1. OCR Basics
1.1 OCR 정의
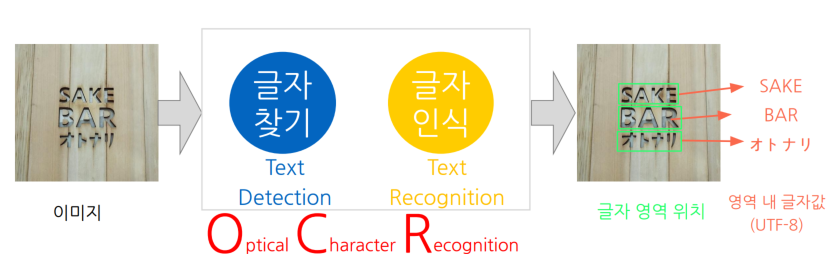
OCR : Optical Character Recognition
STR : Scene Text Recognition

글자를 읽는다 = 글자영역찾기 + 영역 내 글자인식 = OCR
Off line Handwriting VS On line Handwriting

1.2 ObjectDetection 과 비교

ObjectDetection은 위치와 클래스를 예측하는 문제라면,
OCR은 Text라는 단일 클래스이므로, 위치만을 예측하는 문제이다.
OCR 특징

매우높은 밀도, 극단적 종횡비, 특이모양

모호한 객체 영역, 크기 편차.
1.3 글자 영역 표현법
사각형 종류들
(1) 직사각형(RECT,Rectangle)
or

(2) 직사각형 + 각도(RBOX, Rotated Box)
or

(3)사격형(QUAD, Quadrilateral)
첫 글자의 좌상단이 그후 시계방향

다각형(Polygon - (

- Arbitrary-Shaped text 를 주로 다룸.
- 일반적으로 2N points를 사용하고 상하점들이 쌍을 이루도록 배치함.
(두 점과 쌍이 되는 아래의 두 점을 잡으면 특정 글자 영역이 되도록함)
2. OCR Subtasks/Modules
OCR를 수행하기 위해서 필요한 subtask들.
2.1 Text Detector
ObjectDetection 의 경우
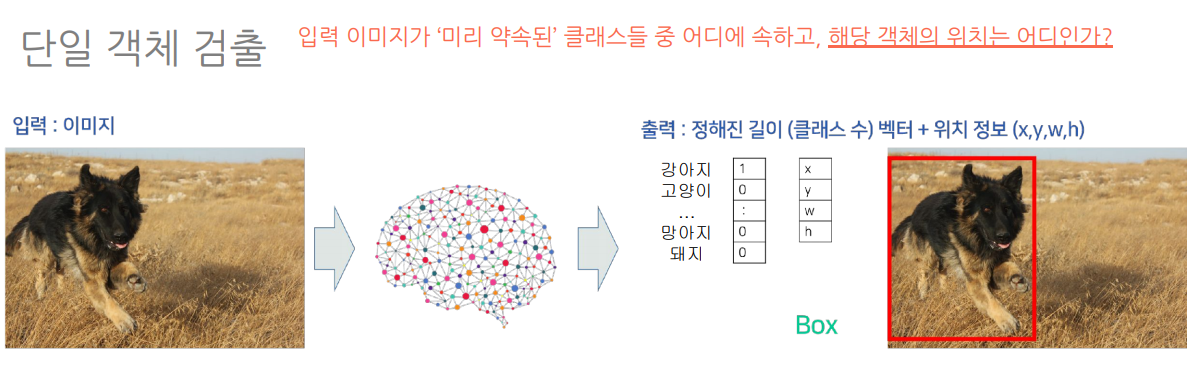
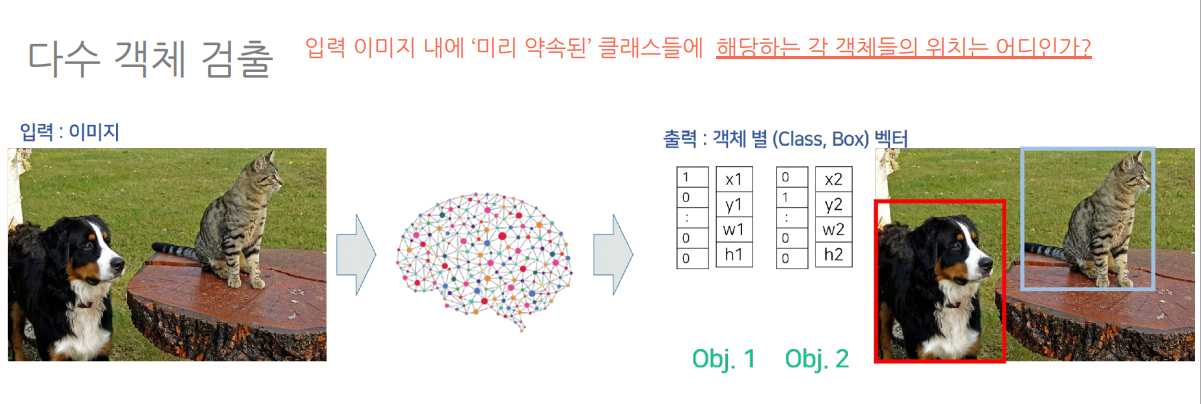
객체들을 파악하고 -> 각 객체의 클래스가 무엇인지 예측
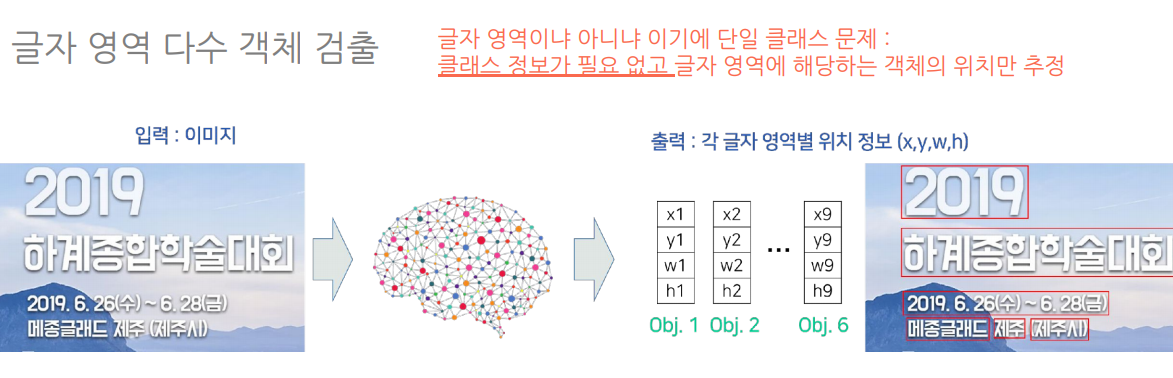
글자검출
글자 영역이냐(1) 아니냐(0)의 문제
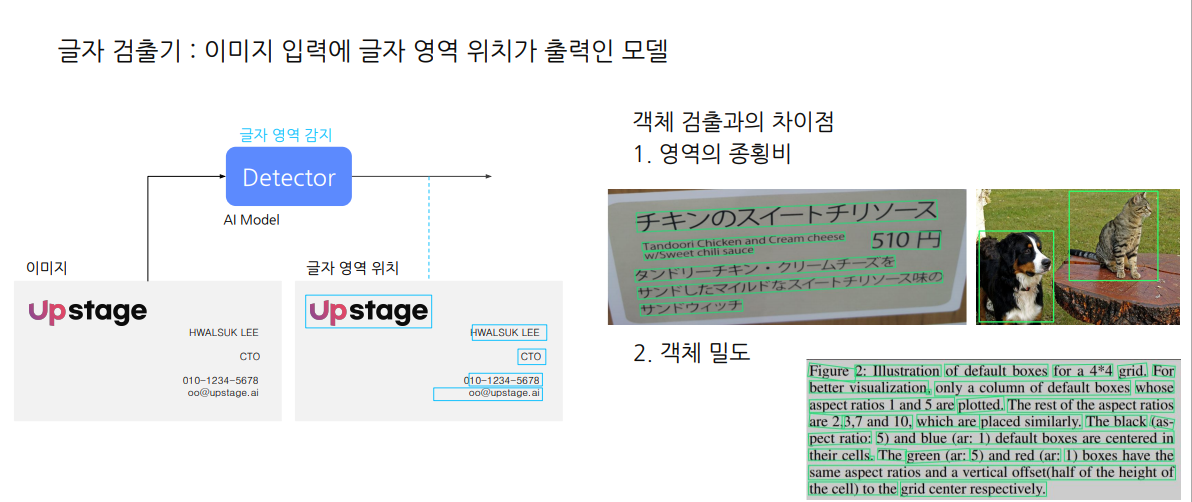
👉 글자이미지가 주어지면 Detector 를 통해서 글자영역위치를 추출하고 Recognizer를 통해서 글자영역 내 글자값 추출
결론 : Text Detector의 출력은 텍스트의 각 단어를 감싸느 박스 좌표값이다. 따라서 단어에 대한 분할을 한다고는 보기 힘드며, 특히 텍스트 밀도가 높은 상황에서 Text detector의 박스들은 반드시 문장이나 단어에 대해서 구분되어 있지 않을 수 있다.
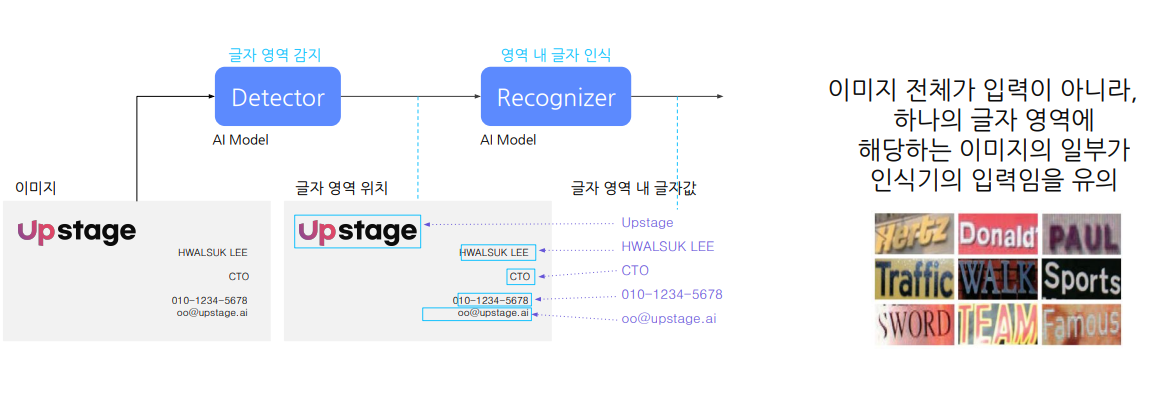
2.2 Text Recognizer
CV와 NLP의 혼합영역

2.3 Serializer(정렬기)
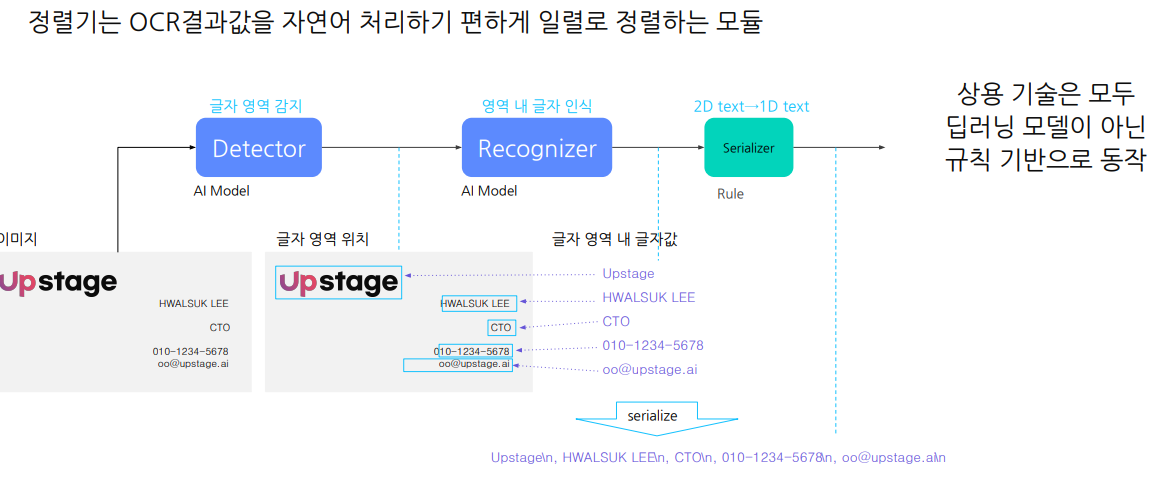
detector, recognizer가 텍스트를 추출하였다고 하더라도, serializer을 통해서 편하게 일렬로 정렬한다.
그 다음에 NLP모듈을 붙여서
- 금칙어처리
- 요약
- 글자 의미 파악
등을 할 수 있게 된다.
2.4 Text Parser
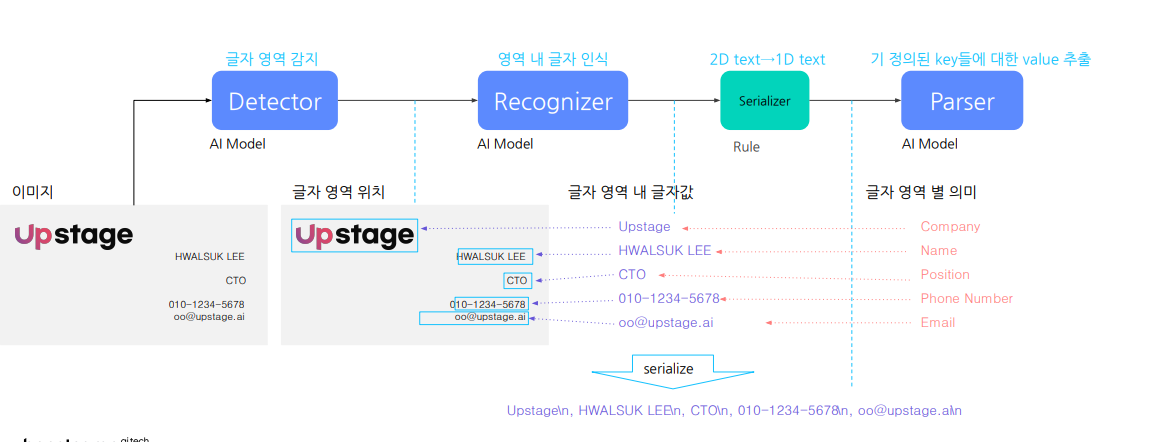
정의된 Key들에 대한 value 추출함.-> 이로 인해 이미지내에서 의미있는 text들을 {key:value} 형식으로 뽑아낼 수 있는 것임
BIO tagging
BIO(Begin Inside Outside)란, NLP에서 텍스트를 토큰화한 뒤 각 토큰이 특정 개체의 시작(Begin) 내부(Inside) 그외 (Outside)에 속하는지를 나타내는 방법이며 이 방법을 통해 문장에서 특정한 개체를 구별할 수 있다.

위 이미지에서 처럼 BIO를 사용하면
- "해"는 영화명 "해리포터"의 시작이므로 B-movie로 태깅됩니다.
- "리", "포", "터"는 영화명 "해리포터"의 내부에 있으므로 I-movie로 태깅됩니다.
- "보러"는 개체가 아니므로 O로 태깅됩니다.
- "메"는 영화관명 "메가박스"의 시작이므로 B-theater로 태깅됩니다.
- "가", "박", "스"는 영화관명 "메가박스"의 내부이므로 I-theater로 태깅됩니다.
👉 이러한 과정을 통해 각 개체에 대한 태그를 해석하며, "해리포터"는 영화명, "메가박스"는 영화관명으로 추출한다.
여기서 BIO tagging의 한계점을 볼 수 있는데, 기(旣)정의된 key에 따라서 value 를 추출할 수 있으므로 미리 정의된 key 값이 아니라면 parser를 할 수도 없다.
