1. Transformer Recap
1.1 Vision Transformer
논문리뷰 : https://velog.io/@leejken530/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B06-ViT
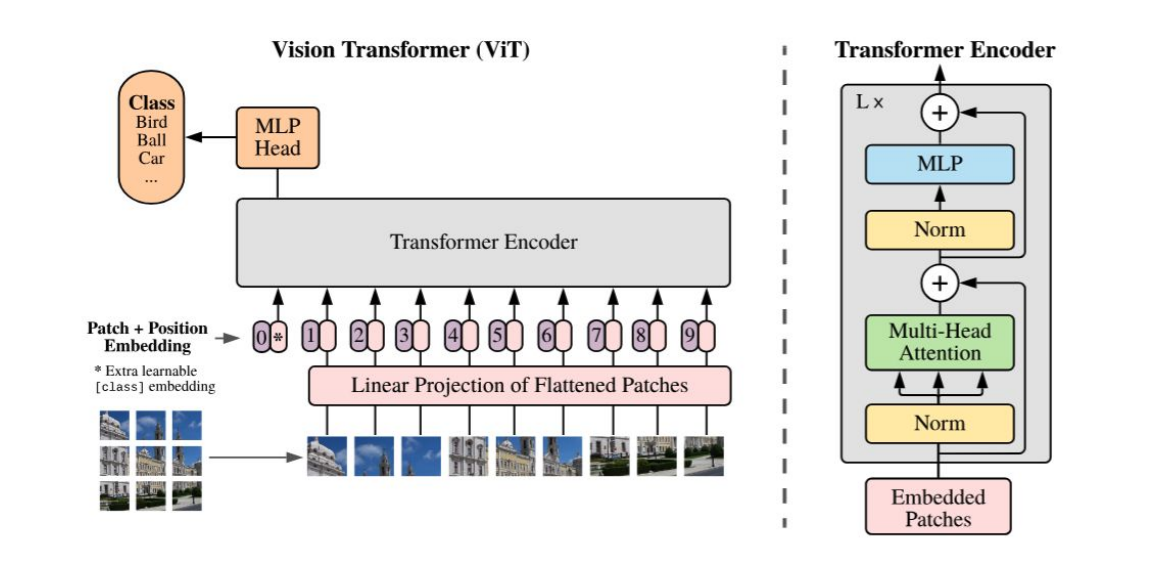
VisionTransformer의 특징
- 패치 임베딩: 이미지를 패치로 분할하고 각 패치를 선형 투영을 통해 임베딩 벡터로 변환합니다.
- 위치 임베딩: 패치 임베딩에 위치 정보를 유지하기 위해 위치 임베딩을 추가합니다.
- 트랜스포머 인코더: 트랜스포머 인코더는 멀티 헤드 셀프 어텐션과 MLP 블록의 교차 레이어로 구성됩니다.
- MLP 헤드: 트랜스포머 인코더의 출력을 이미지 표현으로 변환하고 분류를 수행합니다.
👉이러한 구성을 통해서 Vision transformer는 CNN과 달리 이미지 귀납적 편향이 거의 발생하지 않는다.(논문에서는 이렇게 설명한다."Inductive bias. We note that Vision Transformer has much less image-specific inductive bias than CNNs. In CNNs, locality, two-dimensional neighborhood structure, and translation equivariance are baked into each layer throughout the whole model. In ViT, only MLP layers are local and transla-tionally equivariant, while the self-attention layers are global. The two-dimensional neighborhood structure is used very sparingly: in the beginning of the model by cutting the image into patches and at fine-tuning time for adjusting the position embeddings for images of different resolution (as de-scribed below). Other than that, the position embeddings at initialization time carry no information about the 2D positions of the patches and all spatial relations between the patches have to be learned from scratch")
OCR = CV +NLP이다.
🤔Transformer를 OCR에 활용할 수 있을까?
1.2 Multimodal Transformer
논문 : https://arxiv.org/pdf/2206.06488
Self-attention의 global한 패턴을 이용해 각 입력을 fully connected graph로 처리가능
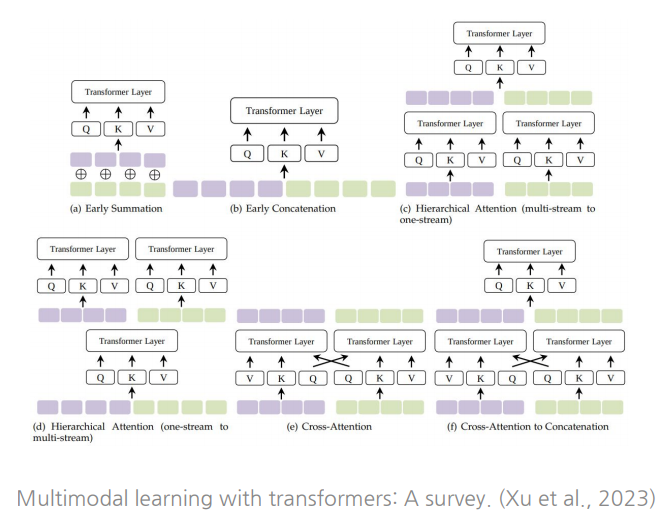
👉 각 modality input의 tokenization 과 embedding이 주어지면, 토근들의 임베딩 공간을 선택하면 된다. 전략으로 단순합산, 단순연결, 교차 attention 등 다양한 전략이 존재.
2. TrOCR(Transformer-based Optical Character Recognition with pre-trainedmodels.)
논문 : https://arxiv.org/abs/1704.03155v2
2.1 Introduction
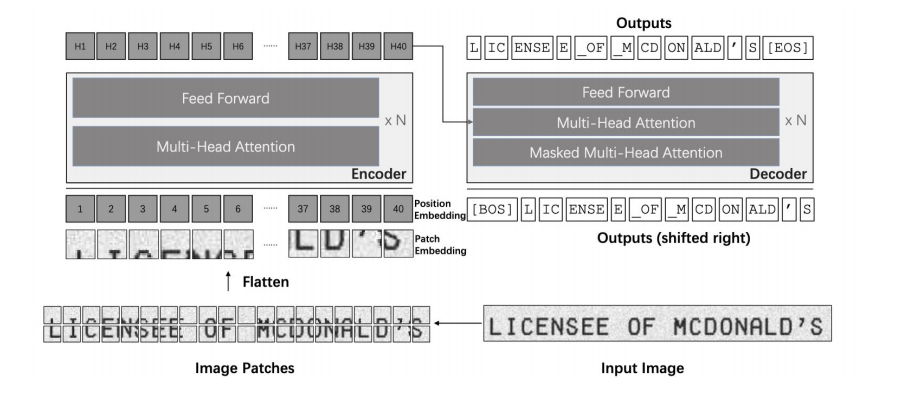
작동순서
1. 입력 이미지 (Input Image)
원본 이미지는 "LICENSEE OF MCDONALD'S"라는 문구가 포함된 이미지입니다. 이 이미지를 ViT 모델이 처리할 수 있는 형태로 변환하는 과정이 필요합니다.
2. 이미지 패치 분할 (Image Patches)
입력 이미지는 작은 패치들(patches)로 나뉩니다. 이 과정은 CNN의 필터와 유사한 방식으로, 이미지의 특정 구역을 자르는 역할을 합니다.
예를 들어, 각 글자 또는 이미지의 일부가 개별적인 패치로 분할됩니다. 그림에서 각 패치는 번호(1, 2, 3, ...)로 구분되어 있으며, 이를 통해 ViT가 이미지 내 개별적인 부분들을 인식할 수 있게 됩니다.
3. 패치 임베딩 (Patch Embedding)
패치들이 플래튼(flatten)되며 1차원 벡터 형태로 변환됩니다. 이렇게 변환된 각 패치는 Transformer 모델이 처리할 수 있는 형태의 입력 데이터가 됩니다.
각 패치에는 위치 임베딩(position embedding)이 추가됩니다. 위치 임베딩은 Transformer 모델이 순서나 위치 정보를 알 수 있도록 해주는 역할을 합니다. Transformer는 원래 순차적인 정보를 가지지 않기 때문에, 이미지 패치들이 어떤 순서에 위치하는지 알려주기 위해 위치 임베딩이 필요합니다.
4. 인코더 (Encoder)
인코더(Encoder)는 여러 층의 다중 헤드 어텐션(Multi-Head Attention)과 피드포워드 네트워크(Feed Forward)로 구성됩니다. 이 모듈은 패치들의 상호 관계와 특징을 학습합니다.
다중 헤드 어텐션을 통해 패치들 사이의 관계를 학습하며, 피드포워드 네트워크는 각 패치의 정보를 더욱 세밀하게 가공합니다.
인코더는 이미지 내 패치들 간의 관계와 패턴을 이해하고, 이를 기반으로 다음 단계에서 사용할 히든 벡터 를 생성합니다.
5. 디코더 (Decoder)
디코더는 Transformer의 인코더-디코더 구조를 따라 Masked Multi-Head Attention을 통해 입력된 패치를 바탕으로 텍스트를 생성합니다.
첫 번째 입력은 [BOS] (Begin of Sequence) 토큰이며, 각 출력 위치에는 이전 출력 결과가 입력으로 들어갑니다. 이는 다음 토큰을 예측하기 위해 이전 예측 결과를 활용하는 방식입니다.
디코더의 출력은 처음에는 [BOS], 그다음에는 "L", "IC", "ENSE" 등의 텍스트 조각들이 생성되며, 마지막에는 [EOS] (End of Sequence) 토큰이 생성됩니다. 이 과정을 통해 최종적으로 텍스트가 완성됩니다.
6. 출력 생성 (Outputs)
디코더의 최종 출력은 이미지에서 추출된 텍스트로, "LICENSEE OF MCDONALD'S" 문구가 출력됩니다.
출력은 디코더가 생성한 텍스트의 순서대로 나열되며, 입력 이미지에서 확인된 텍스트와 동일하게 재구성됩니다.
특징(Efficient and Accurate)
- Plug and Play : 거대한 데이터에 사전 학습된 image/text 트랜스포머 그대로 사용
- Easy to Implement : 이미지/OCR task에 사전 지식을 활용하는 특수한 전처리하지 않는다.
- 이미지 인코더와 텍스트 디코더를 동시에 학습시키는 것이 목표이다
- 여러 단계의 사전학습을 진행한다
-사전학습에선 다른 특성을 지닌 여러 벤치마크 데이터셋를 활용하고,사전학습에 쓰인 데이터의 총량은 10억쌍 가량이다 - 사전학습에 사용되는 데이터는 텍스트 전체영역을 찍은 이미지와 텍스트 쌍으로 이뤄져있다(x) ->TrOCR 은 text recognition 만을 목표로 하기 때문에, 텍스트 전체영역을 찍은 이미지를 text line 이라고 불리는 부분으로 구획하여 각각의 text line 과 정답 텍스트가 한 쌍이 됩니다. 그렇기에 데이터셋의 크기가 10억 쌍 수준을 달성할 수 있었습니다.
2.2 Architecture
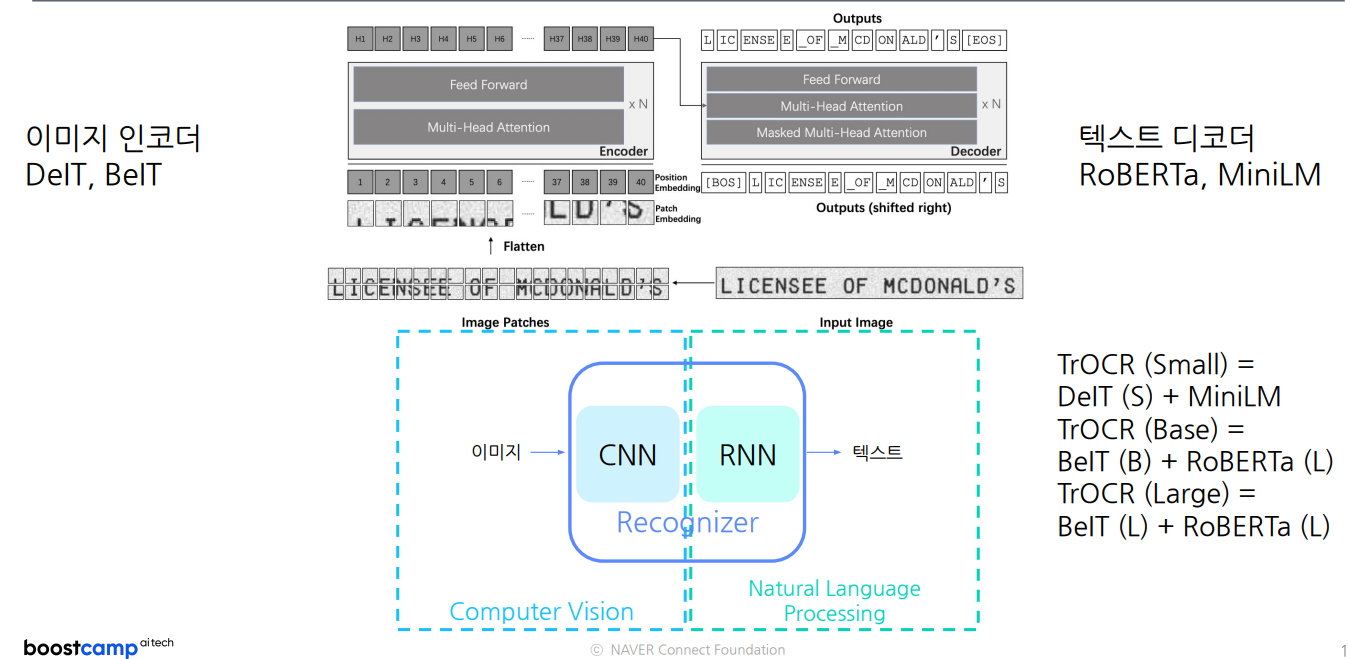
이미지인코더
- DeiT(Data-efficient Image Transformer): 데이터 효율성을 강조한 이미지 전용 Transformer 모델.(지식 증류(knowledge distillation) 기법을 사용)
- BeIT(BERT Pre-trained Image Transformer): BERT 방식의 사전 학습을 이미지에 적용한 모델, 마스크드 이미지 모델링 사용.(마스크드 이미지 모델링(masked image modeling) 방식을 사용하여 학습)
텍스트디코더
- RoBERTa(A Robustly Optimized BERT Pretraining Approach): BERT를 최적화하여 더 강력한 언어 모델, 동적 마스킹과 NSP 제거 등으로 성능 향상.(NSP를 제거하고, 마스크드 언어 모델링(MLM)에 집중하여 성능을 개선)
- MiniLM(Mini Language Model): 경량화된 언어 모델로, 작은 크기에도 높은 성능을 유지하여 리소스가 적은 환경에서 유리.
2.3 데이터중심사전학습
논문 :https://arxiv.org/abs/1605.05923
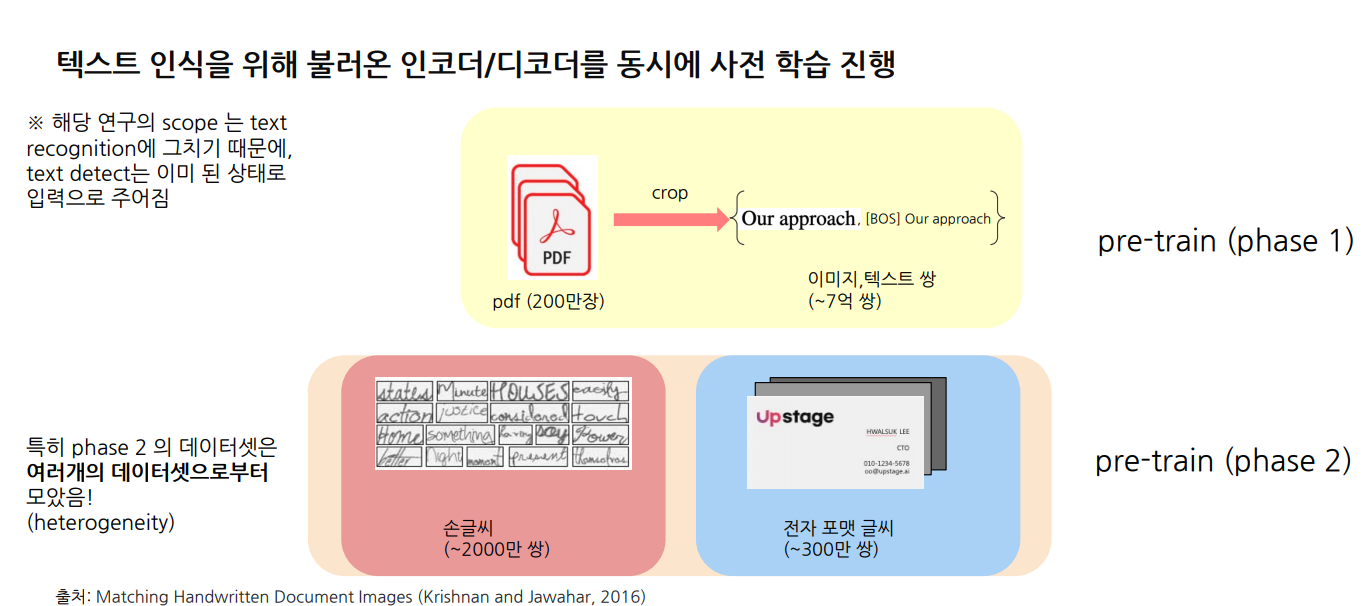
Phrase1: PDF 데이터 사전 학습
모델은 일반 인쇄 텍스트에 대해 기초적인 인식 능력학습
Phrase2: 손글씨 및 다양한 형식 데이터로 추가 학습
다양한 형식의 텍스트를 추가로 학습하여 비정형 데이터에 대한 인식 높임.
2.4 미세조정
2Tasks:Text Recognition Task & Scene Text Recognition

2.5 사전학습 및 미세조정시 데이터증강화
데이터 증강화는 있을 법한 예외상황을 모델링 할때 가장 효과적!!
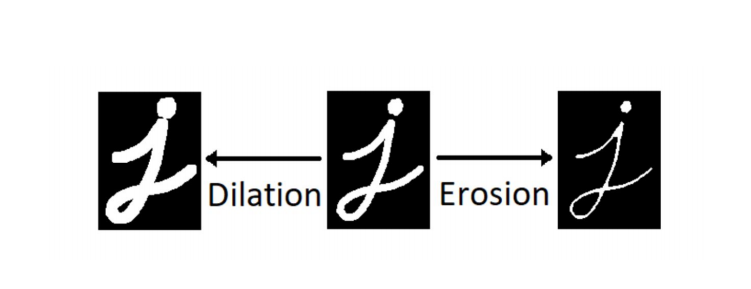
붓글씨 더 힘차게(Dilation) 하거나 얉게(Erosion) 하는 형식으로 Data augmentation함.
참고 Rand_augmentation: https://openaccess.thecvf.com/content_CVPRW_2020/papers/w40/Cubuk_Randaugment_Practical_Automated_Data_Augmentation_With_a_Reduced_Search_Space_CVPRW_2020_paper.pdf
2.6 후속연구-DTrOCR(Decoder-only Transformer-based Optical Character Recognition)
DTrOCR: Decoder-only Transformer for Optical Character Recognition
https://arxiv.org/abs/2308.15996
"""
This method uses a decoder-only Transformer to take advantage of a generative language model that is pre-trained on a large corpus. We examined whether a generative language model that has been successful in natural language processing can also be effective for text recognition in computer vision. Our experiments demonstrated that DTrOCR outperforms current state-of-the-art methods by a large margin in the recognition of printed, handwritten, and scene text in both English and Chinese.
"""
3. MATRN(Multi-modAl Text Recognition Network)
논문 : https://arxiv.org/abs/2111.15263
3.1 Introduction
Motivation
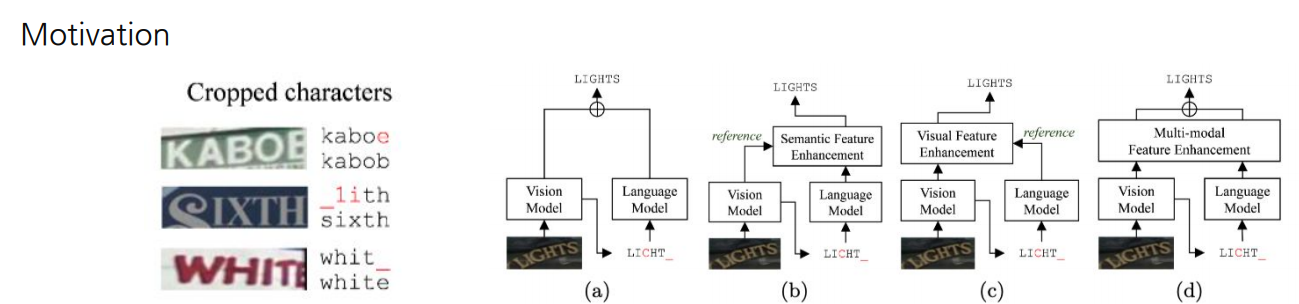
- 시각적 정보의 한계: 가려지거나 해상도가 낮은 이미지에 대해서 이미지로만 판단이 어렵다
- 멀티모달 정보의 fusion:어떻게 하면 두 modality를 정렬시키고,각각의 attention을 유지할수 있을까?
3.2 Architecture
Multimodal Scene Text Recognizer_3가지 부분으로 구성
① Feature Extractor:
Visual/language model,seed text generator
② Multi-modal feature enhancement
Attention layer에서 시각/글자정보 모두 self_attended
③ Output Fusion
시각정보는 다시 seed text generator를 통과 -> Gated Mechanisim
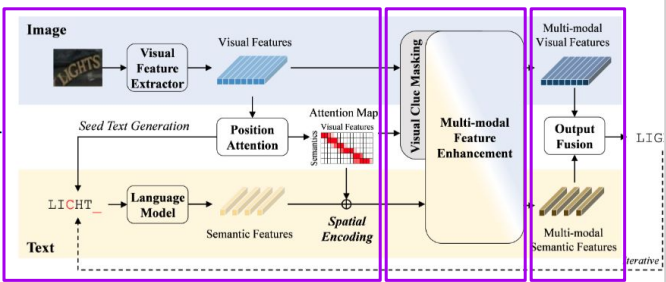
3.2.1 Visual/Semantic Feature Extraction
-
Visual Feature : ResNet과 Transformer 기반 모델 활용
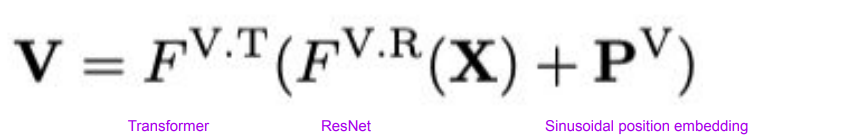
-
Seed Text Generation : visual feature 를 sequential 한 text로 전환

-
Semantic Feature: 4개의 transformer decoder block

- Aligning two modalities: visual feature의 spatial position을 semanticf feature와align

👉 spatial-semanticalignment를 이해하는 visual/semanticfeature를 얻었다!
이제 mulimodal feature enhancement &masking을 통해..
• 이 둘을 동시에 사용하게끔 하는 task정의
• 서로를 상호 고려하게끔 feature enhance
• 어떻게 둘을 합칠 것인지
3.2.2 Multi Modal Feature Enhancement & Masking
- Multimodal feature:2 transformer encoder blocks with 8heads and hidden size of 512
- Visual Clue Masking Strategy:하나의 character를 정하고,이에 상응하는 visual feature를 지움
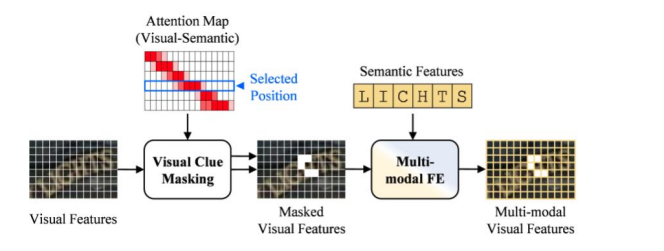
3.2.3 Final Output Fusion
Final Output Fusion:visualfeature를 sequential feature로 만든 뒤,gate mechanism을 적용
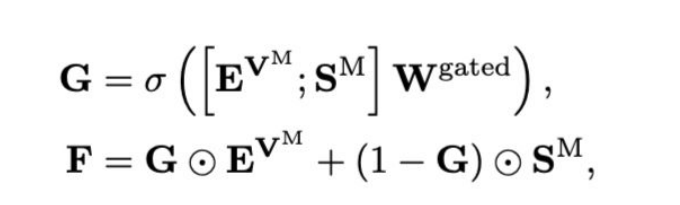
👉 최종적으로 linear layer 와 softmax를 F에 적용하여 character sequence Y(1)얻어냄.
Spatial Encoding to Semantics(SES)
SES는 공간정보를 의미적 정보로 변환하는 프로세스
- SES 는 text 와 image 정보의 alignment 을 나타내는 attention map 이다
- 시각 정보는 U-net 을 거쳐 더 refine 하여 사용한다
- SES에 spatial feature를 곱하면 semantic 의 embedding space 로 project 했다고 볼 수는 있으나, 논문에서는 여기에 learnable linear weight 를 곱하고, softmax 를 취해 estimated text 를 구하였습니다.
- SES의 row별 top K score를 사용하여 텍스트와 관련된 이미지의 위치 정보를 알 수 있다
- Seed text generation 과 visual clue masking 에 사용된다
참고자료
- EAST: An Efficient and Accurate Scene Text Detector
https://openaccess.thecvf.com/content_cvpr_2017/papers/Zhou_EAST_An_Efficient_CVPR_2017_paper.pdf
