3 HDFS 명령어 실습
본 실습은 AWS EMR의 Primary(master) node 에서 진행한다.
HDFS 명령어의 공식 매뉴얼
HDFS DFS (distributed file system)의 공식 매뉴얼
3.1 디렉토리, 파일 조회
유닉스에서 쓰는 명령어들이랑 거의 동일함.
3.1.1 ls
디렉토리의 파일을 출력
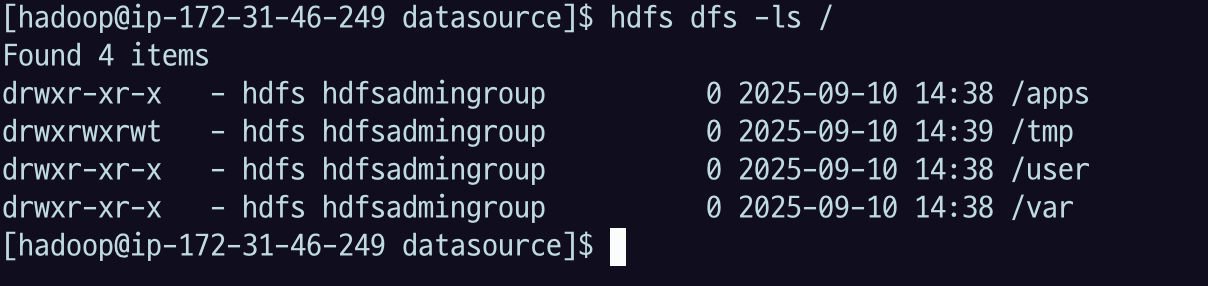
hdfs dfs -ls /hadoop fs -ls/명령어와 같은 것. 이건 옛날 버전.
권한 / user / usergruop / datasize / date / name-
For a file ls returns stat on the file with the following format:
permissions number_of_replicas userid groupid filesize modification_date modification_time filename
-
For a directory it returns list of its direct children as in Unix. A directory is listed as:
permissions userid groupid modification_date modification_time dirname -
데이터 사이즈는 directory라서 0으로 나옴.

hdfs dfs -ls /apps하둡 같은 경우 내가 직접 들어가있는 것이 아니기 때문에 전체 경로를 보여줌
3.1.2 lsr
(depth 전체 경로를 보기 어려우니까)
디렉토리와 하위디렉토리의 파일을 출력
hdfs dfs -lsr /3.1.3 du
파일 용량을 확인
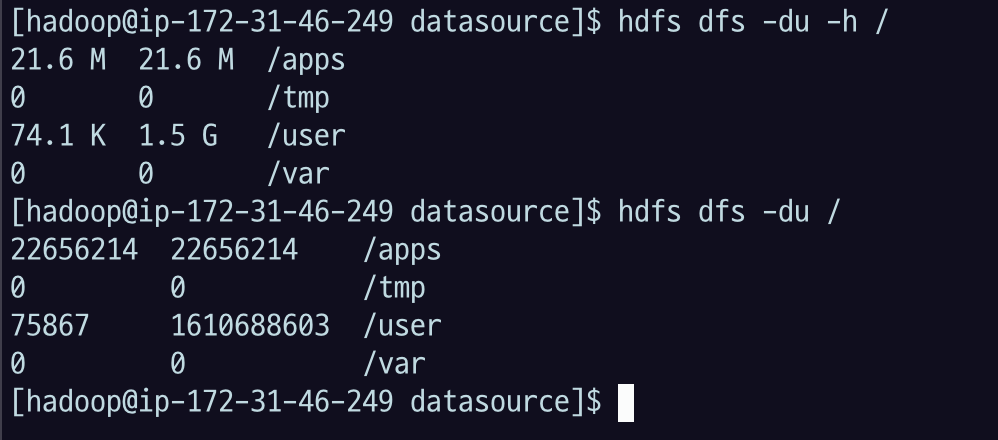
hdfs dfs -du -h /-h : 읽기 편하게
3.1.4 dus
해당 경로에 있는 디렉토리 들의 용량을 합친
summary 용량을 확인

hdfs dfs -du -h -s /3.1.5 cat
파일 내용을 출력 (텍스트만가능)
hdfs dfs -cat /user/hbase/.tmp/hbase-hbck.lock
ip-172-31-33-225/172.31.33.225 Written by an hbase-2.x Master to block an attempt by an hbase-1.x HBCK tool making modification to state. See 'HBCK must match HBase server version' in the hbase refguide. 까지가 나온 걸 확인할 수 있다.
현재 실행 중인 HBase 마스터(ip-172-31-33-225)가 "이 클러스터는 HBase 2.x 버전에서 동작 중이다" 라는 걸 표시하기 위해 락 파일을 쓴 것.
그리고 HBase 1.x 시절의 hbck 툴이 잘못 접속해서 메타데이터를 수정하지 못하도록 보호하는 장치.
- HBase에는 hbck(HBase Consistency Checker)라는 도구가 있는데, 버전별 동작이 다르다
- 1.x 용 hbck은 메타 테이블에 직접 수정을 가할 수 있었는데, 2.x와는 구조가 달라서 쓰면 데이터 불일치/손상 발생.
- 그래서 2.x에서는 아예 락 파일을 생성해서 버전 안 맞는 hbck 실행을 차단함.
3.1.6 text
파일 내용을 출력, 압축된 형태도 가능

hdfs dfs -text /user/hbase/.tmp/hbase-hbck.lock3.1.7 mkdir
디렉토리 생성 mkdir
hdfs dfs -mkdir /data
hdfs dfs -mkdir /data/temp확인
hdfs dfs -ls /3.1.8 head, tail
파일의 시작 또는 끝부분의 1KB 를 확인 (1kb를 출력해주는) 명령어
hdfs dfs -head /data/metadata/carriers.csvhdfs dfs -tail /data/metadata/carriers.csv3.2 파일 복사, 삭제
3.2.1 put, copyFromLocal
로컬에 있는 파일 또는 디렉토리를 HDFS 의 지정된 경로로 복사(업로드)한다.
2 에서 세팅한 디렉토리에서 수행
cd hadoop/example/datasource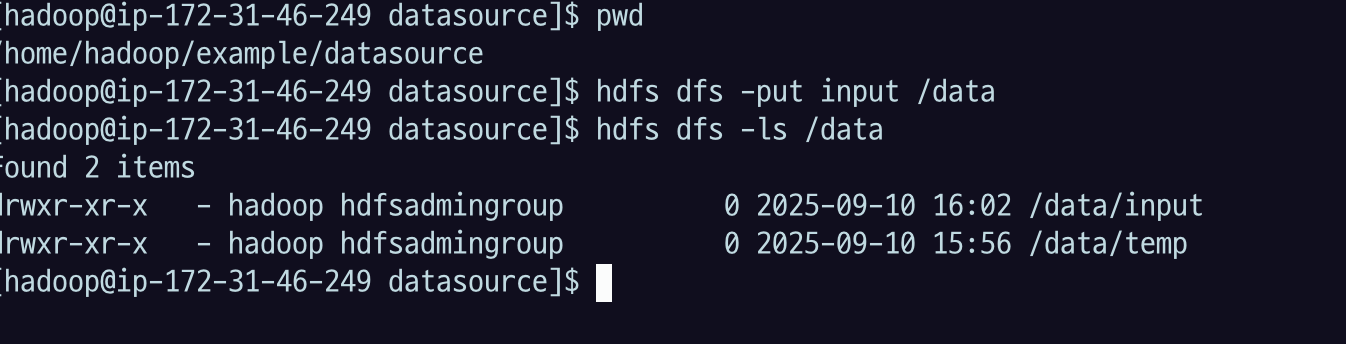
hdfs dfs -put input /data-
hdfs dfs -put
local경로hadoop경로- /data 하위에 input이란 디렉토리로 put
-
1.5G 가량되므로 업로드에 꽤 오래걸린다.
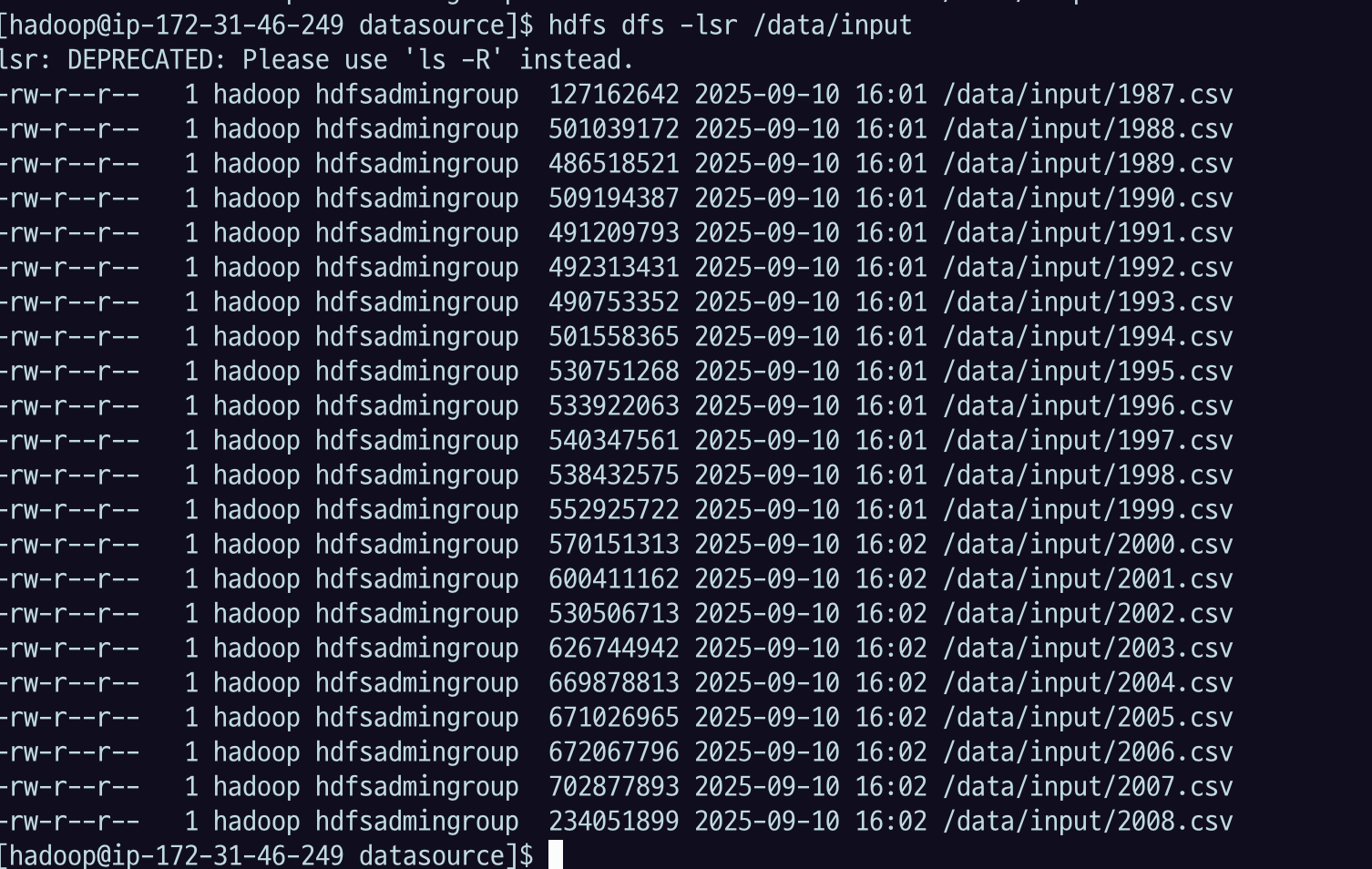
hdfs dfs -ls /data
hdfs dfs -ls /data/inputcopyFromLocal 명령어로 메타데이터로 올려보자.

hdfs dfs -copyFromLocal metadata /datahdfs dfs -ls /data
hdfs dfs -ls /data/metadata3.2.2 get
HDFS의 파일을 로컬로 복사(다운로드)한다.
- 내부적으로는 checksum을 숨김파일로 저장하고 이것을 이용해 무결성을 확인한다.
-crc옵션으로 checksum 파일도 복사가능-ignoreCrc로 체크섬 무시할 수 있음
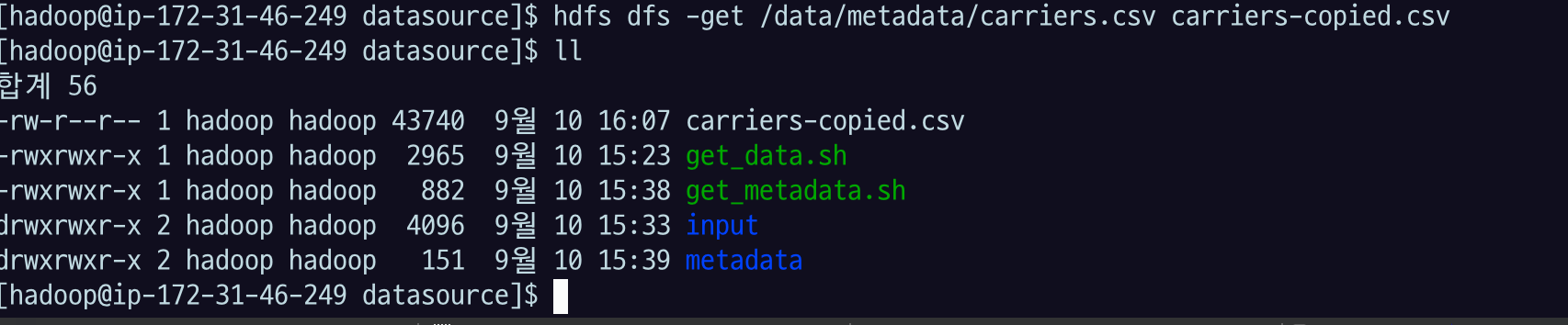
hdfs dfs -get /data/metadata/carriers.csv carriers-copied.csvhdfs dfs -get HDFS경로 local에 있는 경로
llcrc 옵션도 활용해보자.
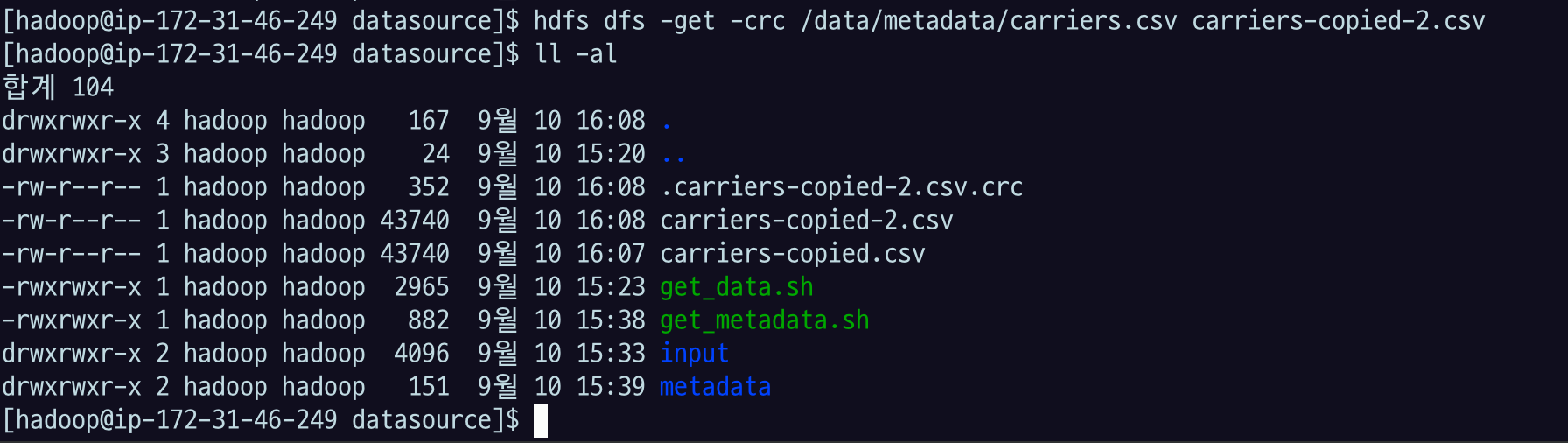
hdfs dfs -get -crc /data/metadata/carriers.csv carriers-copied_2.csvll -al체크섬 파일이 같이 다운받아진 것을 확인할 수 있음
ignore crc 할 수 있긴 한데, 웬만하면 하지 않는 것을 추천
3.2.3 cp, copyToLocal
소스 디렉토리나 파일을 목적지로 복사한다.
cp : hdfs 상에서 복사 하는 것
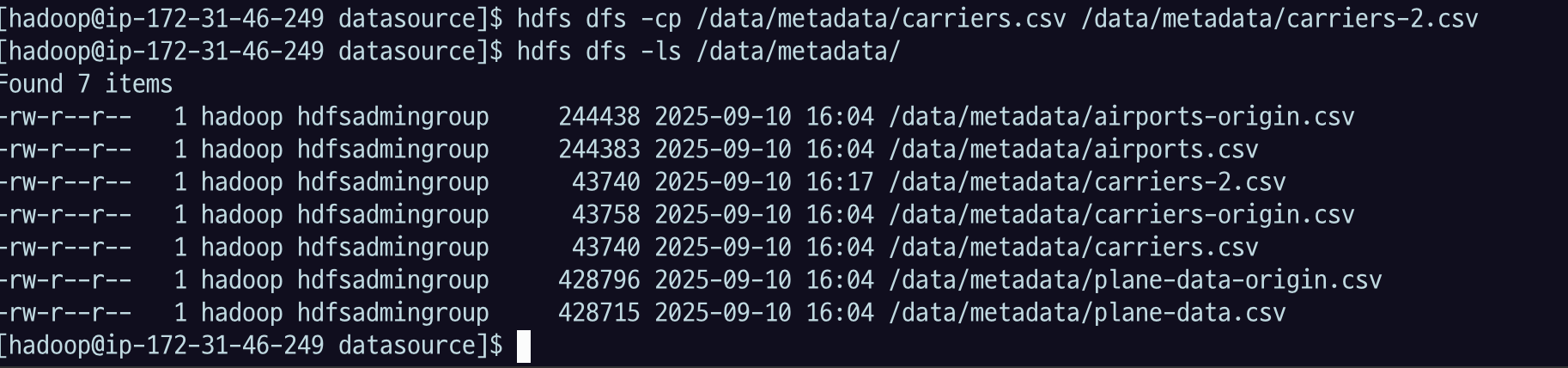
hdfs dfs -cp /data/metadata/carriers.csv /data/metadata/carriers-2.csv확인
hdfs dfs -ls /data/metadatacopyToLocal : 로컬로 받아오는 get 이랑 같다고 보면 됨

hdfs dfs -copyToLocal /data/metadata/carriers-2.csv이 상태로 엔터를 치면
ll현재 경로에 그대로 같은 이름으로 다운로드를 하고
다른 이름으로 하고 싶다면
hdfs dfs -copyToLocal /data/metadata/carriers-2.csv carriers-3.csv이런 식으로 하면 됨.
3.2.4 getmerge
지정한 경로의 모든 파일을 합치고, 로컬 파일시스템에 하나의 파일로 복사(다운로드)한다.
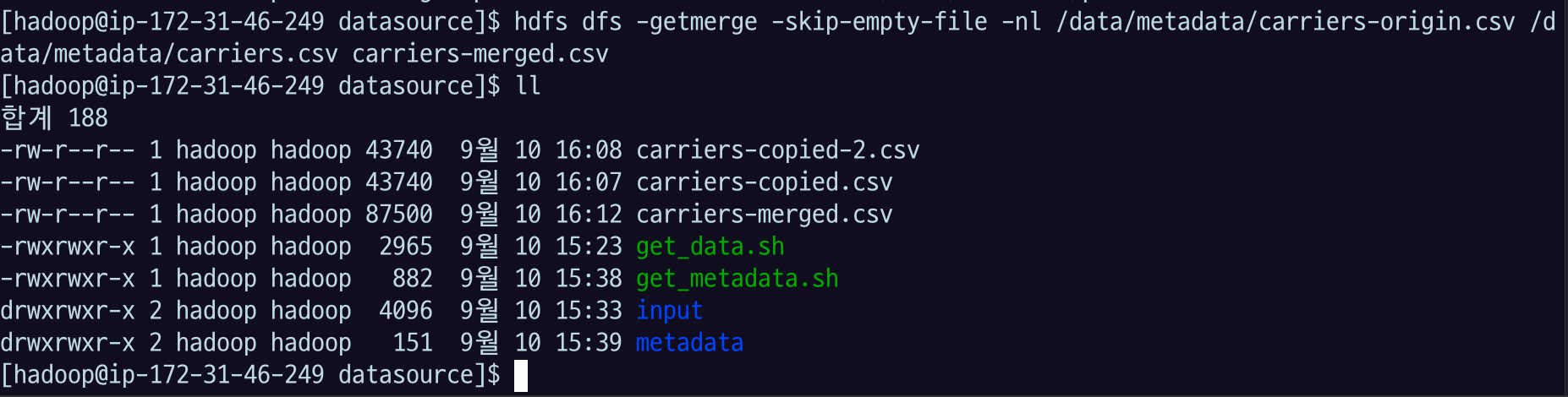
hdfs dfs -getmerge -skip-empty-file -nl /data/metadata/carriers-origin.csv /data/metadata/carriers.csv carriers-merged.csvhdfs dfs -getmerge 합칠 리모트에 있는 대상경로1.csv 합칠 리모트에 있는 대상경로2.csv 합친 결과로 받을 로컬 파일 경로.csv
-skip-empty-file는 빈파일은 머지대상 제외-nl옵션은 merge된 파일들을 newline 추가해서 구분
shift + ] : 다음 New Line 까지 이동
3.2.5 rm
unix 와 마찬가지로 파일을 삭제한다.
-R은 하위 디렉토리로 recursively
hdfs dfs -rm $file3.2.6 rmdir
디렉토리를 삭제한다.
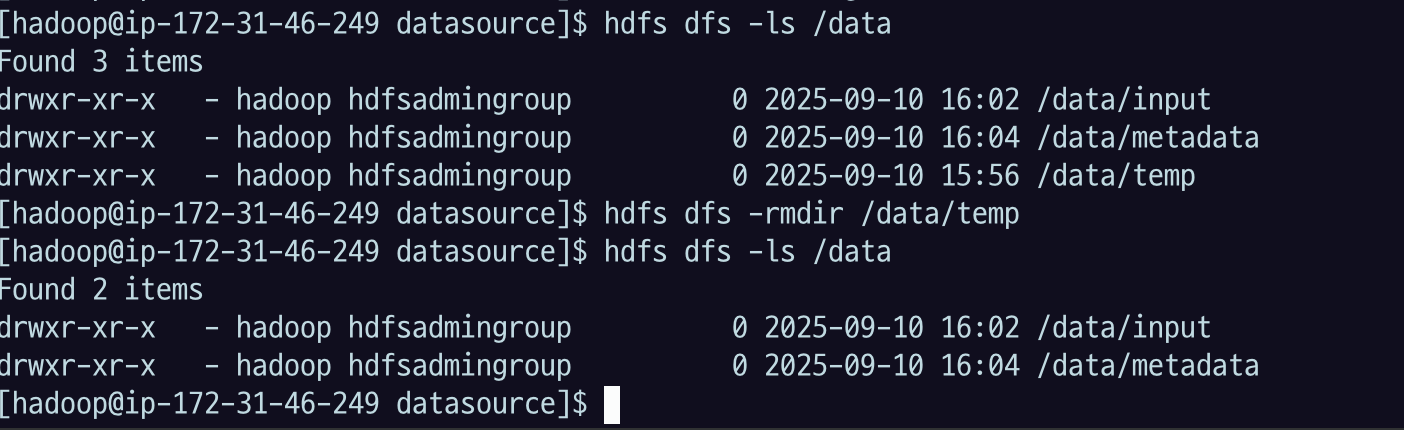
hdfs dfs -rmdir /data/temp3.3 권한 변경
3.3.1 chmod
경로에 대한 권한을 변경한다.
unix의 파일 권한 변경과 유사하다. 권한을 변경하려면 chmod 를 실행하는 사용자가 해당 파일의 소유자 또는 슈퍼유저일 때만 수정이 가능하다. -R 옵션은 재귀적으로 하위 dir가지 적용된다.
- 우리가 쓰는 hadoop 은 우리가 설치한 emr 하에서는 슈퍼유저다.
hdfs dfs -ls /data/metadata/carriers-2.csv
644 권한을 가지고 있음
hdfs dfs -chmod 777 /data/metadata/carriers-2.csv
hdfs dfs -ls /data/metadata/carriers-2.csv
777로 권한이 변경됨.
3.3.2 chown
파일이나 디렉토리의 소유권을 변경한다. -R 옵션은 재귀적으로 실행된다.
바로 위에 /data/metadata/carriers-2.csv 를 보면, user는 hadoop, 소유자 group은 hdfsadmingroup으로 되어 있다.

hdfs dfs -chown tester:testerGroup /data/metadata/carriers-2.csv
hdfs dfs -ls /data/metadata/carriers-2.csvtester라는 user, testerGroup이라는 소유자 그룹으로 소유 권한이 변경됨.
3.3.3 chgrp
파일이나 디렉토리의 소유권그룹만 변경한다.

hdfs dfs -chgrp testerGroup2 /data/metadata/carriers-2.csv
hdfs dfs -ls /data/metadata/carriers-2.csv3.4 기타 util
3.4.1 toughz
0바이트 파일 생성하는 것.
- 어떤 디렉토리 만들었는데, 그거 안에 임시 파일 만들고 싶다. 이런 경우에 사용
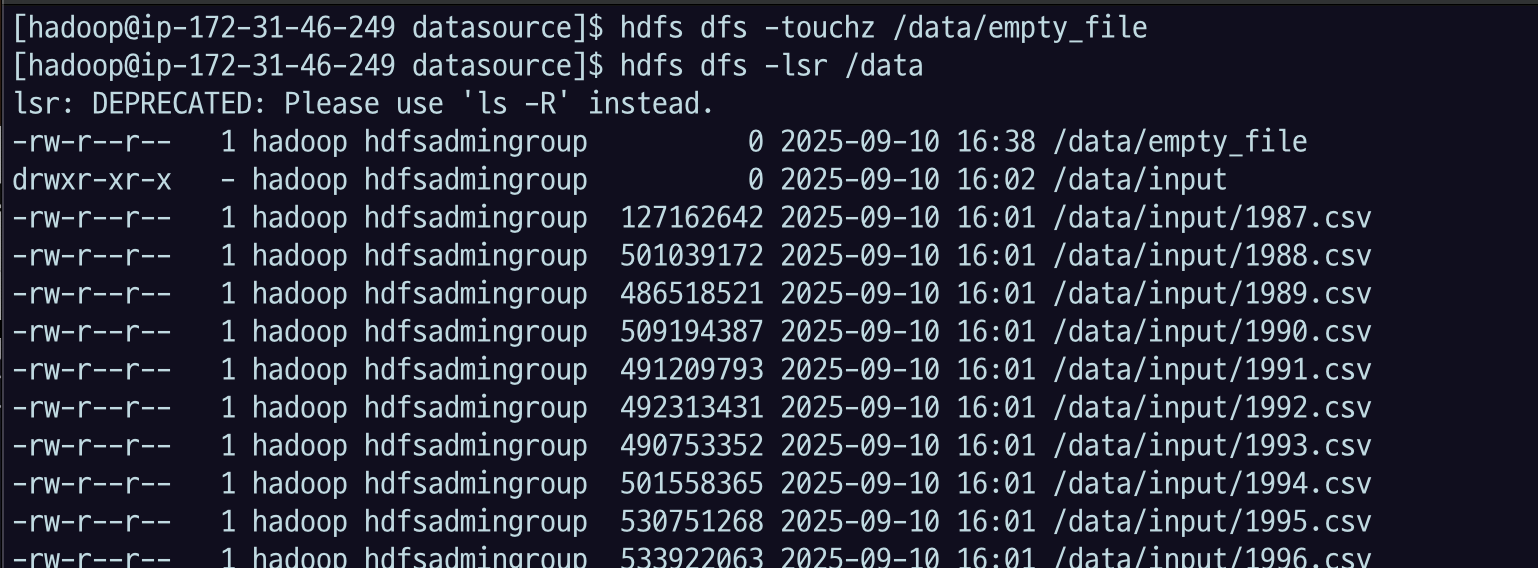
hdfs dfs -touchz /data/empty_filehdfs dfs -ls /data확인해 보면 디렉토리가 아닌 데도 파일 사이즈가 0이다.
hdfs dfs -head /data/empty_file아무 것도 나오지 않는다. 아무 데이터가 없다는 것
3.4.2 stat
경로에 대한 자세한 통계를 조회한다.
hdfs dfs -stat $foramt $fileformat에는 다음 옵션을 쓸수 있다.
Format accepts permissions in octal (%a) and symbolic (%A), filesize in bytes (%b), type (%F), group name of owner (%g), name (%n), block size (%o), replication (%r), user name of owner(%u), access date(%x, %X), and modification date (%y, %Y). %x and %y show UTC date as “yyyy-MM-dd HH:mm:ss”, and %X and %Y show milliseconds since January 1, 1970 UTC. If the format is not specified, %y is used by default.
- access date : 아 이 파일 최근에 사용 중이구나

hdfs dfs -stat /data/input/2008.csv아무 옵션을 안 주면 그 파일의 수정된 날짜를 utc time으로 출력하게됨

hdfs dfs -stat "size:%b type:%F filename:%n block_size:%o replication:%r m_date:%y" /data/input/2008.csvreplication : 1
이전에 EMR 세팅할 때 코어 노드 수가 4개 미만이면 replication 수는 1개 라고 설명했었다.
vi /etc/hadoop/conf.empty/hdfs-site.xml에 들어가서 dfs.replicaion을 보면 1로 들어가 있음.
3.4.3 setrep
복제 데이터 갯수 변경.
-R옵션으로 하위 디렉토리까지 적용 가능
아까 rep 하나였으니 세개로 변경을 해 보자
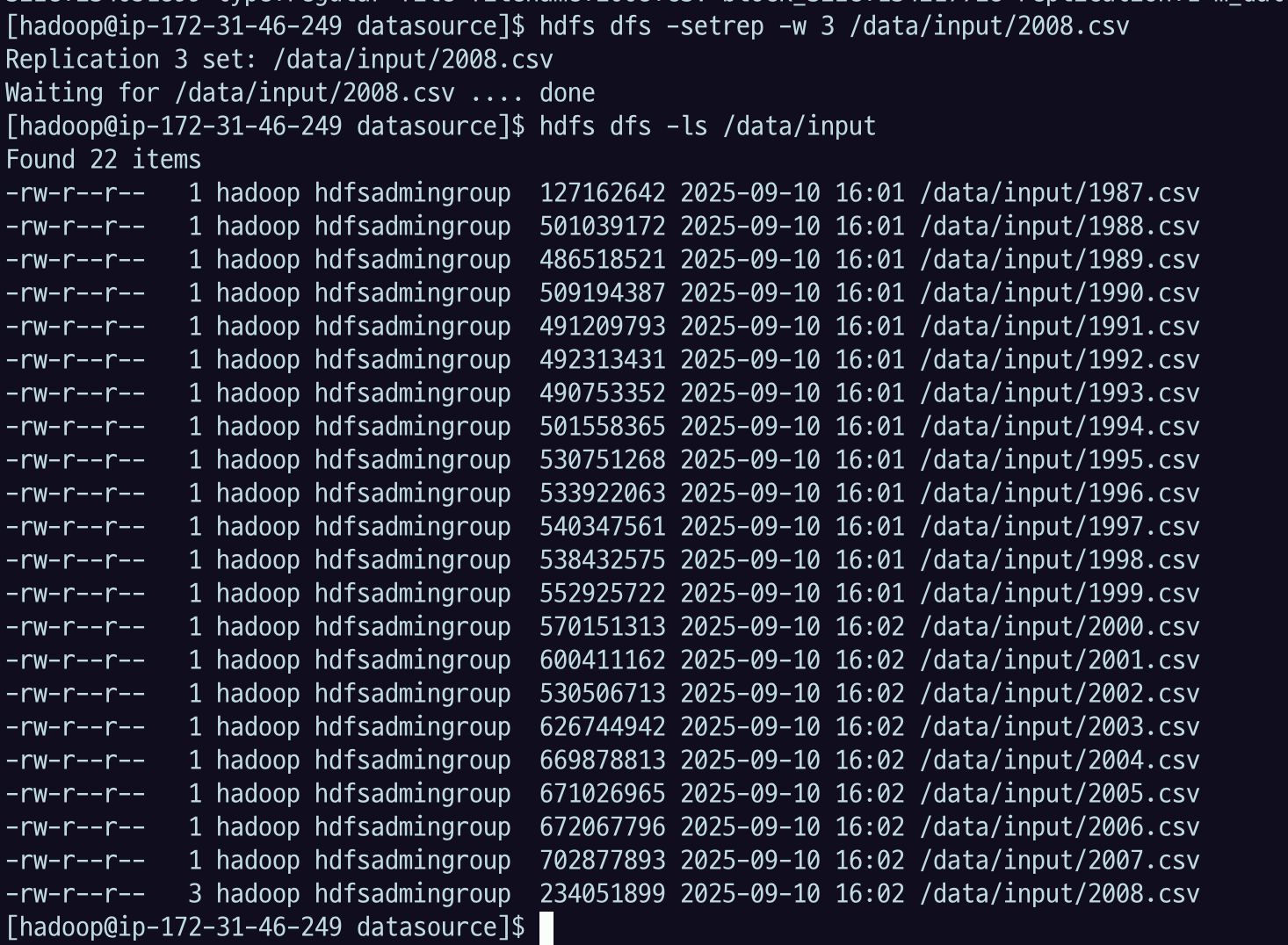
hdfs dfs -setrep -w 3 /data/input/2008.csv위 stat 명령의 %o 옵션으로 변경된 복제 갯수 확인 할 수 있음.
- 복제 갯수는 hdfs-site.xml 의
dfs.replication가 기본 설정이다. - EMR의 경우
/etc/hadoop/conf/hdfs-site.xml에서 확인할 수 있다.
hdfs dfs -ls /data/input/로 경로를 보면 파일의 개수가 변하는 건 아니지만 2008년 보면 이 친구 자체는 하나고, 사이즈도 정해져 있다.

hdfs dfs -stat "size:%b type:%F filename:%n block_size:%o replication:%r m_date:%y" /data/input/2008.csv그런데, 우리가 통계 정보로 보면 리플리케이션이 3개로 늘어난 것을 볼 수 있다.
input 디렉토리 만이라도 복제본을 유지하고 싶다면.
hdfs dfs -setrep -R -w 3 /data/input/위 처럼 입력해 전체적인 반복문을 돌면서 input에 대한 세팅을 하는 모습을 볼 수 있다.
다른 파일 확인해보면,
hdfs dfs -stat "size:%b type:%F filename:%n block_size:%o replication:%r m_date:%y" /data/input/2000.csvreplication 정보가 세개로 변경된 것을 확인할 수 있다.
3.4.4 expunge
휴지통을 비운다. HDFS는 삭제한 파일을 바로 지우지 않고 일정기간 동안 휴지통에 보관하고 주기적으로 비운다. expunge 는 이 주기와 관계없이 휴지통을 비운다.
hdfs dfs -expunge얘가 체크포인트가 만들어지면 그 체크포인트로 부터 delete를 수행한 파일들이 옮겨지고,
fs.trash.interval이라는 기간 전까지 유지된다
interval 지나면 그 때 마다 주기적으로 휴지통 비운다.
`user//.Trash 에 보면 삭제 대상인 파일들이 지정이 되어 있다.
