[딥러닝] 간단한 순환 신경망 (Recurrent Neural Network, RNN)

1. RNN의 개요
순환 신경망, 또는 재귀 신경망이라고 불리는 RNN은 Recurrent Neural Network의 약자로, 입력 데이터의 순서를 고려하여 학습하고, 이전 시점의 정보를 다음 시점의 입력으로 활용할 수 있기 때문에, 문맥을 읽고 판단할 수 있다. (시간에 따라 변화하는 시계열 데이터를 입력으로 다룰 수 있다.) 따라서 주로 문장, 음성, 영상을 다루는 데 사용된다.
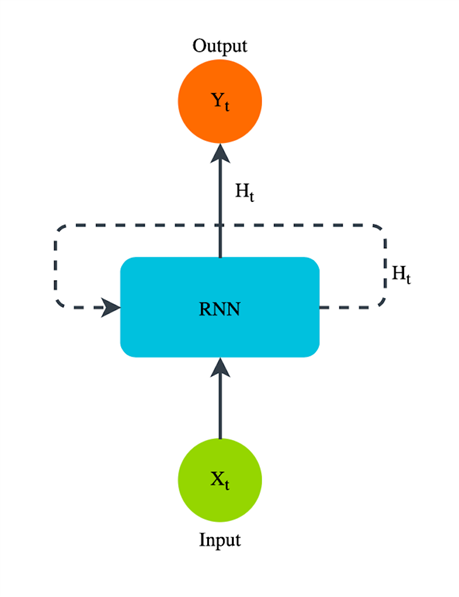
위 그림과 같이, RNN은 중간층에 대하여 계속 반복되는 형태이다. 이전 시각의 중간층과 연결되어 있기 때문에 시계열 데이터를 다룰 수 있다.
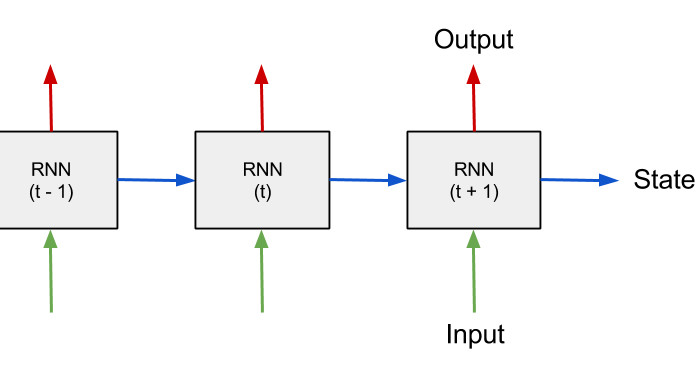
2. 간단한 RNN 구현하기
사인파 데이터를 생성하고 이를 이용해 RNN 모델을 학습시키고, 학습된 모델로 예측을 수행해보겠다.
2-1. 훈련용 데이터 작성하기
x_data는 부터 까지의 값을 가지는 등간격의 점sin_data는x_data에 해당하는 사인값에 약간의 노이즈를 추가한 값- 이 데이터는 RNN 모델의 학습 데이터로 사용
import numpy as np
import matplotlib.pyplot as plt
x_data = np.linspace(-2*np.pi, 2*np.pi)
sin_data = np.sin(x_data) + 0.1*np.random.randn(len(x_data))
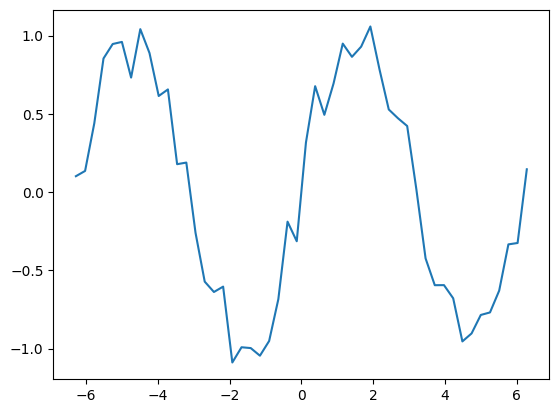
plt.plot(x_data, sin_data)
plt.show()사인파에 난수를 더한 형태로 훈련용 데이터를 만들었다.
n_rnn은 각 시계열의 길이n_sample은 전체 데이터에서 시계열 길이를 뺀 값으로, 시계열 샘플의 수를 의미x는 입력 데이터,t는 정답 데이터- 각 시계열 샘플은
sin_data의 연속된 10개의 데이터로 이루어지며, 정답은 입력보다 하나씩 뒤로 밀려서 구성됨 - Keras RNN의 입력 형식에 맞추기 위해
x와t를 (샘플 수, 시계열의 수, 입력층의 뉴런 수) 형태로 재구성함
n_rnn = 10 # 시계열의 수
n_sample = len(x_data) - n_rnn # 샘플의 수
x = np.zeros((n_sample, n_rnn)) # 입력
t = np.zeros((n_sample, n_rnn)) # 정답
for i in range(n_sample):
x[i] = sin_data[i:i+n_rnn]
t[i] = sin_data[i+1:i+n_rnn+1] # 시계열을 입력보다 1개 뒤로 비켜놓는다
x = x.reshape(n_sample, n_rnn, 1) # Keras에서 RNN은 입력을 (샘플 수, 시계열의 수, 입력층의 뉴런 수) 로 한다
print(x.shape)
t = t.reshape(n_sample, n_rnn, 1)
print(t.shape)실행결과
(40, 10, 1)
(40, 10, 1)2-2. RNN 구축
Keras에서 SimpleRNN() 함수로 구축할 수 있다.
SimpleRNN(뉴런 수, return_sequences=시계열을 전부 반환할지 여부)
return_sequences = True 로 하면 모든 시각에서 출력을 반환하고, False 는 마지막 출력만 반환한다.
Sequential모델을 사용하여 순차적으로 레이어를 쌓는다.SimpleRNN레이어를 추가하여 중간층의 뉴런 수를 20으로 설정하고, 입력 데이터의 형태를 지정한다.Dense레이어를 추가하여 최종 출력을 1차원으로 만든다.- 모델을 컴파일할 때 손실 함수로 평균 제곱 오차(mean_squared_error)를 사용하고, 최적화 알고리즘으로 SGD(Stochastic Gradient Descent)를 사용한다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN
n_in = 1 # 입력층의 뉴런 수
n_mid = 20 # 중간층의 뉴런 수
n_out = 1 # 출력층의 뉴런 수
model = Sequential()
model.add(SimpleRNN(n_mid, input_shape=(n_rnn, n_in), return_sequences=True)) # 간단한 RNN층
model.add(Dense(n_out, activation='linear')) # fully-connected layer
model.compile(loss="mean_squared_error", optimizer="sgd") # 오차는 제곱오차, 최적화 알고리즘은 SGD
print(model.summary())실행결과
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn (SimpleRNN) (None, 10, 20) 440
dense (Dense) (None, 10, 1) 21
=================================================================
Total params: 461 (1.80 KB)
Trainable params: 461 (1.80 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
None2-3. 학습
구축한 RNN 모델을 학습시킨다. validation_split 으로 훈련 데이터 중 얼만큼을 모델 평가에 사용할지를 지정한다. 이번에는 훈련 데이터의 10퍼센트를 평가에 사용한다.
- 학습 데이터
x와 정답 데이터t를 사용하여 20번의 에포크 동안 학습한다. - 배치 크기는 8로 설정하고, 데이터의 10%를 검증 데이터로 사용한다.
history = model.fit(x, t, epochs=20, batch_size=8, validation_split=0.1)2-4. 학습의 추이
- 학습 과정에서의 손실 값과 검증 손실 값을 시각화한다.
history.history에서 손실 값과 검증 손실 값을 가져와 각각 그래프로 표시한다.
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(np.arange(len(loss)), loss, label='loss')
plt.plot(np.arange(len(val_loss)), val_loss, label='val_loss')
plt.legend()
plt.show()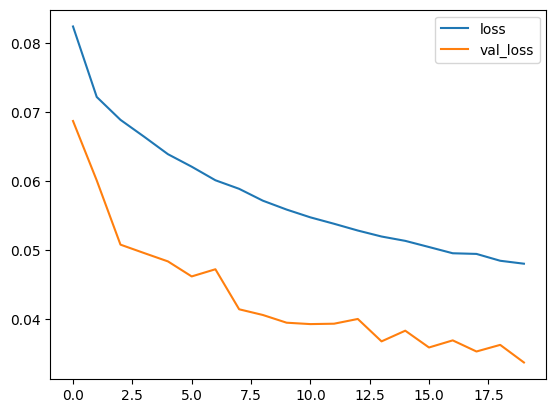
2-5. 학습한 모델의 사용
RNN 학습한 모델을 사용하여 sin() 함수의 다음 값을 예측한다. 최근 시각의 시계열 데이터를 사용하여 다음 시각의 값을 예측한다.
predicted는 초기 입력 데이터로 시작하여 반복적으로 모델을 사용해 다음 값을 예측하고, 예측된 값을predicted에 추가한다.- 마지막으로, 원래의 사인 데이터와 예측된 데이터를 그래프로 시각화하여 비교한다.
predicted = x[0].reshape(-1) # 처음의 입력. reshape(-1)으로 1차원의 벡터로 한다
for i in range(0, n_sample):
y = model.predict(predicted[-n_rnn:].reshape(1, n_rnn, 1)) # 최근 데이터를 사용하여 예측을 실시한다
predicted = np.append(predicted, y[0][n_rnn-1][0]) # 출력의 마지막 결과를 predicted에 추가한다
plt.plot(np.arange(len(sin_data)), sin_data, label='Training data') # 훈련에 사용된 데이터
plt.plot(np.arange(len(predicted)), predicted, label='Predicted data') # 예측된 데이터
plt.legend()
plt.show()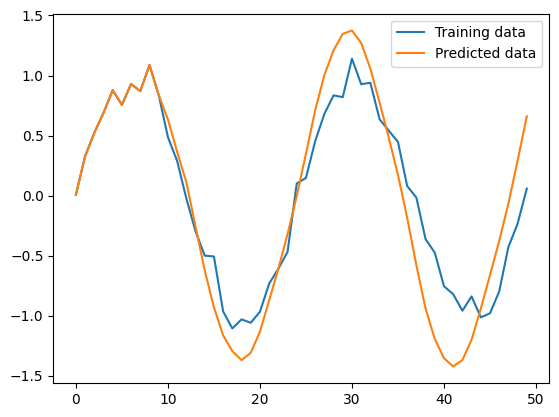
그래프 해석
- 초반부: 초기 몇 포인트에서 원래 데이터와 예측 데이터가 거의 일치한다. 모델이 처음 데이터를 잘 예측하고 있다.
- 중간부: 중간 부분에서는 예측 데이터가 원래 데이터와 조금씩 차이가 나는 것을 볼 수 있다. 일부 구간에서는 모델이 원래 데이터의 변동성을 잘 따라가지만, 노이즈에 의해 예측이 부정확해지는 구간도 있다.
- 후반부: 후반부로 갈수록 예측 데이터와 원래 데이터의 차이가 커지는 것을 볼 수 있다. 이는 시계열 데이터를 예측할 때, 시간이 지남에 따라 모델의 예측이 점점 더 부정확해질 수 있다는 일반적인 문제를 반영한다.
