분포의 모수가 상수가 아니라 모수도 어떤 분포를 따른다고 봄.
=> f(x,θ)=f(x∣θ)h(θ)
-
Joint pdf of (X,θ)
g(x1,...,xn,θ)=∏if(xi∣θ)h(θ)=L(θ;x)h(θ)
-
Marginal pdf of X
gX(x)=∫g(x,θ)dθ
-
Posterior distriburion of θ given the sample
k(θ∣x)=gX(x)g(x,θ)
ex1) Xi∣θ∼iidPoisson(θ),θ∼Gamma(α,β) (α,β:known)
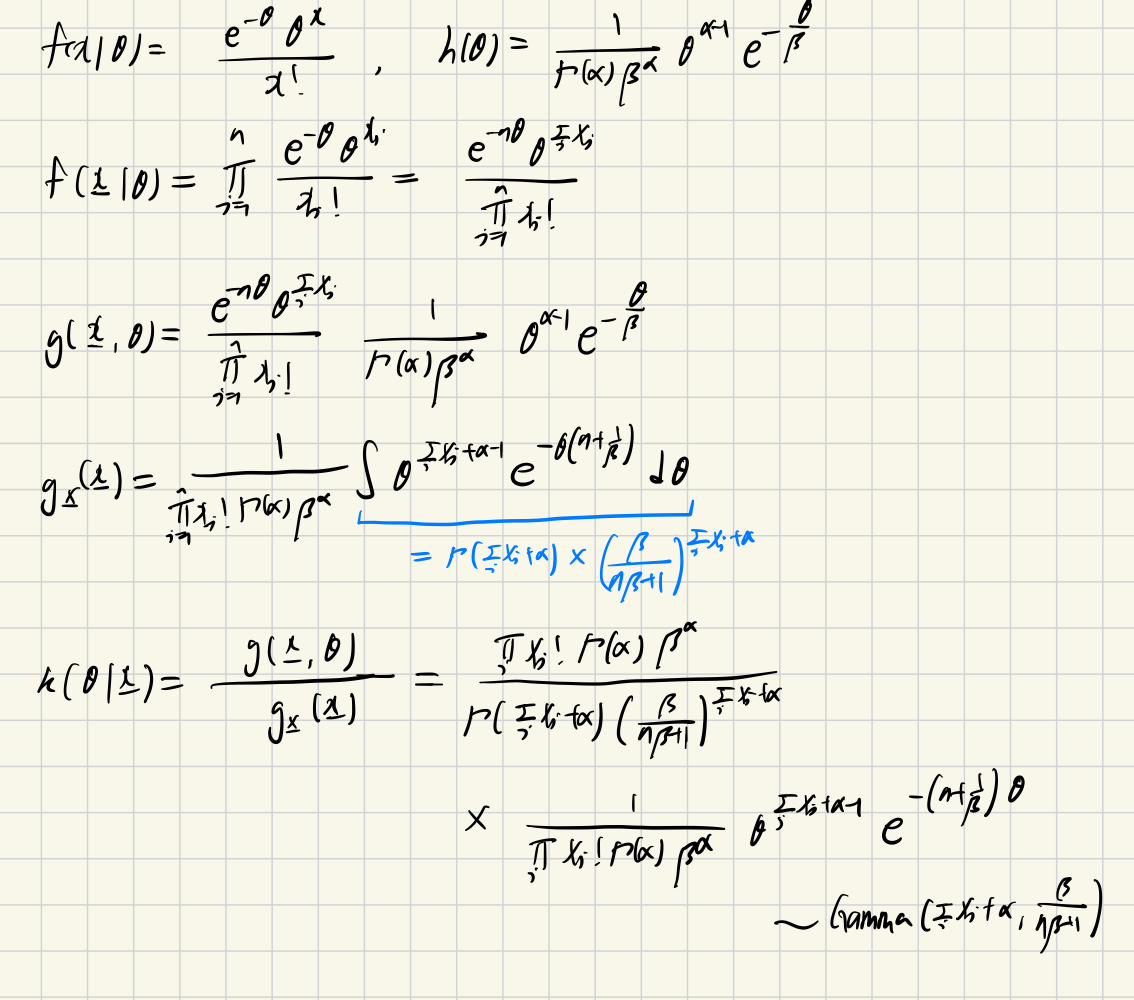
Bayesian point estimation
- δ(x): decision function
- l(θ,δ(x)): loss function
ex) (θ−δ(x))2,∣θ−δ(x)∣,(θ/δ(x)−1)2
- Bayes estimator minimizes the posterior expected loss
E[l(θ,δ(x))∣X=x]=∫l(θ,δ(x))k(θ∣x)dθ
ex1) Xi∣θ∼iidPoisson(θ),θ∼Gamma(α,β) (α,β:known)
θ∣x∼Gamma(∑ixi+α,nβ+1β)When l(θ,δ(x))=(θ−δ(x))2, θ^=E(θ∣x)θ^B=E(θ∣x)=nβ+1β(∑ixi+α)=n+β1∑ixi+α=n+β1nx+n+β11/βαβ : weighted sum of MLE & mean of prior distritbution
ex2) Xi∣θ∼iidb(1,θ),θ∼Beta(α,β)(α,β:known)
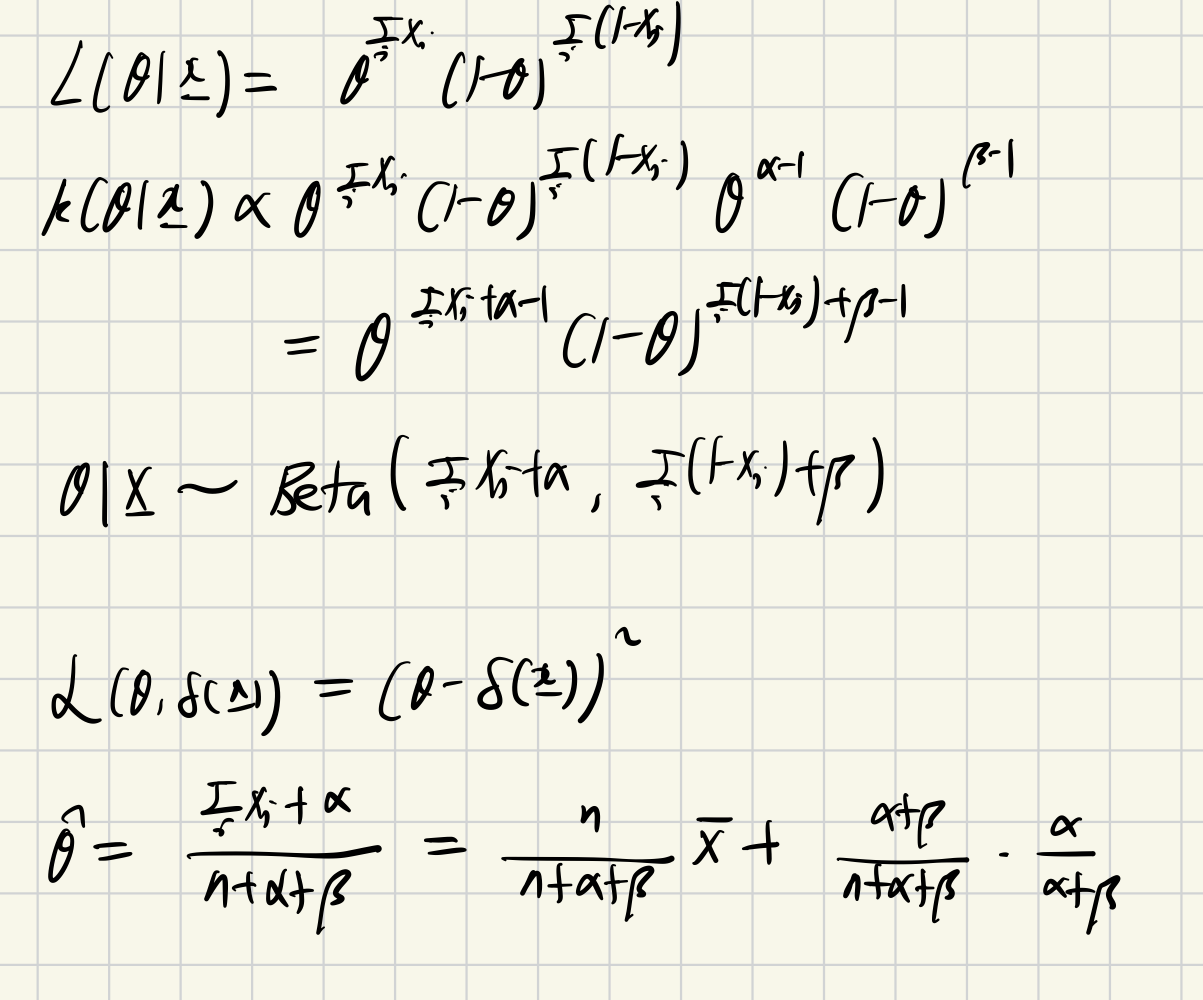
✔︎ conjugate prior
: If the posterior pdfs is in the same family of distributions as the prior, the prior is called conjugate prior
ex)
① When X∼Poisson(θ), Gamma is conjugate prior
② When X∼b(n,θ), Beta is conjugate prior
③ When X∼N(μ,1), Normal is conjugate prior
