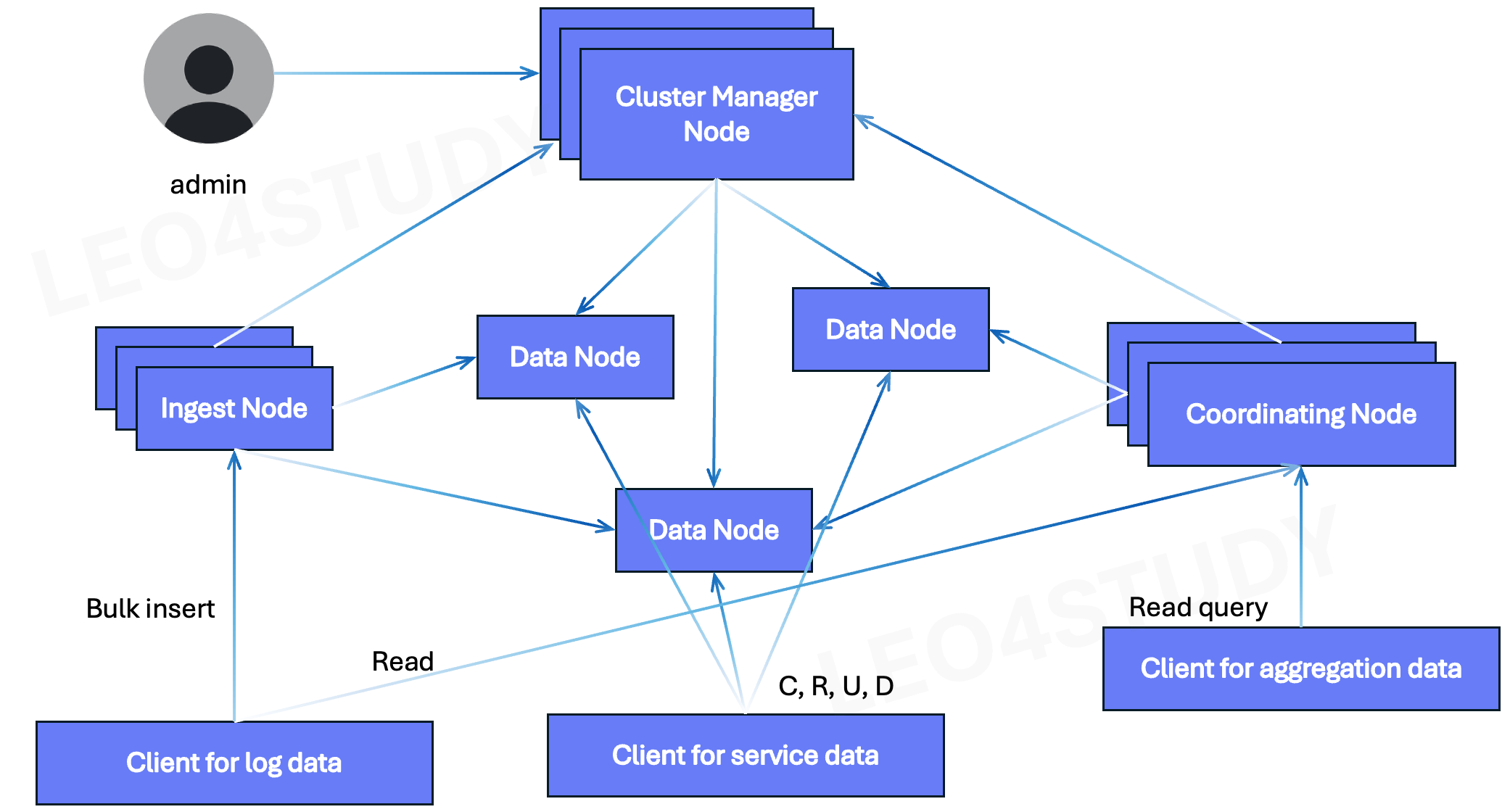
1. Ingest Node → Data Node
Ingest Node는 데이터를 전처리(grok, remove, mutate 등)한 후, 실제 데이터를 저장하기 위해 Data Node로 전송한다.
🔹 전형적인 흐름
- Client → Ingest Node (pipeline 처리)
- Ingest Node → Data Node (primary shard에 저장)
🔹 Ingest Node의 역할
- 파이프라인 처리: 예) 로그 파싱, 필드 제거, 마스킹 등
- 전처리 후 적재 대상 shard를 찾아 Data Node에 직접 저장
🔹 Data Node의 역할
- 데이터를 물리적으로 저장 (Primary / Replica shard)
- 쿼리 대상이 되는 샤드 보유
2. Ingest Node → Manager Node
Ingest Node는 일반적인 상황에서는 Manager Node와 통신하지 않지만, 특정 상황에서는 Manager Node에 먼저 요청을 보냄.
🔹 Cluster Manager가 관여하는 상황
-
Index가 없을 때
- Cluster Manager가 Index 생성
- Shard 할당 결정
-
Mapping 업데이트가 필요할 때
- 새로운 필드 등장 시, dynamic mapping 등록
-
Index Template, ILM 정책 적용 등
- 인덱스 메타데이터 관리
전체 흐름 요약
🟢 일반적인 경우
Client
↓
Ingest Node (pipeline 처리)
↓
Data Node (shard 저장)🟡 Index가 없는 경우
Client
↓
Ingest Node
↓
Cluster Manager (index 생성 및 shard 할당)
↓
Data Node요약 테이블
| 상황 | Manager Node 관여 여부 | 설명 |
|---|---|---|
| Index 존재 & Mapping 완비 | X | Ingest → Data Node로 바로 |
| Index 없음 | O | Manager가 index 생성 후 shard 할당 |
| 새로운 필드 등장 (dynamic mapping) | O | mapping 업데이트 |
| 템플릿, ILM 등 인덱스 메타 관리 | O | index 생성 전 처리 |

Data Analytics Engineer 가 되