3 Hadoop Name Node HA
3.1 HDFS Name Node HA가 필요한 이유
Hadoop v1.x 버전 까지는 namenode 는 SPOF(single point of failure)였다.
Hadoop 의 기본 아키텍처는 namenode를 master, datanode 들을 slave 로 하는 master-slave 구조이다.
이 중 namenode 는 하나의 인스턴스고, datanode 는 수평적 확장이 가능했으므로 namenode는 bottleneck 이 되기 쉬웠다.
namenode 가 이용 불가능한 상태라면, datanode가 아무리 많더라도 클러스터 전체가 이용 불가능해진다.
초기 버전에서는 namenode의 데이터 유실을 방지하는 secondary namenode 가 있었지만 Availability 문제를 완전히 해결하지는 못했다.
이러한 상태라면 예상치 못한 장애 뿐만 아니라, 계획된 업그레이드나 업데이트를 위해서 downtime 이 발생할 수 밖에 없었다.
3.2 HDFS HA Architecture
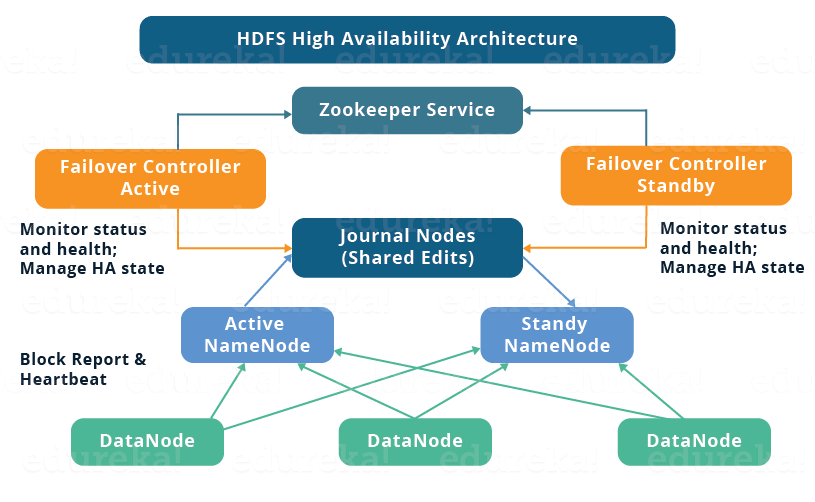
https://www.edureka.co/blog/how-to-set-up-hadoop-cluster-with-hdfs-high-availability/
알고넘어가면 좋을 게
가장 기본 구성요소는 Active랑 Standby 두 가지 역할의 Namenode가 생겼다.
ha 구성이 되었다는 건 active namenode도 running 중이고, standby namenode도 running 중이다. 이 상태를 ha cluster다 라고 하고
active namenode가 다운 되면 standby namenode가 active로 바뀌게 됨.
전환하는 시간이 필요하기는 하지만 다운타임을 최소화 하고 자동으로 active node가 복구된다는 점에서 HA 하다고 할 수 있음
3.2.1 HA Architecture 기본 구성요소
HA Architecture 는 namenode를 active/passive 상태인 namenode 를 각각 두어서 SPOF 문제를 해결했다.
HA cluster 에서는 active namenode, standby(passive) namenode 가 running중이어야 한다.
active namenode 가 다운되면, 다른 passive namenode 가 namenode 역할을 가져가고, downtime 을 최소화 한다.
standby namenode 는 Hadoop cluster 의 failover 기능을 통합하는 backup namenode 역할을 수행한다.
standby namenode를 통해서 namenode 가 예상치 못한 장애에 자동화된 failover 를 수행할 수 있다. 또한 maintenance 작업에서 graceful failover 를 기대할 수 있다.
이러한 HA Cluster 에서 consistency 를 유지하기 위해서는 두 가지 이슈가 있다.
-
Active, Standby namenode 는 항상 서로 sync 되어야 한다.
-
한 순간에 단 하나의 active namenode만 존재해야 한다.
만약 잠깐이라도 두 개의 active namenode 인 상태가 된다면, 서로 다른 active 데이터 상태를 가져서 데이터 충돌이 일어날 수 있다.(split-brain)
이것을 막기 위해서 Fencing 과정을 가진다.
3.2.2 HA Architecture 구현방법
Active Standby namenode 설정을 하는 방법으로 두 가지의 선택지가 있다.
-
Quorum Journal Nodes 를 사용
-
NFS(Network File Storage)를 이용한 shared storage 를 사용
3.3 Quorum Journal Nodes를 이용한 HA Architecture
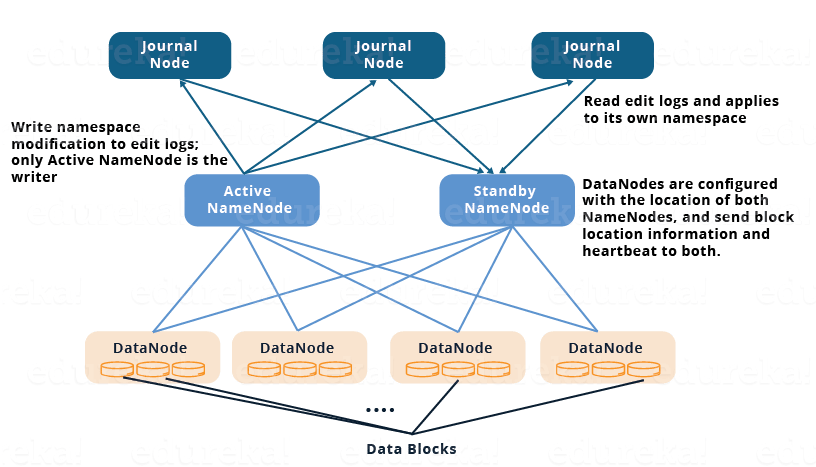
구성요소 : active namenode, standby namenode, journal nodes(보통 3개 이상, 홀수)
Journal node는 이름은 node인데 node로도 띄울 수 있고, 실제로는 active namenode나 datanode같이 머신에 있는데, 프로세스만 다른 daemon process로만 관리할 수도 있다.
왜냐면 리소스 사용량이 적고 가벼운 친구기 때문에.
3.3.1 Sync mechanism on HA Architecture using Quorum Journal Nodes
- Active, Standby namenode 는 Journal Nodes 라는 별도의 노드 그룹 (또는 데몬 프로세스) 으로 sync를 유지한다.
- Journal Nodes 는 ring topology 라는 구성으로 서로 연결되어있다.
- Journal 노드에 들어온 request 는 ring 구조를 따라 다른 노드로 copy 된다.
이로인해 특정 Journal node 에 failure 가 발생해도 Fault Tolerance 를 보장한다. - Active namenode 는 Journal Node 에 있는 EditLogs 를 업데이트 한다.
- Standby namenode 는 Journal Node 로부터 EditLogs 의 변경사항을 읽고 그것을 자신의 namespace 에 적용한다.
- Failover 시에 Standby namenode 는 Active namnode가 되기전에 우선 자신이 가진 metadata 의 내용이 Journal Node에 있는 모든 업데이트를 반영한 상태인지 확인한다.
Journal Node 의 모든 데이터가 싱크되었다면 그 때 Active Namenode가 된다. - 모든 datanode 는 active namenode 와 StandbyNode 의 IP 주소를 모두 알고 있다. datanode 는 자신의 heart beat 와 block report 데이터를 두 namenode에게 보낸다.
이로인해 Standby는 active 가 되기 전에 이미 datanode 정보와 block location 정보를 모두 알고 있으므로 빠르게 failover 를 수행할 수 있다.
3.3.2 Fencing of NameNode using Quorum Journal Nodes
Quorum Journal Nodes를 이용한 Architecture에서 Split-brain을 방지하기 위한 방법
- Journal node는 한 순간에 하나의 namenode 만 writer 가 되도록 한다.
- Standby namenode 가 Journal nodes 에 대한 writing 권한을 받으면, 다른 namenode 가 active 상태가 되지 못하게 막는다.
- 이 과정이 모두 끝난 후에 active namenode 역할을 수행한다.
3.4 Shared Storage를 이용한 HA Architecture
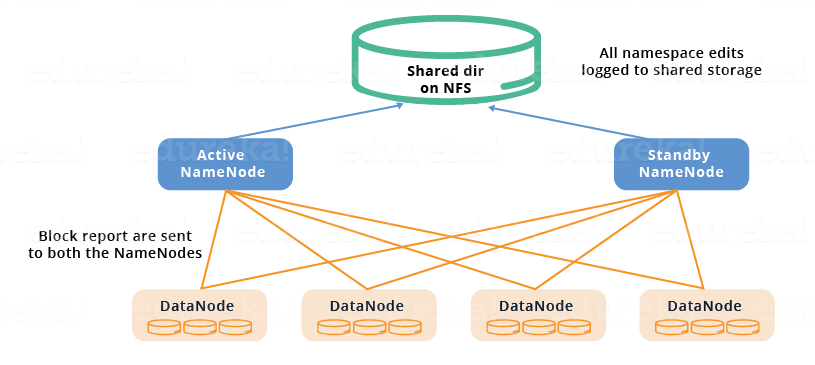
아까는 Namenods들이 바라보고 있는 게 아까는 Journal node 였는데, 이번엔 네트워크로 이용할 수 있는 파일스토리지의 공유 디렉토리(둘 다 바라볼 수 있는 어떤 디렉토리)를 지정해서 거기다가 모든 sync를 위한 데이터를 저장한다.
이 NFS가 지속적으로 접근 가능함을 보장한다는 전제 하에서만 해당 구성이 동작할 수 있다.
3.4.1 Sync mechanism on HA Architecture using Shared Storage
- Active, Standby namenode 는 shared storgae device 를 통해 sync를 유지한다.
- Active namenode 는 변경사항을 shared storage 에 있는 EditLog 에 기록한다.
- Standby namenode 는 변경사항을 shared storage에 있는 EditLog 를 읽어서 자신의 namespace 에 적용한다.
- Failover 발생시에 Standby namenode 는 shared storage 에 있는 EditLog 의 변경사항을 모두 반영한 것을 확인한 뒤에 active namenode 가 된다.
3.4.2 Fencing of NameNode on HA Architecture using Shared
- Split-brain을 방지하기 위해 관리자는 최소한 하나의 fencing 방법을 설정해야 한다.
- 다양한 fencing 메커니즘을 사용할 수 있다.
여기에는 namenode의 프로세스를 삭제하고 공유 스토리지 디렉토리에 대한 액세스를 취소하는 작업 등이 있을 수 있다. - 마지막 수단으로, 우리는 이전에 active namenode 에 STONITH로 split brain을 방지할 수 있다.(STONITH "shoot the other node in the head")
특수 전원 공급 분배기로 namenode 머신을 강제로 끄는 방법이다.
3.5 Automatic Failover
standby가 어떤 과정을 거쳐서 active가 되는지는 알았는데, 누가 그걸 해 줘? 누가 결정 해 줘?
3.5.1 Failover 의 종류
Failover 는 시스템의 failure 나 fault 를 감지하고 secondary system 에대한 조작을 자동으로 수행하는 동작을 말한다.
Failover 에는 다음 두가지 방식이 있다.
-
Graceful Failover: (사람이)직접 failover 과정을 진행한다. 주로 유지보수 과정에서 필요한경우 계획하고 의도적으로 실행한다. -
Automatic Failover: 예상치 못한 namenode장애에 의해 자동으로 수행된다.
3.5.2 Zookeeper 를 이용한 Hadoop Failover
zookeeper 를 이용해서 automatic failover 가 이루어지는 과정을 알아보자.
(아래 그림은 Journal Nodes 를 이용해 HA를 구성한 그림 )
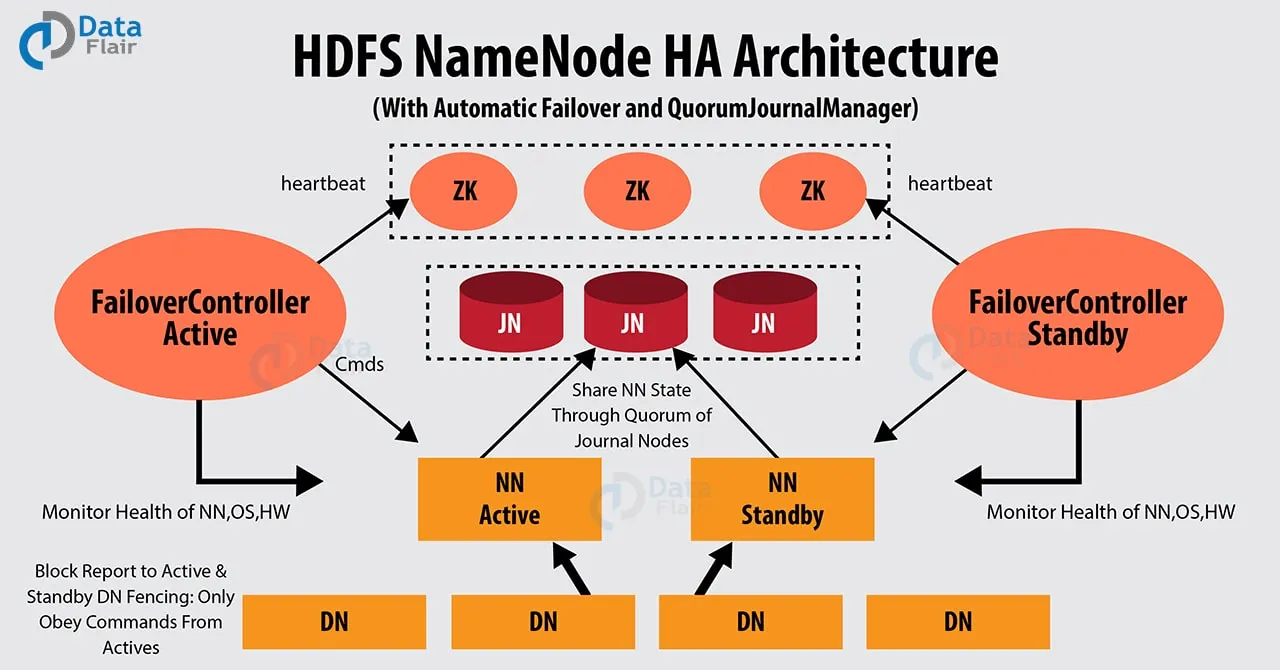
HDFS HA cluster 에서는 automatic failover 가 가능하게 하기 위해 Apache Zookeeper 를 사용한다.
zookeeper 는 적은 양의 coordination data 를 유지하고, zookeeper 의 client 들에게 데이터의 변경을 알리고, failure 감지를 위해 client 들을 모니터링 한다.
Zookeeper 는 namenode 에 session을 유지하고 있다.
만약 failure 가 발생하면 zookeeper 에 연결된 client session이 만료될 것이고 이때 zookeeper 는 다른 namenode 들에게 failover process가 시작되었음을 알린다.
Active namenode 의 failure 가 발생하면 다른 standby(passive) namenode는 active namenode가 되기 위해 zookeeper 에 유지되고 있던 state 에 lock을 건다.
ZookeerFailoverController (ZKFC) 는 namenode의 상태 모니터링을 하는 zookeeper서버의 client 프로세스이다.
각 namenode는 ZKFC를 자신의 노드에 띄우고, ZKFC가 namenode를 주기적으로 health check 를 하도록 해야한다.
3.6 Observer Name Node (ONN) 로 부하 분산하기
ONN은 Hadoop 3.x 버전부터 사용할 수 있다.
3.6.1 Observer Name Node 의 필요성
위에서 배운 HDFS HA Architecture 에서 active namenode 는 client의 모든 요청을 받고, standby namenode 는 단순히 active namenode 와 같도록 sync 받는 일만 한다.
HA는 달성했지만, 여전히 단일 active namenode가 병목이 되는 문제는 발생한다.
단일 active namenode에 부하가 심해진다면, HA를 이용해서 failover 가 되었더라도 또 다시 부하로 active namenode를 이용 못하는 상태가 연쇄적으로 발생할 수 있다. (HA가 load를 해결해주지는 못 함)
Oserver NameNode 는 이러한 active namenode의 부하를 분산해주기 위해 만들어졌다.
Observer NameNode 는 standby namenode와 마찬가지로 active namenode와 같은 상태를 유지한다. 여기에 더해 active namenode 처럼 consistent read 를 지원한다.
HDFS를 사용하는 대부분의 use case 가 write-once-read-many access model을 따르기 때문에 read 의 부하를 분산해주는 것 만으로 active namenode 의 부하를 많이 낮출 수 있다.
3.6.2 State of namenode
Hadoop 3 버전부터는 HA Hadoop Cluster 에서 namenode 는 3가지의 state 를 가질 수 있다. active, standby, observer
State Transition은 다음과 같은 구성 사이에서 가능하다.
- active - standby
- standby - observer
active - observer 사이에서 직접 전환은 불가능하다.
3.6.3 Consistency in a client - read your own writes
개념 배경
-
HDFS Router-based Federation 또는 Observer NameNode 기능을 사용할 때, 클라이언트는 쓰기(write) 는 Active NameNode에 하고, 읽기(read) 는 Observer NameNode에 위임할 수 있다.
-
문제는 Observer NameNode가 Active NameNode의 로그를 약간 지연된 상태로만 반영하기 때문에, 클라이언트가 방금 쓴(write) 데이터를 바로 읽으려고 하면 stale 데이터를 읽을 수 있다는 점이다.
-
이를 방지하기 위해 "read-after-write consistency" (자신이 쓴 것은 자신이 바로 읽을 수 있음) 보장을 위한 메커니즘이 필요하다.
State ID의 역할
- 클라이언트는 RPC 요청 헤더에 state ID라는 값을 포함한다.
- 이 state ID는 사실상 "내가 지금까지 본 가장 최신 트랜잭션 ID"를 의미한다.
- 여기서 트랜잭션 ID(Transaction ID) 는 NameNode의 edit log에 기록되는 순차 번호로, 파일 생성, 삭제, rename 같은 모든 namespace 변경 작업에 대해 증가한다.
Write 동작
-
클라이언트가 Active NameNode에 write 요청을 보낸다.
-
Active NameNode는 해당 write를 처리하면서 새로운 transaction ID를 발급한다.
-
클라이언트는 응답을 받을 때, 자신의 state ID를 Active NameNode가 반환한 latest transaction ID 값으로 업데이트한다.
즉, 클라이언트는 "나는 최소한 transaction ID = X까지의 업데이트를 본 적 있다"라는 상태를 가지게 된다.
Read 동작
-
클라이언트가 read 요청을 Observer NameNode로 보낼 때, RPC 헤더에 자신의 state ID를 함께 전달한다.
-
Observer NameNode는 다음을 확인한다:
-
Observer가 가진 자기 자신의 latest transaction ID ≥ 클라이언트가 보낸 state ID 인지 비교한다.
-
만약 Observer가 아직 그 transaction ID까지 동기화하지 못했다면 → 클라이언트가 방금 쓴 데이터를 확실히 보여줄 수 없음.
-
이 경우, Observer는 요청을 Active NameNode로 redirect하거나, 내부적으로 동기화가 완료될 때까지 기다릴 수 있다.
-
-
Observer가 state ID와 같거나 더 최신의 transaction ID를 반영하고 있다면 → read를 수행하고 결과를 리턴한다.
보장되는 것
-
이렇게 하면, 한 클라이언트 안에서의 read-after-write consistency ("내가 쓴 것은 반드시 내가 읽을 수 있음")가 보장된다.
-
즉, 여러 observer 노드가 있더라도, 최소한 같은 클라이언트가 방금 쓴 데이터를 stale하게 읽는 문제는 방지된다
중요한 점
-
이 방식은 클라이언트 단위 보장이다. 즉, Client A가 쓴 것을 Client B가 즉시 읽을 수 있다는 보장은 없다.
-
여러 클라이언트 간의 consistency 문제(즉, global consistency)는 Maintaining Client Consistency 섹션에서 별도로 다룬다.
3.6.4 Edit log tailing
observer namnode에게 Edit log tailing 은 아주 중요하다.
active namenode 에 업데이트된 새로운 transaction에 대해서 observer namenode 가 반영하는 latency 에 영향을 주기 때문이다.
새로 도입된 Edit log tailing 방식인 "Edit Tailing Fast-Path" 은 latency를 줄일 수 있도록 디자인 되었다.(빨리 트렌젝션 정보를 싱크하기 위해서)
기존의 edit log tailing 기능에 더해,
- HTTP 대신 RPC based tailing 을 사용한다. (L7 > TCP+)
- Journal Node의 in-memory cache 를 사용한다. (최대한 메모리에서 빨리 응답할 수 있도록)
3.6.5 Client-side proxy provider의 동작
새로운 client-side proxy provider 인 ObserverReadProxyProvider 는 기존에 Failover 에서 사용되는 ConfiguredFailoverProxyProvider 를 상속받는데,
이를 통해 observer namenode 에서 read 를 사용할 수 있도록 한다.
클라이언트가 read 요청을 하면 proxy provider 는 먼저 클러스터에서 사용할 수 있는 observer namenode 로 read 를 시도한다.
모든 observer namenode로부터의 읽기가 실패했을 때 active namenode로 요청을 보낸다.
3.6.6 Maintaining Client Consistency
위에서 설명한 read your own writes 에 의해서
-
하나의 클라이언트에 대해 너가 쓴 거를 너가 읽을 수 있도록 보장해 줄게
클라이언트 'foo'가 active namenode에 a.txt 를 생성하는 write를 수행했다고 가정해보자. -
이때, foo 가 observer namenode 로 요청하는 모든 read 는 a.txt 가 완료된것을 보장한 뒤에 read 에 응답한다.
이때, foo 가 write 를 보냄과 동시에 ‘bar’라는 out-of-band(HDFS가 아닌) 클라이언트에게 이 사실을 알렸고, bar client 가 HDFS 에 a.txt 를 조회한다고 해보자.
- 이 때, bar 는 a.txt 를 읽을 수 있을까?
이것은 보장되지 않는다.
따라서 여러 클라이언트들 사이에 이러한 inconsistent 한 동작을 방지하기 위해서 메타데이터를 동기화 하기위한 msync() 기능이 추가되었다.
어떤 클라이언트에서든 msync() 를 호출하면, active name node 에 대한 state ID를 업데이트해서 이후 요청하는 어떤 read 든지 msync() 지점까지 consistent 함을 보장할 수 있다.
- 위의 사례에서 bar 가
msync()를 수행한 뒤에 a.txt 를 read 요청한다면 읽기를 보장할 수 있다.
msync()를 사용하기 위해 어플리케이션 코드를 변경할 필요는 없다.
클라이언트는 Observer에 대해 읽기를 수행하기 전에 자동으로 msync()를 호출하여 클라이언트 초기화 전에 수행된 쓰기를 볼 수 있다.
또한 ObserverReadProxyProvider 가 지원하는 자동 msync 모드가 있으며, 이 모드는 설정 가능한 간격으로 msync()를 자동으로 수행하여 클라이언트가 시간 제한보다 오래된 데이터를 볼 수 없도록 한다.
새로 고칠 때마다 Active NameNode에 대한 RPC가 필요하므로 오버헤드가 있다. 기본적으로 사용하지 않도록 설정되어 있다.
