
1. GRU의 개요
GRU는 RNN의 일종으로 LSTM보다 단순한 구조를 가지고 있다.
GRU는 두 가지 주요 게이트(업데이트 게이트, 리셋 게이트)를 사용한다.
- 업데이트 게이트(Update Gate): 현재 입력 정보와 이전 은닉 상태를 얼마나 많이 업데이트할지를 결정한다. (LSTM의 입력 게이트와 망각 게이트가 통합된 것으로 생각한다)
- 리셋 게이트(Reset Gate): 이전 은닉 상태를 얼마나 많이 리셋할지를 결정한다.
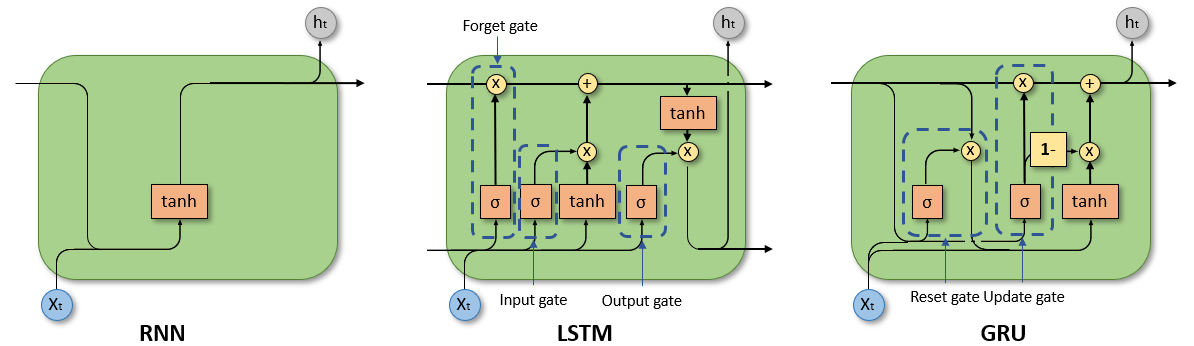
리셋 게이트는 과거의 데이터에 리셋 게이트의 값을 곱하는 방식으로 조정한다.
업데이트 게이트에서는 이전 데이터에 갱신 게이트의 값에서 1을 뺀 것을 곱한다. (이전 상태에서의 기억을 얼만큼의 비율로 이어받을 것인가?) 현재 시각에서의 기억과 이전 시각에서의 기억의 비율을 조정하여 더한 것을 해당 층의 출력으로 한다. 즉, GRU도 LSTM처럼 장기간에 걸쳐서 기억을 이어받을 수 있어 문맥을 파악할 수 있다.
2. 간단한 GRU의 구현
2-1. 훈련 데이터
데이터셋은 RNN, LSTM에서와 동일하다.
2-2. LSTM과 GRU 비교
Keras를 사용하여 LSTM, GRU를 구축한다.
GRU(뉴런 수, return_sequences=TRUE/FALSE)
아래 코드에서 LSTM과 GRU를 비교해본다.
from tensorflow.python.keras.models import Sequential
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, LSTM, GRU, Input
from tensorflow.keras.optimizers import SGD
n_in = 1 # 입력층의 뉴런 수
n_mid = 20 # 중간층의 뉴런 수
n_out = 1 # 출력층의 뉴런 수
# 비교를 위한 LSTM 모델
input_lstm = Input(shape=(n_rnn, n_in))
lstm_layer = LSTM(n_mid, return_sequences=True)(input_lstm)
output_lstm = Dense(n_out, activation='linear')(lstm_layer)
model_lstm = Model(inputs=input_lstm, outputs=output_lstm)
model_lstm.compile(loss='mean_squared_error', optimizer=SGD())
print(model_lstm.summary())
# GRU
input_gru = Input(shape=(n_rnn, n_in))
gru_layer = GRU(n_mid, return_sequences=True)(input_gru)
output_gru = Dense(n_out, activation='linear')(gru_layer)
model_gru = Model(inputs=input_gru, outputs=output_gru)
model_gru.compile(loss='mean_squared_error', optimizer=SGD())
print(model_gru.summary())
GRU쪽의 파라미터가 더 적다.
2-3. 학습
import time
epochs = 500
batch_size = 8
# LSTM
start_time = time.time()
history_lstm = model_lstm.fit(x, t, epochs = epochs, batch_size=batch_size, verbose=0)
print("LSTM 학습 시간 : ", time.time()-start_time)
# GRU
start_time = time.time()
history_gru = model_gru.fit(x, t, epochs = epochs, batch_size=batch_size, verbose=0)
print("GRU 학습 시간 : ", time.time()-start_time)실행결과
LSTM 학습 시간 : 10.303903579711914
GRU 학습 시간 : 9.481327772140503GRU의 파라미터 수가 더 적으므로 학습 시간도 짧다.
2-4. 학습의 추이
오차의 추이를 확인한다.
loss_lstm = history_lstm.history['loss']
loss_gru = history_gru.history['loss']
plt.plot(np.arange(len(loss_lstm)), loss_lstm, label='LSTM')
plt.plot(np.arange(len(loss_gru)), loss_gru, label='GRU')
plt.legend()
plt.show()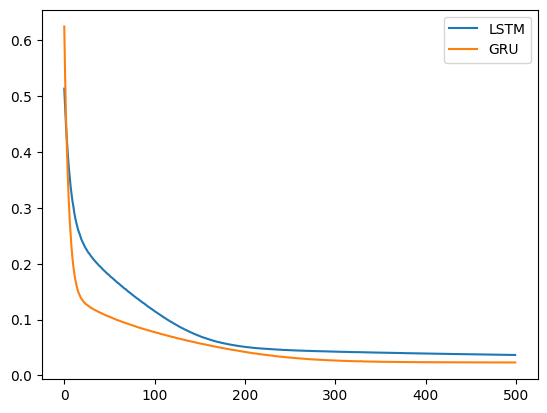
LSTM과 비교해서 GRU에서 더 빨리 수렴한다.
2-5. 학습한 모델의 사용
각각 학습한 모델을 사용하여 sin() 함수의 다음 값을 예측한다.
predicted_lstm = x[0].reshape(-1)
predicted_gru = x[0].reshape(-1)
for i in range(1, len(x)):
y_lstm = model_lstm.predict(predicted_lstm[-n_rnn:].reshape(1, n_rnn, 1))
predicted_lstm = np.append(predicted_lstm, y_lstm[0][n_rnn-1][0])
y_gru = model_gru.predict(predicted_gru[-n_rnn:].reshape(1, n_rnn, 1))
predicted_gru = np.append(predicted_gru, y_gru[0][n_rnn-1][0])
plt.plot(np.arange(len(sin_data)), sin_data, label='Training Data')
plt.plot(np.arange(len(predicted_lstm)), predicted_lstm, label='Predicted_LSTM')
plt.plot(np.arange(len(predicted_gru)), predicted_gru, label='Predicted_GRU')
plt.legend()
plt.show()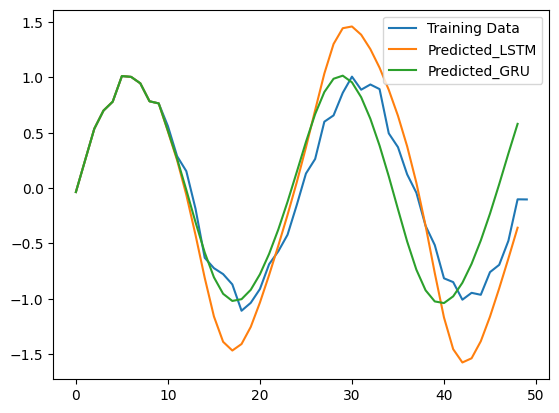
이 그래프에서는 GRU를 사용한 모델의 수렴이 더 빠르고 원래의 데이터에 근접하다. 이처럼, GRU는 파라미터 수가 적어서 1 epoch에 필요한 시간이 짧으면서도, LSTM보다 빠르게 수렴한다. 다만, LSTM은 복잡한 시계열에 대한 학습에 더 적합한 경우가 있으므로, 구분하여 더 적합한 모델을 사용하도록 선택하는 것이 적절하다.
