴보자.
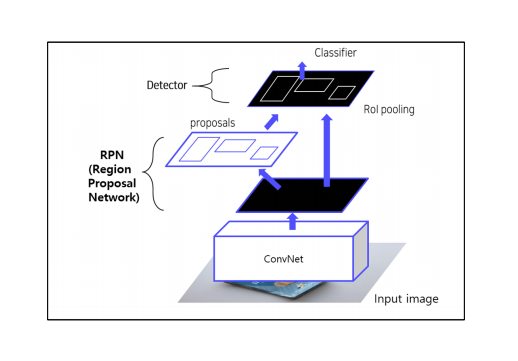
Convnet 을 이용하여 RPN 추출후 -> image classification 한다.
높은 수준의 IoU사용
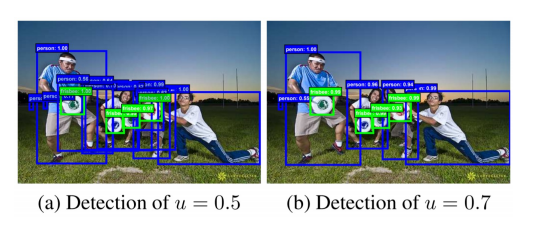
위의 이미지에서 보이는 바와 같이, 높은 수준의 IoU를 사용하면, high quality detection 을 수행. 다만, 성능이 하락하는 문제가 존재
👉 이를 극복하기 위해서 Cascad RCNN 제안.
1.2 motivation
Localization performance
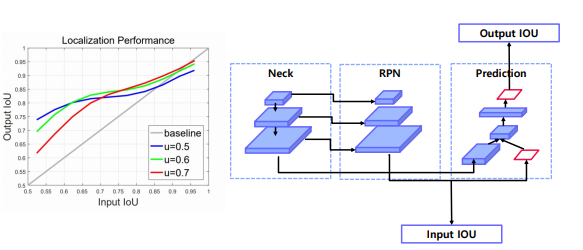
입력 IoU : 모델이 초기 예측한 바운딩 박스의 IoU 값
출력 IoU : 모델이 후처리나 조정을 거쳐 최종적으로 얻은 바운딩 박스의 IoU 값
위 이미지를 통해서 얻을 수 있는 점은, Input IoU 가 높을 수록 높은 IoU threshold 에서 학습된 model 이 더 좋은 결과를 낸다.
Detection Performance
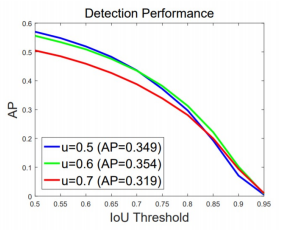
IoU threshold: 탐지 성능을 평가할 때 사용하는 기준값으로, 예측된 바운딩 박스가 실제 바운딩 박스와 얼마나 겹쳐야 참 양성(True Positive) 로 간주할지 결정
- IoU threshold에 따라 다르게 학습되었을 때 결과가 다름
- 전반적인 AP의 경우 IoU threshold 0.5로 학습된 model이 성능이 가장 좋음
IoU를 단순히 높여서만으로는, 성능 향상에 한계가 있으므로, Cascade RCNN을 제안!!
1.3 Method
각 방법론을 알아보고 마지막에 cascade R-CNN에 대해서 알아보자.
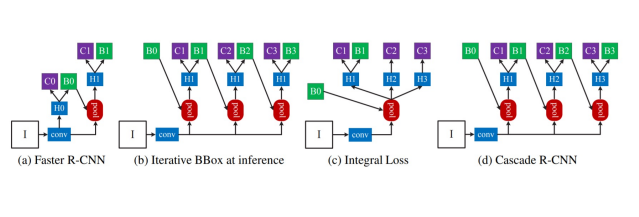
(a) Faster R-CNN
Faster R-CNN 과정 설명
① 입력 이미지 (I):
모델에 입력되는 원본 이미지입니다.
② Convolutional Layers:
입력 이미지를 특징 맵으로 변환합니다.
③ H0 (RPN Proposal):
Region Proposal Network(RPN)를 통해 생성된 제안 영역(proposal)입니다. 이 제안 영역은 객체가 있을 가능성이 높은 위치를 나타냅니다.
④ RoI Pooling:
H0에서 나온 제안 영역을 고정된 크기(H1)로 변환합니다.
RoI Pooling을 통해 다양한 크기의 제안 영역을 동일한 크기로 조정합니다.
⑤ H1:
RoI Pooling을 거쳐 고정된 크기로 변환된 특징 맵입니다.
⑥ C0 (Background Classification):
제안 영역이 배경인지 여부를 예측합니다.
⑦C1 (Object and Background Classification):
배경뿐만 아니라 객체의 종류까지 예측합니다.
⑧B1 (Bounding Box Regression):
객체의 위치를 더 정확하게 조정하기 위한 바운딩 박스 회귀를 수행합니다.
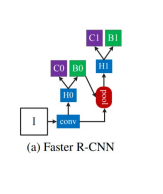
(b) Iterative BBox at inference
최종헤드로부터 B1을 얻고 B1으로 다시 projection 을 해서 B2,B3를 만듦.
즉, inference 단계에서 head 에서 예측된 bounding box를 다시 RoI projection 을 이용하는 iterative 방식.
box 가 좀 더 정확하게 생긴다. 하지만 성능의 향상은 그렇게 높지는 않다고 한다.
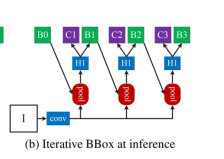
(c) Integral Loss
- Faster RCNN과는 다르게, IoU threshold 가 다른 Classifier C1,C2,C3 학습
- Loss 의 경우, 각각 C1, C2, C3 의 classifier loss 합
- : 전체 분류 손실을 나타내며, 모델의 예측 와 실제 레이블 간의 차이를 측정
- : 여러 IoU 임계값 에 대해서 합산. 는 사용된 모든 IoU 임계값의 집합.
- : 특정 IoU 임계값 에서의 분류손실. 이 부분은 모델이 해당 임계값에서 얼마나 잘 예측하는지 평가함.
: IoU 임계값 에 대한 모델의 예측
: 해당 임계값에서의 실제 레이블
- inference 시, C1,C2,C3 의 confidence 평균을 낸다.(앙상블하는 방법을 사용함)
근데 큰 성능 향상은 없다고 함.
(d) Cascade R-CNN
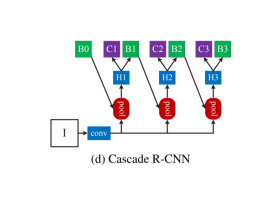
여러개의 RoI head(H1, H2, H3)를 학습하고 이때, Head 별로 IOU threshold 를 다르게 설정. -> C3, B3가 최종결과.
결과
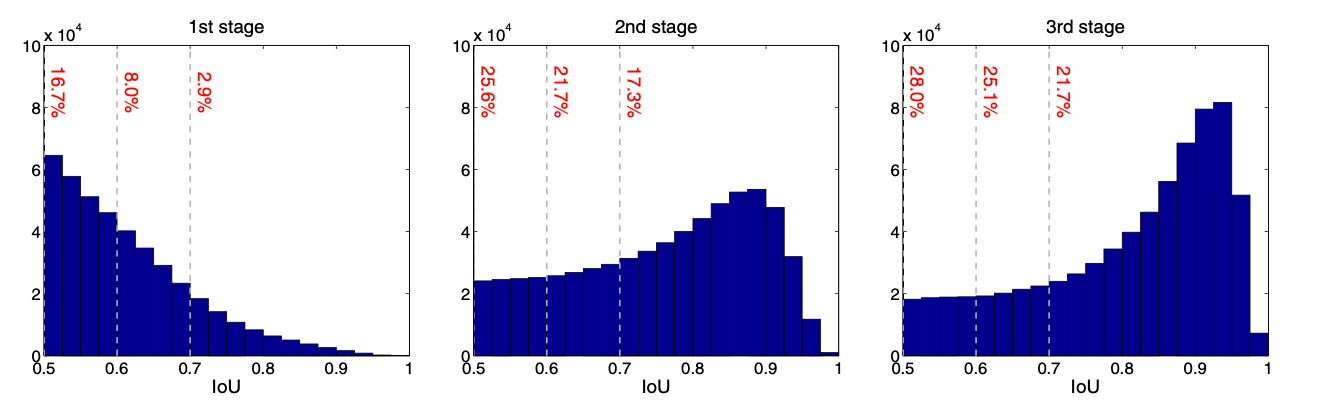
각 head 를 지나갈 때마다 , IoU 의 성능이 향상됨을 알 수 있다.
위 방법론을 통해서 알 수 있는 3가지점
(1) box pooling을 반복 수행할 시 성능 향상되는 것을 증명 (Iterative)
(2) IOU threshold가 다른 Classifier가 반복될 때 성능 향상 증명 (Integral)
(3) IOU threshold가 다른 RoI head를 cascade로 쌓을 시 성능 향상 증명 (Cascade)
2. Deformable Convolutional Networks (DCN)
2.1 Contribution
CNN의 문제점
일정한 패턴을 지닌 convolution neural networks는 geometric transformations에 한계를 지님



Affine, viewpoint, Pose에 따라서 CNN은 Object 가 다르다고 느낄 수 있는 것이다.
기존 해결 방법
Geometric augmentation

즉, Geometric 된 이미지를 이미지를 training 시키는 방식으로 하면 모델이 이해할 수 있게 된다. 하지만 이는 모델이 우리가 추가한 것만 이해할 수 있게 하고 train에 test 할 augmentation 을 넣지 않으면 쓸모가 없어진다.
Geometric invariant feature selection

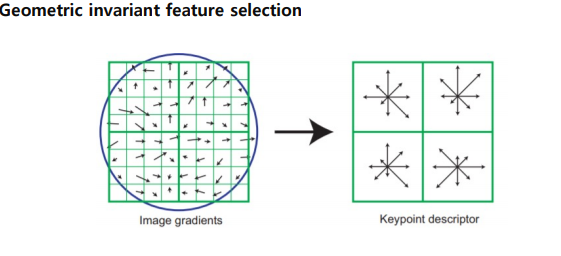
뽑힌 feature 들도 결국 사람의 손에 의해서 뽑힌 feature 들이기 때문에 end-to-end 라고 보기 어렵다. 결국 사람이 heuristic 하게 넣어준 것만 학습하게 되면은 사람이 모르는 feature 에서는 안될 수 밖에 없다.
2.2 Method
Deformable Convolution
3.Transformer
3.1 Overview
3.2 Vision Transformer (ViT)
3.3 End-to-End Object Detection with Transformer
3.4 Swin Transformer
4. 참고사항
1) Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao, “YOLOv4: Optimal Speed and Accuracy of Object Detection”
2) Zhaowei Cai, Nuno Vasconcelos, “Cascade R-CNN: Delving into High Quality Object Detection”
3) David G. Lowe, “Distinctive Image Features from Scale-Invariant Keypoints”
4) Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, Yichen Wei, “Deformable Convolutional Networks”
5) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, IlliaPolosukhin, “Attention Is All You Need”
6) Alexey Dosovitskiy, “AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE”
7) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko, “End-toEnd Object Detection with Transformers”
8) Ze Liu, “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows”
