2 실습용 데이터 다운로드
본 실습은 AWS EMR의 Primary(master) node 에 접속해서 진행한다.
- single 모드 쓴다던지 이런 경우엔 하둡 HDFS 명령어가 가능한 노드에서 진행하면 됨
ssh -i ./keys/pemkey.pem hadoop@ec2addesshdfs version으로 명령어 잘 되는지 확인한 다음 진행
2.1 실습용 데이터
실습용 데이터는 1987~2008년의 미국 항공편 운항 통계 데이터이다. 링크
전체 실습 데잍 사이즈 : 대략 1.5GB
- 데이터가 너무 많아 오래 걸리지는 않고, 너무 적어서 데이터가 너무 샘플 적지 않고. 적당한 수준
예제 데이터의 컬럼에 대한 설명은 링크 에서 확인할 수 있다.
다음 디렉토리에 데이터를 저장한다.
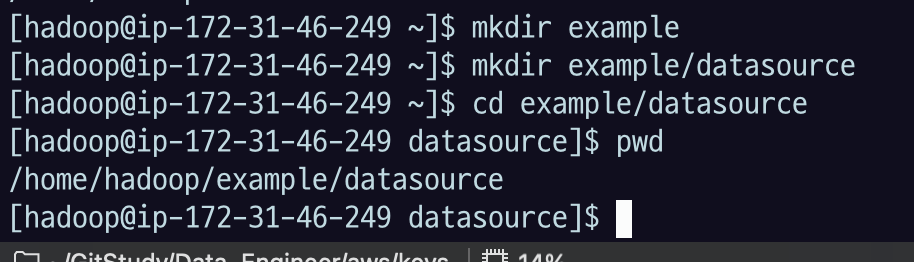
mkdir example
mkdir example/datasource
cd example/datasource2.1.1 get_data.sh
vi get_data.sh다음 bash script 를 담은 get_data.sh 파일을 만들고 실행 권한을 부여한 뒤 실행한다.
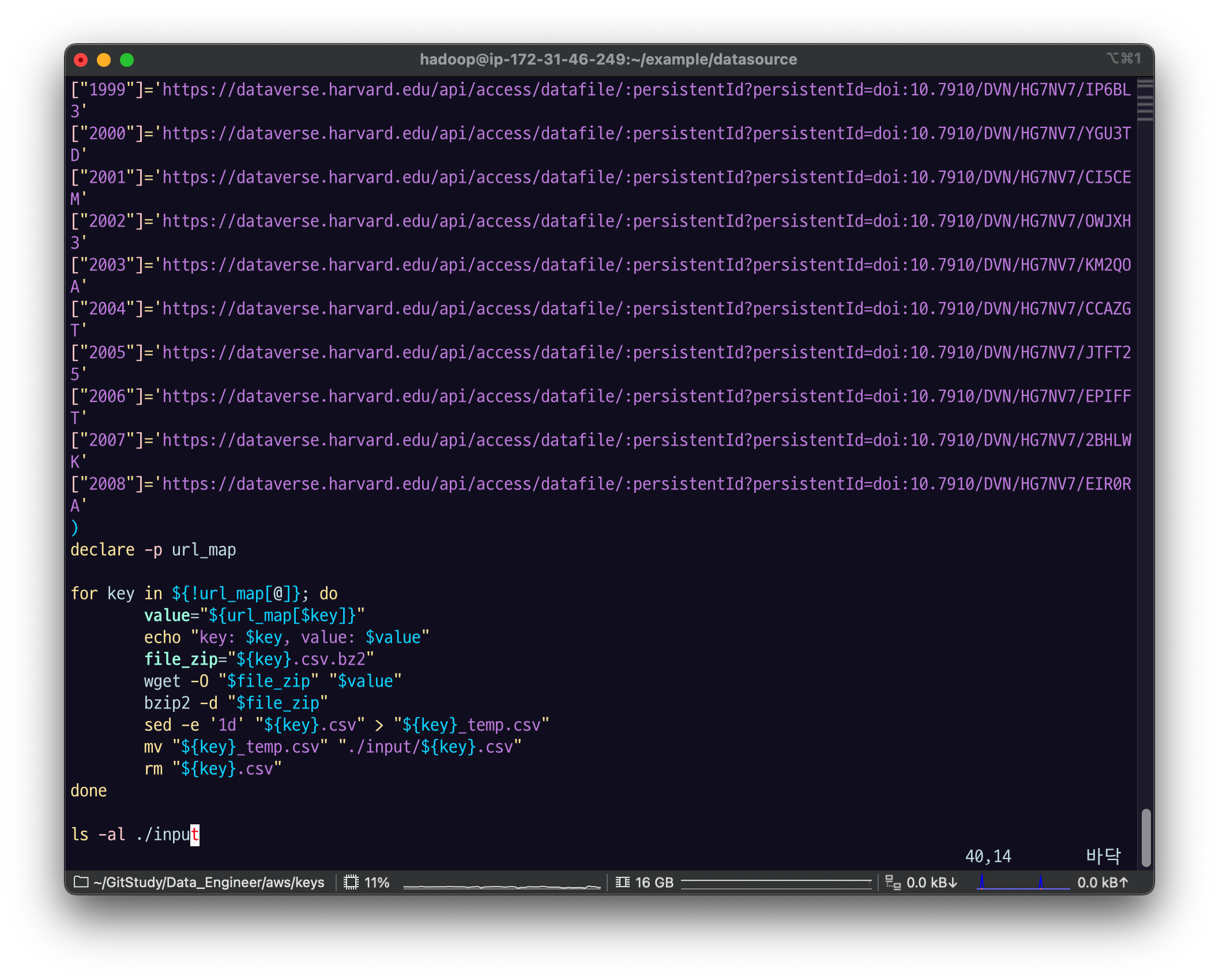
#!/bin/bash
mkdir input
declare -a url_map=(
["1987"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/IXITH2'
["1988"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/TUYWU3'
["1989"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/T7EP3M'
["1990"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/QJKL3I'
["1991"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/EJ4WJO'
["1992"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/PLPDQO'
["1993"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/IOU9DX'
["1994"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/BH5P0X'
["1995"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/ZLTTDC'
["1996"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/3KDWWL'
["1997"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/RUGDRW'
["1998"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/H07RX8'
["1999"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/IP6BL3'
["2000"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/YGU3TD'
["2001"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/CI5CEM'
["2002"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/OWJXH3'
["2003"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/KM2QOA'
["2004"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/CCAZGT'
["2005"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/JTFT25'
["2006"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/EPIFFT'
["2007"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/2BHLWK'
["2008"]='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/EIR0RA'
)
declare -p url_map
for key in ${!url_map[@]}; do
value="${url_map[$key]}"
echo "key: $key, value: $value"
file_zip="${key}.csv.bz2"
wget -O "$file_zip" "$value"
bzip2 -d "$file_zip"
sed -e '1d' "${key}.csv" > "${key}_temp.csv"
mv "${key}_temp.csv" "./input/${key}.csv"
rm "${key}.csv"
done
ls -al ./input연도 별 csv 파일 다운 받는 것
input 디렉토리 만들고
bash에서 map 형태 선언할 때 declare -a 이런 식으로 함.
- [key]=value 이런 식으로 하고 띄어쓰기나 엔터로 구분을 함.
declare -p url_map
- url_map 을 프린트 한다.
for key in ${!url_map[@]}; do
- url_map for문 돌 건데, 느낌표 사용하면 여기서 key를 하나씩 꺼내서 줌
file_zip="${key}.csv.bz2"
- bz2 는 압축된 파일이다.
wget -0 "$file_zip" "$value"
- wget으로
$file_zip명으로 저장을 할 거고$value이 url에서 다운로드 받겠다 한 것.
bzip2 -d "$file_zip"
- bzip2 로 압축을 풀고
sed -e '1d' "${key}.csv" > "${key}_temp.csv"- sed -e '1d' 는 뭐냐면 원본에서 첫 번째 줄을 지워달라는 것. 왜냐면 csv 파일 열면 맨 처음 컬럼들에 대한 설명이 있는데 이런 설명 없이 바로 데이터가 들어가야 하기 때문에 지워줌.
지운 걸 temp 라는 파일로 만들고
- sed -e '1d' 는 뭐냐면 원본에서 첫 번째 줄을 지워달라는 것. 왜냐면 csv 파일 열면 맨 처음 컬럼들에 대한 설명이 있는데 이런 설명 없이 바로 데이터가 들어가야 하기 때문에 지워줌.
mv 로 원본 파일과 바꿔치고,
원래 있었던 파일을 지운다. 이런 식으로 되어 있음.
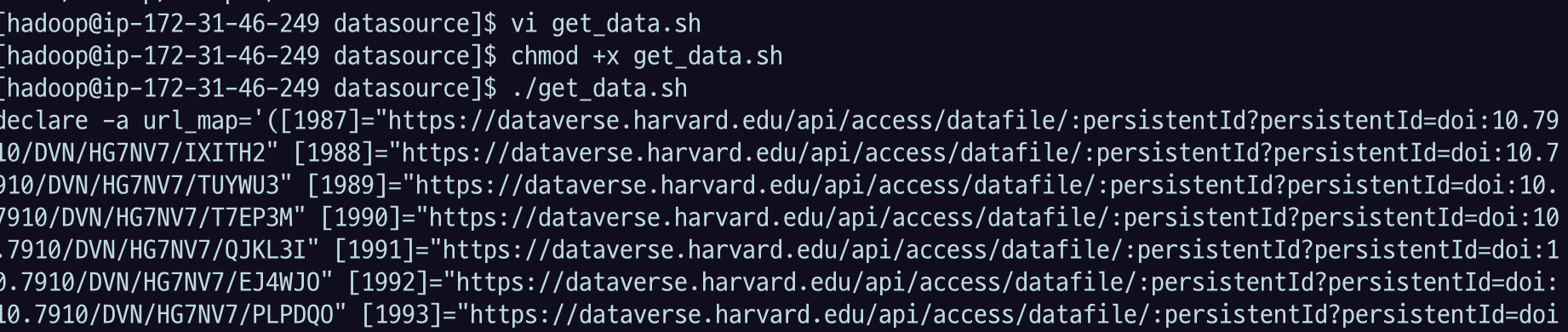
wq로 저장하고 나오고, 실행 권한이 없으니까
chmod +x get_data.sh이렇게 하면 실행할 수 있는 스크립트가 되고
./get_data.sh로 실행한다. 전체가 1.5기가 정도 되고 그걸 압축 푸는 과정이 있으니까 시간이 꽤 걸릴 것.
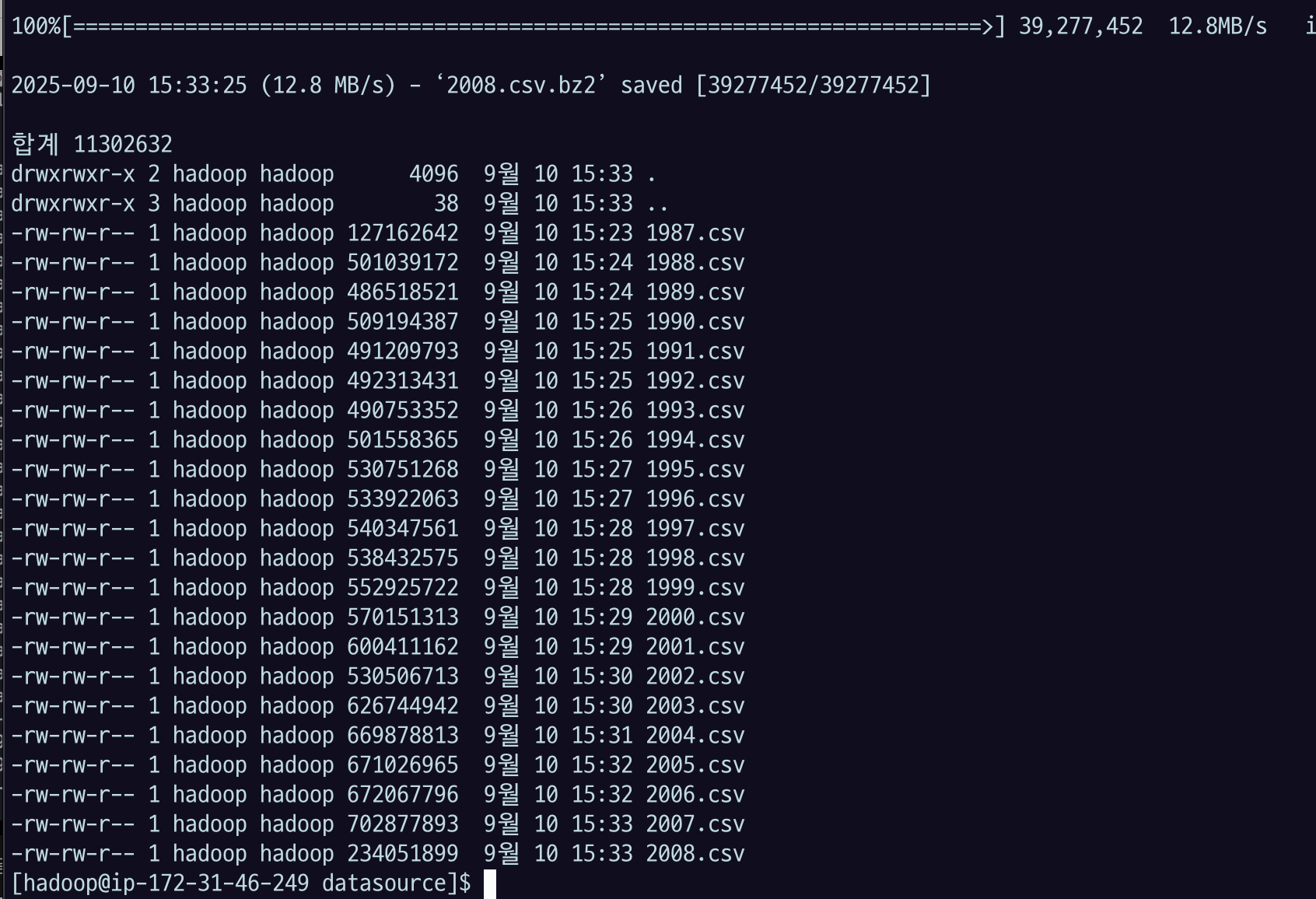
data size를 보면, 하나 파일이 기가를 넘지는 않지만 수백 메가 정도의 용량을 가지고 있는 좀 큰 CSV 파일이다.
head input/1987.csv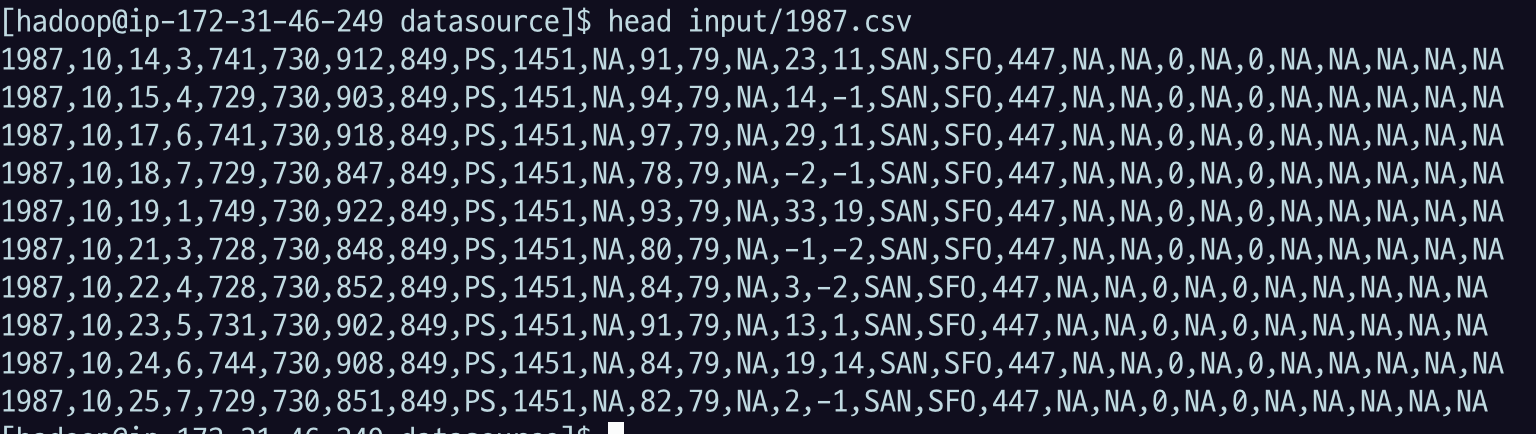
2.1.2 get_metadata.sh
위의 데이터 해석에 참고할 수 있는 다음 메타 데이터를 얻을 수있다.
- airports
- carriers
- plane-data
vi get_metadata.sh
다음 bash script 를 담은 get_metadata.sh 파일을 만들고 실행 권한을 부여한 뒤 실행한다.
#!/bin/bash
target_dir="metadata"
mkdir $target_dir
url="https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/XTPZZY"
origin="airports-origin.csv"
data="airports.csv"
wget -O "${target_dir}/${origin}" "$url"
sed -e '1d' "${target_dir}/${origin}" > "${target_dir}/${data}"
url='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/3NOQ6Q'
origin="carriers-origin.csv"
data="carriers.csv"
wget -O "${target_dir}/${origin}" "$url"
sed -e '1d' "${target_dir}/${origin}" > "${target_dir}/${data}"
url='https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/XXSL8A'
origin="plane-data-origin.csv"
data="plane-data.csv"
wget -O "${target_dir}/${origin}" "$url"
sed -e '1d' "${target_dir}/${origin}" > "${target_dir}/${data}"
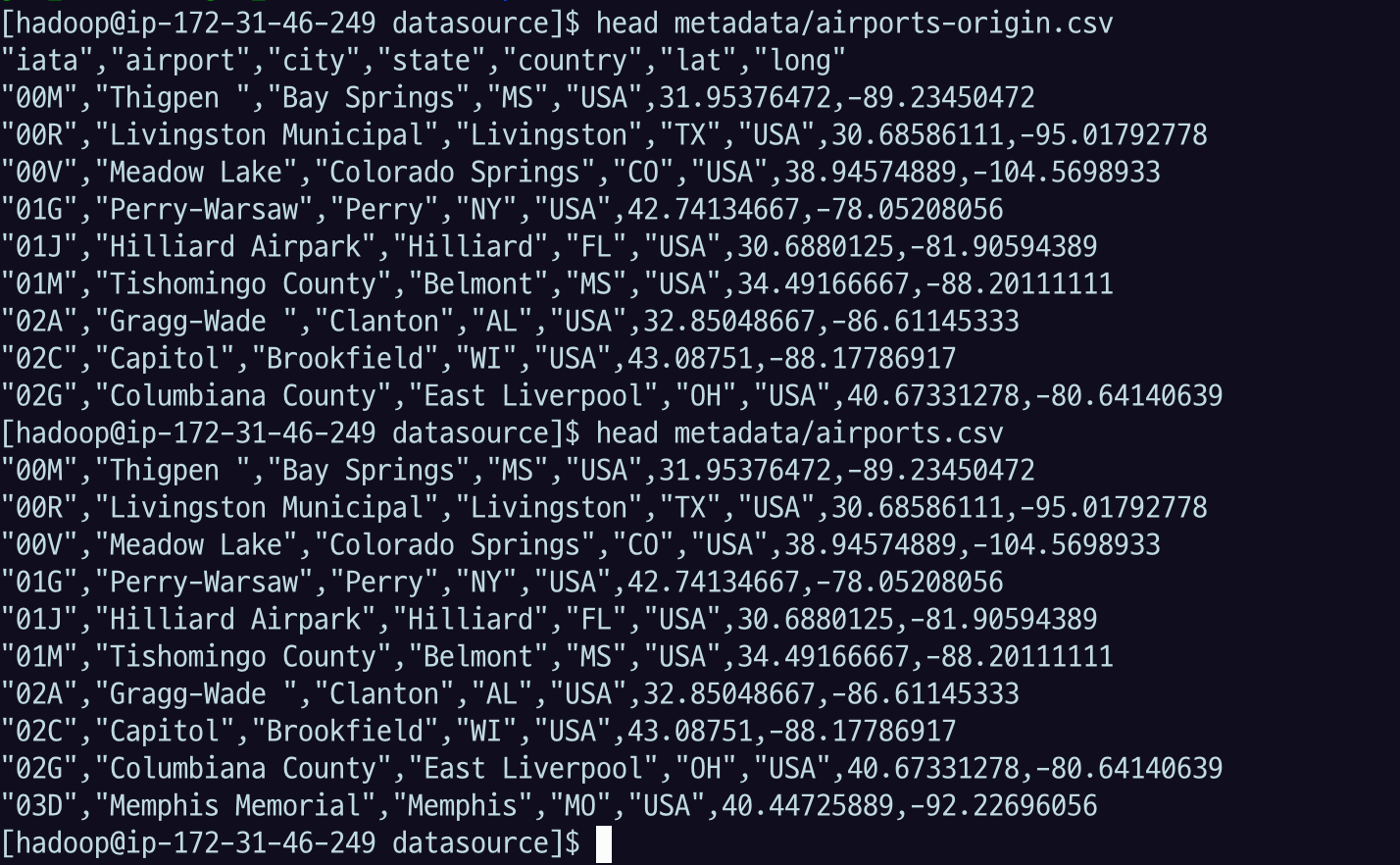
ls -al "$target_dir"metadata 디렉토리에 저장된다.
origin
- 원래 파일은 컬럼 이름을 지우지 않은 거고
data - '1d'로 컬럼을 지운 버전
chmod +x get_metadata.sh./get_metadata.sh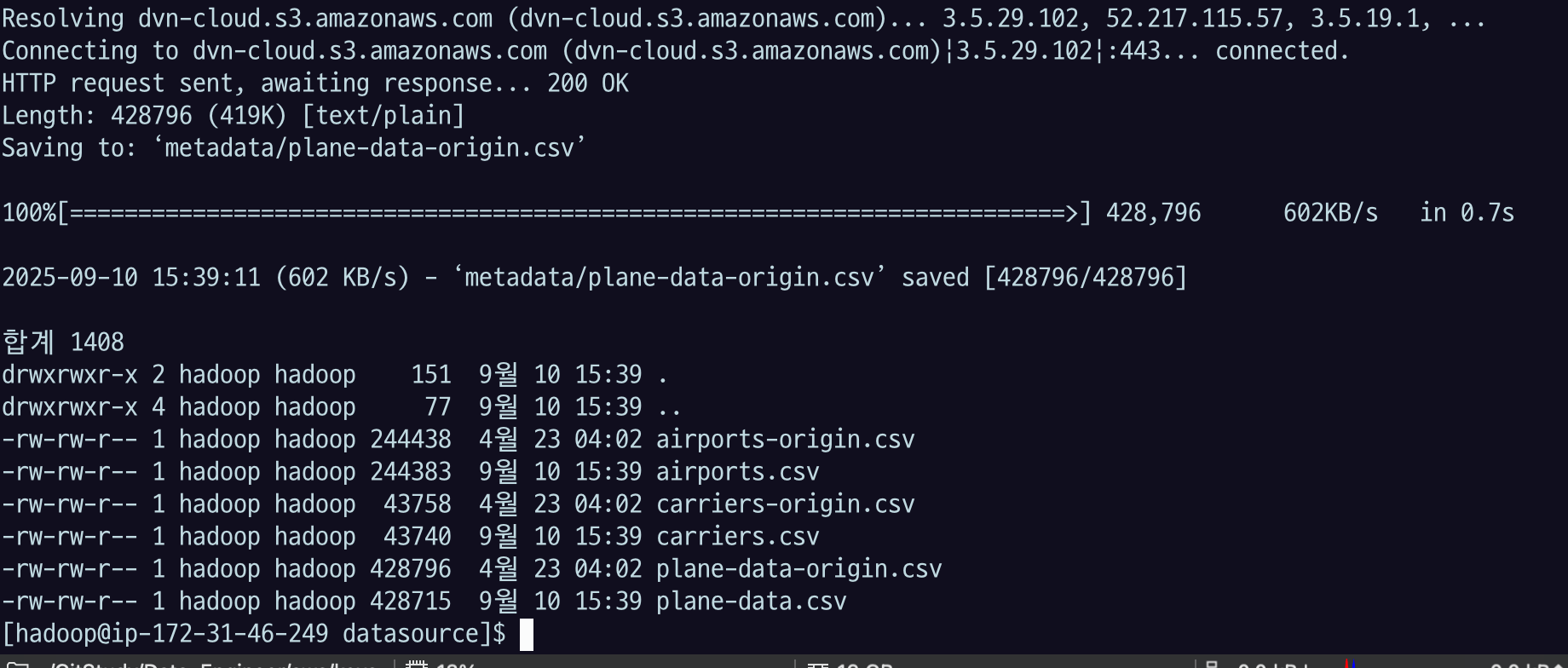
head 로 확인해 보면, origin은 컬럼 이름이 들어가 있고, origin이 아니면 바로 데이터가 나옴