1. Data-Centric AI 필요성
1.1 AI Research vs AI Production
수업/학교/연구
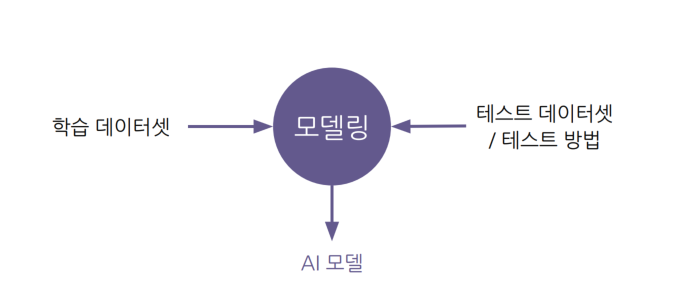
-> 정해진 데이터셋/평가 방식에서 더 좋은 모델을 찾는일을 한다.
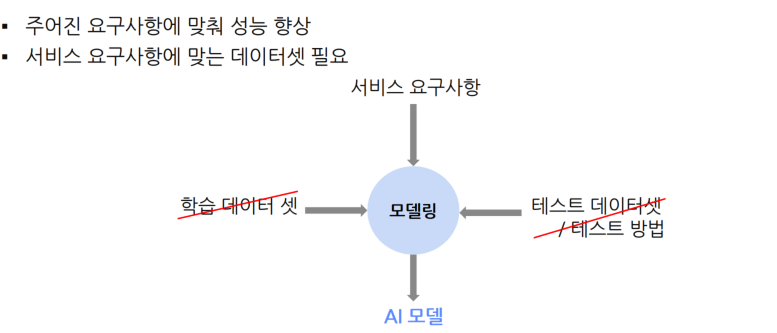
서비스 개발시
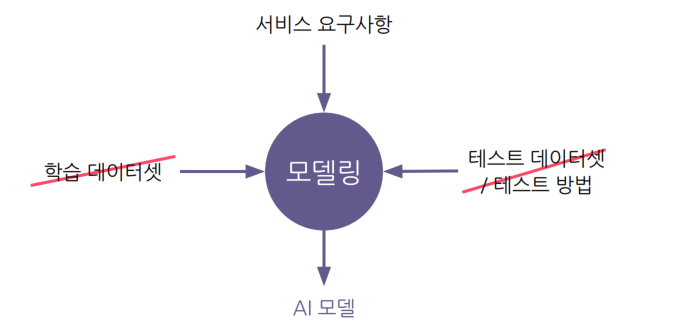
-> 데이터셋은 준비되어 있지 않고, 요구사항만 존재.
-> 서비스에 적용되는 AI 개발의 상당부분이 데이터셋을 준비하는 작업.
1.2 Production Process of AI Model
AI모델 개발 4단계
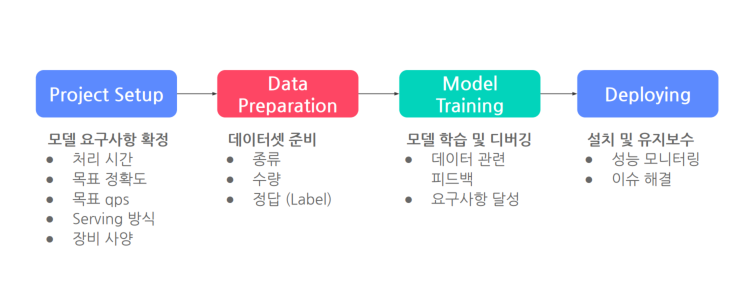
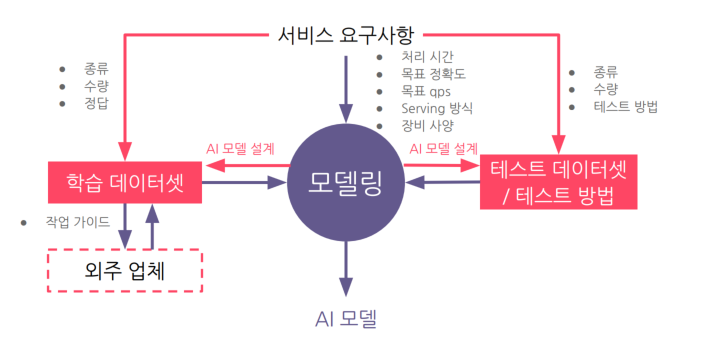
이 과정의 목표: 요구사항을 충족시키는 모델을 지속적으로 확보하는 것.
여기서는 (1)Data Centric 방법 과 (2) Model-Centric 방법 2가지가 있다.
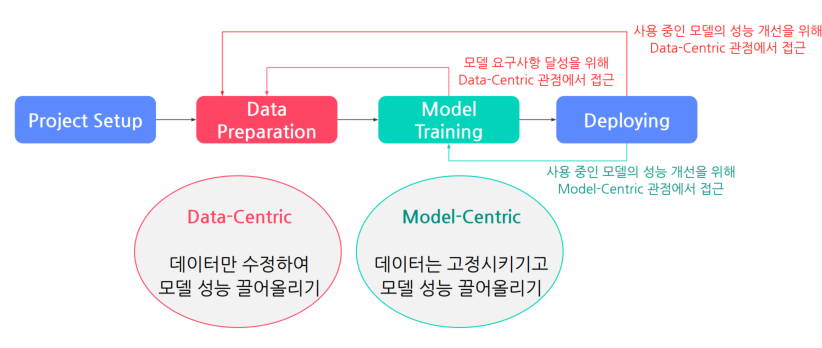
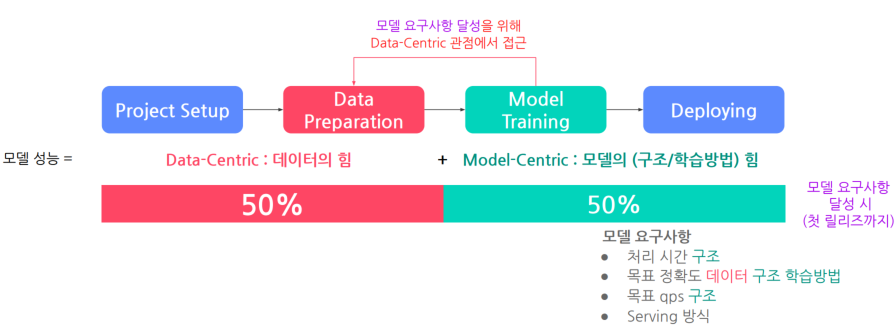
목표달성에 있어 데이토와 모델에 대한 비중
첫 release 할시, -> data50:model50
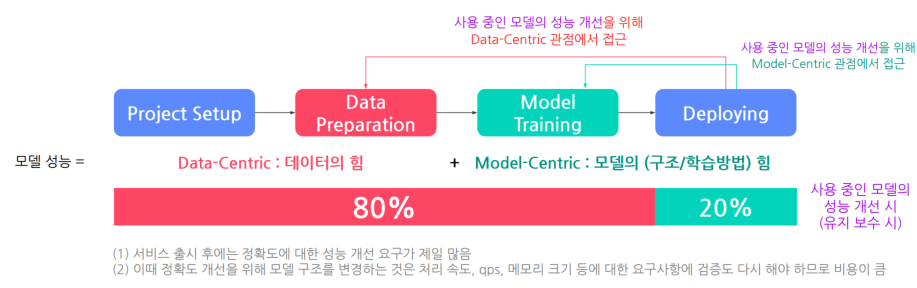
사용중인 모델 개선할때 data80:model20
2. Data-Centric AI 흐름
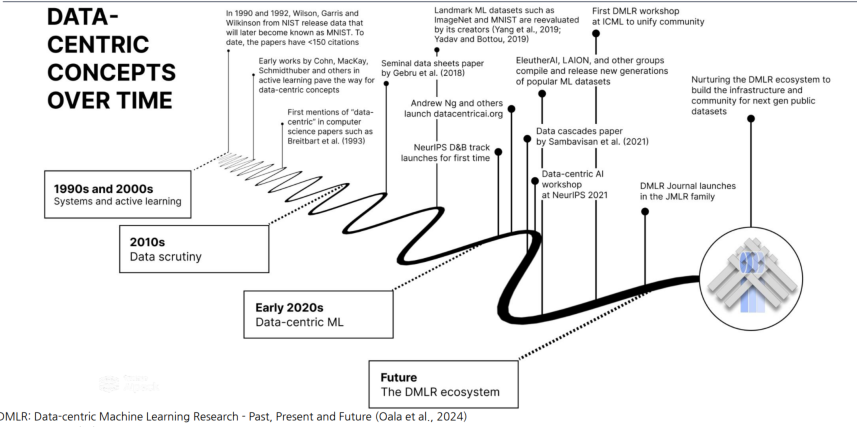
위 이미지에서처럼, 처음에는 논문 citation 수도 적었지만 이후에는 크게 발전하는 모습을 볼 수 있다.

DMLR 논문 :https://arxiv.org/abs/2311.13028
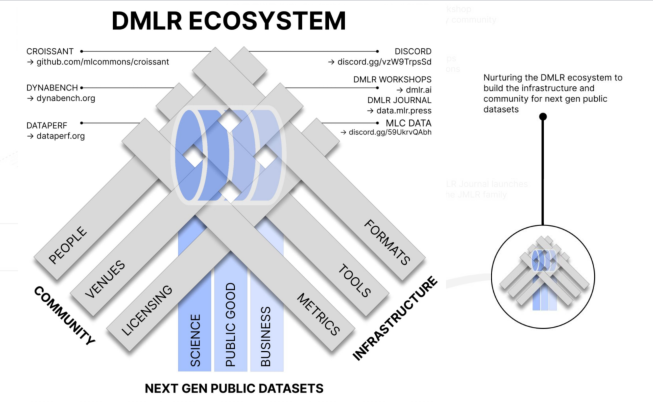
3. Data-Centric AI 최근동향
Data-FlyWheel
Data-FlyWheel: 산업에서 데이터를 활용해 최대한의 가치를 창출하고 모델의 성능을 향상시키려는 선순환 구조 이 개념은 데이터와 인공지능 성능 간의 상호 강화 관계를 통해 지속적인 개선과 성장을 이루는 프레임워크를 말합니다.
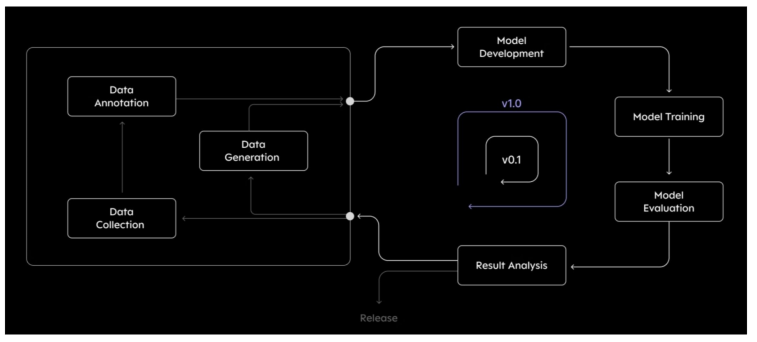
DMops : DataManagement Operations & Recipes
논문 : https://arxiv.org/abs/2301.01228
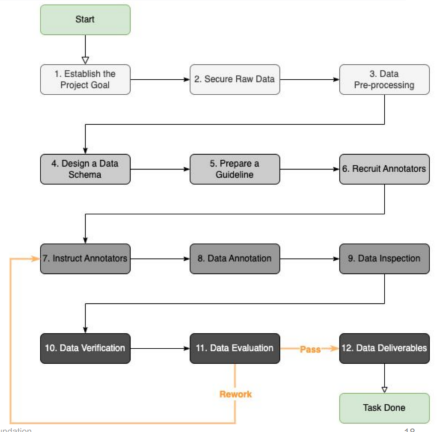
- DataAnnotationTool
좋은 데이터를 얻기 위해 Data Annotation Tool을 잘 설계해야함 - 크라우드소싱
언제 어디서든 누구나 온라인 플랫폼을 통해 데이터작업에 참여할 수 있는 방식 - DataSoftwareTool
DMOps에서 더 나아가 데이터를 clean하게 만들 수 있는 여러 기능을 제공
Data Labeling Tool
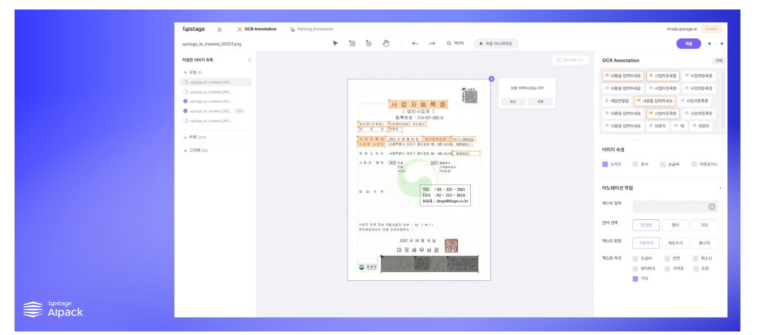
https://www.upstage.ai/ai-pack
ChatGPT improved GPT-3 by improving data quality

-> GPT 가 GPT를 통해서 데이터를 입력받아서, 모델 성능을 향상
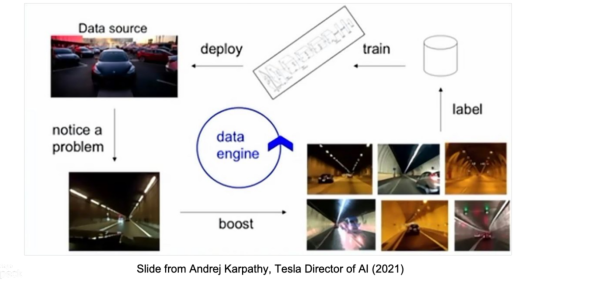
Tesla Data Engine:use model outputs to improve training dataset
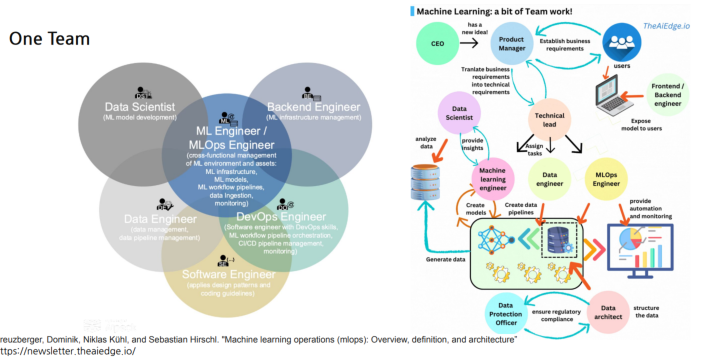
One Team
🤔 학계에서 데이터를 다루기 힘든 이유?
① 좋은 데이터를 많이 모으기 힘들고,데이터는 아직 미지의 영역이다
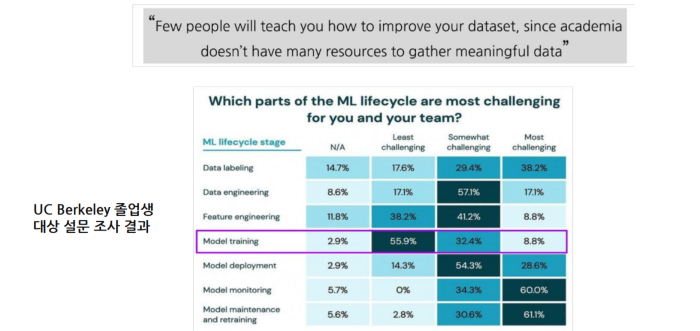
② 라벨링 작업에 대한 명확한 정답이 없고 비용이 크다.
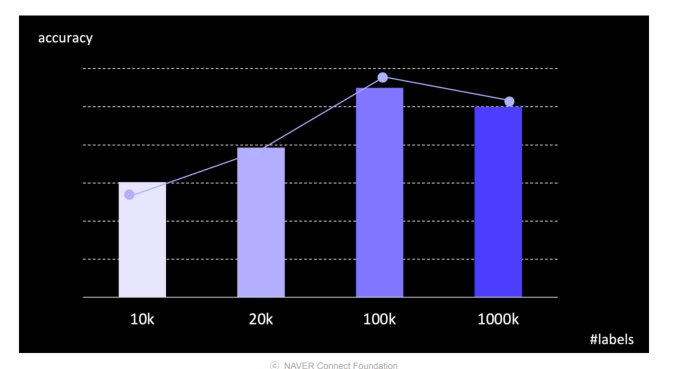
1000k가 100k보다 오히려 성능이 떨어지는 현상이 발생하기도 한다. 이는 라벨링이 잘못되었을 가능성이 높다.
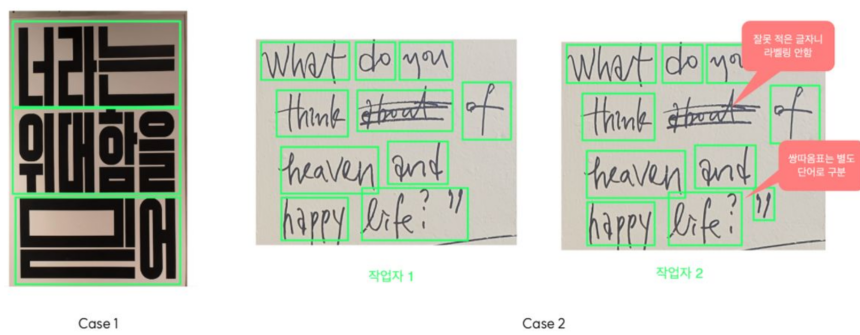
예를들어, 똑같은 데이터라고 하더라도 라벨작업을 다르게하여 라벨링 노이즈가 발생하게 된다.
좋은 데이터를 만들기 위해서는 일관성있게 라벨링, 중요한 케이스, 예상치 못한 데이터, 적절한 크기의 데이터가 있어야 한다.
👉 즉, 특이 경우를 발견하고 해당 샘플들을 모으며, 이를 포함한 라벨링 가이드를 만들어야 한다.
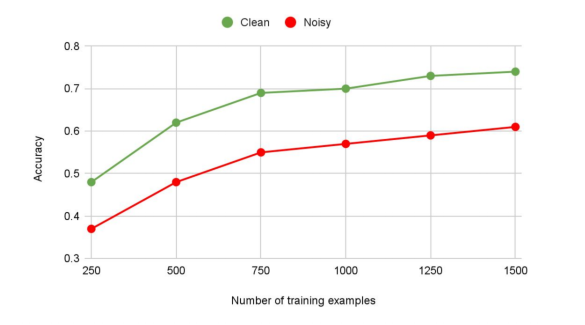
③ High Quality Data가 필요하다(데이터의양<데이터의질)
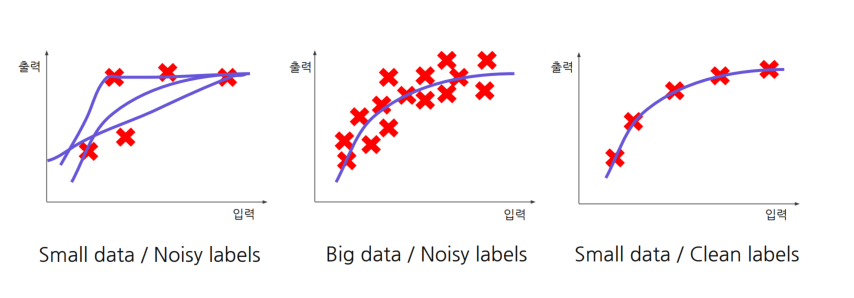
-> data가 많아도 라벨노이즈가 많으면 안 좋을 수도 있다.
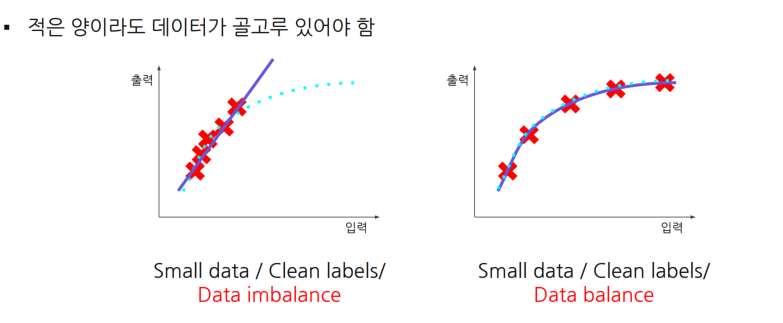
④ 데이터의 균형이 맞아야 한다
⑤ 학계는 정해진 테스트셋 내에서 경쟁하는 방식이다
3.2 Data-CentricAI:학계X산업계
논문 : https://arxiv.org/abs/2207.10062

4. 참고자료
