4 EMR 클러스터 웹 인터페이스
Hadoop 의 다양한 도구를 패키지로 설치했다. 각 컴포넌트별로 접근하는 인터페이스가 다르다. EMR로 구성한 경우 다음 매뉴얼로 확인한다.
2025.08.18. 기준
| 인터페이스 이름 | URI |
|---|---|
| Flink 기록 서버 (EMR 5.33 이상) | http://master-public-dns-name:8082/ |
| Ganglia | http://master-public-dns-name/ganglia/ |
| Hadoop HDFS NameNode (EMR 6.x 이전) | https://master-public-dns-name:50470/ |
| Hadoop HDFS NameNode | http://master-public-dns-name:50070/ |
| Hadoop HDFS DataNode | http://coretask-public-dns-name:50075/ |
| Hadoop HDFS NameNode (EMR 6.x) | https://master-public-dns-name:9870/ |
| Hadoop HDFS DataNode (EMR 6.x 이전) | https://coretask-public-dns-name:50475/ |
| Hadoop HDFS DataNode (EMR 6.x) | https://coretask-public-dns-name:9865/ |
| HBase | http://master-public-dns-name:16010/ |
| Hue | http://master-public-dns-name:8888/ |
| JupyterHub | https://master-public-dns-name:9443/ |
| Livy | http://master-public-dns-name:8998/ |
| Spark HistoryServer | http://master-public-dns-name:18080/ |
| Tez의 Hive 실행 시간 비교 | http://master-public-dns-name:8080/tez-ui |
| YARN NodeManager | http://coretask-public-dns-name:8042/ |
| YARN ResourceManager | http://master-public-dns-name:8088/ |
| Zeppelin | http://master-public-dns-name:8890/ |
EMR 대시보드에서 Applications 를 누르면 접근할 수 있는 url 주소와 포트가 나열되어있다.
primary node public dns에서
누가 active name node 인지 확인하자.
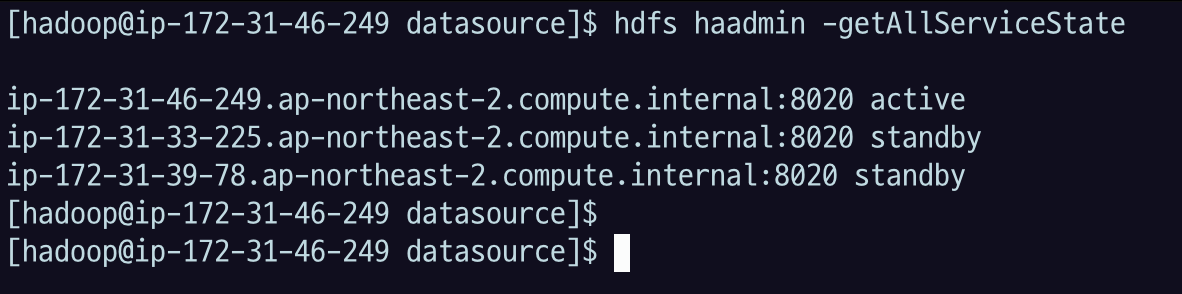
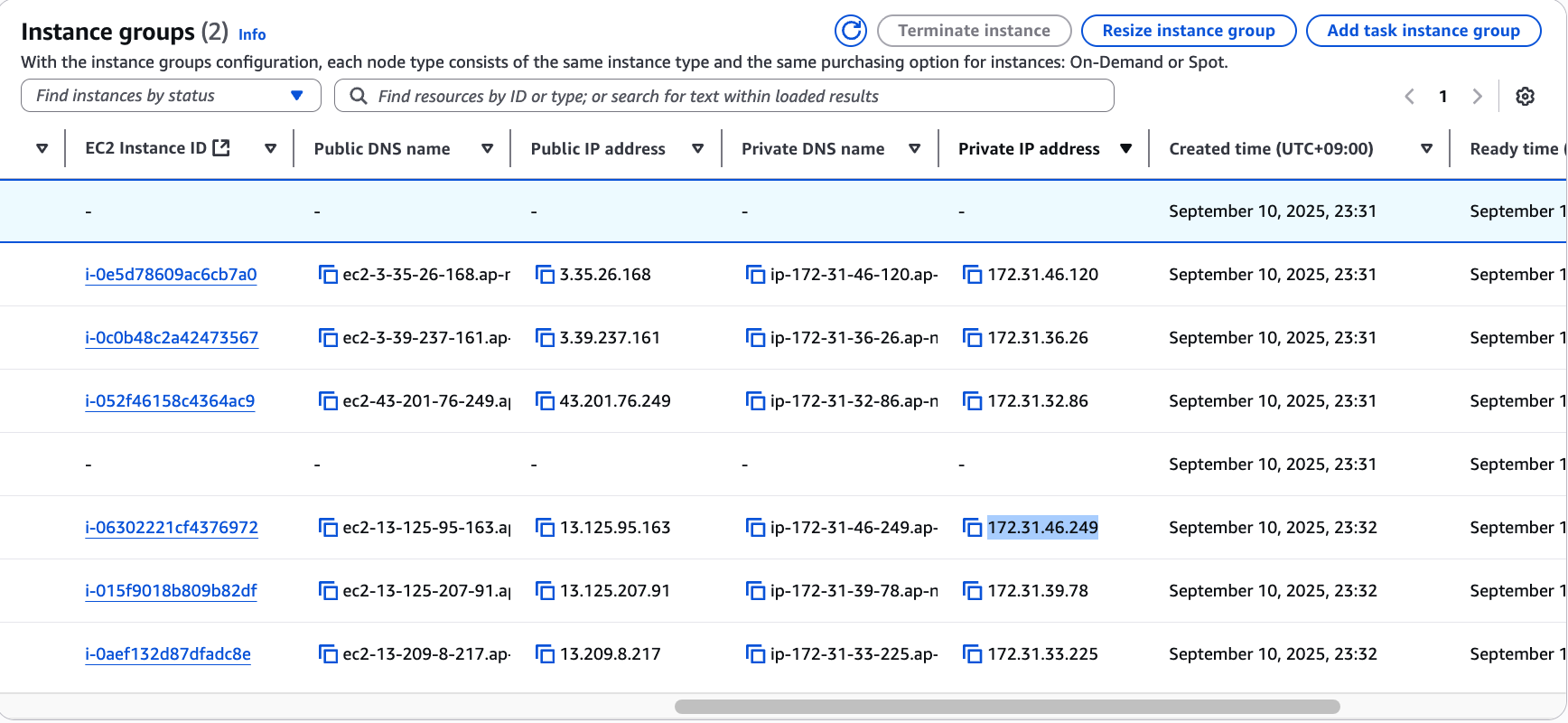
hdfs haadmin -getAllServiceStateinstance groups > instances 에서 각 인스턴스들을 눌러 보면서 Private IPv4 address 가 일치하는 인스턴스를 찾고,
그 친구의 Public IPv4 DNS를 복사해 6.x 버전이니까 9870 포트로 접속을 해보자.
ec2-13-125-95-163.ap-northeast-2.compute.amazonaws.com:9870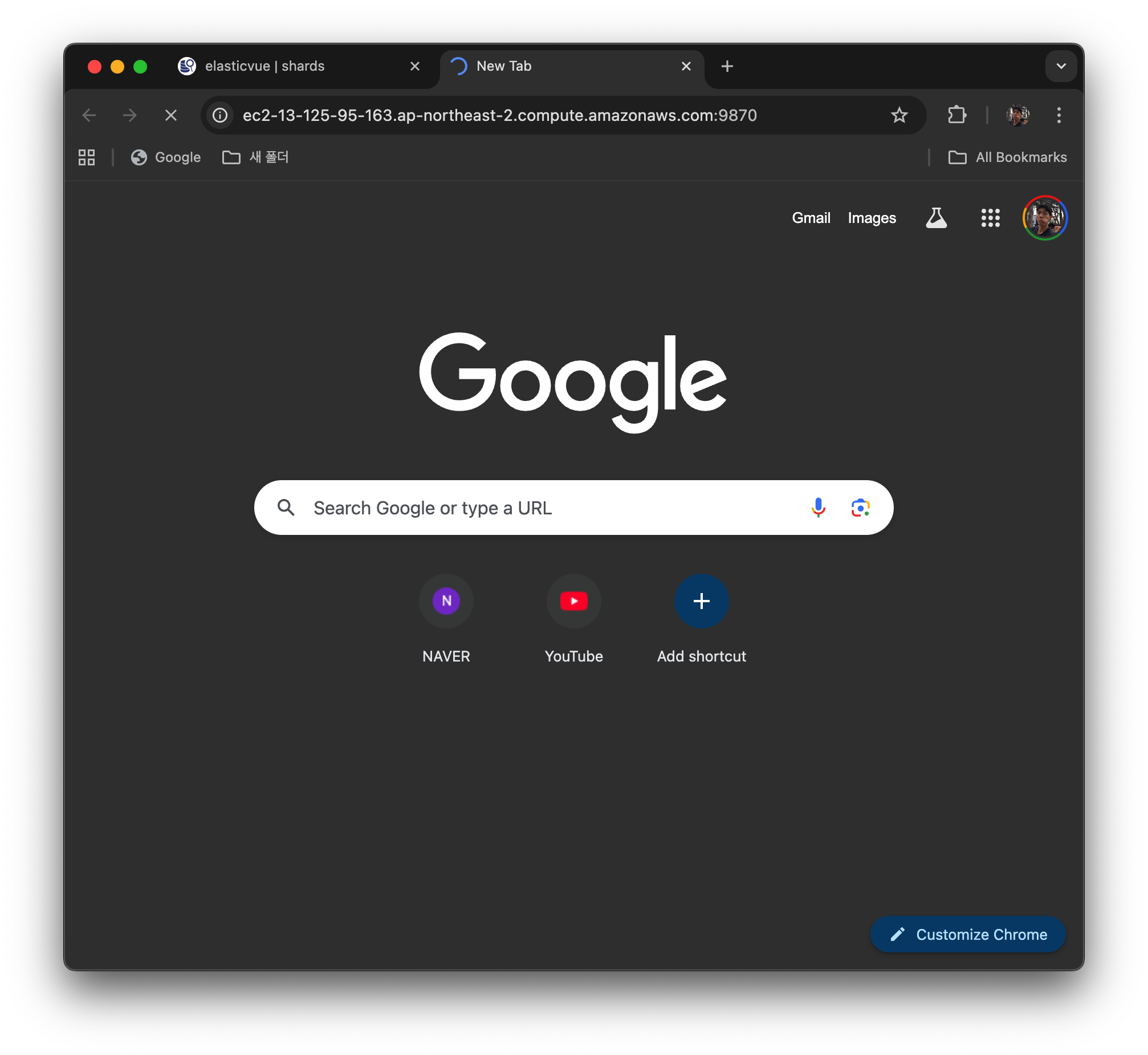
로딩이 되면서 접속이 안 됨.
접속이 안 되는 이유는 ACL에서 막혀 있기 때문.
내가 여기 접근 할 수 있는 권한이 없다.
그 권한을 줄 수 있는 방법이 두가지 있음
그 방법 두가지는 아래서 설명.
4.1 로컬에서 웹인터페이스에 접근 하는 방법
EMR의 primary의 기본 보안 그룹으로 설정했다면 로컬 환경에서 단순히 public address 로 해당 포트로 접근할 수 없을 것이다. 해결방법은 두가지가 있다.
방법 1
- 보안그룹을 수정해서, inbound 에 자신의 IP address 또는 모든 IP 에 대해서 해당 port 로 진입을 허용하는 방법.
- 쉬운 방법이지만 하드웨어는 중요한 시스템인데 IP나 IP 대역에 대해 port를 외부에 노출시키는 것이다 보니 보안상 좋지 않은 방법.
❗ 주의. EMR에서 사용하는 security groups에 inbound allow all (0.0.0.0/0) 하는 포트가 22말고 추가로 있다면, cluster 생성시에는 validation error 로 생성에 실패한다.
방법 2
- 포트포워딩을 통해서 pem 파일 인증을 통해서 연결하기
- 매뉴얼 을 참고한다.
- 불편하지만 보안적으로 안전한 방법이다. 프로덕션이라면 이 방법을 추천한다.
- 임시적으로 열었다가 컴퓨터 종료 시 닫힘.
위 가이드를 이용해서 hadoop namenode 의 웹인터페이스로 접속해보자.
ssh -i port forwarding : EC2 8080으로 서비스 포트가 열려 있고,
로컬에서 브라우저 연 다음 localhost:8081로 접속하면 이 EC2:8080으로 연결하게 해주는 것. 나의 8081은 EC2의 8080이랑 같아. 라는 설정을 해주는 것
- 이건 보안그룹 ssh가 먼저 열려 있어야 함.
ssh -i ~/mykeypair.pem -N -L 8157:ec2-###-##-##-###.compute-1.amazonaws.com:8088 hadoop@ec2-###-##-##-###.compute-1.amazonaws.com~/mykeypair.pem : 마스터EC2 에 대한 pem 파일
-N : 원격 명령 실행은 하지 않고, 포트 포워딩만 수행
-L : 로컬 포트와 원격 호스트/포트를 연결하는 로컬 포트 포워딩 설정
8157 : 내 로컬 호스트에서 열 포트 번호
:ec2-###~~.com:8080 : 그 대상이 되는 서버의 호스트와 포트 번호
hadoop@ec2-###~~.com : 하둡 유저로 해당 주소 노드에다가 이렇게 하겠다. 라는 pem파일에 접속하는 유저랑 호스트 번호
ssh -i ~/mykeypair.pem -N -L 8157:ec2-###-##-##-###.compute-1.amazonaws.com:8088 hadoop@ec2-###-##-##-###.compute-1.amazonaws.com로컬에서도 똑같이 마스터 포트로 할 거고, 그리고 EC2에 있는 퍼블릭 주소랑 거기 있는 9870쓰겠다. 라고 하고 호스트의 유저는 hadoop을 쓸 거고 이 주소 노드에다가 할 거다.
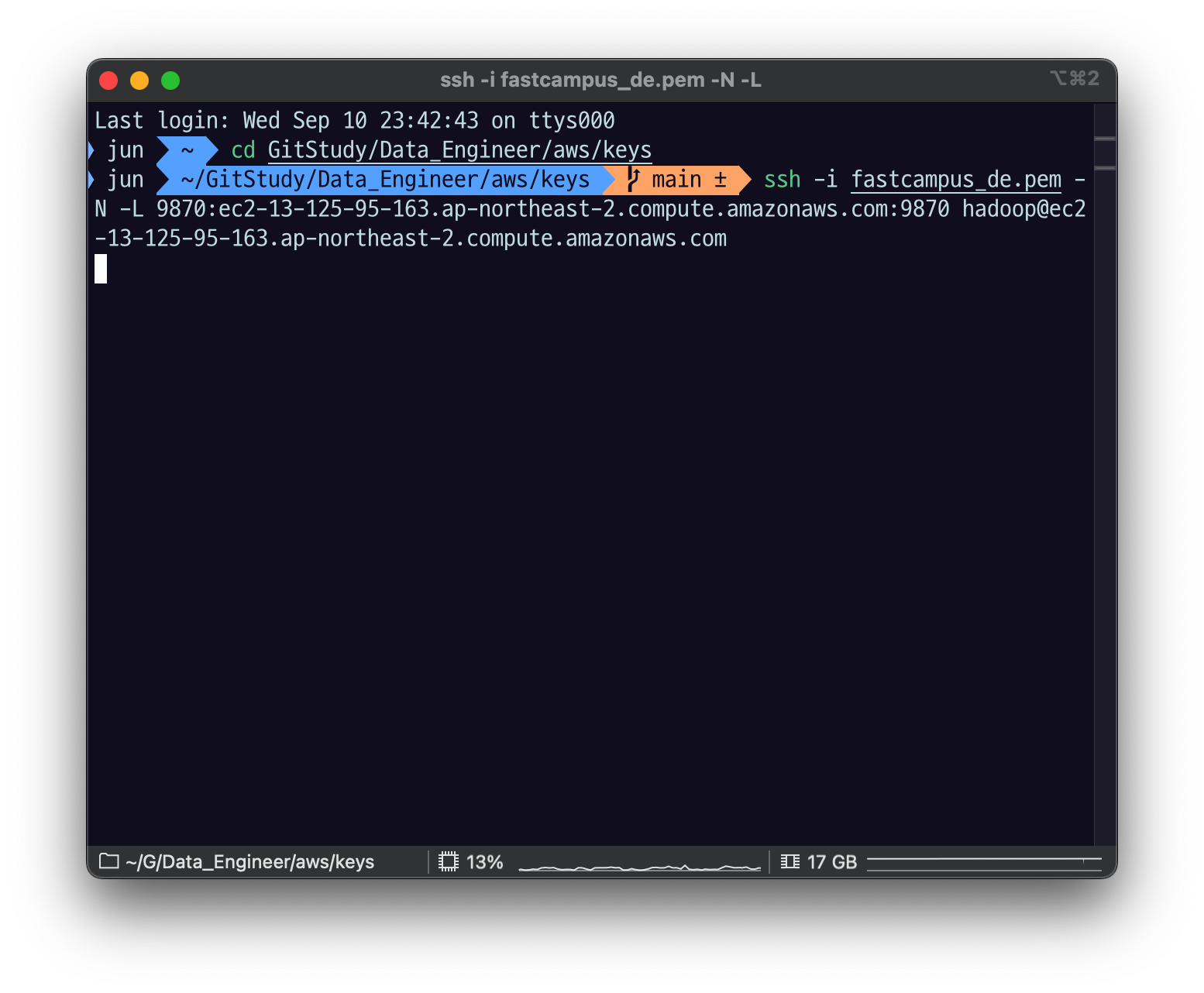
엔터를 치고 나서, 터미널에서 커서를 잡고 아무 것도 안 되고 있으면, 지금 잘 연결이 된 것이다.
브라우저에 와서 9870을, 내 로컬에 있는 포트를 포워딩 했으니까 localhot:9870을 넣으면 됨
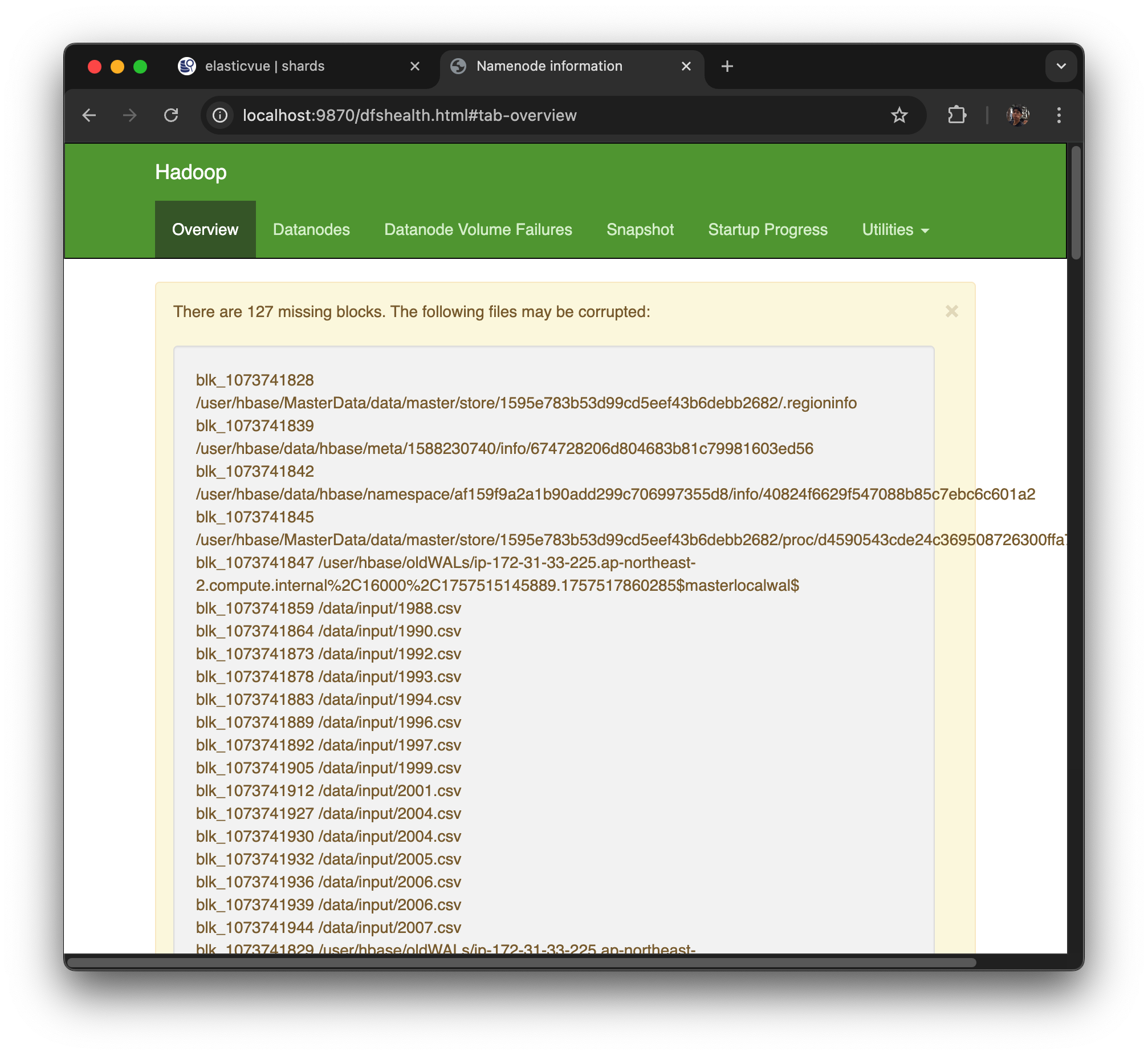
There are 127 missing blocks. The following files may be corrupted:
라는 메세지는 spot instance 때문에 나온 메세지다.
DataNode 손실: Spot 인스턴스처럼 노드가 종료되면 해당 노드에 있던 블록들이 사라진다. 복제본(replication factor)이 충분하지 않으면 missing block으로 남음
Replication factor 설정 부족: 기본 replication factor가 1이라면, 노드 하나만 죽어도 블록 유실이 발생.
디스크/스토리지 장애: DataNode가 살아있더라도 특정 디스크에 저장된 블록이 손상되면 missing block이 뜰 수 있음
HBase 사용 중이던 파일(WAL, meta, namespace 등): 로그 상에/user/hbase/oldWALs,/hbase/meta/namespace도 같이 보이는데, 이는 HBase 테이블 메타/로그 블록들이 유실되었음을 의미.
그 말인 즉 지금 EMR CORE NODE 들이 꺼졌다는 것인데 확인을 해보자..

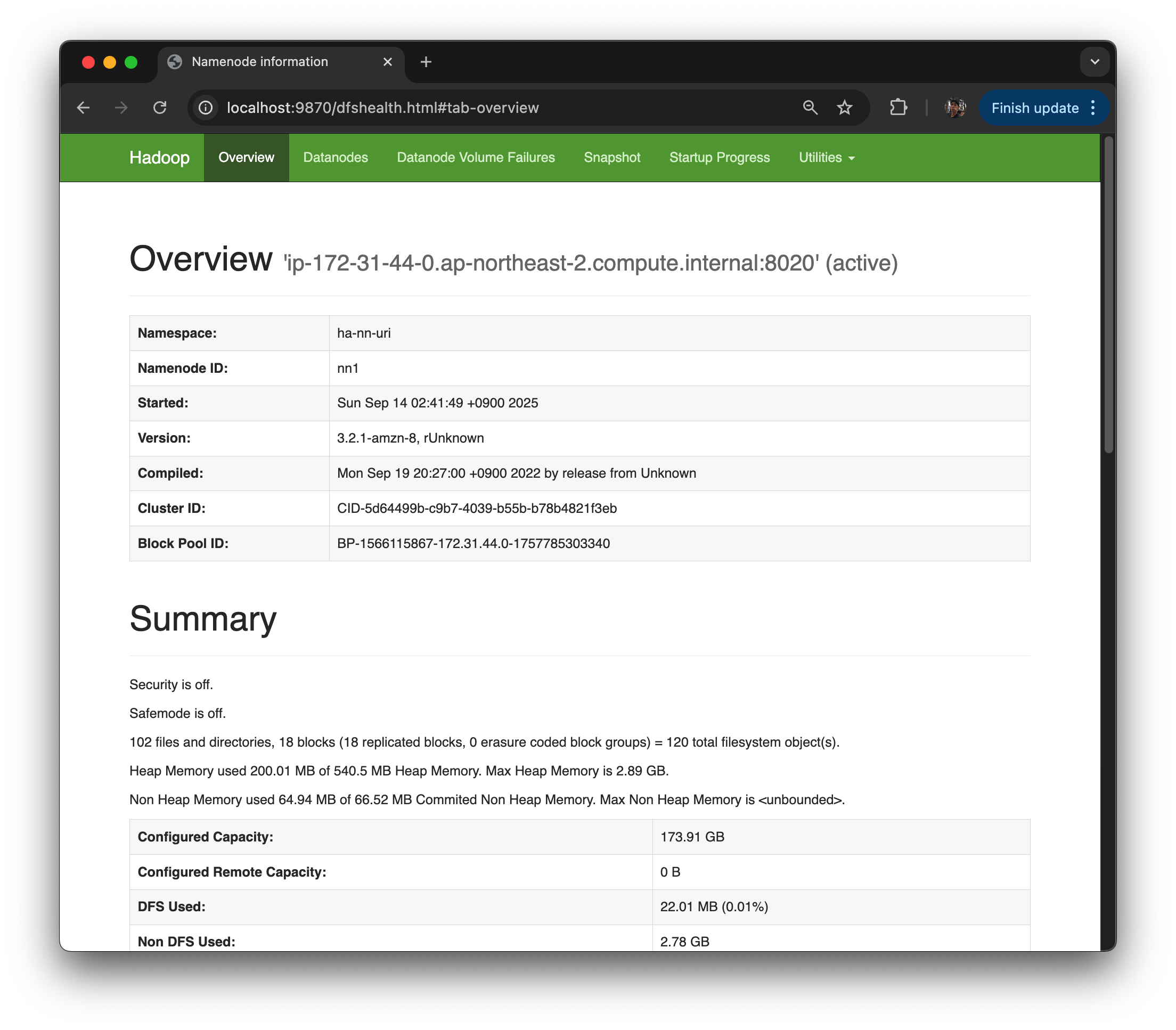
그렇게 되면 dfshealth.html 하둡 기본 health home 화면이 나오면 잘 된 것이다.
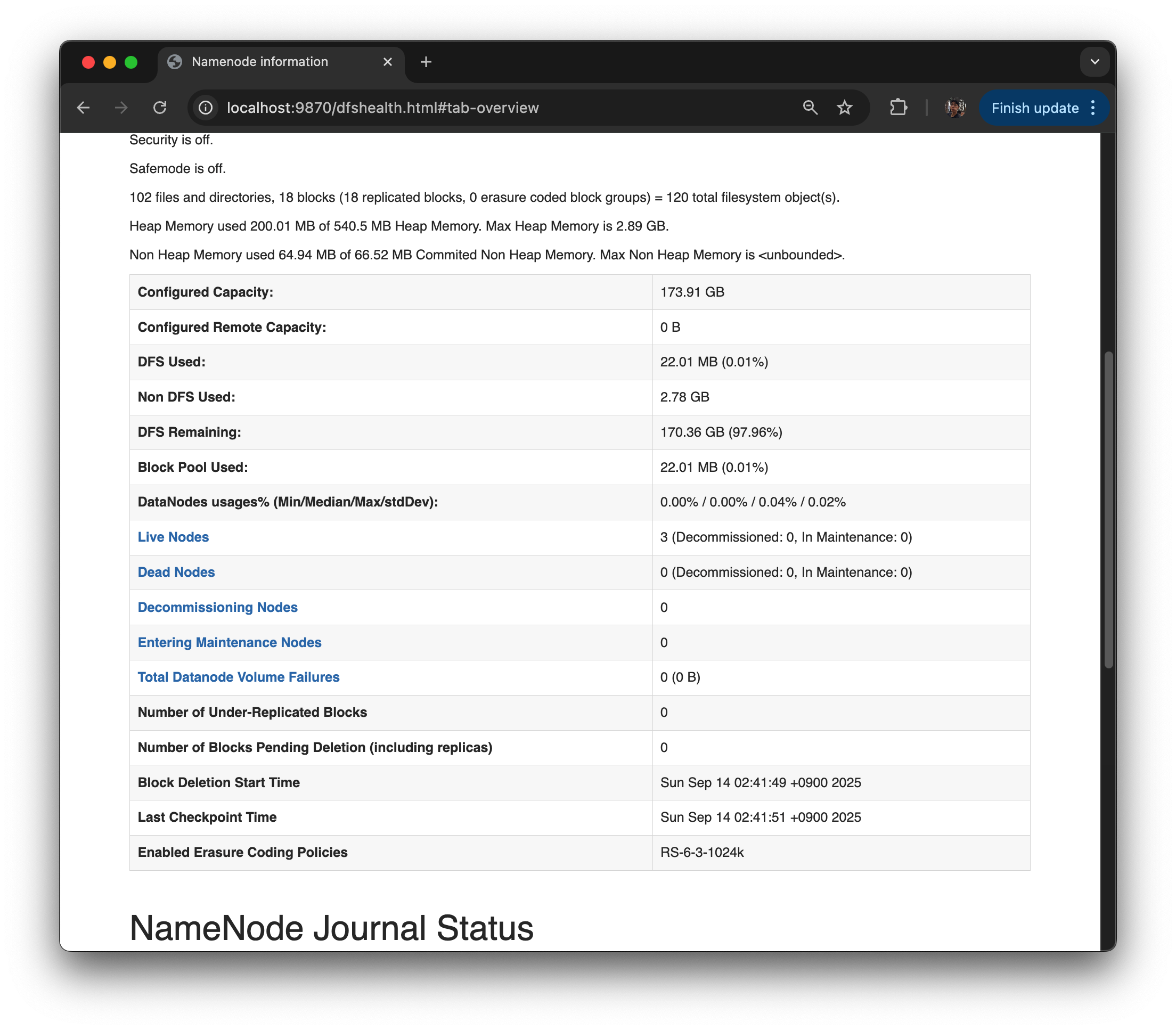
-
NameNode 상태나 기본적 Storage Disk의 Capacity 등이 나와 있음.
-
맨 위 메뉴 바에서 Datanode 페이지로 이동해 상태를 확인할 수 있음
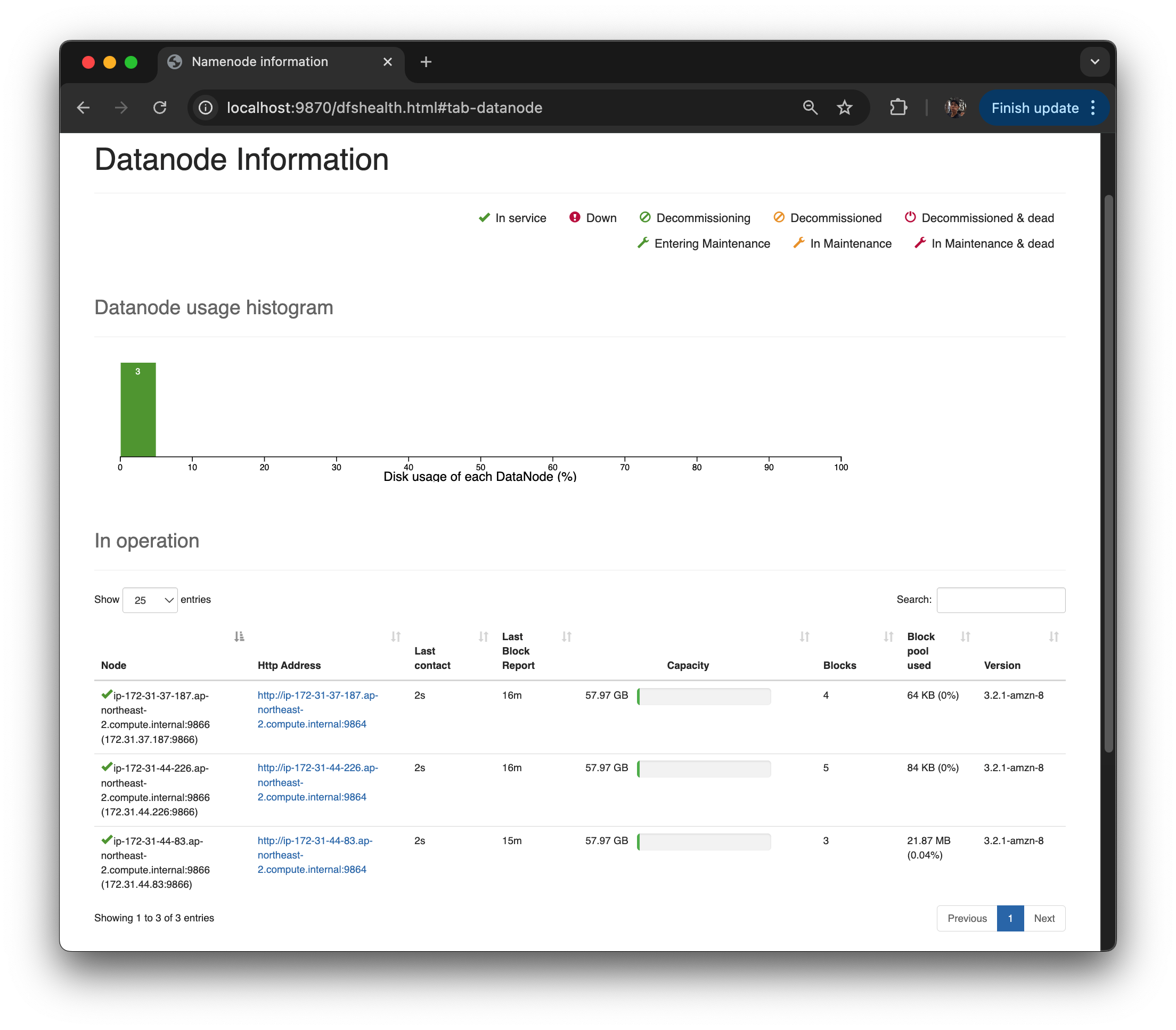
-
Utilities > Browse the file system 이거 잘 씀. 디렉토리 구조를, Unix 창에서 어렵게 확인 했었는데 UI 로 확인 가능
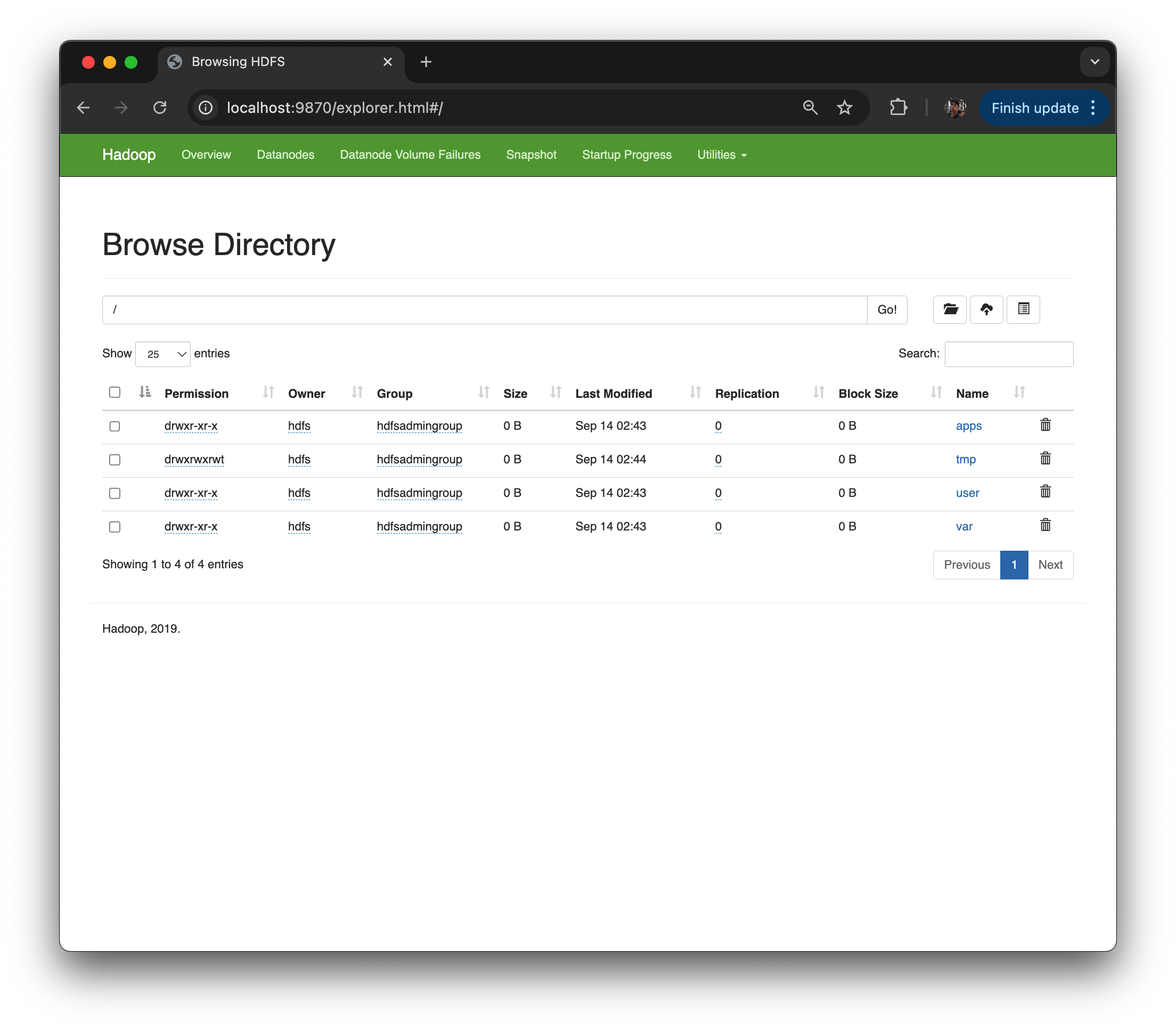
-
Metrics, logs, configuration XML, Thread Dump 등 볼 수 있음
4.2 SSH turnnel + dynamic port forwarding + proxy 로 웹인터페이스 redirect 가능하게 하기
다음은 Yarn 작업 웹인터페이스이다.
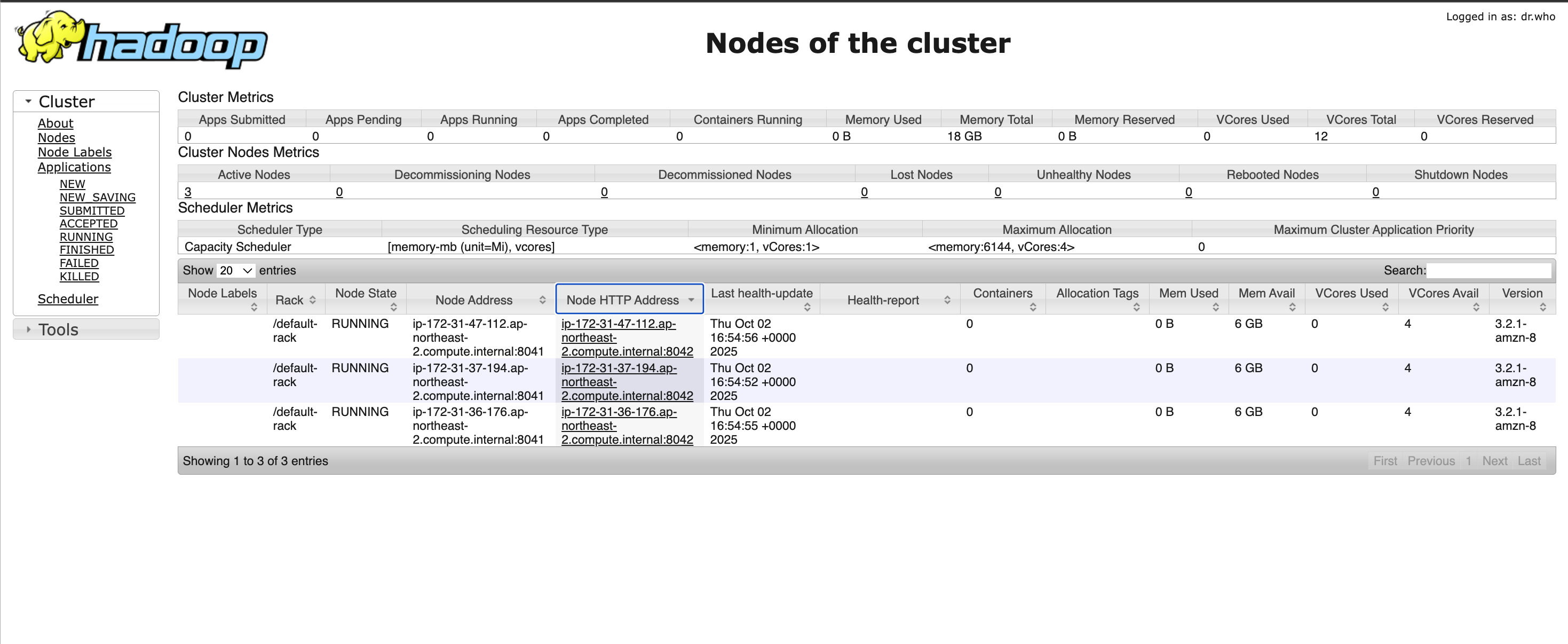
(위 그림에서 빨간색) Node 정보와 같이, cluster 가 서로를 알고 있는 주소는 AWS의 VPC 내부의 private dns 주소이다.
(위 그림에서 초록색) 웹인터페이스에는 다른 정보를 보기위한 링크들이 많은데, 이때 redirect 되는 주소는 저 private 주소를 기반으로한 주소이다. 4.1 에 언급한 방식으로 연결한다면, 이렇게 redirect 를 할 때마다
- port forwarding 을 한 경우, 포트가 달라질때마다 포트포워딩을 추가해야 한다.
포트 포워딩을 한 경우에는 접근하려는 포트가 달라질 때마다 새로운 포트 포워딩을 추가해야 한다. 예를 들어 로컬의 8011 포트와 EC2의 8011 포트를 연결했다고 하면, 내 브라우저에서
localhost:8011로 접속해 EC2가 제공하는 화면을 볼 수 있다. 하지만 EC2가 반환한 HTML 안에 프라이빗 IP 주소가 포함된 링크가 있다면, 해당 링크를 클릭했을 때 브라우저는http://<private-ip>:...주소로 접속을 시도하게 되고, 이는 로컬에서는 알 수 없는 주소이므로 연결에 실패한다. 비슷하게localhost:8088을 EC2의 8088 포트로 연결해도, YARN Tracking URL의 History 링크에 들어가면 EC2 내부용 프라이빗 DNS 주소를 가리키기 때문에 접속할 수 없다. 이런 경우에는 링크가 가리키는 프라이빗 DNS 주소를 확인한 뒤 해당 인스턴스의 퍼블릭 DNS를 찾아서 새로운 SSH 포트 포워딩을 설정해야 하며, 이후 브라우저에서 다시 로컬호스트로 접속해야 원하는 화면을 볼 수 있다. 결국 포트나 IP가 바뀔 때마다 이러한 과정을 반복해야 하므로 웹 인터페이스를 사용하는 목적이 크게 줄어든다.
- security group 으로 한경우, redirect된 private dns 를 public dns 로 수동으로 매번 바꿔야한다.
시큐리티 그룹으로 접근을 허용한 경우에는 리디렉션된 프라이빗 DNS를 퍼블릭 DNS로 매번 수동으로 바꿔야 한다. 이는 보안상 취약할 뿐 아니라 번거로운 방식이다. EMR 클러스터가 내부적으로 통신할 때 사용하는 주소는 모두 AWS VPC 내부에서만 유효한 프라이빗 DNS이므로, 우리가 브라우저로 받은 HTML에 프라이빗 DNS 기반 링크가 포함되어 있다면 그 상태로는 외부에서 접근할 수 없다. 결국 보안 그룹만으로는 이 문제를 해결할 수 없고, 포트 포워딩이나 다른 방식의 터널링을 사용해야 한다.

ssh turnneling 을 이용한 dynamic port forwarding과 proxy 플러그인을 이용해서 이런 불편함을 해결하고, 보안을 해치지 않을 수 있다.
4.2.1 SSH turnnel 을 이용한 dynamic port forwarding
ssh -i $key_file -N -D 8157 hadoop@$your_ec2_public_dns-
-D: Dynamic port forwarding -
8157: 내 노드에서 연결할 포트- 원하는 포트로 바꿔도된다.
-
hadoop@$your_ec2_public_dns: 대상이 되는 유저와 노드- 이 노드의 유저의 모든 경로에 8157이라는 포트로 접근할 수 있게 됨
4.2.2 브라우저 플러그인을 이용한 proxy 설정
- Chrome
- https://chrome.google.com/webstore/category/extensions 접속
- Proxy SwitchyOmega 설치
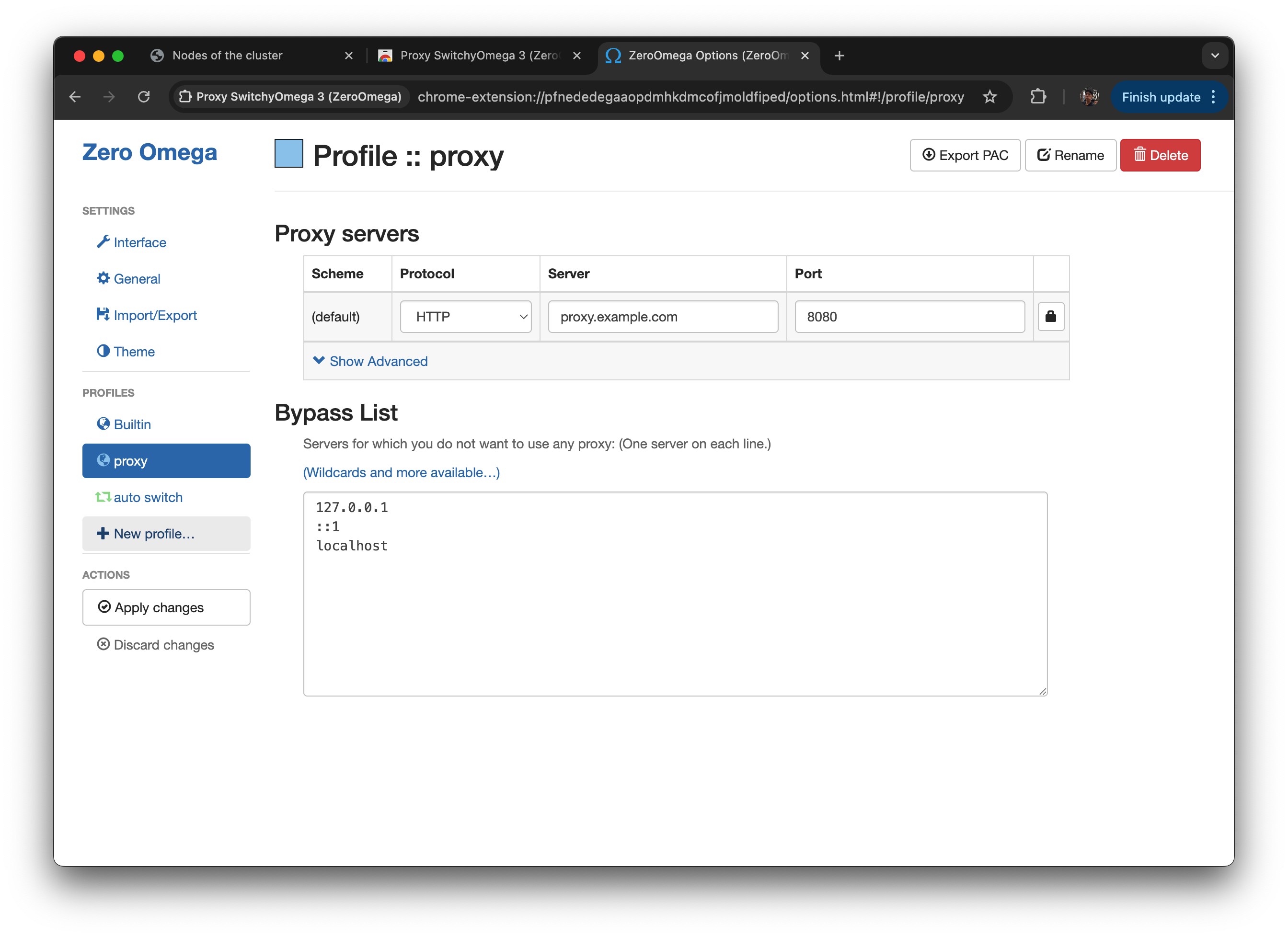
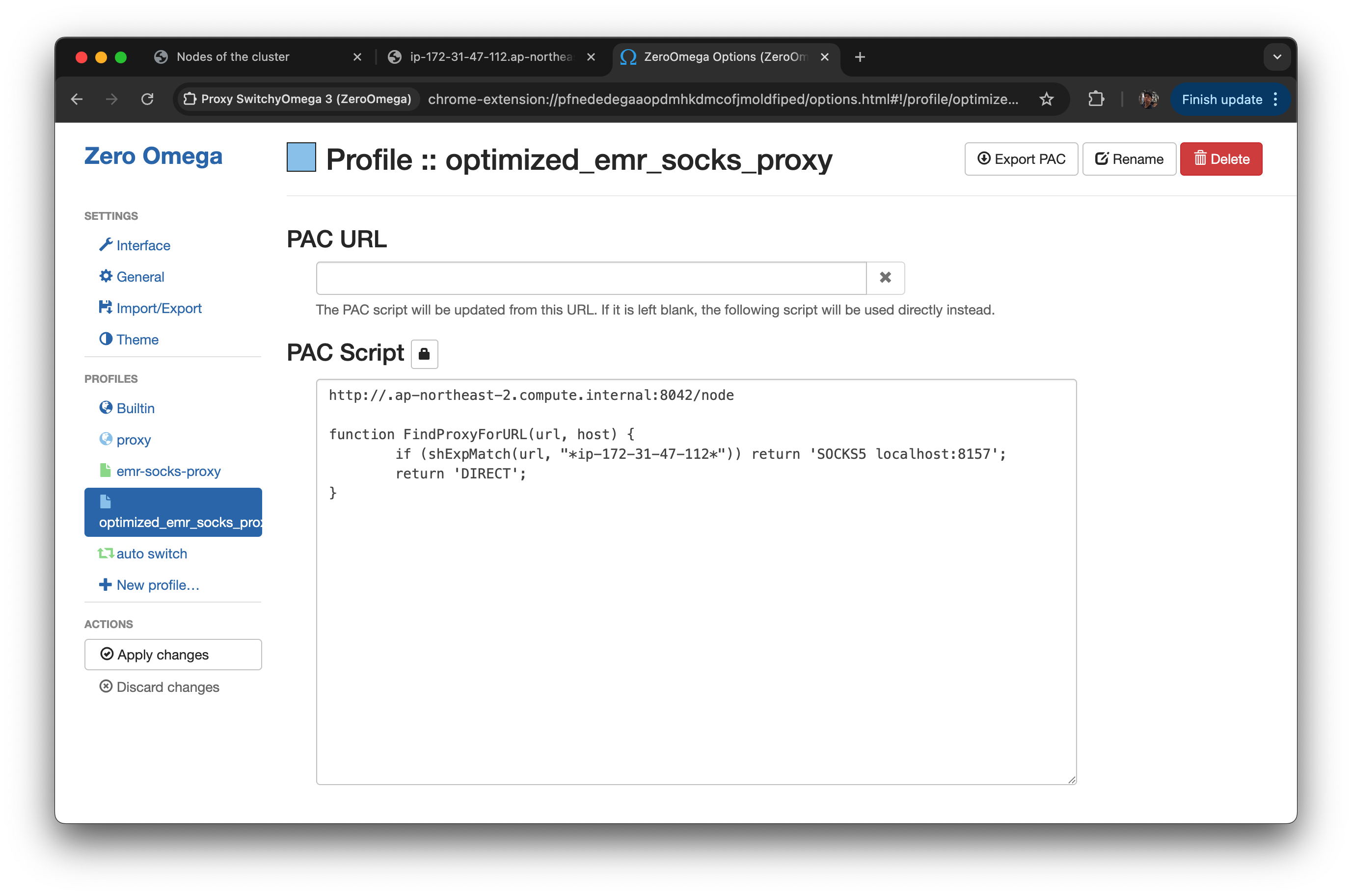
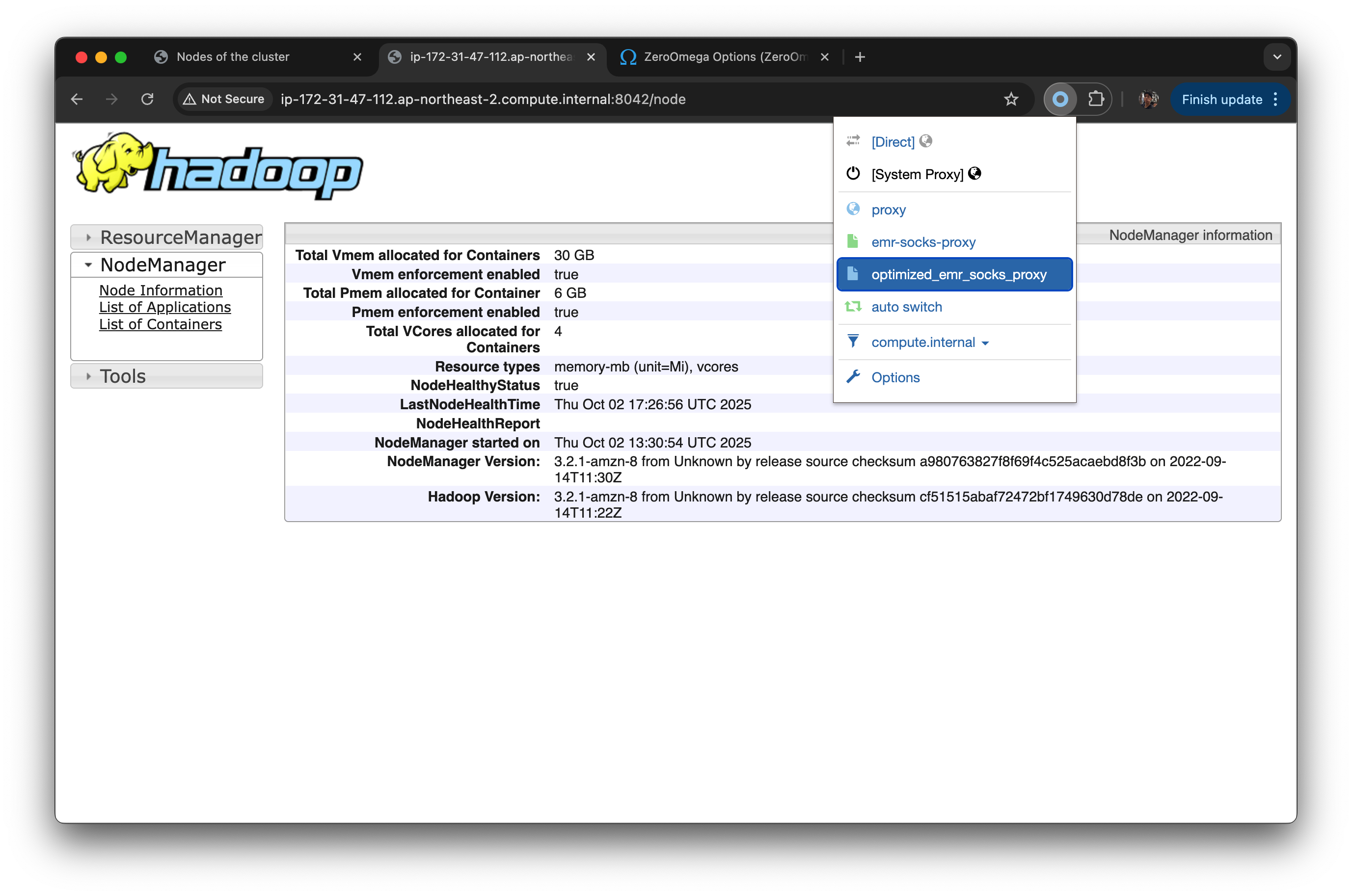
emr-socks-proxy라는 프로파일 생성
-
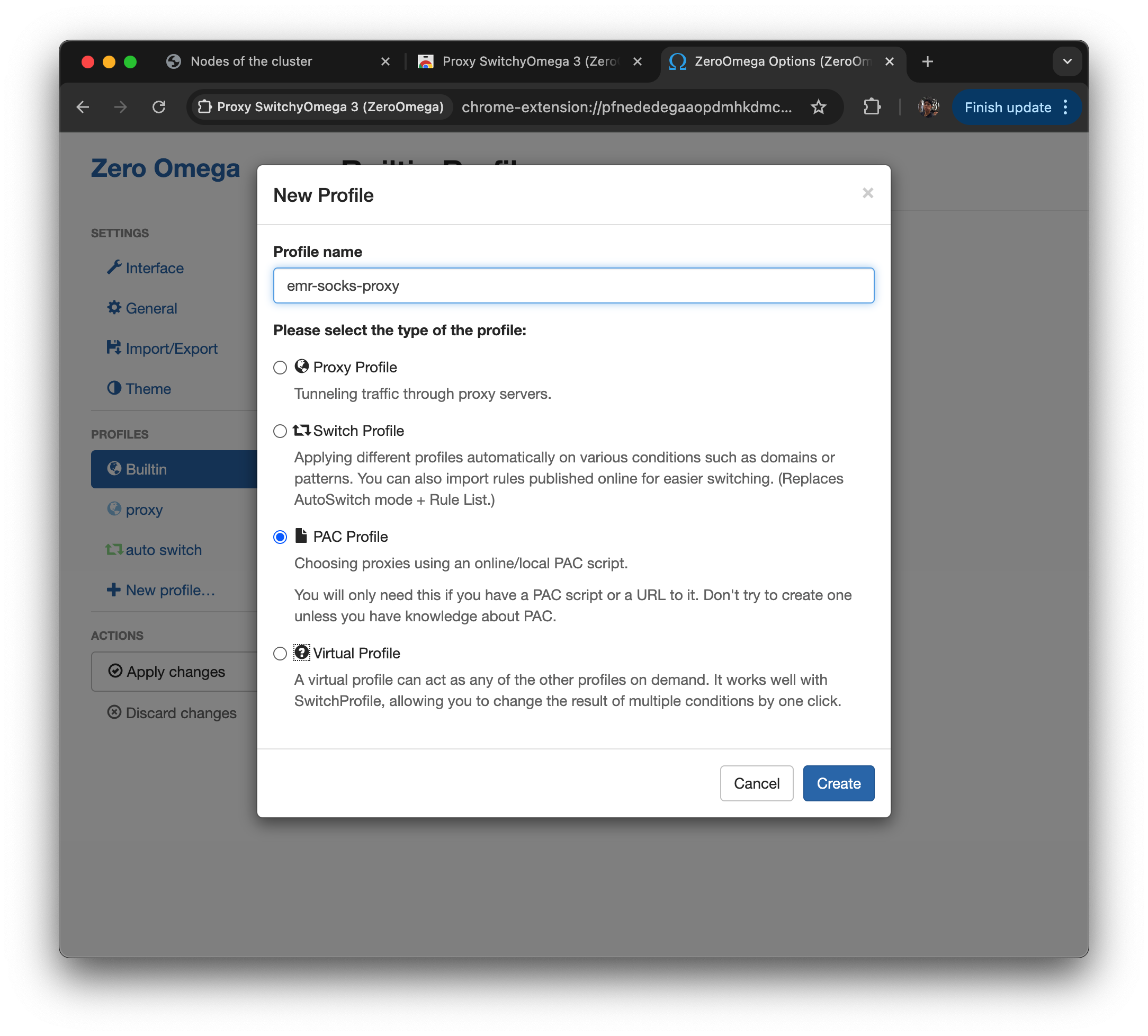
PAC profile 선택
-
아래 PAC 스크립트를 입력
function FindProxyForURL(url, host) {
if (shExpMatch(url, "*ec2*.amazonaws.com*")) return 'SOCKS5 localhost:8157';
if (shExpMatch(url, "*ec2*.compute*")) return 'SOCKS5 localhost:8157';
if (shExpMatch(url, "http://10.*")) return 'SOCKS5 localhost:8157';
if (shExpMatch(url, "*10*.compute*")) return 'SOCKS5 localhost:8157';
if (shExpMatch(url, "*10*.amazonaws.com*")) return 'SOCKS5 localhost:8157';
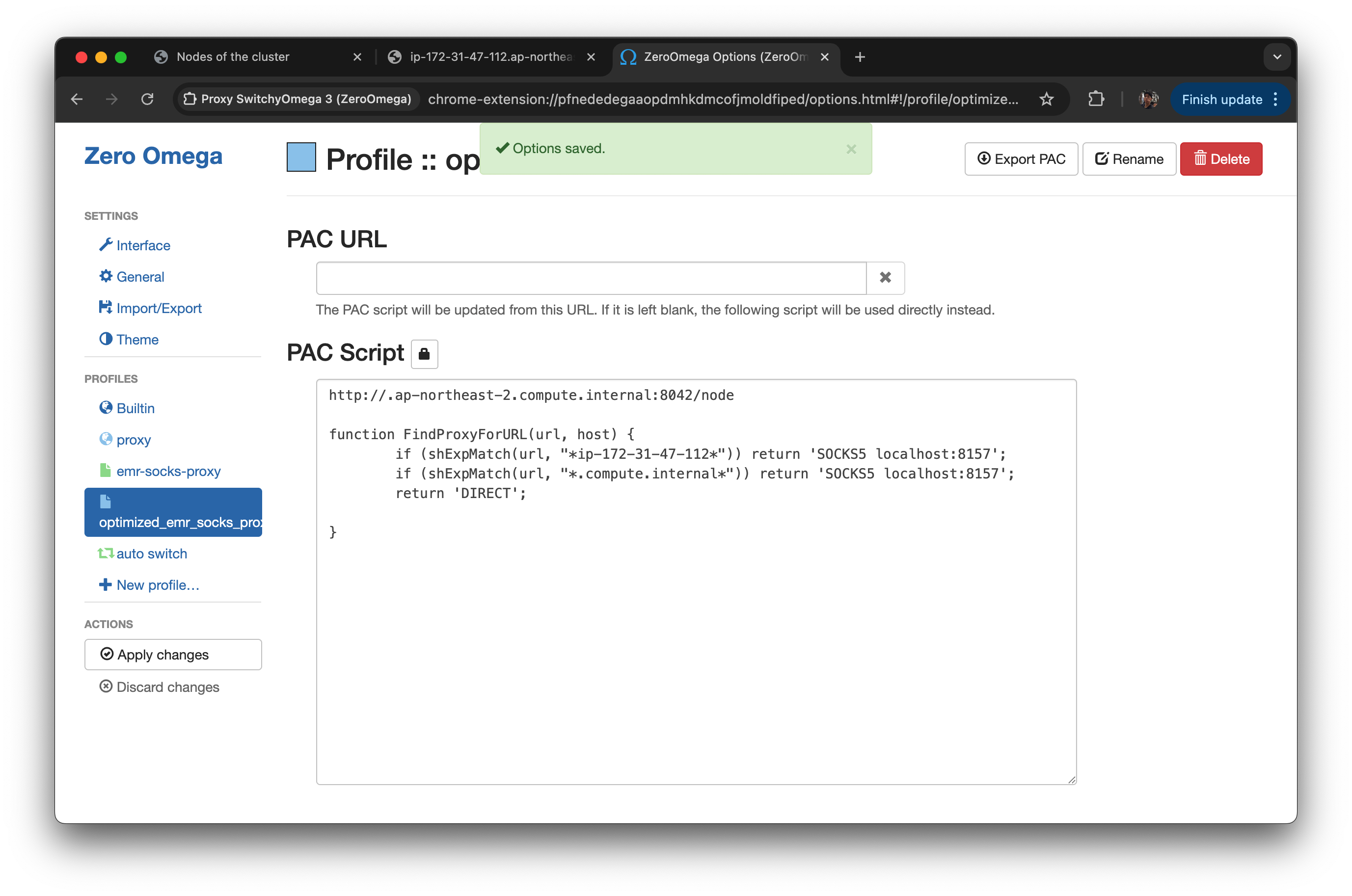
if (shExpMatch(url, "*.compute.internal*")) return 'SOCKS5 localhost:8157';
if (shExpMatch(url, "*ec2.internal*")) return 'SOCKS5 localhost:8157';
return 'DIRECT';
}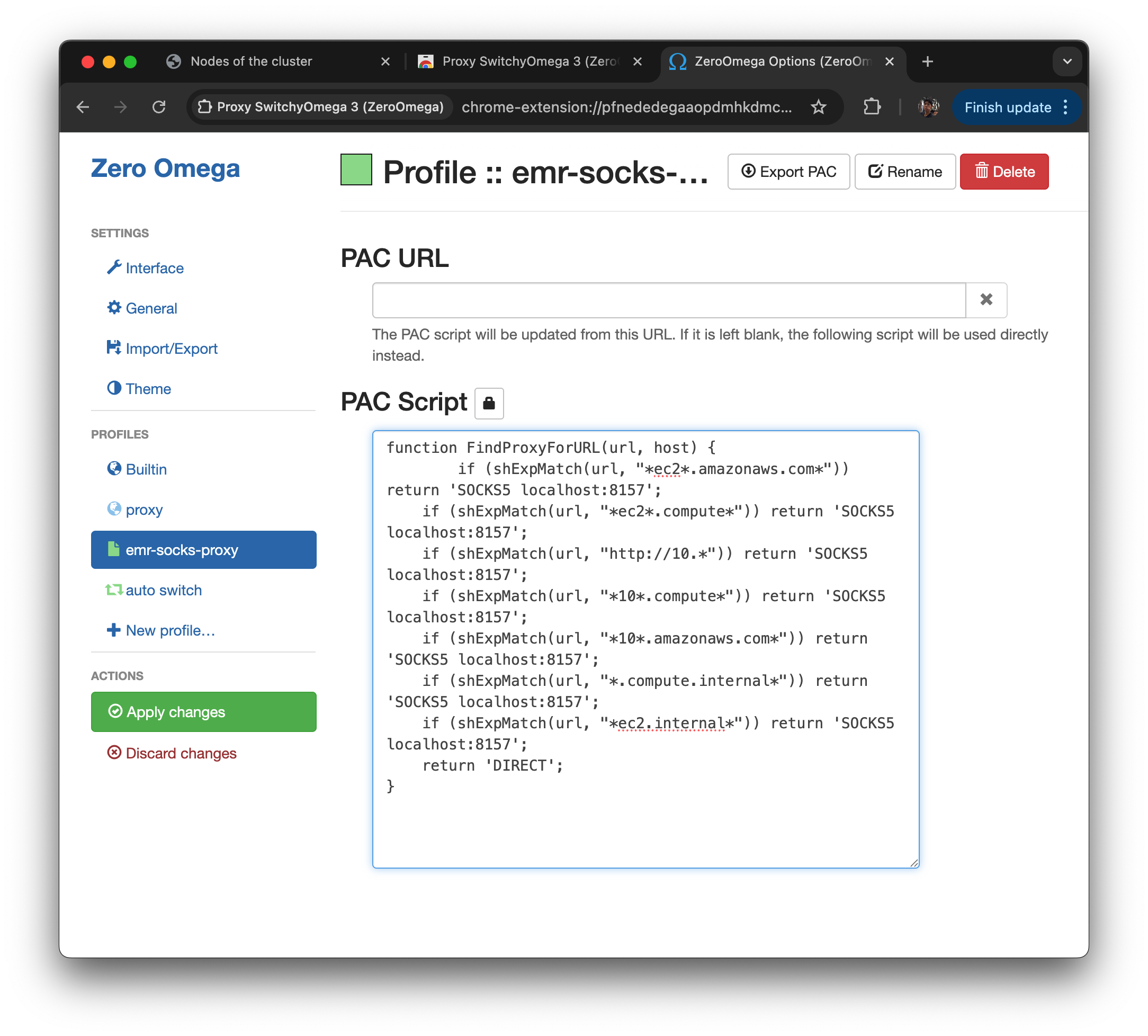
- shell expression match는 주어진 URL이 특정 패턴과 일치하는지를 확인하는 방식이다. 스크립트에서 정의된 패턴과 URL이 일치하면 해당 요청은 SOCKS5 localhost:8157로 전달된다. 여기서 지정된 패턴들은 AWS에서 사용하는 프라이빗 주소 체계(.amazonaws.com, .compute.internal, 10.* 등)에 해당한다.
- 따라서 사실상 대부분의 프라이빗 주소 요청은 로컬의 8157 포트를 통해 SSH SOCKS 프록시로 전달되며, 이는 우리가 설정한 EMR 노드로 연결된다.
- 다만 이 규칙은 EMR과 같은 AWS 내부 프라이빗 주소 체계에만 적용되므로 일반적인 외부 주소에는 영향을 주지 않는다. EMR의 주요 웹 인터페이스들이 주로 primary active 노드에서 실행되기 때문에 이러한 PAC 설정을 통해 해당 웹 UI에 접근할 수 있도록 구성한 것이다.
- Apply changes
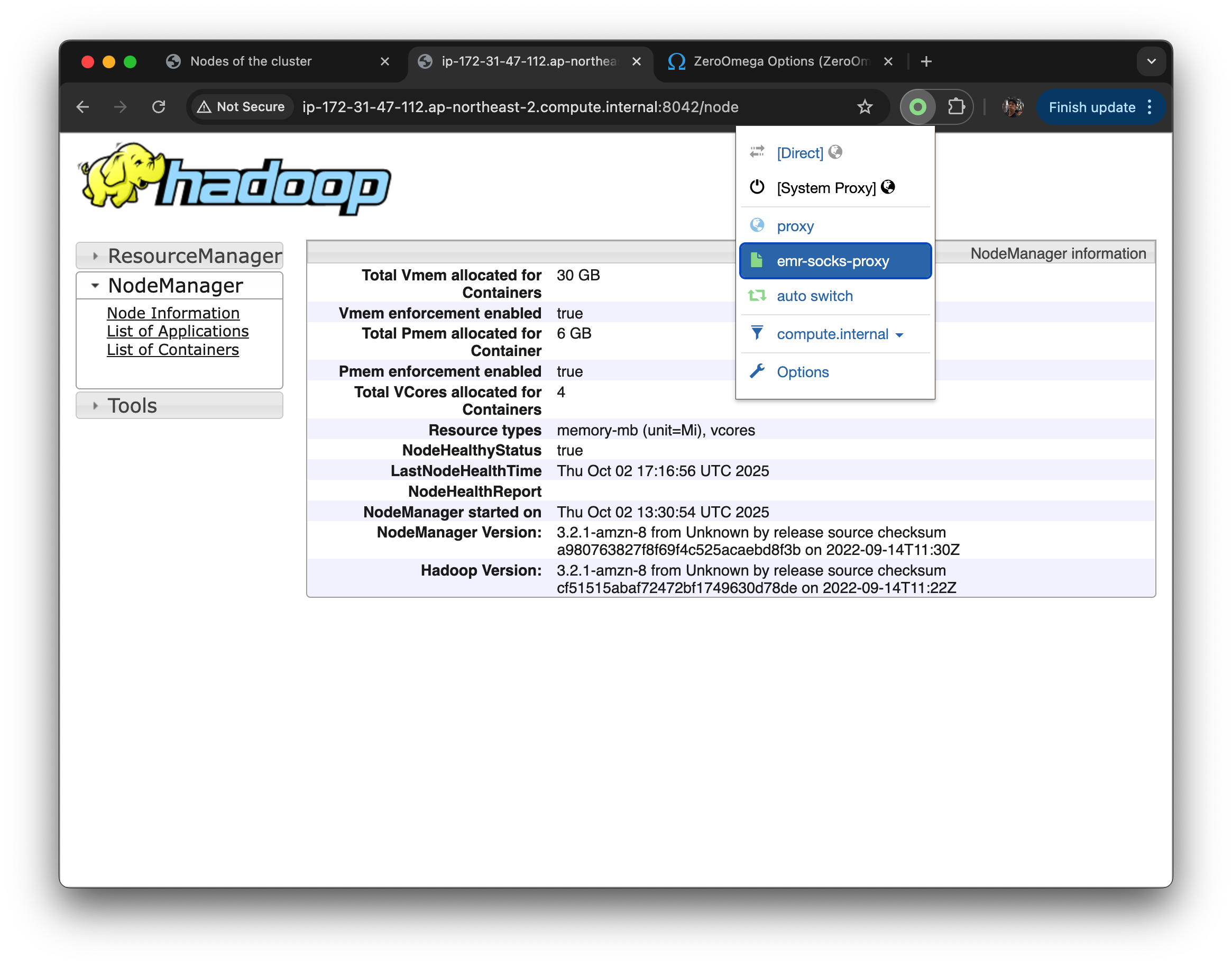
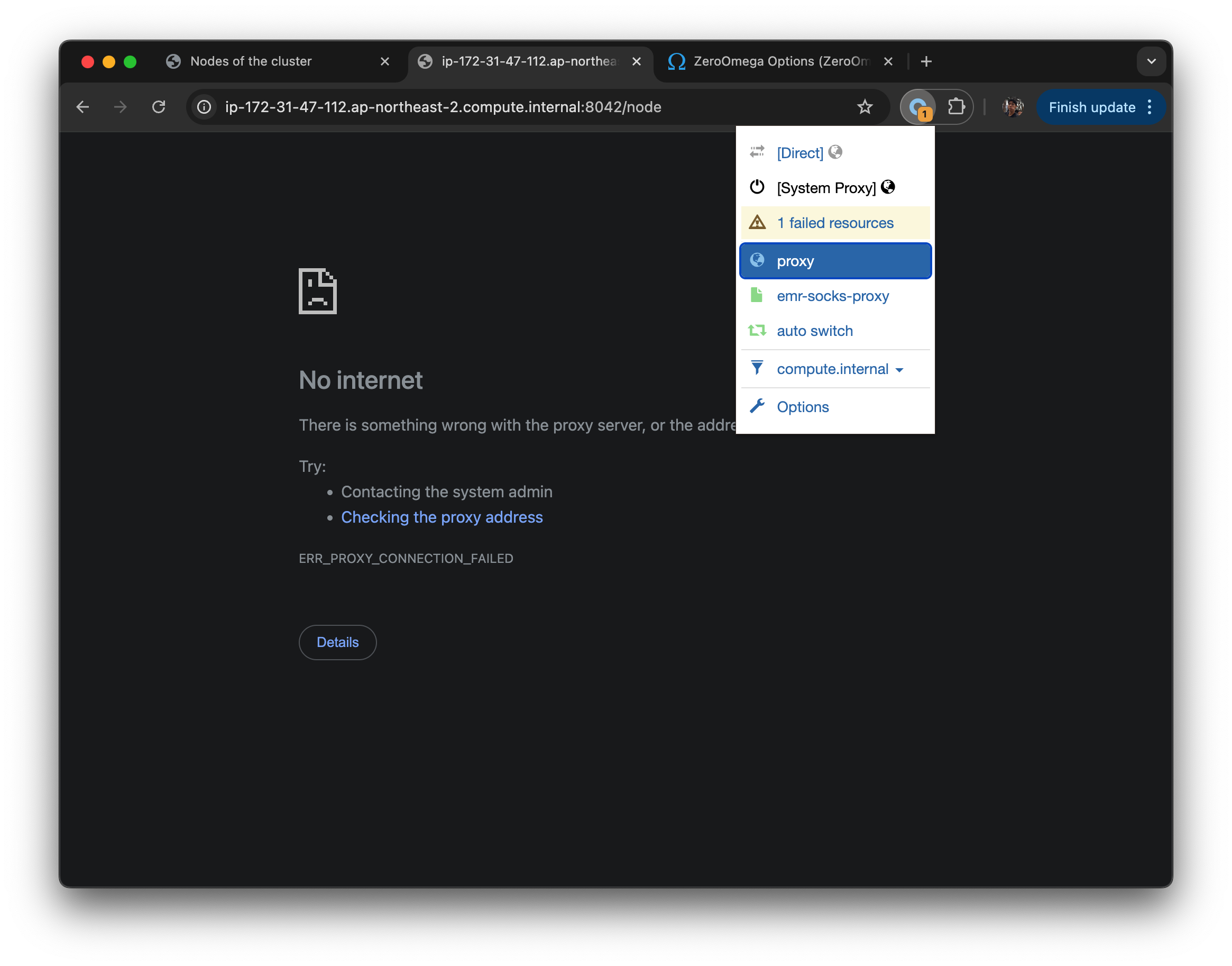
위 세팅을 마쳤으면, 다시 redirect url 을 클릭했을때 private dns 주소를 못찾을 때, Proxy SwitchyOmega 를 선택하고 emr-socks-proxy 를 선택하면 설정한 프로파일로 proxy할 수 있다.
- 꼭 ssh turnnel dynamic port forwarding 맺어진 상태여야한다.
- 내가 브라우저에서 http://10.0.0.12:8088 (YARN UI 같은 프라이빗 주소) 접속 시도.
- PAC 스크립트가 "이건 10.* 대역이네? → SOCKS5 localhost:8157 써라" 라고 결정.
- 브라우저는 내 로컬 8157 포트로 트래픽을 보냄.
- 8157 포트는 SSH Dynamic Port Forwarding이 켜져 있음 → SSH 터널을 타고 EC2 노드 안으로 전달.
- 결과적으로, 내가 로컬 브라우저에서 EMR 내부 주소(프라이빗 UI)에 접근할 수 있게 됨.
브라우저 요청 URL
│
▼
PAC 스크립트 검사 → "*ec2*.amazonaws.com*" 일치
│
▼
SOCKS5 localhost:8157 (프록시 서버로 전달)
│
▼
SSH 터널 타고 EC2 노드 내부망으로
│
▼
EC2 노드가 AWS 내부 서버에 접속
│
▼
응답을 다시 SSH 터널 통해 브라우저로 전달optimized PAC Script
ssh -i fastcampus_de.pem -N -L 9870:ec2-13-125-43-71.ap-northeast-2.compute.amazonaws.com:9870 hadoop@ec2-13-125-43-71.ap-northeast-2.compute.amazonaws.comhttp://localhost:9870/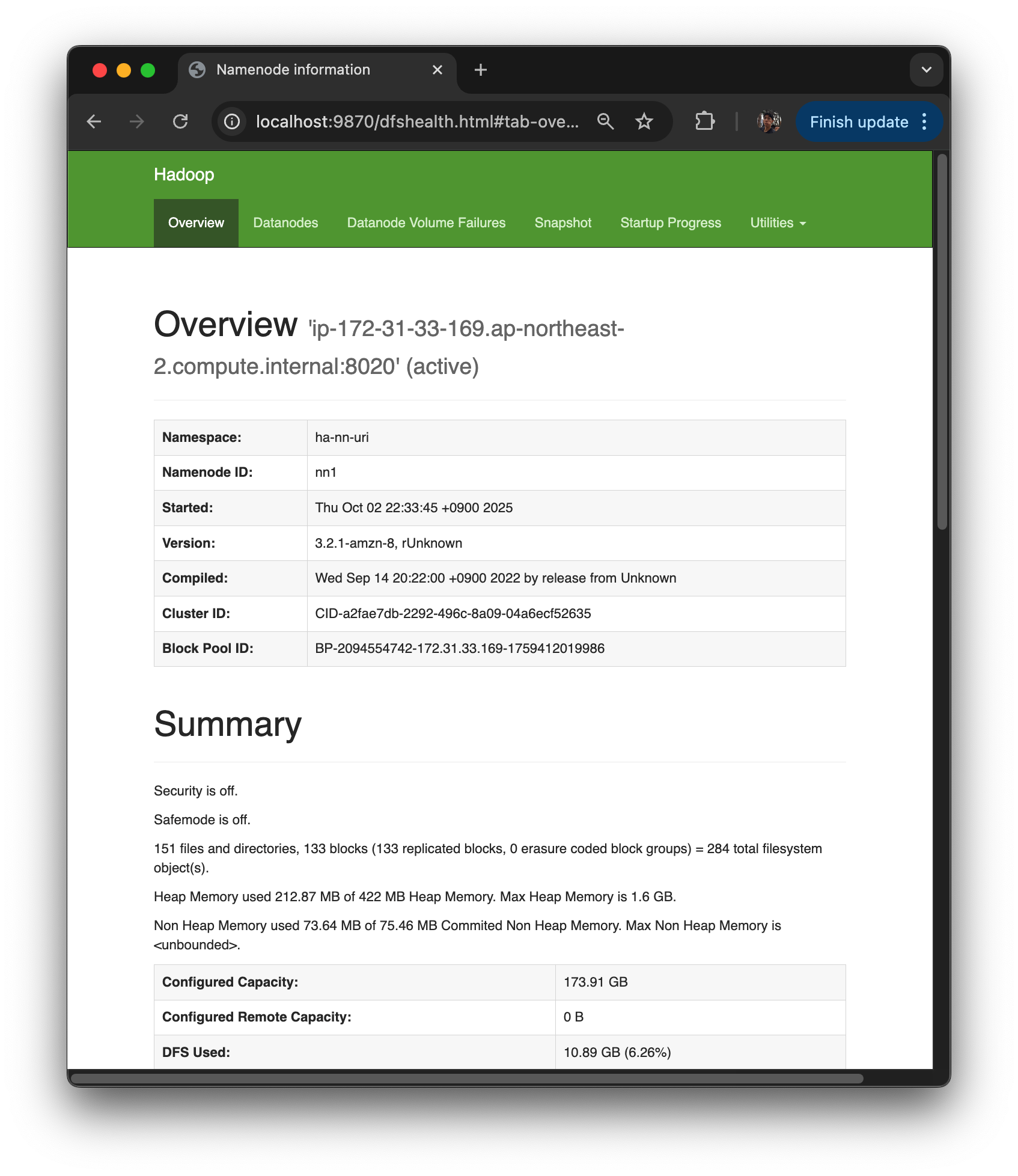
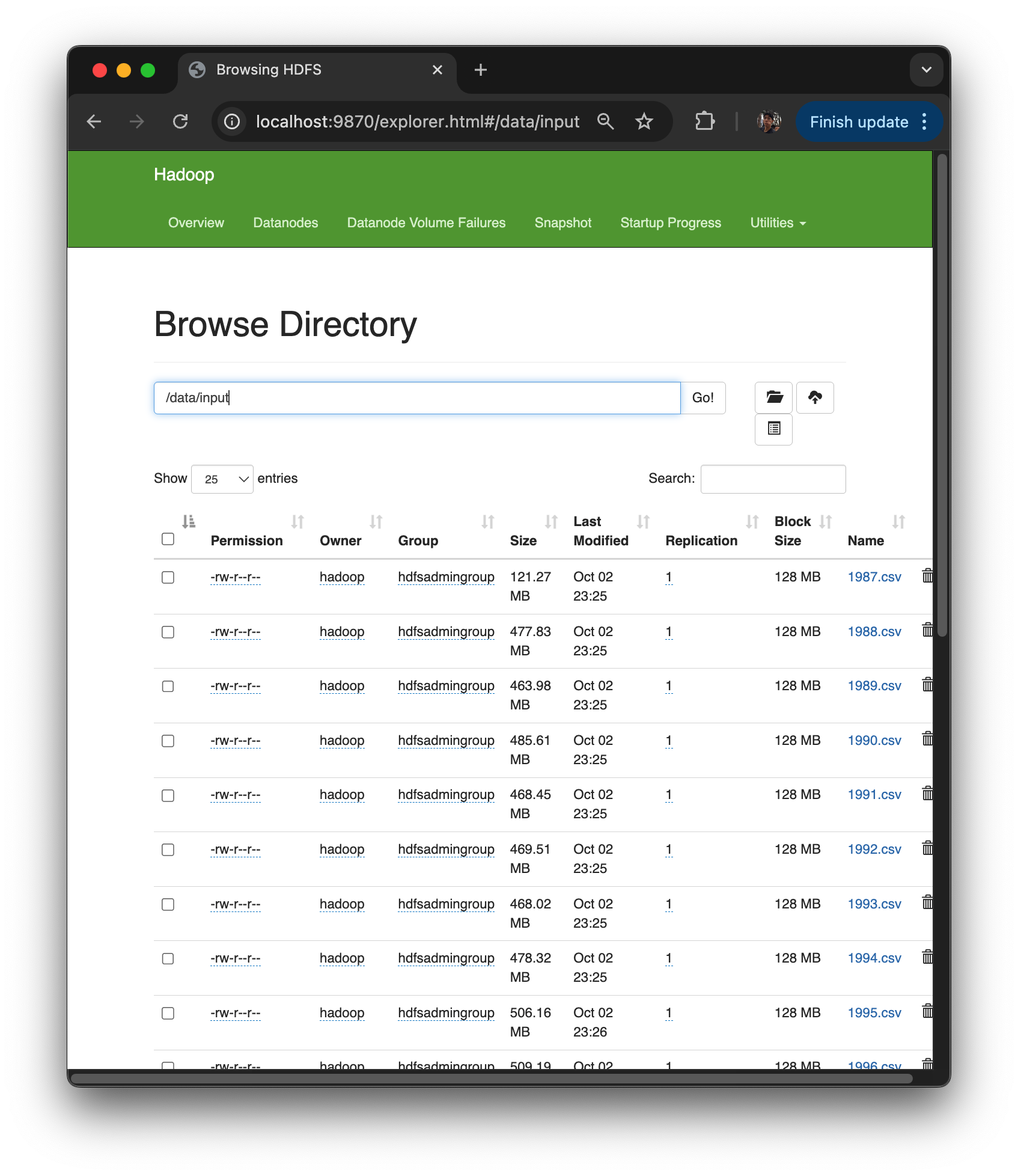
utilities/browse directory
파일 시스템.
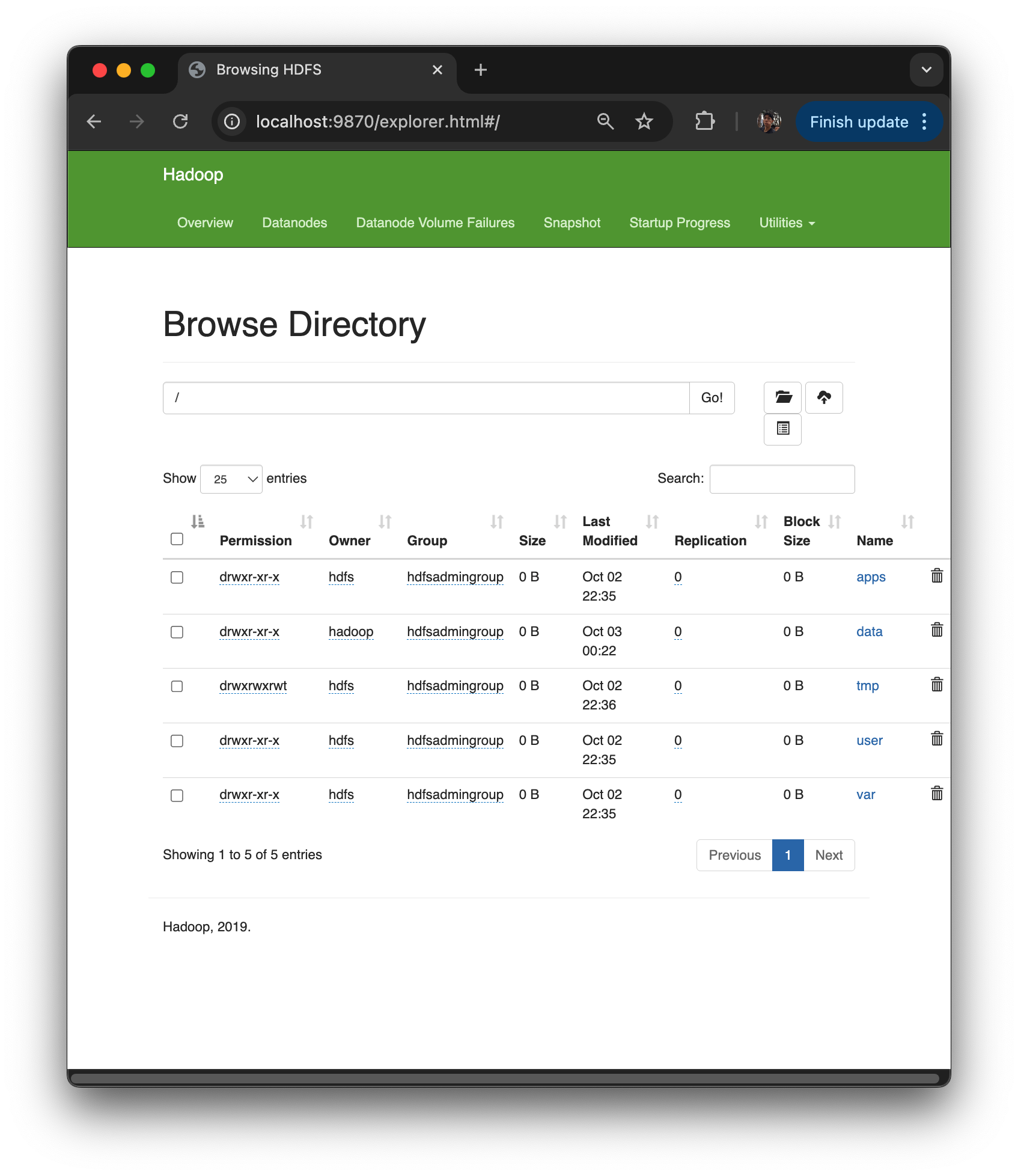
/data/input 보면 다운받았던 파일들 보임
jun ~/GitStudy/Data_Engineer/aws/keys main ±
ssh -i fastcampus_de.pem -N -L 8088:ec2-13-125-43-71.ap-northeast-2.compute.amazonaws.com:8088 hadoop@ec2-13-125-43-71.ap-northeast-2.compute.amazonaws.com
~ lsof -i :8088
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
ssh 6692 jun 7u IPv6 0xbee00dd36d8d1aed 0t0 TCP localhost:radan-http (LISTEN)
ssh 6692 jun 8u IPv4 0xe16572bc85ddcbf5 0t0 TCP localhost:radan-http (LISTEN)
web : localhost:8088 접속
DNS_PROBE_FINISHED_NXDOMAIN
좋은 상황 정리해주셨어요 👍
지금 하신 건 SSH 터널링으로 Hadoop/YARN ResourceManager Web UI (8088 포트)를 로컬에서 접근하려는 시도인데,
DNS_PROBE_FINISHED_NXDOMAIN 에러가 나는 이유는 DNS 문제가 아니라, 브라우저에서 URL을 잘못 열고 있어서입니다.
ssh -i fastcampus_de.pem -N -L 8088:ec2-13-125-43-71.ap-northeast-2.compute.amazonaws.com:8088 hadoop@ec2-13-125-43-71.ap-northeast-2.compute.amazonaws.com
👉 로컬 PC의 localhost:8088 을 원격 EC2의 8088 포트로 포워딩 했음.
lsof -i :8088 확인 결과, ssh 프로세스가 localhost:8088을 LISTEN 중 → 포트 포워딩 성공.
그런데 접속은 DNS_PROBE_FINISHED_NXDOMAIN 으로 실패.
주소창에 http://localhost:8088 으로 접속해보시고, 안 되면 EC2 안에서 curl http://localhost:8088 으로 먼저 확인해보세요.
curl http://localhost:8088
This is standby RM. The redirect url is: /
This is standby RM. The redirect url is: /
이건 Hadoop YARN ResourceManager가 HA(High Availability) 모드로 실행되고 있어서,
지금 접속한 ResourceManager는 Standby (대기) 상태라는 의미입니다.
즉, Active ResourceManager가 따로 있고, 웹 UI는 Active 쪽에서만 제대로 뜹니다.
어느 노드가 Active인지 확인
EC2 내부에서:
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2이런 식으로 ResourceManager ID별 상태를 확인할 수 있습니다.
Active → 정상 웹 UI 제공
Standby → 위처럼 리다이렉트만 뜸
보통 HA 설정에서는 RM 두 대가 존재하고,
http://<active-rm-host>:8088 → 정상 동작
http://<standby-rm-host>:8088 → standby 메시지
현재 노드에서 yarn node -list 로 로 Active RM 확인 가능.
yarn node -list
2025-10-02 16:26:49,121 INFO client.AHSProxy: Connecting to Application History server at ip-172-31-33-169.ap-northeast-2.compute.internal/172.31.33.169:10200
2025-10-02 16:26:49,228 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
Total Nodes:3
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
ip-172-31-36-176.ap-northeast-2.compute.internal:8041 RUNNING ip-172-31-36-176.ap-northeast-2.compute.internal:8042 0
ip-172-31-47-112.ap-northeast-2.compute.internal:8041 RUNNING ip-172-31-47-112.ap-northeast-2.compute.internal:8042 0
ip-172-31-37-194.ap-northeast-2.compute.internal:8041 RUNNING ip-172-31-37-194.ap-northeast-2.compute.internal:8042 0
Failing over to rm2
👉 이 메시지가 핵심입니다.
ResourceManager HA 환경에서 rm1이 Standby라서, 클라이언트가 자동으로 rm2(Active RM)로 failover 했다는 의미예요.
현재 상태 요약
클러스터 노드는 총 3개 (NM 3개 RUNNING) → 정상.
ResourceManager는 HA 모드로 설정됨.
지금 ssh 포트포워딩을 건 노드는 Standby RM.
따라서 웹에서 This is standby RM만 보임.
Active RM 호스트 찾기
지금은 rm2가 Active 상태예요.
확인은 아래처럼:
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
Active → 현재 UI 제공Standby → redirect 메시지
[hadoop@ip-172-31-33-169 datasource]$ yarn rmadmin -getServiceState rm1 standby [hadoop@ip-172-31-33-169 datasource]$ yarn rmadmin -getServiceState rm2 active [hadoop@ip-172-31-33-169 datasource]$rm2 노드가 뭔지 어떻게 알아?
yarn-site.xml 확인
YARN ResourceManager HA 설정은 yarn-site.xml 안에 들어있습니다.
EMR: /etc/hadoop/conf/yarn-site.xml
ec2 노드에서
vi /etc/hadoop/conf/yarn-site.xml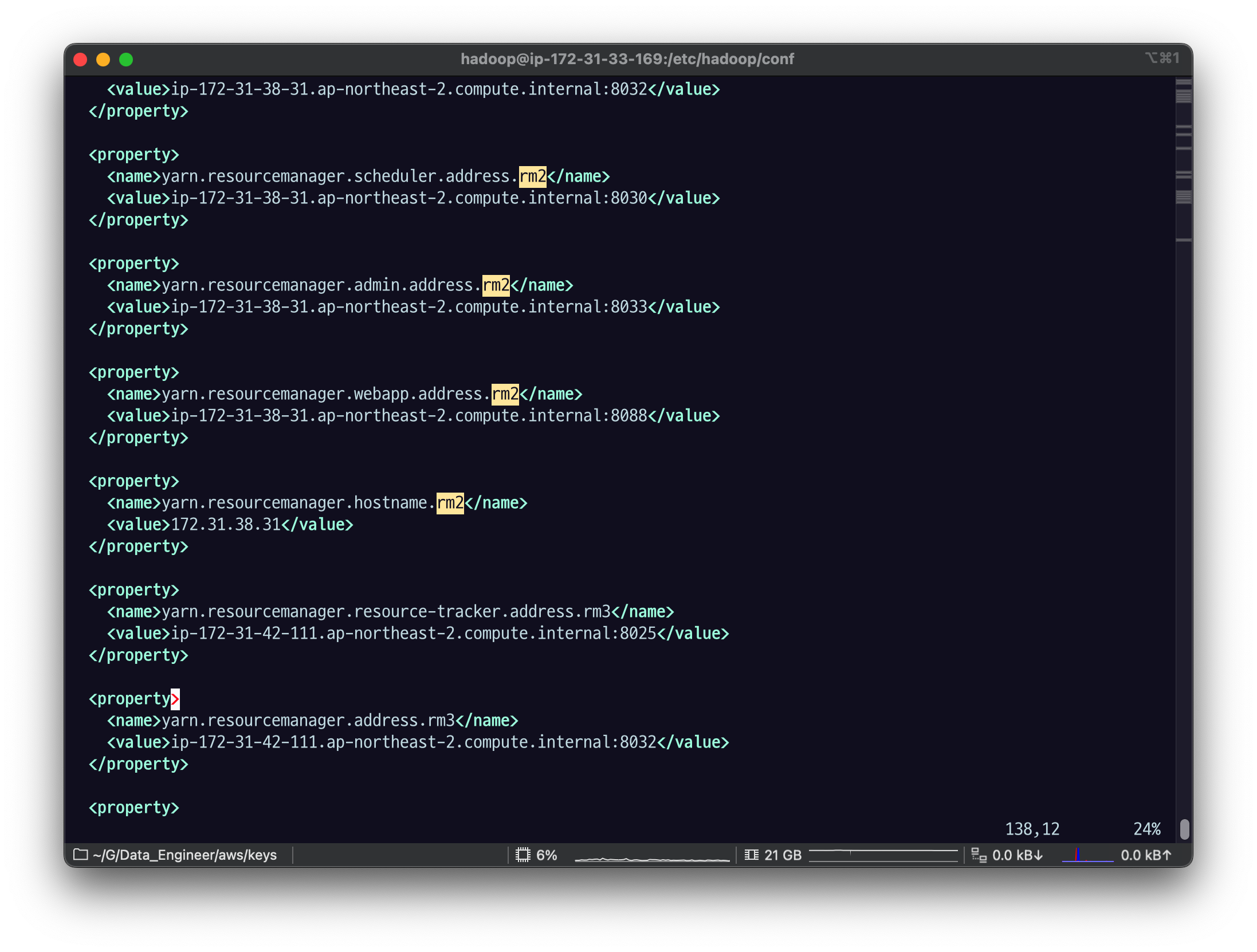
주소 찾았고
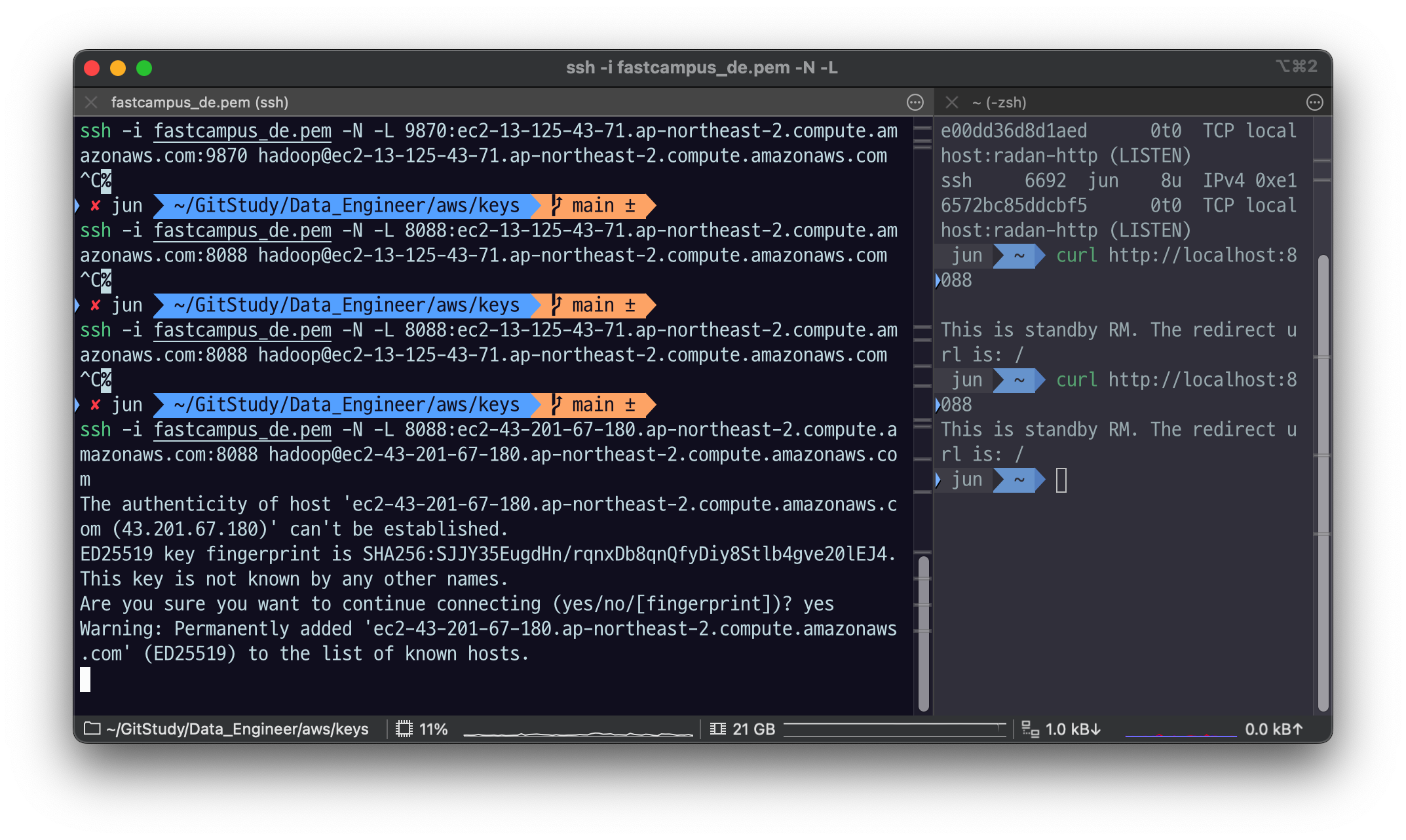
해당 ec2 public DNS name 으로 다시 시도.
ㅠㅠㅠㅠ 드디어 되었다 이 지독한 녀석
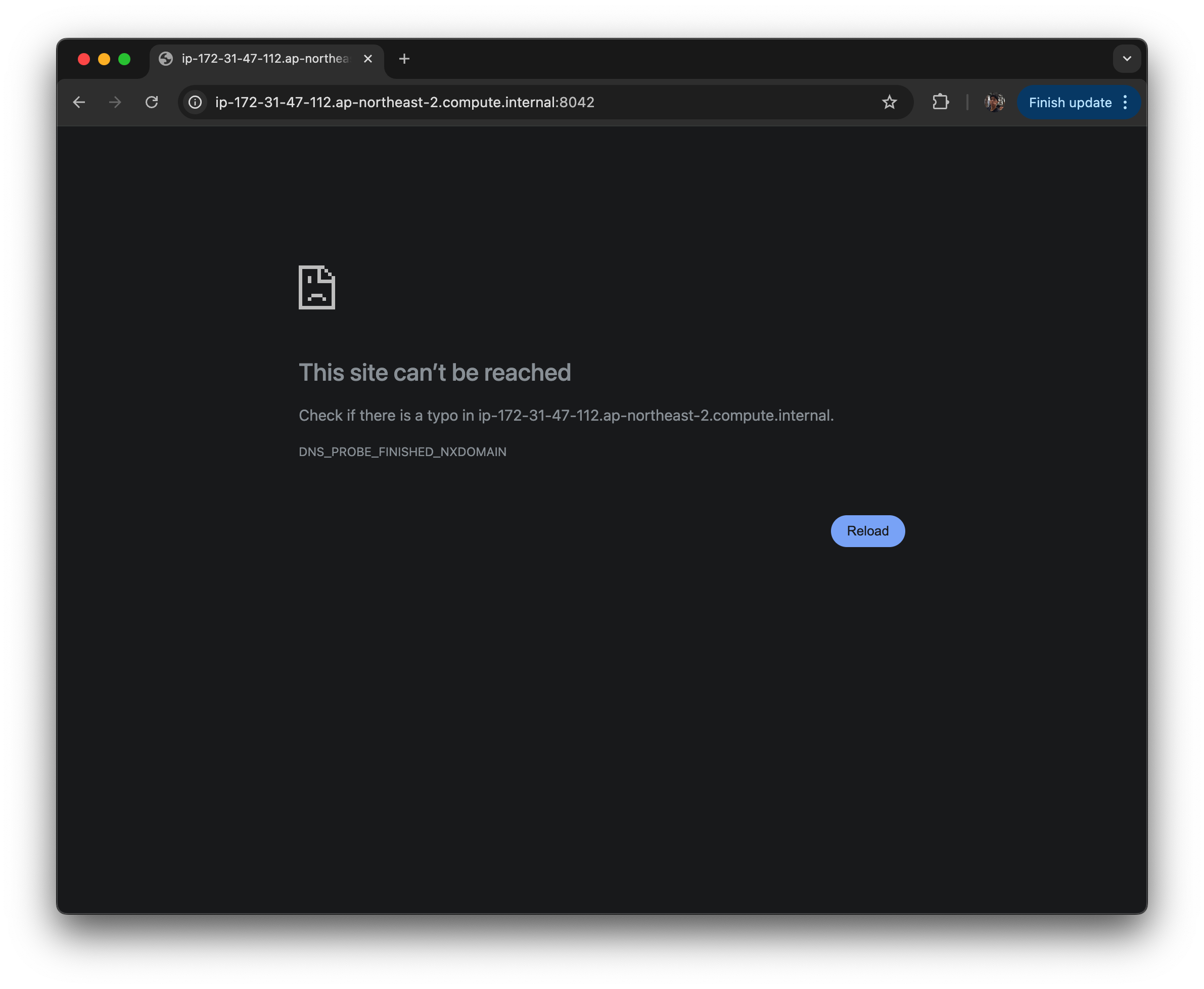
여기에서 클러스터에 있는 job 목록을 볼 수 있다.
job목록에서 tracking url을 입력하면
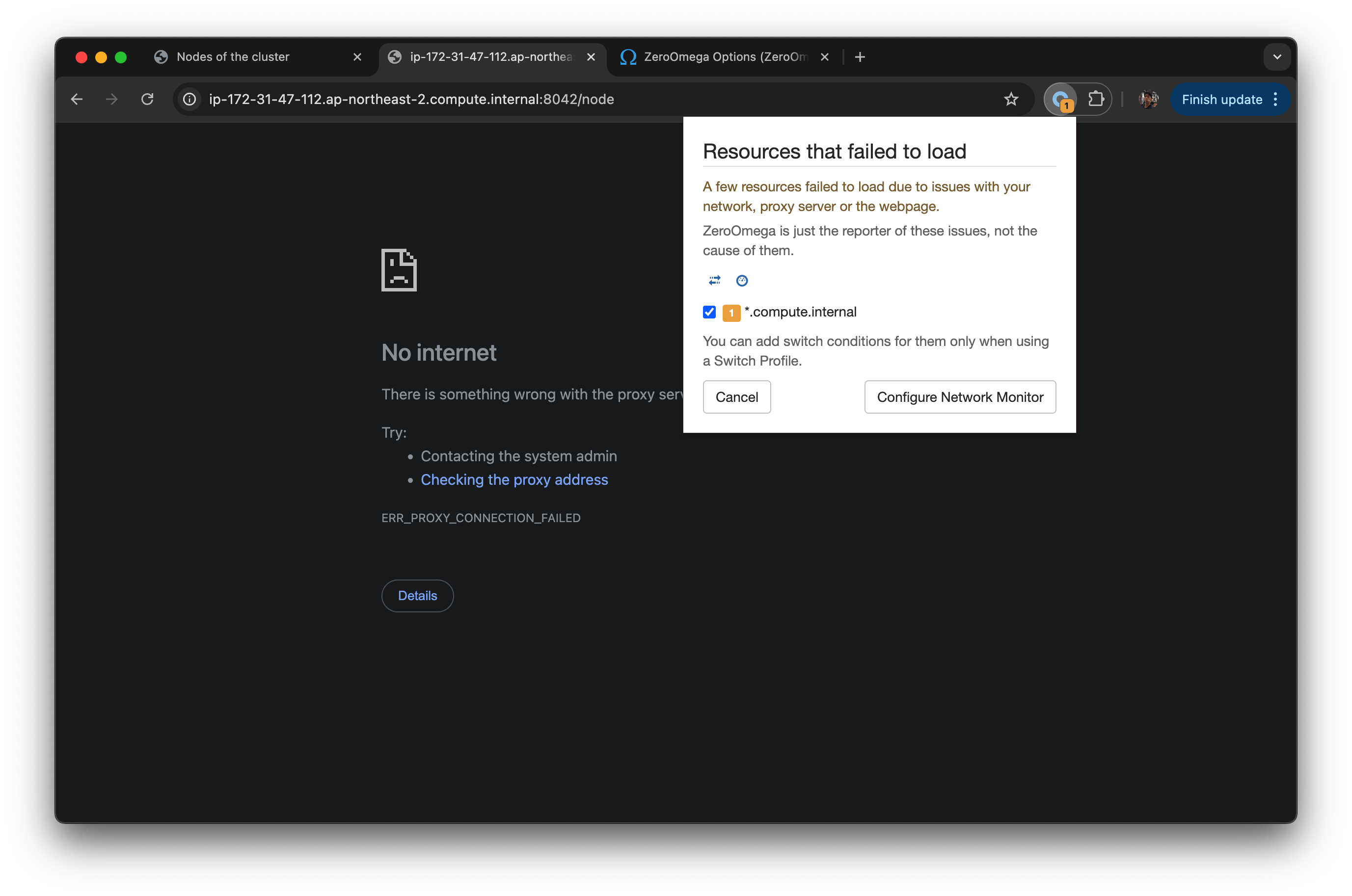
사이트에 도달할 수 없다고 된다.
nodes/ Node HTTP Address 를 클릭 해도 같은 상황 발생.
