[딥러닝] 합성곱 신경망 (Convolution Neural Network, CNN)

1. CNN의 개요
합성곱 신경망(Convolution Neural Network, CNN)은 사람의 시각이 모델이 되며, 특히 이미지 인식 분야에서 널리 사용된다.
CNN은 합성곱 층(convolutional layer), 풀링 층(pooling layer), 전결합 층(fully connected layer)으로 구성되어 있다.
-
합성곱 층(convolutional layer)
- 사람의 시각 시스템의 수용장과 유사한 역할을 한다.
- 이 층에서는 필터(커널)를 사용해 입력 이미지의 작은 영역을 처리한다.
- 각 필터는 특정한 특징(예: 수평선, 수직선, 모서리 등)을 감지하도록 학습된다.
-
풀링 층(pooling layer)
- 입력 이미지의 공간 크기를 줄이는 역할을 한다.(이미지의 중요한 특징을 유지하면서 크기를 줄인다.)
- 시각 피질에서 정보를 축약하는 것과 유사하다.
- 주로 최대 풀링(Max Pooling)이나 평균 풀링(Average Pooling)이 사용된다.
-
계층적 구조
- CNN은 여러 개의 합성곱 층과 풀링 층을 쌓아올려서 계층적으로 구성된다.
- 처음에는 간단한 특징을 감지하고, 점점 더 깊은 층으로 갈수록 복잡한 패턴과 객체를 인식한다.
- 이는 시각 피질이 단순한 특징을 감지하고, 복잡한 형태로 정보를 통합하는 방식과 유사하다.
-
전결합 층(fully connected layer)
- 사람의 시각 피질의 마지막 단계와 같다.
- 모든 정보를 종합하여 최종적으로 인식하거나 결정을 내리는 과정과 유사한 작업을 수행한다.
- 추출된 특징을 기반으로 분류 작업을 수행한다.
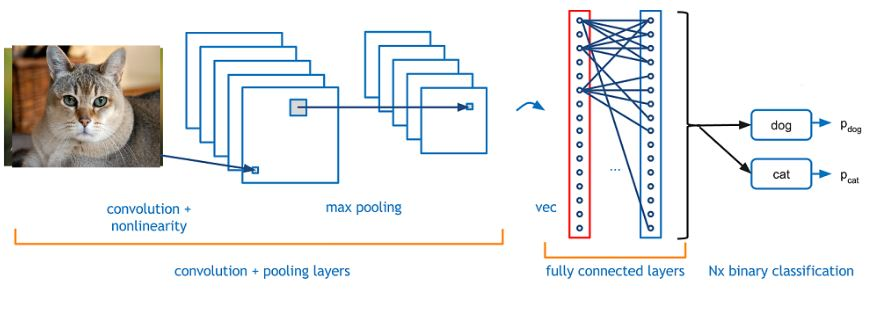
예시: 이미지 인식
위 그림에는 고양이 이미지를 인식하는 CNN이 있다.
- 초기 합성곱 층: 이미지의 작은 부분에서 선과 모서리 같은 기본적인 특징을 감지
- 중간 합성곱 층: 이러한 기본 특징들을 결합하여 더 복잡한 패턴(예: 귀, 눈, 코 등)을 인식
- 깊은 합성곱 층: 중간 패턴들을 결합하여 전체 고양이의 형태를 인식
- 전결합 층: 모든 정보를 종합하여 최종적으로 이미지가 고양이인지 아닌지 판단
2. 합성곱과 풀링
2-1. Convolutional Layer
위의 설명 내용을 다시 쓰면
- 합성곱 층(convolutional layer)
- 사람의 시각 시스템의 수용장과 유사한 역할을 한다.
- 이 층에서는 필터(커널)를 사용해 입력 이미지의 작은 영역을 처리한다.
- 각 필터는 특정한 특징(예: 수평선, 수직선, 모서리 등)을 감지하도록 학습된다.
합성곱 층에서는 이미지에 대하여 합성곱이라는 처리를 통해 이미지의 특징을 추출한다. 이미지는 픽셀로 이루어진 2차원 행렬로 표현되고, 필터(또는 커널)는 작은 크기의 행렬로, 일반적으로 3x3, 5x5 등의 크기를 가진다.
필터를 이미지 전체에 걸쳐 슬라이딩(이동) 시키면서 합성곱 연산을 수행한다. 필터가 이미지의 특정 위치에 놓일 때, 필터와 그 부분 이미지의 대응하는 값들을 곱하고 더한 결과가 새로운 특징 맵(feature map)의 해당 위치에 기록된다.
필터는 이미지의 특정 패턴을 감지하도록 학습된다. 예를 들어, 수직선을 감지하는 필터는 이미지에서 수직선이 있는 부분에서 높은 값을 출력한다.
필터가 이미지의 각 위치에서 수행하는 연산은 다음과 같다.
- 필터의 각 요소와 해당 이미지 부분의 픽셀 값을 곱한다.
- 곱한 값을 모두 더한다.
- 결과 값을 새로운 행렬(feature map)의 해당 위치에 저장한다.
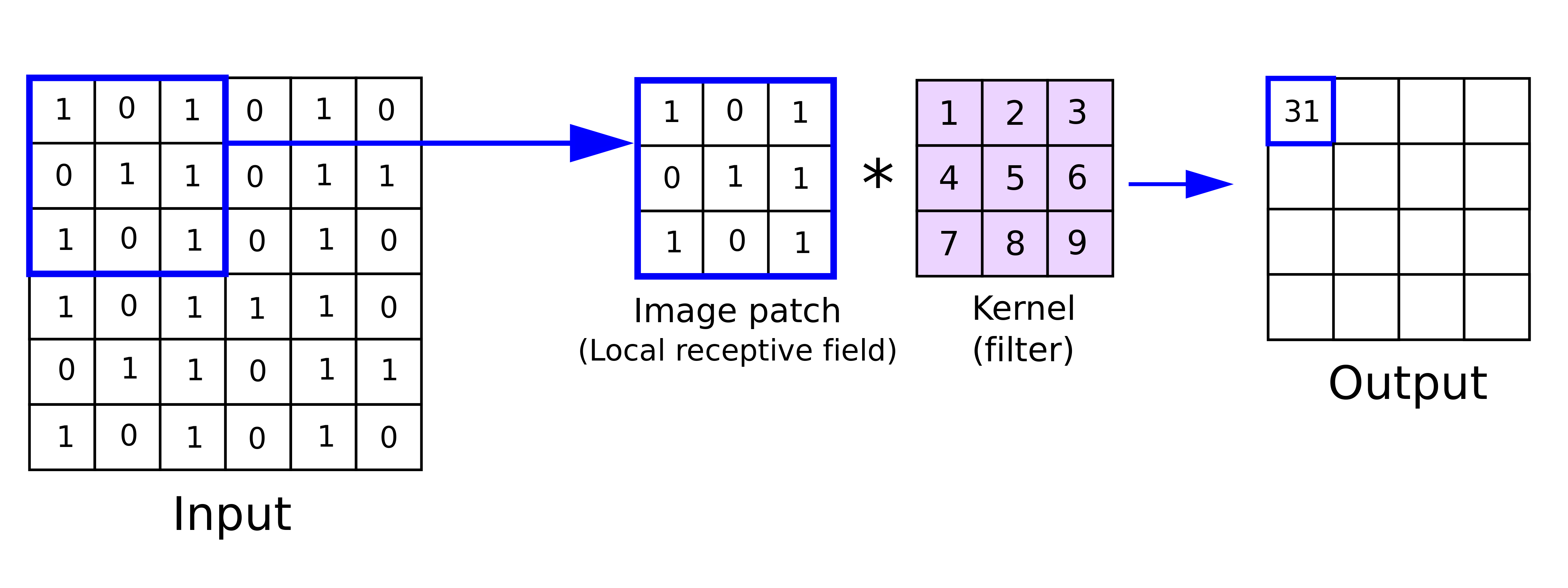
위 그림은 입력 이미지에 합성곱을 통해 출력 이미지를 추출하는 방법을 간략화하여 나타낸 것이다.
이 과정을 이미지 전체에 반복하면, 각 위치에서 필터에 의해 감지된 특징이 기록된 새로운 행렬(특징 맵)이 생성된다. 여러 개의 필터를 사용하면 이미지의 다양한 특징(예: 선, 모서리, 텍스처 등)을 추출할 수 있다. 이를 통해 합성곱 신경망은 입력 이미지의 중요한 시각적 정보를 효율적으로 학습한다.
2-2. Pooling Layer
풀링 층은 주로 feature map의 크기를 줄이고, 연산량을 감소시키며, 모델의 일반화 성능을 향상시키는 데 사용한다. 또한 모델의 복잡성을 감소시켜 과적합(overfitting)을 방지한다.
풀링의 종류
➀ Max Pooling
가장 일반적으로 사용되는 풀링 방식으로, 주어진 영역 내에서 가장 큰 값을 선택한다. 큰 값은 필터가 감지한 특정 패턴이나 특징이 강하게 나타나는 부분을 의미하므로, 이를 선택하여 중요한 정보를 유지할 수 있다.
예: 2x2 영역에서 최대 값을 선택하는 경우
입력:
1 3
2 4
출력:
4➁ Average Pooling
주어진 영역 내에서 평균 값을 계산하여 선택한다. 영역 내의 값들을 평균하여 전체적인 특징을 부드럽게 요약한다. Max Pooling에 비해 덜 강조된 정보를 유지하지만, 여전히 중요한 정보를 요약할 수 있다.
예: 2x2 영역에서 평균 값을 계산하는 경우
입력:
1 3
2 4
출력:
(1+3+2+4)/4 = 2.52-3. 패딩(Padding)
패딩 사용의 목적
➀ 출력 크기 조정
- 패딩을 사용하지 않으면, 합성곱 연산을 거치면서 특징 맵의 크기가 점점 줄어든다. 예를 들어, 5x5 이미지에 3x3 필터를 적용하면 출력 크기는 3x3이 된다.
- 패딩을 사용하면 입력과 출력의 크기를 같게 만들 수 있다. 이를 통해 CNN의 깊은 층에서도 충분한 공간 정보를 유지할 수 있다.
➁ 경계 정보 보존
- 패딩을 사용하지 않으면, 이미지의 가장자리 부분은 합성곱 연산에 덜 사용되므로 경계 부분의 정보가 손실될 수 있다.
- 패딩을 사용하면 이미지의 경계 부분도 필터의 중심 위치에 올 수 있어, 경계 정보가 보존된다.
- 필터의 중심이 입력 이미지의 가장자리를 벗어나지 않고 중앙에 위치할 수 있다. 즉 필터가 이미지 전체에 고르게 적용될 수 있다.
제로 패딩
CNN에서 주로 사용되는 패딩 방식이다. 입력 이미지의 주위에 값이 0인 픽셀을 배치한다.
예를 들어, 5x5 입력에 3x3 필터를 적용하고 패딩을 1로 설정하면, 출력 크기는 5x5가 된다.
입력 이미지 (패딩 추가) :
0 0 0 0 0
0 1 2 3 0
0 4 5 6 0
0 7 8 9 0
0 0 0 0 03x3 필터 적용된 출력 이미지 :
12 21 16
27 45 33
24 39 28출력 크기: 3x3 (입력과 동일)
2-4. 스트라이드(Stride)
스트라이드(stride)는 CNN에서 필터를 적용할 때의 이동 간격을 의미한다. 스트라이드는 필터가 입력 데이터 위를 얼마나 많이 이동하는지를 결정하며, 이는 출력 크기에 직접적인 영향을 미친다.
스트라이드의 역할
➀ 출력 크기 조절
- 스트라이드가 크면 출력 크기는 작아지고, 스트라이드가 작으면 출력 크기는 커진다.
- 스트라이드를 1로 설정하면 필터는 한 칸씩 이동하며 모든 위치에서 합성곱 연산을 수행한다.
- 스트라이드를 2로 설정하면 필터는 두 칸씩 이동하여 계산하고 출력 크기가 절반으로 줄어든다.
➁ 연산량 조절
- 스트라이드를 크게 설정하면 계산해야 할 합성곱 연산의 수가 줄어들어 연산량이 감소한다.
- 스트라이드를 작게 설정하면 더 많은 합성곱 연산을 수행하게 되어 연산량이 증가한다.
스트라이드와 출력 크기의 관계
출력 높이 = (입력 높이 - 필터 높이 + 2 * 패딩) / 스트라이드 + 1
출력 너비 = (입력 너비 - 필터 너비 + 2 * 패딩) / 스트라이드 + 13. im2col / col2im
im2col과 col2im은 합성곱 신경망(Convolutional Neural Network, CNN)에서 합성곱 연산을 효율적으로 수행하기 위해 자주 사용되는 테크닉이다. 반복 작업을 감소시킴으로써 CPU에서 연산을 가속화하거나, 메모리 효율성을 개선하기 위해 활용된다. 또한 행렬 연산은 병렬 처리에 매우 적합하므로, GPU를 이용한 연산에서 속도를 크게 향상시킬 수 있다.
im2col : image to column
col2im : column to image
3-1. im2col
im2col은 이미지를 행렬로 변환하는 과정이다. 합성곱 연산을 행렬 곱셈으로 변환하여 보다 효율적으로 계산할 수 있도록 한다.
im2col의 개념
예시
입력 이미지 :
1 2 3
4 5 6
7 8 92x2 필터, 스트라이드 1에 대해서 각 2x2 블록을 추출
블록 1: 1 2
4 5
블록 2: 2 3
5 6
블록 3: 4 5
7 8
블록 4: 5 6
8 9im2col 변환
1 2 4 5
2 3 5 6
4 5 7 8
5 6 8 9이때 행렬연산을 위해서 필터도 행렬로 변환한다.
예를 들어, 2x2 필터가 다음과 같다고 가정한다.
1 0
0 1필터를 1차원 벡터로 변환하면 이렇게 변한다.
[1 0 0 1]그러면 다음과 같이 이미지와 필터에 대하여 행렬연산이 가능해진다.
[1 2 4 5] [1]
[2 3 5 6] * [0] = [6 8 14 16]
[4 5 7 8] [0]
[5 6 8 9] [1]스트라이드가 2인 경우에는 입력 이미지를 필터가 이동하는 간격에 따라 행렬로 변환한다.
배치(batch), 채널(channel)
일반적으로 입력 이미지는 다음과 같은 형태를 갖는다.
- 배치 크기 (Batch Size): 한 번에 처리할 이미지의 개수. (보통 신경망은 학습 효율성을 위해 배치 단위로 입력을 처리함)
- 채널 수 (Channels): 각 이미지가 가지는 색상 채널 수. (흑백 이미지는 1개의 채널, RGB 이미지는 3개의 채널)
예시
배치 크기가 2이고 RGB 이미지(3개의 채널)가 있다.
(1) 입력 이미지 : 각 이미지는 3개의 채널을 가지고 있으며, 각 채널은 3x3 크기의 픽셀 값을 가지고 있다.
Image 1:
[[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
],
[
[10, 11, 12],
[13, 14, 15],
[16, 17, 18]
],
[
[19, 20, 21],
[22, 23, 24],
[25, 26, 27]
]]
Image 2:
[[
[28, 29, 30],
[31, 32, 33],
[34, 35, 36]
],
[
[37, 38, 39],
[40, 41, 42],
[43, 44, 45]
],
[
[46, 47, 48],
[49, 50, 51],
[52, 53, 54]
]](2) im2col 변환 : 2x2 필터를 사용하고 스트라이드가 1인 경우
Image 1 변환:
[[
[1, 2, 4, 5],
[2, 3, 5, 6],
[4, 5, 7, 8],
[5, 6, 8, 9],
[10, 11, 13, 14],
[11, 12, 14, 15],
[13, 14, 16, 17],
[14, 15, 17, 18],
[19, 20, 22, 23],
[20, 21, 23, 24],
[22, 23, 25, 26],
[23, 24, 26, 27]
]]
Image 2 변환:
[[
[28, 29, 31, 32],
[29, 30, 32, 33],
[31, 32, 34, 35],
[32, 33, 35, 36],
[37, 38, 40, 41],
[38, 39, 41, 42],
[40, 41, 43, 44],
[41, 42, 44, 45],
[46, 47, 49, 50],
[47, 48, 50, 51],
[49, 50, 52, 53],
[50, 51, 53, 54]
]](2') im2col 변환 : 2x2 필터를 사용하고 스트라이드가 2인 경우
스트라이드가 2인 경우, 필터를 적용할 때 각 블록은 2칸씩 이동하면서 추출된다.
Image 1 변환:
[[
[1, 2, 4, 5],
[4, 5, 7, 8],
[10, 11, 13, 14],
[13, 14, 16, 17],
[19, 20, 22, 23],
[22, 23, 25, 26]
]]
Image 2 변환:
[[
[28, 29, 31, 32],
[31, 32, 34, 35],
[37, 38, 40, 41],
[40, 41, 43, 44],
[46, 47, 49, 50],
[49, 50, 52, 53]
]]위와 같이 각 이미지가 하나의 행렬로 변환되어 배치 단위로 합쳐진다.
일반적으로는, CNN의 연산 효율성을 높이기 위해, 배치(batch)와 채널(channel)이 있는 경우에도 im2col 로 이미지를 단일 행렬로 변환해서 사용한다.
처음 입력 이미지는 4차원의 텐서로 표현된다. 이러한 4차원 텐서의 형태는 [배치 크기, 채널 수, 높이, 너비]로 정의된다. 입력 이미지가 4차원 텐서로 표현되면 각 이미지의 각 채널을 하나의 큰 행렬로 합쳐서 im2col 변환을 수행할 수 있다. 즉 im2col 변환을 통해 입력 이미지를 2차원 행렬로 평탄화(flatten)하여 처리하는 것이다.
예시
입력 이미지가 다음과 같은 4차원 형태를 갖는다고 할 때,
[
[ // 첫 번째 배치 (Batch 1)
[ // 첫 번째 채널 (Channel 1)
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
],
[ // 두 번째 채널 (Channel 2)
[10, 11, 12],
[13, 14, 15],
[16, 17, 18]
]
],
[ // 두 번째 배치 (Batch 2)
[ // 첫 번째 채널 (Channel 1)
[19, 20, 21],
[22, 23, 24],
[25, 26, 27]
],
[ // 두 번째 채널 (Channel 2)
[28, 29, 30],
[31, 32, 33],
[34, 35, 36]
]
]
]이때 이미지의 차원은
- 배치 크기 (Batch Size): 2
- 채널 수 (Channels): 2
- 높이 (Height): 3
- 너비 (Width): 3
이다.
이 이미지를 2차원으로 평탄화하면, 각 이미지는 하나의 행으로 표현된다. 따라서 전체 배치의 데이터는 다음과 같이 변환된다.
[
[1, 2, 3, 10, 11, 12], // 첫 번째 이미지의 평탄화된 형태
[4, 5, 6, 13, 14, 15],
[7, 8, 9, 16, 17, 18],
[19, 20, 21, 28, 29, 30], // 두 번째 이미지의 평탄화된 형태
[22, 23, 24, 31, 32, 33],
[25, 26, 27, 34, 35, 36]
]3-2. col2im
col2im은 im2col과는 반대로, 주어진 2차원 행렬을 입력 이미지의 원래 형태로 변환한다. CNN에서 역합성곱(Deconvolution) 또는 역합성곱(transposed convolution) 연산에서 주로 사용한다.
col2im 변환 과정
네트워크의 역방향 전파(backward propagation) 과정에서는 출력에서 입력으로의 기울기(gradient)를 계산해야 한다.(오류를 감소시키는 과정이므로) 이 때 col2im 변환은 이러한 기울기를 다시 입력 이미지의 형태로 되돌리는 역할을 한다.
예시
(1) 입력 이미지 : 다음과 같은 3x3 크기의 입력 이미지가 있다고 가정한다.
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
](2) im2col 변환 : 2x2 크기의 필터를 사용하고 스트라이드가 1인 경우, 이 입력 이미지를 im2col 변환하면 다음과 같은 4x4 크기의 행렬로 변환된다.
[
[1, 2, 4, 5],
[2, 3, 5, 6],
[4, 5, 7, 8],
[5, 6, 8, 9]
](3) col2im 변환
im2col변환된 행렬을 순회하면서 각 행렬 요소를 원래의 위치에 맞게 복원한다.- 원래 입력 이미지의 해당 위치에 대응하는 부분에 채워 넣는다.
원래 입력 이미지의 왼쪽 상단 영역:
[
[1, 2],
[4, 5]
]4. 합성곱의 구현
im2col 을 사용하여 합성곱을 구현한다.
4-1. im2col 구현
import numpy as np
def im2col(img, fit_h, fit_w): #입력 이미지, 필터 높이와 폭
img_h, img_w = img.shape
out_h = (img_h - fit_h) + 1 #출력 이미지 높이
out_w = (img_w - fit_w) + 1 #출력 이미지 폭
cols = np.zeros((fit_h * fit_w, out_h * out_w)) #생성되는 행렬의 크기
for h in range(out_h): # 출력 이미지의 각 위치를 순회
h_lim = h + fit_h # h : 필터가 걸리는 영역의 위쪽 끝, h_lim : 필터가 걸리는 영역의 아래쪽 끝
for w in range(out_w): # 출력 이미지의 각 위치를 순회
w_lim = w + fit_w # w : 필터가 걸리는 영역의 위쪽 끝, w_lim : 필터가 걸리는 영역의 아래쪽 끝
cols[:, h*out_w + w] = img[h:h_lim, w:w_lim].reshape(-1) # im2col 형식으로 변환된 값을 cols 행렬에 저장, reshape(-1)을 사용하여 1차원 배열로 평탄화
return cols위에서 정의한 im2col 함수를 사용하여 이미지를 행렬로 변환한다.
img = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]])
cols = im2col(img, 2, 2) #입력 이미지, 필터 높이와 폭을 전달
print(cols)실행결과
[[ 1. 2. 3. 5. 6. 7. 9. 10. 11.]
[ 2. 3. 4. 6. 7. 8. 10. 11. 12.]
[ 5. 6. 7. 9. 10. 11. 13. 14. 15.]
[ 6. 7. 8. 10. 11. 12. 14. 15. 16.]]배치 크기, 채널 수, 패딩, 스트라이드를 적용하여 일반화된 im2col 함수는 다음과 같다.
def im2col(images, fit_h, fit_w, stride, pad) :
# 입력 이미지 텐서의 차원
n_bt, n_ch, img_h, img_w = images.shape
# 출력 이미지의 높이와 너비
out_h = (img_h - fit_h + 2*pad) // stride + 1
out_w = (img_w - fit_w + 2*pad) // stride + 1
# 입력 이미지에 패딩을 추가
img_pad = np.pad(images, ((0, 0), (0, 0), (pad, pad), (pad, pad)), 'constant')
# 빈 cols 배열 생성
cols = np.zeros((n_bt, n_ch, fit_h, fit_w, out_h, out_w))
# im2col 형식으로 변환
for h in range(out_h):
h_lim = h * stride + fit_h
for w in range(out_w):
w_lim = w * stride + fit_w
cols[:, :, :, :, h, w] = img_pad[:, :, h * stride:h_lim, w * stride:w_lim] # img_pad에서 스트라이드를 적용하여 필터가 적용될 영역을 선택하고, 이를 cols에 할당
cols = cols.transpose(1,2,3,0,4,5).reshape(n_ch * fit_h * fit_w, n_bt * out_h * out_w) #cols의 축 순서를 바꾸어 im2col 형식으로 변환. 그리고 reshape을 사용하여 필터가 적용된 데이터를 1차원 벡터로 평탄화
return cols이때 transpose(1,2,3,0,4,5) 는 (n_ch, fit_h, fit_w, n_bt, out_h, out_w) 모양의 배열을 (fit_h, fit_w, n_bt, n_ch, out_h, out_w) 모양으로 바꾸는 것이다.
예시 이미지에 적용하면,
img = np.array([[[[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]]]])
cols = im2col(img, 2, 2, 1, 0) # 입력 이미지, 필터 높이와 폭, 스트라이드, 패딩
print(cols)실행결과
[[ 1. 2. 3. 5. 6. 7. 9. 10. 11.]
[ 2. 3. 4. 6. 7. 8. 10. 11. 12.]
[ 5. 6. 7. 9. 10. 11. 13. 14. 15.]
[ 6. 7. 8. 10. 11. 12. 14. 15. 16.]]4-2. 합성곱 구현
scikit-learn의 흑백 손글씨 이미지를 읽어들여 합성곱을 실시해본다.
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
image = digits.data[0].reshape(8, 8)
plt.imshow(image, cmap='gray')
plt.show()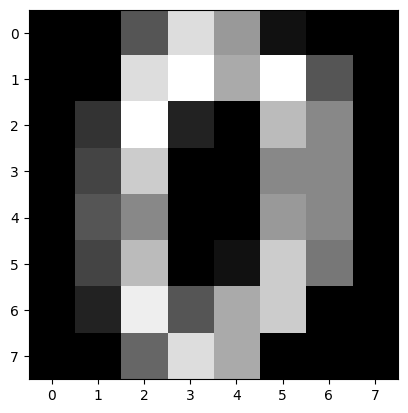
위에서 작성한 일반화된 im2col 코드를 사용할 것이므로 입력 형태에 맞게 차원을 추가하여 reshape할 것이다.
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
image = digits.data[0].reshape(1, 1, 8, 8)
# im2col 함수를 사용하여 이미지 변환
cols = im2col(image, 3, 3, 1, 0)
print(cols.shape) # 변환된 행렬의 형태 확인
# 변환된 이미지 출력
plt.figure(figsize=(5, 5))
plt.imshow(cols, cmap='gray')
plt.title('im2col Transformed Image')
plt.show()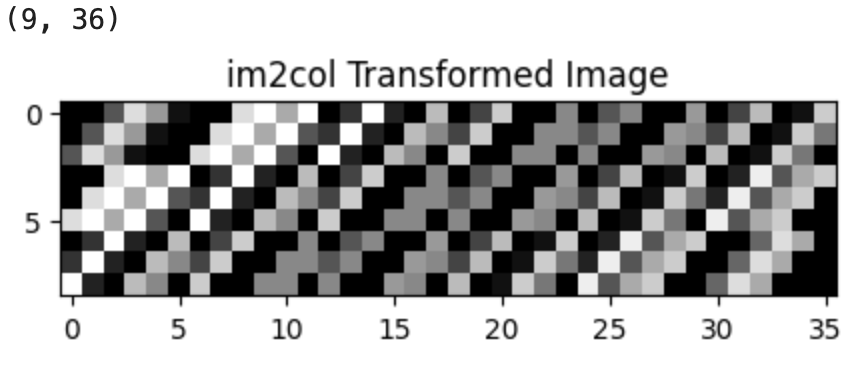
여기에 세로선을 강조하는 필터를 적용하려고 한다.
[[-1, 1, -1],
[-1, 1, -1],
[-1, 1, -1]]적용할 필터는 위와 같다.
google colab에 다음의 코드 셀을 추가한다.
# 필터 정의
filter = np.array([[-1, 1, -1],
[-1, 1, -1],
[-1, 1, -1]])
# 필터 적용
filtered = np.dot(filter.reshape(1, -1), cols)
# 변환된 이미지 출력
plt.figure(figsize=(5, 5))
plt.imshow(filtered.reshape(6, 6), cmap='gray') # im2col로 인해 변환된 이미지의 형태를 6x6으로 reshape하여 출력
plt.title('Filtered Image')
plt.show()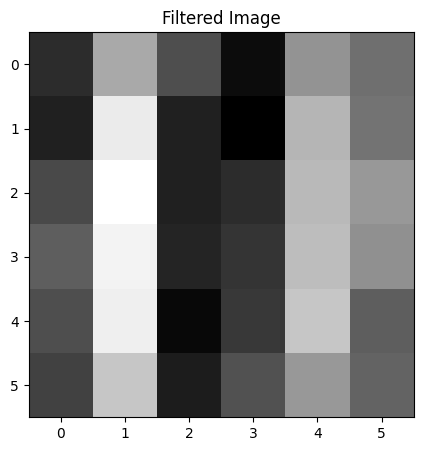
필터에 의해 세로선이 강조되었고(이미지의 특징이 추출되었고), 이미지 크기는 으로 작아졌다.
5. 풀링의 구현
im2col을 사용하여 풀링을 다음과 같이 구현했다.
# Max 풀링 함수 정의
def max_pooling(cols):
return np.max(cols, axis=0)
pool = 2
stride = 2
# im2col 함수를 사용하여 이미지 변환
cols = im2col(image, pool, pool, stride, 0)
# Max 풀링 적용
pooled = max_pooling(cols)
# 출력 이미지의 크기
pooled_h = (image.shape[2] - pool) // stride + 1
# . . . image의 차원 : 0 - 배치, 1 - 채널, 2 - 높이, 3 - 너비
pooled_w = (image.shape[3] - pool) // stride + 1
# 변환된 이미지 출력
plt.figure(figsize=(4, 4))
plt.imshow(pooled.reshape(pooled_h, pooled_w), cmap='gray')
plt.title('Max Pooling Result')
plt.show()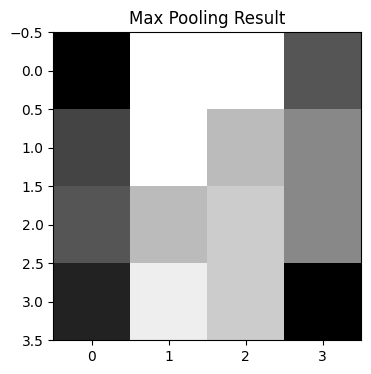
여기서는 각각 영역의 최댓값이 추출되어(max pooling) 이미지를 만들어냈다. 원본 이미지는 크기였으나 풀링 적용 후의 이미지는 크기가 되었다.
6. CNN의 구현
Keras를 사용하여 CNN을 구현한다. CIFAR-10 데이터셋을 사용해서 이미지 분류 모델을 훈련한다.
6-1. CIFAR-10
CIFAR-10은 컴퓨터 비전에서 널리 사용되는 데이터셋 중 하나로, 캐나다의 컴퓨터 과학자들이 수집한 이미지 데이터셋이다. 이 데이터셋은 Airplane, Automobile, Bird, Cat, Deer, Dog, Frog, Horse, Ship, Truck의 10개의 클래스로 구성된 32x32 크기의 컬러 이미지로 구성되어 있다. 각 클래스마다 6,000장의 이미지가 포함되어 총 60,000장의 이미지로 구성되어 있다. 각 이미지는 RGB 채널을 사용하여 총 3개의 채널을 가지며, 총 50,000장의 훈련 이미지와 10,000장의 테스트 이미지로 나누어져 있다.
이미지 처리에 시간이 걸리므로, 모델 훈련시 GPU 사용을 권장한다.
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.datasets import cifar10
(x_train, t_train), (x_test, t_test) = cifar10.load_data()
print(f"Image size : {x_train[0].shape}")
cifar10_labels = np.array(["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"])
n_image = 25 # 표시할 이미지 수
rand_idx = np.random.randint(0, len(x_train), n_image)
plt.figure(figsize=(10, 10))
for i in range(n_image):
plt.subplot(5, 5, i+1)
plt.imshow(x_train[rand_idx[i]])
label = cifar10_labels[t_train[rand_idx[i]]]
plt.title(label)
plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False) # 라벨 및 메모리 미표시
plt.show()
다음 단계로, 각 이미지에 붙은 라벨을 one-hot encoding 한다. 앞서 말했듯, CIFAR-10 데이터셋에서 각 이미지는 10개의 클래스로 분류된다. 각 클래스는 고유한 정수 라벨(0부터 9)을 가지는데, One-hot 인코딩을 통해 이 정수 라벨을 길이 10의 이진 벡터로 변환할 수 있다.
예를 들어, 클래스 3 (Cat)은 [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]로 인코딩하는 것이다.
batch_size = 32 # 배치 크기 : 한 번의 훈련 단계에서 처리할 샘플의 수
n_classes = 10 # 10개의 클래스로 분류
epochs = 20 # 에포크 수 : 반복 학습 횟수
# one-hot 표현으로 변환
t_train = tf.keras.utils.to_categorical(t_train, n_classes)
t_test = tf.keras.utils.to_categorical(t_test, n_classes)
print(t_train[:10])실행결과
[[0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]]6-2. 모델 구축
구축할 CNN 모델의 계층 구조는 다음과 같다.

Keras의 합성곱층은 Conv2D() 함수로 구현한다.
Ckeras.layers.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid', activation=None, ...)Conv2D() 함수의 주요 인자들은 다음과 같다.
-
filters: 정수, 출력 공간의 차원(즉, 출력 필터의 수).- ex)
filters=32일 경우, 32개의 필터를 사용하여 입력 이미지에 합성곱 연산을 수행한다.
- ex)
-
kernel_size: 정수 또는 (정수, 정수), 합성곱 커널의 높이와 너비.- ex)
kernel_size=(3, 3)는 3x3 크기의 필터를 사용한다.
- ex)
-
strides: 정수 또는 (정수, 정수), 합성곱의 스트라이드 길이. 기본값은 (1, 1).- ex)
strides=(2, 2)는 필터가 2칸씩 움직이면서 합성곱 연산을 수행한다.
- ex)
-
padding:"valid"또는"same"(패딩 방식)"valid": 패딩을 하지 않음. 필터가 이미지 가장자리까지 도달하지 않음."same": 입력과 동일한 크기를 유지하도록 패딩을 추가함.
-
activation: 활성화 함수 (예:relu,sigmoid,softmax,tanh등).- ex)
activation='relu'는 ReLU 활성화 함수를 사용함.
- ex)
-
input_shape: 첫 번째 레이어에만 사용되는 인자, 입력의 형태.- ex)
input_shape=(32, 32, 3)는 32x32 크기의 RGB 이미지 데이터를 입력으로 받는다.
- ex)
다음으로 Max Pooling Layer는 MaxPooling2D() 함수에 의해 구현된다.
keras.layers.MaxPooling2D(pool_size=(2, 2), strides=None, padding='valid', ...)MaxPooling2D() 함수의 주요 인자들은 다음과 같다.
- pool_size: 정수 또는 (정수, 정수), 풀링 윈도우의 크기. 기본값은 (2, 2).
- 예: pool_size=(2, 2)는 2x2 크기의 풀링 윈도우를 사용한다는 의미
- strides: 정수 또는 (정수, 정수), 풀링 윈도우의 스트라이드. 기본값은 None이며, 이 경우 strides는 pool_size와 동일하게 설정.
- 예: strides=(2, 2)는 풀링 윈도우가 2칸씩 움직인다는 의미
- padding: "valid" 또는 "same", 패딩 방식.
- "valid": 패딩을 하지 않음. 풀링 윈도우가 이미지 가장자리까지 도달하지 않음.
- "same": 입력과 동일한 크기를 유지하도록 패딩을 추가
이것을 사용하여 CNN 모델을 다음과 같이 구축해보았다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, Activation
from tensorflow.keras.optimizers import Adam
model = Sequential() # 레이어를 순차적으로 쌓아 올린다.
## Convolution Block 1
# 입력 이미지에 대해 32개의 필터를 사용하여 3x3 커널 크기로 합성곱을 수행한다.
model.add(Conv2D(32, (3, 3), padding='same', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2))) # 2x2 최대 풀링을 적용하여 특성 맵의 크기를 절반으로 줄임
## Convolution Block 2
# 64개의 필터를 사용하여 3x3 크기로 합성곱을 수행
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
## Fully Connected Layer
model.add(Flatten()) # 1차원 배열로 변환
model.add(Dense(256)) # 256개의 뉴런을 가진 Fully Connected Layer 추가
model.add(Activation('relu'))
model.add(Dropout(0.5)) # 50%의 드롭아웃을 적용하여 과적합을 방지
model.add(Dense(n_classes)) # CIFAR-10 데이터셋의 클래스 수 (10개)에 맞게 마지막 Dense 층을 추가
model.add(Activation('softmax')) # 소프트맥스 활성화 함수를 사용하여 클래스 확률을 출력
## 컴파일
# 최적화 알고리즘에 Adam, 손실 함수에 교차 엔트로피를 지정하여 컴파일
model.compile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy'])
# - Adam 최적화 알고리즘을 사용
# - 손실 함수로 categorical crossentropy를 사용
# - 평가 메트릭 : 정확도
model.summary()Dropout(0.5) 레이어는 첫 번째 Dense 레이어와 두 번째 Dense 레이어 사이에 추가되어, 첫 번째 Dense 레이어의 뉴런 중 50%를 무작위로 비활성화한다. 이렇게 하면 모델의 일반화 능력이 향상되어 훈련 데이터에 대한 과적합을 방지하고 테스트 데이터에 대한 성능이 개선될 수 있다.
실행결과
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 32, 32, 32) 896
activation_5 (Activation) (None, 32, 32, 32) 0
conv2d_5 (Conv2D) (None, 30, 30, 32) 9248
activation_6 (Activation) (None, 30, 30, 32) 0
max_pooling2d_2 (MaxPoolin (None, 15, 15, 32) 0
g2D)
conv2d_6 (Conv2D) (None, 15, 15, 64) 18496
activation_7 (Activation) (None, 15, 15, 64) 0
conv2d_7 (Conv2D) (None, 13, 13, 64) 36928
activation_8 (Activation) (None, 13, 13, 64) 0
max_pooling2d_3 (MaxPoolin (None, 6, 6, 64) 0
g2D)
flatten_1 (Flatten) (None, 2304) 0
dense_1 (Dense) (None, 256) 590080
activation_9 (Activation) (None, 256) 0
dropout_1 (Dropout) (None, 256) 0
dense_2 (Dense) (None, 10) 2570
activation_10 (Activation) (None, 10) 0
=================================================================
Total params: 658218 (2.51 MB)
Trainable params: 658218 (2.51 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________6-3. 모델 학습
CNN 모델을 훈련시켜보자. 하드웨어 가속기로는 GPU를 사용한다.
x_train = x_train / 255 # [0, 1] 범위에 넣는다
x_test = x_test / 255
# 훈련 데이터를 사용해 모델 훈련
history = model.fit(x_train, t_train, batch_size=batch_size, epochs=epochs, validation_data=(x_test, t_test))실행결과
Epoch 1/20
1563/1563 [==============================] - 18s 7ms/step - loss: 1.5045 - accuracy: 0.4519 - val_loss: 1.1478 - val_accuracy: 0.5927
Epoch 2/20
1563/1563 [==============================] - 9s 5ms/step - loss: 1.0924 - accuracy: 0.6137 - val_loss: 0.9723 - val_accuracy: 0.6630
Epoch 3/20
1563/1563 [==============================] - 10s 6ms/step - loss: 0.9320 - accuracy: 0.6760 - val_loss: 0.9140 - val_accuracy: 0.6831
Epoch 4/20
1563/1563 [==============================] - 9s 6ms/step - loss: 0.8337 - accuracy: 0.7085 - val_loss: 0.7804 - val_accuracy: 0.7290
Epoch 5/20
1563/1563 [==============================] - 9s 6ms/step - loss: 0.7465 - accuracy: 0.7396 - val_loss: 0.7447 - val_accuracy: 0.7479
Epoch 6/20
1563/1563 [==============================] - 9s 6ms/step - loss: 0.6822 - accuracy: 0.7583 - val_loss: 0.7962 - val_accuracy: 0.7377
Epoch 7/20
1563/1563 [==============================] - 10s 6ms/step - loss: 0.6289 - accuracy: 0.7801 - val_loss: 0.8464 - val_accuracy: 0.7261
Epoch 8/20
1563/1563 [==============================] - 9s 6ms/step - loss: 0.5812 - accuracy: 0.7959 - val_loss: 0.7522 - val_accuracy: 0.7552
Epoch 9/20
1563/1563 [==============================] - 9s 6ms/step - loss: 0.5405 - accuracy: 0.8099 - val_loss: 0.7603 - val_accuracy: 0.7598
Epoch 10/20
1563/1563 [==============================] - 10s 6ms/step - loss: 0.4983 - accuracy: 0.8232 - val_loss: 0.7500 - val_accuracy: 0.7607
Epoch 11/20
1563/1563 [==============================] - 9s 6ms/step - loss: 0.4711 - accuracy: 0.8332 - val_loss: 0.7786 - val_accuracy: 0.7652
Epoch 12/20
1563/1563 [==============================] - 9s 5ms/step - loss: 0.4395 - accuracy: 0.8423 - val_loss: 0.8000 - val_accuracy: 0.7627
Epoch 13/20
1563/1563 [==============================] - 10s 6ms/step - loss: 0.4164 - accuracy: 0.8513 - val_loss: 0.8048 - val_accuracy: 0.7637
Epoch 14/20
1563/1563 [==============================] - 10s 6ms/step - loss: 0.3896 - accuracy: 0.8600 - val_loss: 0.8722 - val_accuracy: 0.7527
Epoch 15/20
1563/1563 [==============================] - 8s 5ms/step - loss: 0.3677 - accuracy: 0.8690 - val_loss: 0.8400 - val_accuracy: 0.7502
Epoch 16/20
1563/1563 [==============================] - 9s 6ms/step - loss: 0.3546 - accuracy: 0.8696 - val_loss: 0.8939 - val_accuracy: 0.7654
Epoch 17/20
1563/1563 [==============================] - 9s 6ms/step - loss: 0.3417 - accuracy: 0.8767 - val_loss: 0.8913 - val_accuracy: 0.7594
Epoch 18/20
1563/1563 [==============================] - 8s 5ms/step - loss: 0.3235 - accuracy: 0.8836 - val_loss: 0.9968 - val_accuracy: 0.7496
Epoch 19/20
1563/1563 [==============================] - 9s 6ms/step - loss: 0.3099 - accuracy: 0.8876 - val_loss: 0.9405 - val_accuracy: 0.7609
Epoch 20/20
1563/1563 [==============================] - 10s 7ms/step - loss: 0.3021 - accuracy: 0.8921 - val_loss: 0.9970 - val_accuracy: 0.7532history 로 학습의 추이를 확인하자.
import matplotlib.pyplot as plt
train_loss = history.history['loss']
train_acc = history.history['accuracy']
val_loss = history.history['val_loss']
val_acc = history.history['val_accuracy']
# 오차 표시
plt.plot(np.arange(len(train_loss)), train_loss, label='Train Loss')
plt.plot(np.arange(len(val_loss)), val_loss, label='Validation Loss')
plt.title('Train and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
# 정밀도 표시
plt.plot(np.arange(len(train_acc)), train_acc, label='Train Accuracy')
plt.plot(np.arange(len(val_acc)), val_acc, label='Validation Accuracy')
plt.title('Train and Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()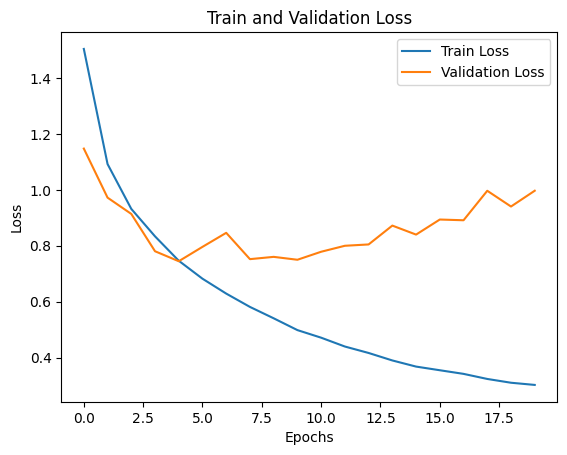
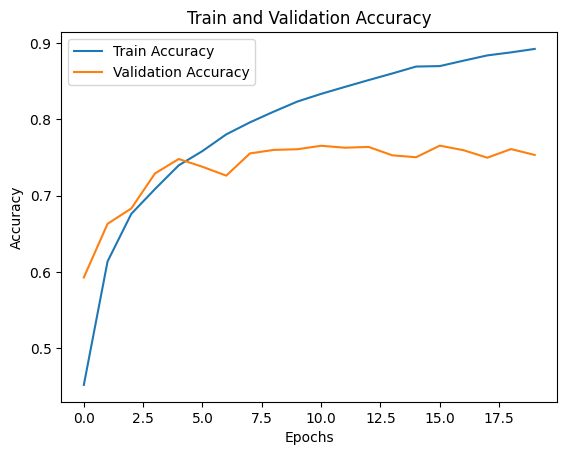
그래프를 확인해보면, 테스트 데이터의 오차는 그다지 줄어들지 않고 있다. 모델이 훈련 데이터에 overfitting하고 있는 것으로 보인다. 정확도 또한 마찬가지로 일정 이상 증가하지 않는 모습을 보인다.
이러한 overfitting 문제를 해결하기 위해 데이터 확장을 구현하도록 한다.
7. 데이터 확장
학습 데이터가 적으면 overfitting이 발생하고 일반화 성능이 저하된다. 그러나 학습 데이터를 더 모으는 데에는 시간과 비용이 많이 든다. 이러한 문제에 대한 해결 방법으로 데이터 확장을 제안한다. 데이터 확장은, 이미지에 반전, 확대, 축소 등 변환을 가하여 이미지의 수를 늘려 데이터 부족 문제를 해결하는 방법이다.
7-1. 데이터 확장 구현 - 이미지 회전
데이터 확장에는 Keras의 ImageDataGenerator() 함수를 사용한다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
def show_images(image, generator):
# 이미지 shape 확인
channel, height, width = image.shape
image = image.reshape(1, channel, height, width) # 이미지를 배치 형태로 변환하여 generator에 입력
gen = generator.flow(image, batch_size=1) # generator를 사용해 변환된 이미지 생성
plt.figure(figsize=(9, 9))
for i in range(9):
gen_img = gen.next()
plt.subplot(3, 3, i + 1)
gen_img = np.squeeze(gen_img) # 배치 형태의 이미지를 다시 차원 축소
plt.imshow(gen_img)
plt.axis('off')
plt.show()
image = x_train[152]
plt.imshow(image)
plt.title('Original Image')
plt.axis('off')
plt.show()
# 이미지를 회전하는 generator 생성
generator = ImageDataGenerator(rotation_range=20)
# 이미지 출력
show_images(image, generator)실행결과


7-2. 다양한 데이터 확장
7-2-1. 수평 방향 평행이동
# 이미지 수평 이동
generator = ImageDataGenerator(width_shift_range=0.5)
show_images(image, generator)
7-2-2. 수직 방향 평행이동
# 이미지 수직 이동
generator = ImageDataGenerator(height_shift_range=0.3)
show_images(image, generator)
왜 두개가 반대로 작동하는건지 모르겠다
7-2-3. Shear
generator = ImageDataGenerator(shear_range=20)
show_images(image, generator)
7-2-4. Zoom
generator = ImageDataGenerator(zoom_range=0.3)
show_images(image, generator)
7-2-5. flip
generator = ImageDataGenerator(horizontal_flip=True, vertical_flip=True)
show_images(image, generator)
7-3. 데이터 확장 적용한 학습
x_train = x_train / 255
x_test = x_test / 255
generator = ImageDataGenerator(rotation_range=20, horizontal_flip=True, vertical_flip=True)
generator.fit(x_train)
history = model.fit(generator.flow(x_train, t_train, batch_size=batch_size), epochs=epochs, validation_data=(x_test, t_test))학습의 추이를 history 를 통해 확인한다.
import matplotlib.pyplot as plt
train_loss = history.history['loss']
train_acc = history.history['accuracy']
val_loss = history.history['val_loss']
val_acc = history.history['val_accuracy']
plt.plot(np.arange(len(train_loss)), train_loss, label='Train Loss')
plt.plot(np.arange(len(val_loss)), val_loss, label='Validation Loss')
plt.title('Train and Validation Loss')
plt.legend()
plt.show()
plt.plot(np.arange(len(train_acc)), train_acc, label='Train Accuracy')
plt.plot(np.arange(len(val_acc)), val_acc, label='Validation Accuracy')
plt.title('Train and Validation Accuracy')
plt.legend()
plt.show()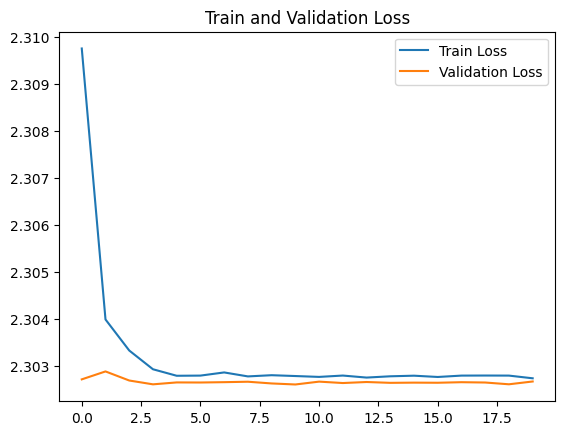
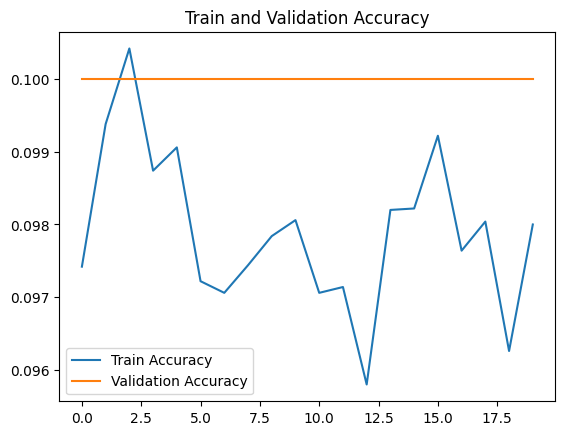
충격 받음
Test Loss: 2.3027
Test Accuracy: 0.1000이정도면 뭔가 잘못됐음
