
- 지난 시간 동안, Neural Networks와 선형 함수들을 살펴봄
- 선형 레이어를 쌓고, 그 사이에 비선형 레이어(activation function)를 추가하여 Neural Network를 만듦
- 이를 이용하여, Mode 문제를 해결 (Mode 문제란, 학습을 통해 하나의 template만 만들어져서, 이미지의 다양한 feature를 반영하지 못한 문제)
- 마지막으로, 이 template들을 결합하여 최종 class score를 계산
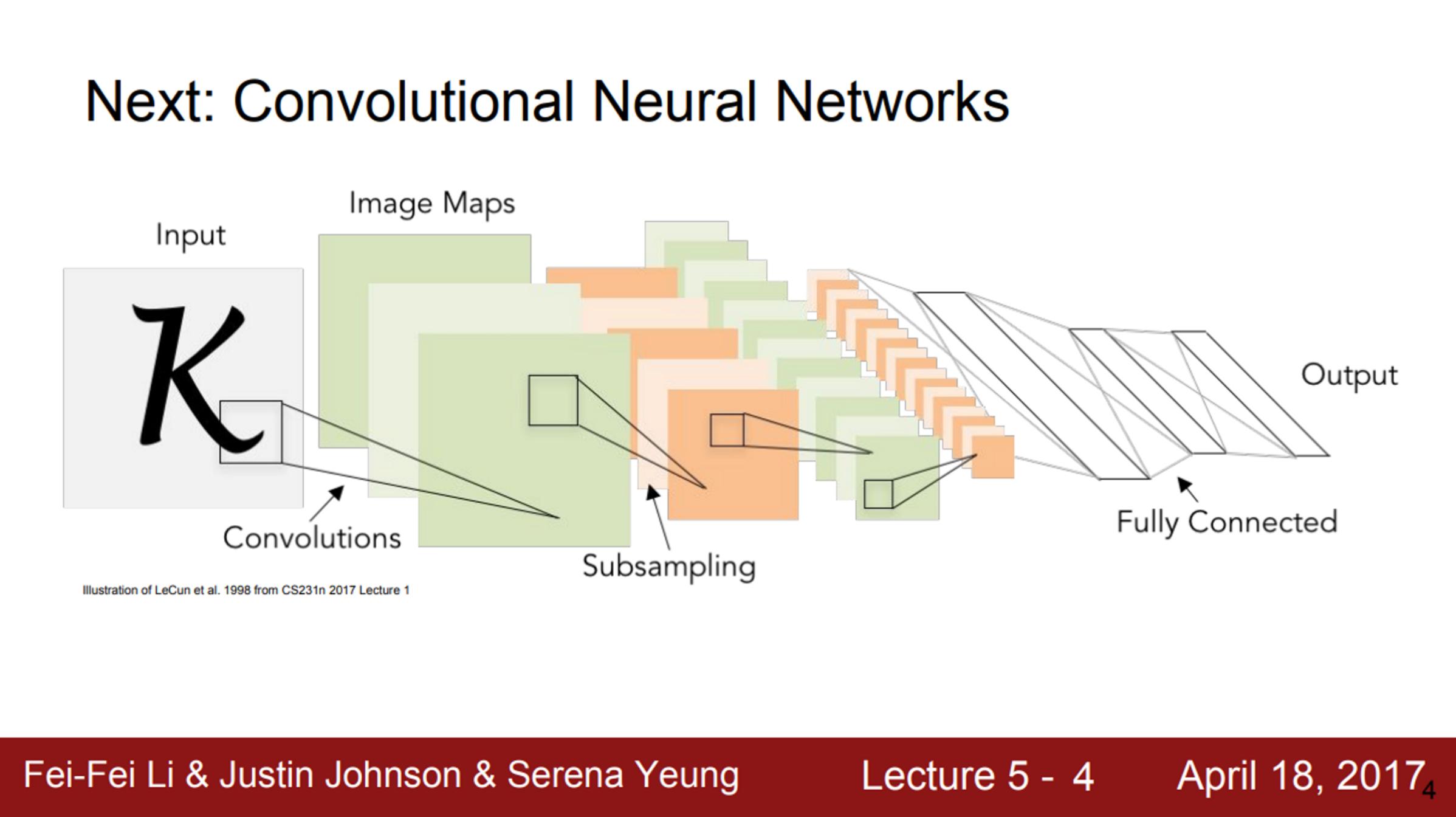
- CNN이란, 기존의 Neural Network와 같은 부류이지만, Convolutional Layer를 사용한 Neural Network
- Convolutional Layer는 기본적으로 공간적 구조를 유지함

- 먼저, Neural Network의 역사를 살펴보면…
- 1957년 Frank Rosenblatt가 Mark 1 Perceptron machine을 개발
- 이 기계는 Perceptron을 구현한 최초의 기계
- Perceptron은 우리가 배운 와 유사한 함수를 사용
- 여기에서도 가중치 를 업데이트하는 Update rule이 존재
- 이 Update rule은 Backpropagation과 유사
- 하지만, 당시에는 Backpropagation이라는 개념이 없어서, 단지 를 조절하면서 맞추는 식이었음
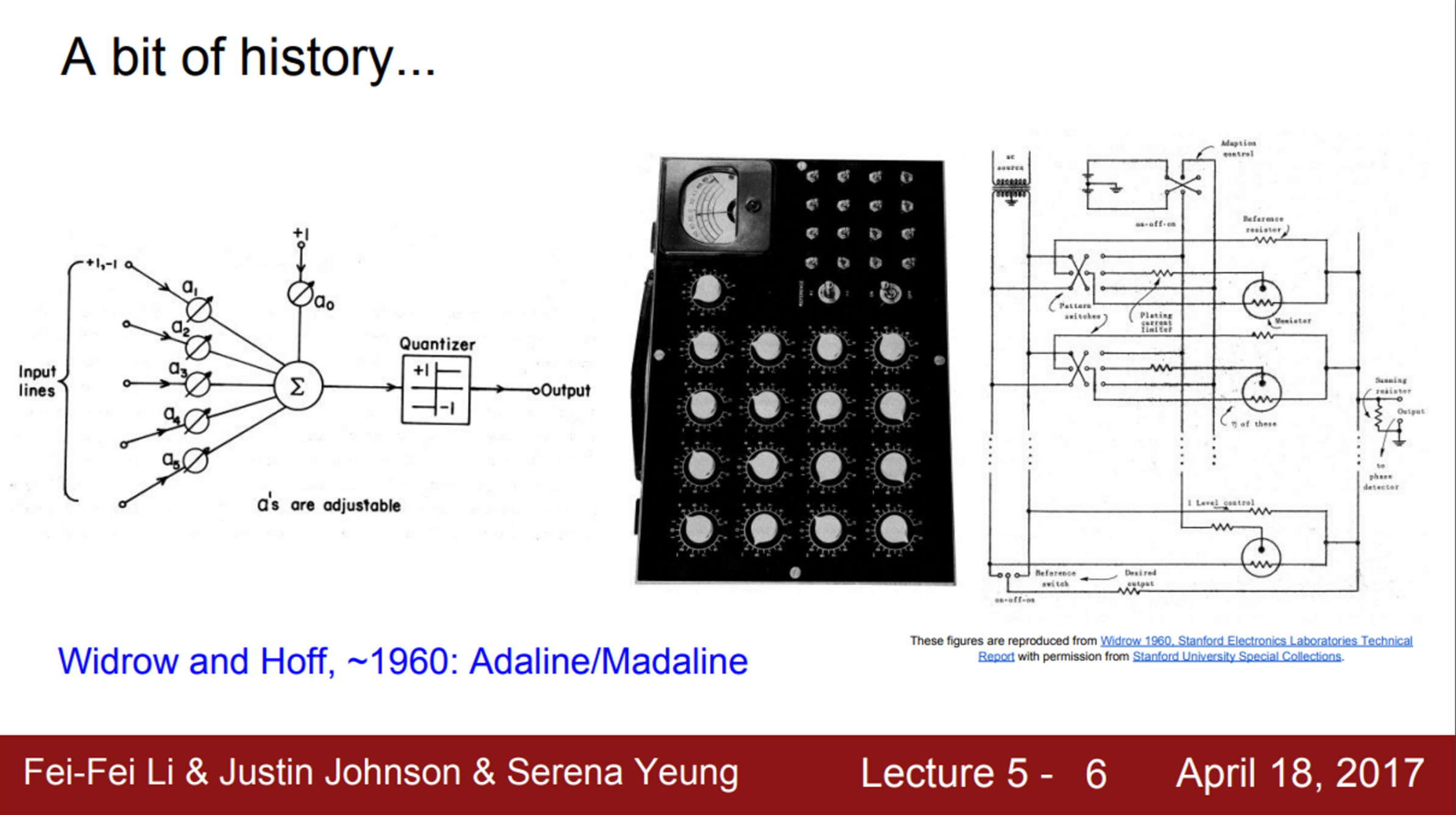
- 이후 1960년대, Widrow와 Hoff가 Adaline and Madaline을 개발
- 이는 최초의 Multilayer Perceptron Network
- 이 시점에서야 비로소 Neural Network와 비슷한 모양을 하기 시작
- 그러나, Backpropagation 같은 학습 알고리즘은 없었음
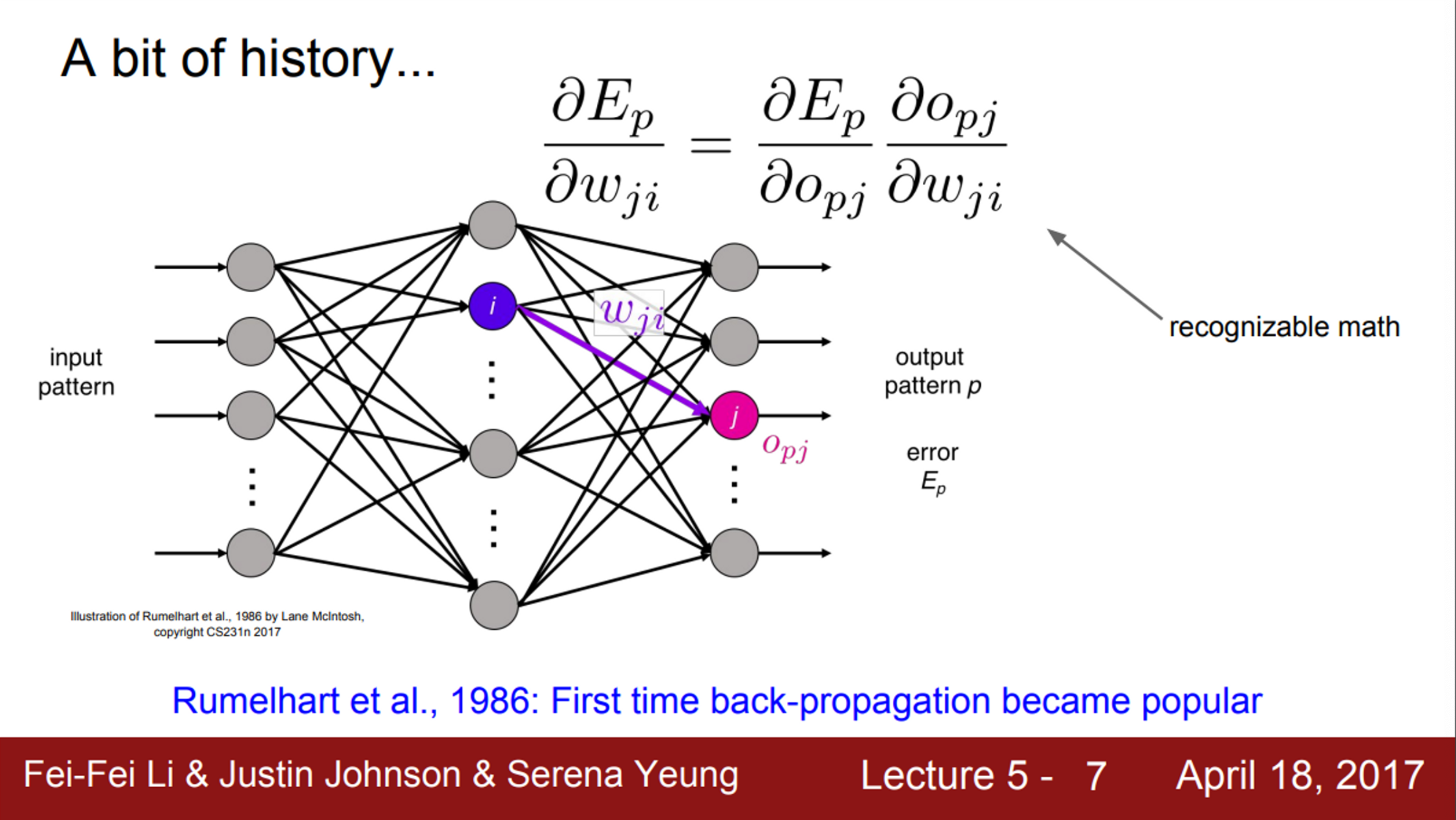
- 최초의 Backpropagation은 1986년에 Rumelhart가 제안
- Chain rule과 Update rule이 존재
- 하지만 그 이후로는 Neural Network를 더 크게 만들지는 못했음
- 그리고 한동안은 새로운 이론이 나오지 못했고, 널리 쓰이지도 못했음
- 2000년대에 들어서며 다시 활기를 찾기 시작함
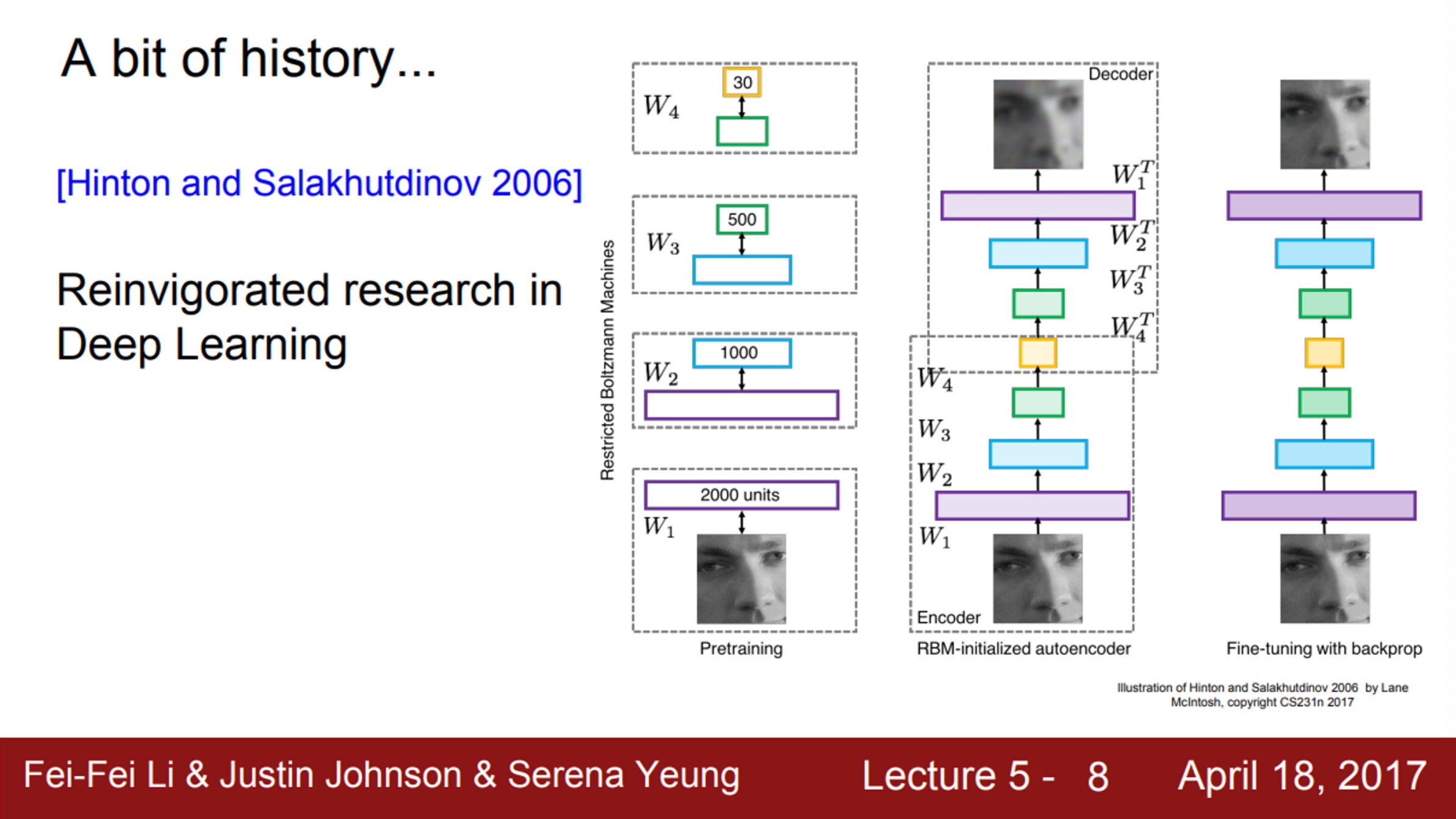
- Geoff Hinton과 Ruslan Salakhutdinov의 2006년 논문에서 DNN의 학습 가능성을 선보였고, 이것이 실제로 아주 효과적이라는 것을 보여줌
- Backpropagation이 가능하려면 아주 세심하게 초기화를 해야함
- 그래서, 여기에서는 전처리 과정이 필요했고, 초기화를 위해 RBM을 이용해서 각 hidden layer 가중치를 학습시켜야 했음
- 이렇게 초기화된 hidden layer를 이용해서 전체 신경망을 backpropagation 하거나 fine tune을 하는 것
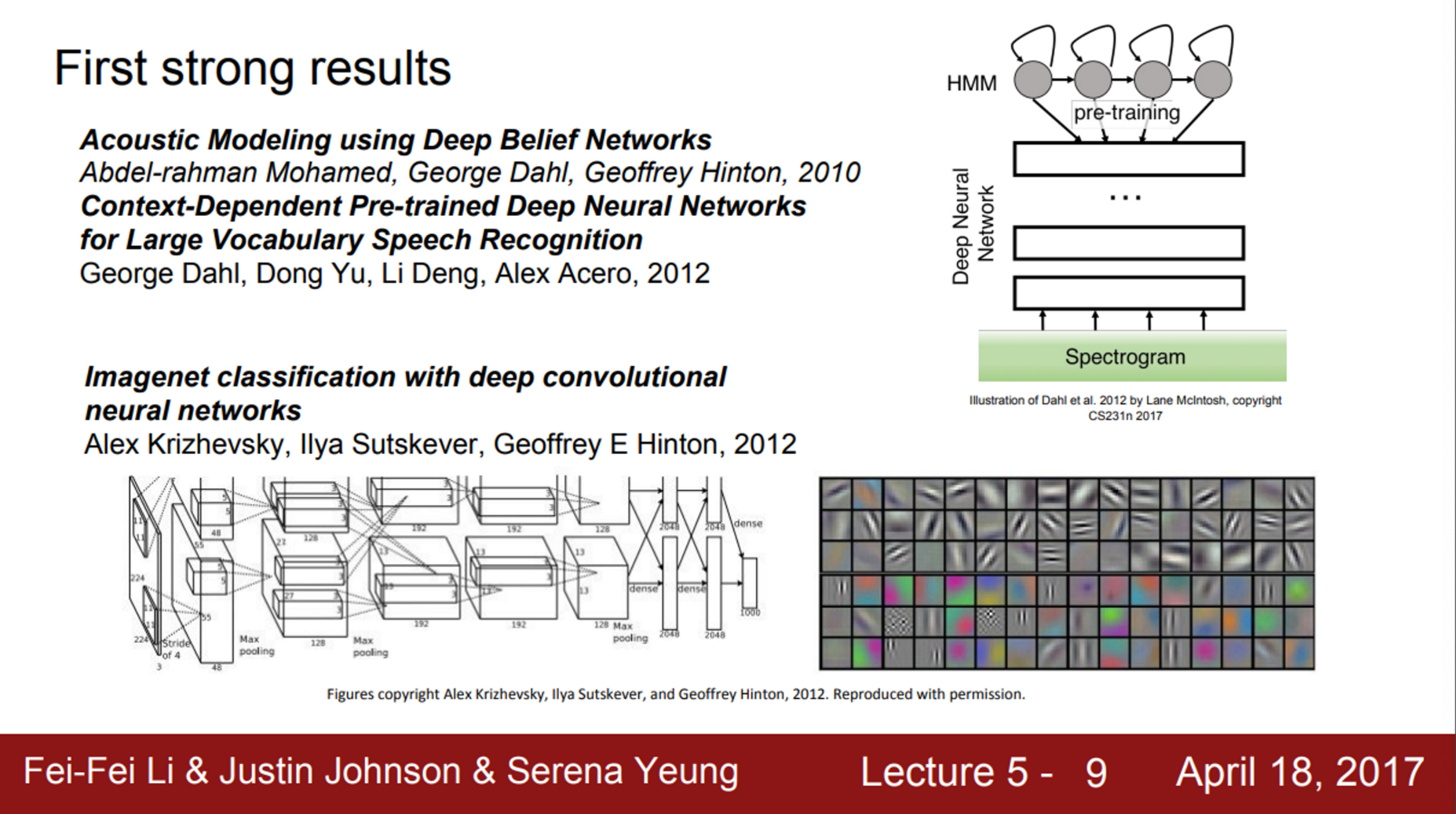
- 실제로 Neural Network의 광풍이 불기 시작한 때는 2012년
- Neural Network가 음성 인식에서 아주 좋은 성능을 보였음
- 이는 Hintin lab에서 나온 것인데, acoustic modeling과 speech recognition에 관한 것
- 또한, 2012년에는 Hinton lab의 Alex Krizhevsky가 영상 인식에 관한 landmark paper를 공개
- 이 논문에서는 ImageNet Classification에서 최초의 Neural Network를 사용했고, 결과는 매우 놀라웠음
- AlexNet은 ImageNet benchmark의 error를 극적으로 감소시켰음
- 이후로 ConvNet은 아주 널리 쓰이고 있음
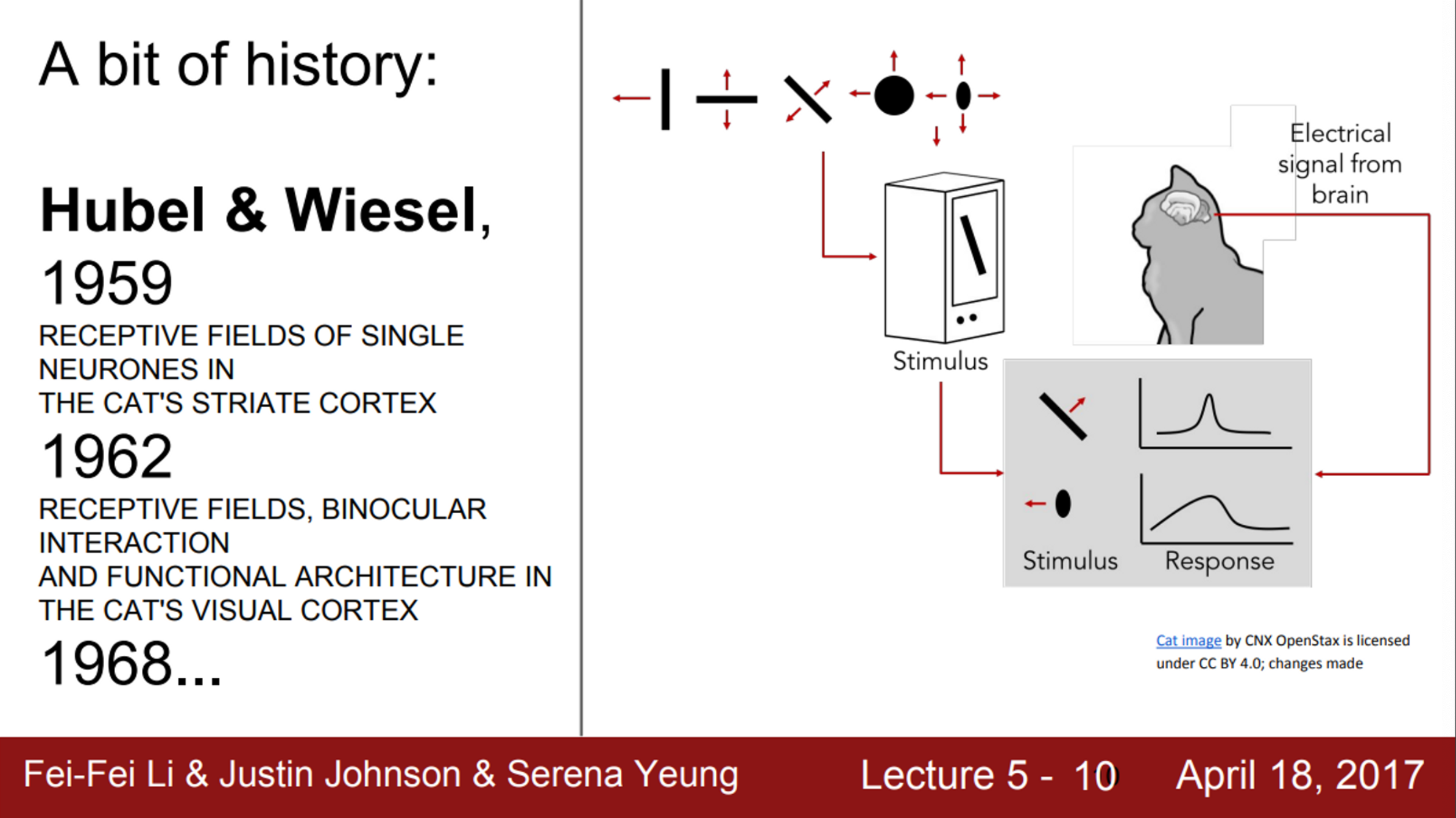
- Convolutional Neural Network가 어떻게 유명해졌는지?
- 1950년대, Hubel과 Wiesel이 일차 시각 피질의 뉴런에 관한 연구를 수행
- 이 실험에서 뉴런이 oriented edges와 shapes 같은 것에 반응한다는 것을 알아냄
- 이 실험에서 내린 몇 가지 결론은 아주 중요했음

- 그 중 하나는 바로, 피질 내부에 지형적인 매핑(topographical mapping)이 있다는 것
- 피질 내 서로 인접해 있는 세포들은 visual field 내에 어떤 지역성을 띄고 있음
- 오른쪽 그림에서, 해당하는 spatial mapping을 볼 수 있음
- 그리고, 중심에서 더 벗어난 파란색 지역도 볼 수 있음
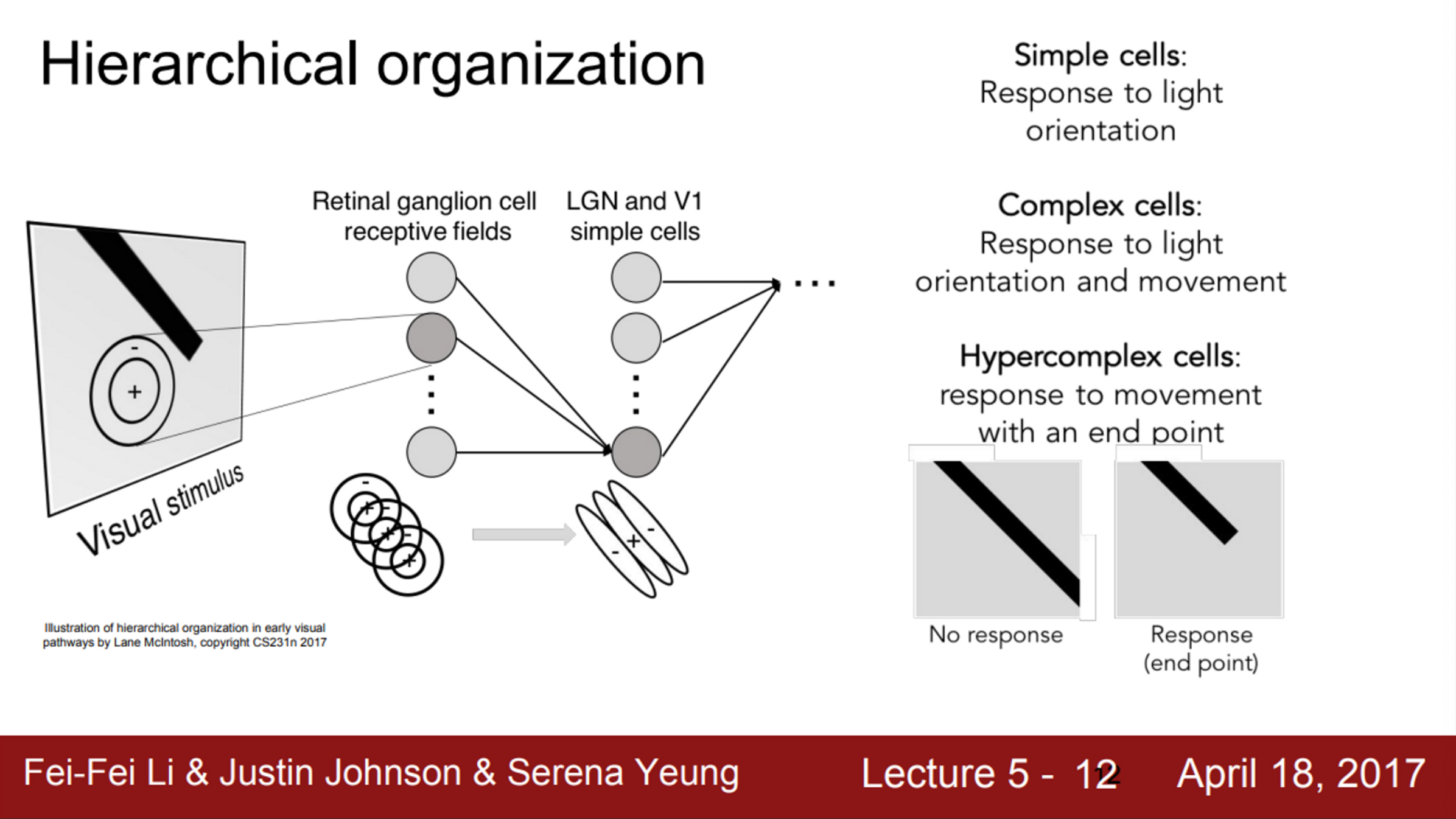
- 또한, 이 실험에서 뉴런들이 계층 구조를 지닌다는 것도 발견함
- 다양한 종류의 시각 자극을 관찰하면서, 시각 신호가 가장 먼저 도달하는 곳이 바로 Retinal ganglion 이라는 것을 발견함
- Retinal ganglion cell은 원형으로 생긴 지역
- 가장 상위에는 Simple cells가 있는데, 이 세포들은 다양한 edges의 방향과 빛의 방향에 반응함
- 더 나아가, Simple cells가 Complex cells와 연결되어 있다는 것을 발견함
- Complex cells는 빛의 방향 뿐만 아니라, 움직임에서 반응함
- 즉, 복잡도가 증가함에 따라, hypercomplex cells는 끝 점(end point)과 같은 것에 반응하게 되는 것
- 다양한 종류의 시각 자극을 관찰하면서, 시각 신호가 가장 먼저 도달하는 곳이 바로 Retinal ganglion 이라는 것을 발견함
- 이런 결과로부터, corner나 blob에 대한 아이디어를 얻기 시작함
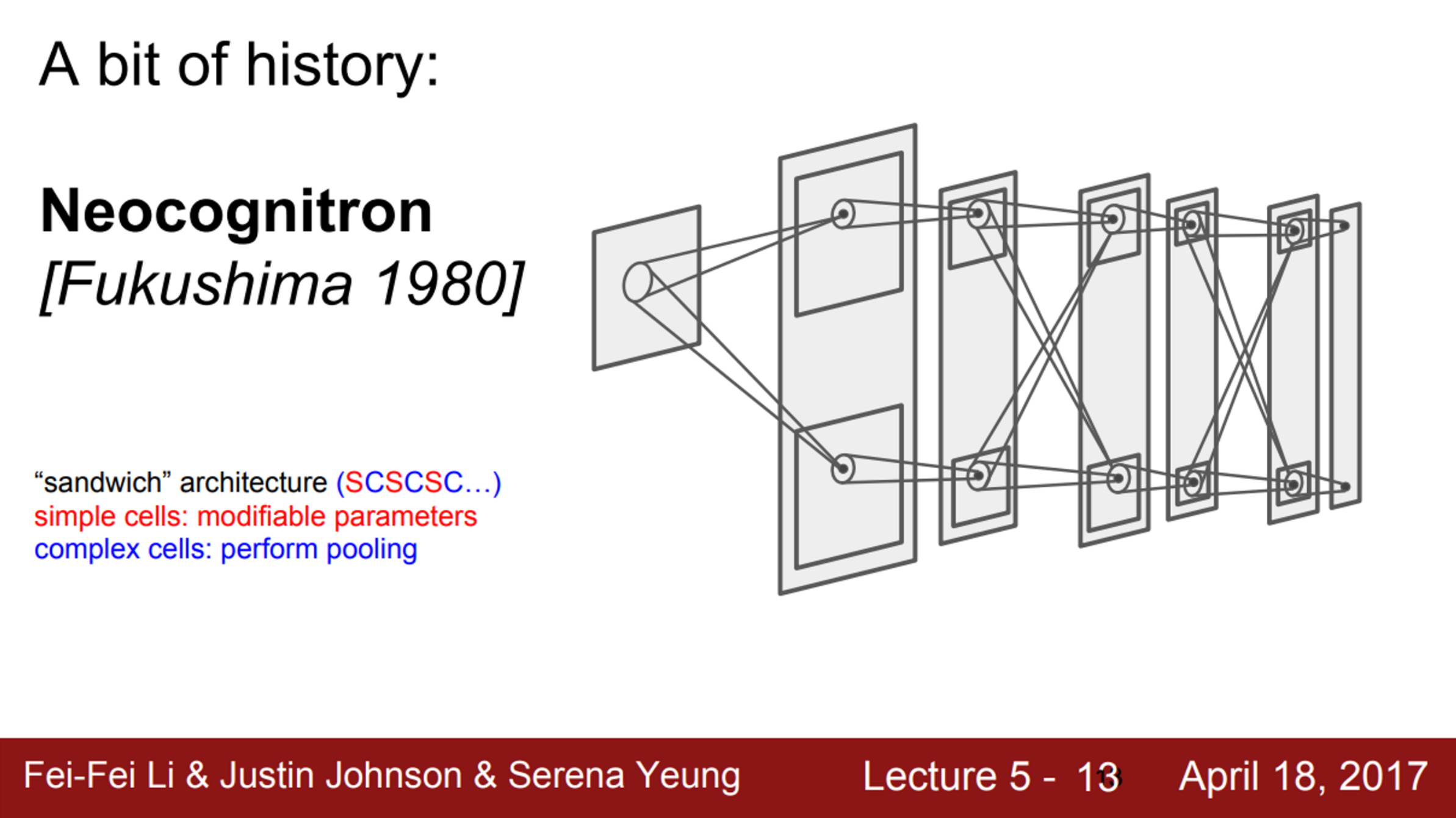
- 1980년 neocognitron은 Hubel과 Wiesel이 발견한 simple/complex cells의 아이디어를 사용한 최초의 Neural Network
- Fukishima는 simple/complex cells를 교차시킴 (SCSCSC…)
- simple cells는 학습 가능한 parameters를 가지고 있고, complex cells는 pooling과 같은 것으로 구현했는데, 작은 변화에 simple cells보다 좀 더 강인함
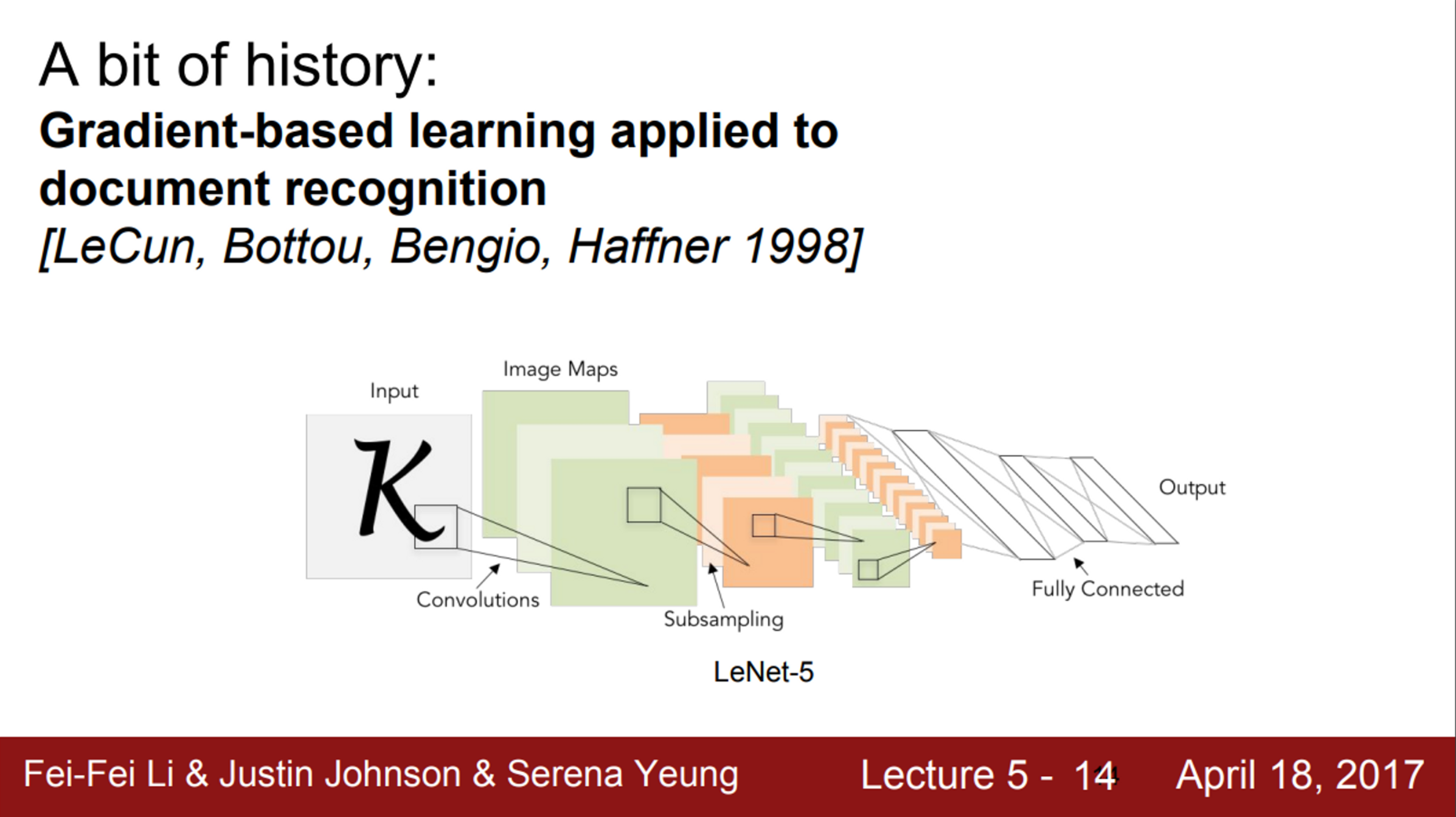
- 1998년 Yann LeCun이 최초로 Neural Network를 학습시키기 위해, backpropagation과 gradient-based learning을 적용
- 우편 번호의 숫자를 인식하는데도 아주 잘 동작함
- 하지만, 아직 이 Network를 더 크게 만들 수는 없었음
- 숫자라는 데이터는 단순했음
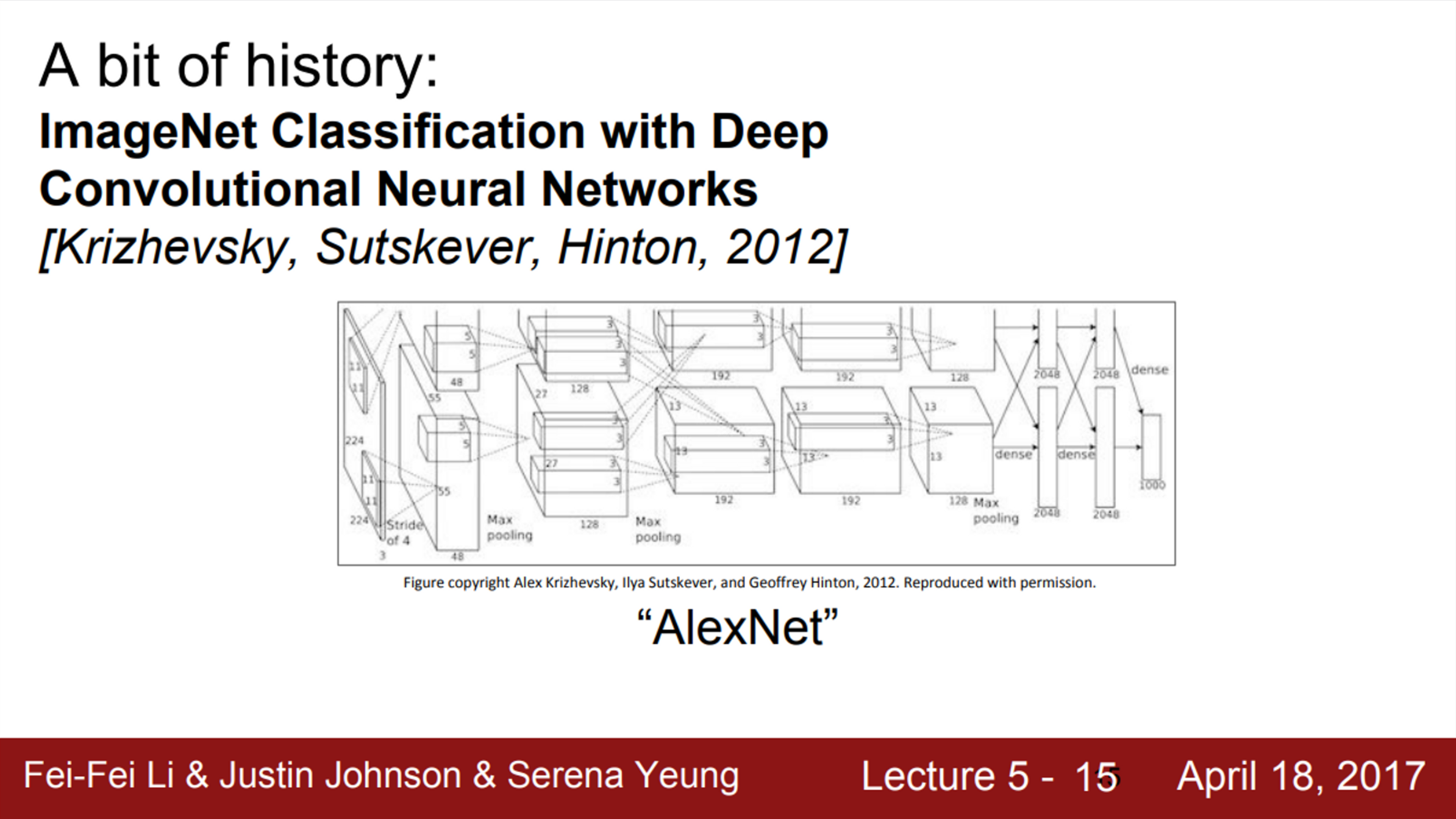
- 2012년 Alex Krizhevsky가 Convolutional Neural Network의 현대화 바람을 일으킴
- Yann LeCun의 CNN과 크게 달라보이진 않음
- 다만, 더 크고 깊어진 것
- 가장 중요한 점은, ImageNet dataset과 같이 대규모의 데이터를 활용할 수 있다는 것
- 추가적으로, GPU의 힘도 있음
- Yann LeCun의 CNN과 크게 달라보이진 않음

- 오늘날 ConvNet은 모든 곳에 쓰임
- AlexNet의 ImageNet 데이터 분류 결과를 살펴보자면, 이미지 검색에 정말 좋은 성능을 보이고 있음
- 학습된 특징이 유사한 것을 매칭시키는데 아주 강력하다는 것을 볼 수 있음

- Detection에서도 ConvNet을 사용함
- 영상 내에 객체가 어디에 있는지를 아주 잘 찾아냄
- Segmentation은 단지 네모 박스만 치는 것이 아니라, 나무나 사람 등을 구별하는데 픽셀 하나 하나에 모두 레이블링하는 것

- 이런 알고리즘은 자율주행 자동차에 사용할 수 있음
- 대부분의 작업은 GPU가 수행할 수 있으며, 병렬처리를 통해 ConvNet을 아주 효과적으로 훈련하고 실행시킬 수 있음
- 자율 주행에 들어가는 임베디드 시스템에서도 동작할 뿐만 아니라 최신의 GPU에서도 가능
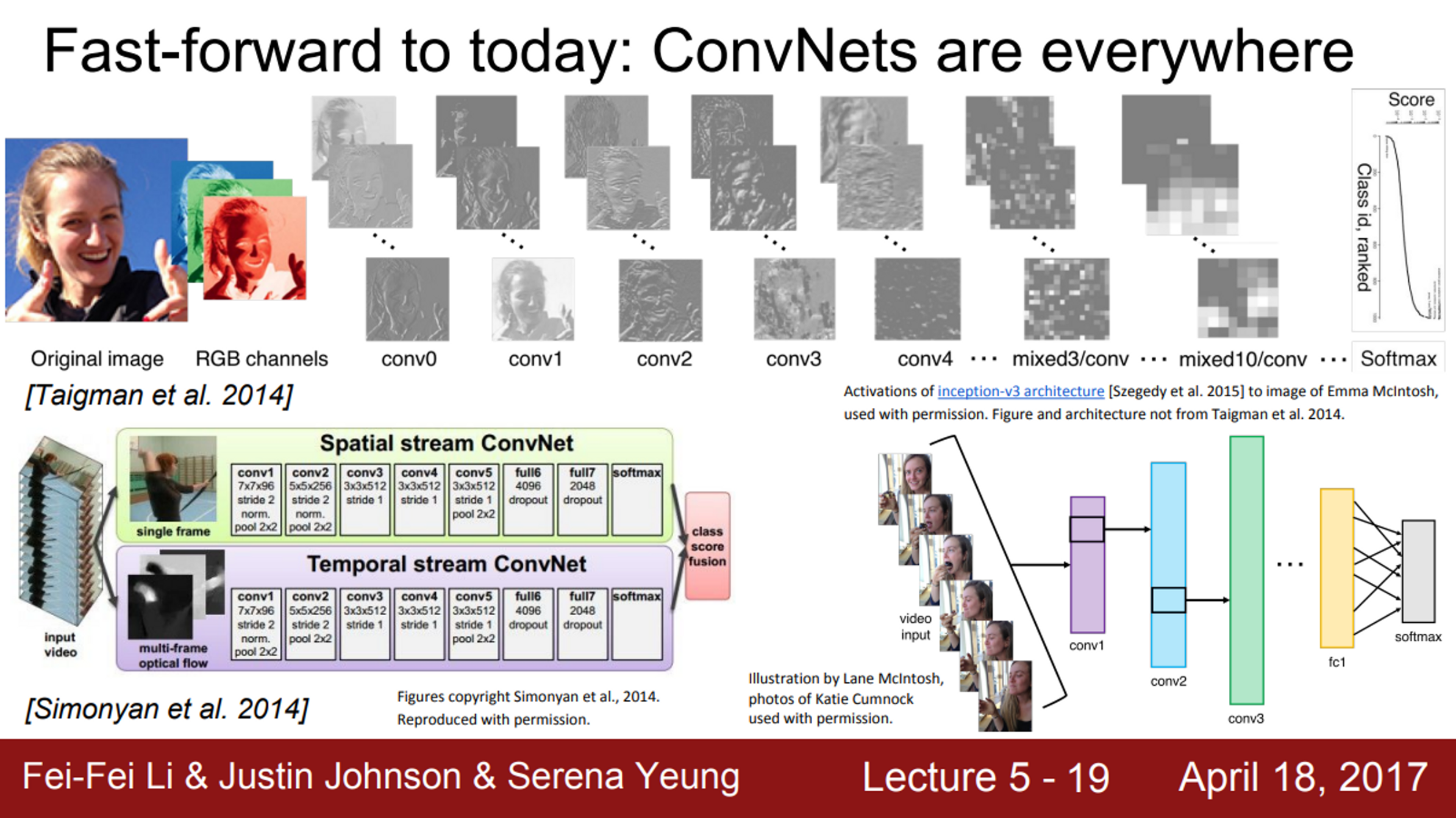
- 이는 모두 ConvNet을 활용할 수 있는 다양한 어플리케이션의 예라고 할 수 있음
- 얼굴 인식의 예를 보면, 얼굴 이미지를 입력으로 받아서 이 사람이 누구인지에 대한 확률을 추정할 수 있음
- ConvNet을 비디오에도 활용할 수 있는데, 단일 이미지의 정보 뿐만 아니라, 시간적 정보도 같이 활용하는 방법

- 또한, Pose recognition도 가능
- 다양하고 비 정형적인 사람의 포즈도 잘 잡아냄

- 의학 영상을 가지고 해석하거나 진단할 때도 이용 가능

- 최근의 Kaggle Chanllange에서는 고래를 분류하는 것도 있었음
- 또한, 항공 지도를 이용하여 길과 건물을 인식하기도 함

- Classification이나 Detection에서 더 나아가는 방법도 존재
- Image Captioning 같은 방법

- 또한, Neural Network를 이용하여 예술 작품도 만들 수 있음
- Style Transfer - 원본 이미지를 가지고 특정 화풍으로 다시 그려주는 알고리즘
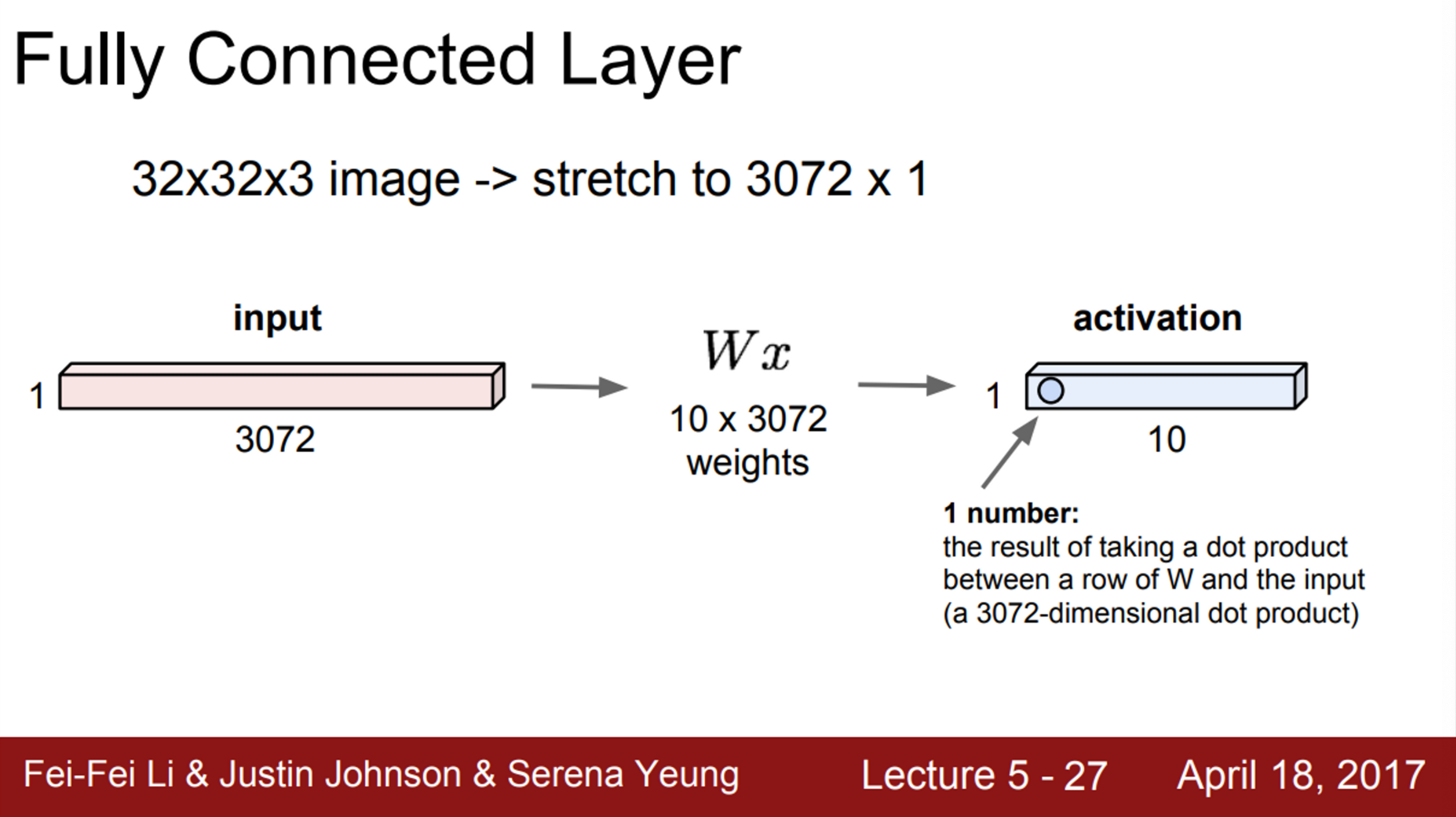
- Fully Connected Layer의 경우,
- 32 X 32 X 3의 이미지가 있을 때, 이를 길게 펼쳐서 3072 차원(=32X32X3)의 벡터로 만듦
- 이후 가중치 와 벡터를 곱함 ()
- 그리고 activation을 얻음 (이 Layer의 출력)
- activation은 10개의 행으로 이루어져 있으며, 3072 차원의 입력과 내적한 결과
- 내적 후 어떤 숫자 하나를 얻게 되는데, 이는 그 Neuron 하나의 값
- 해당 예시는 10개의 출력이 존재

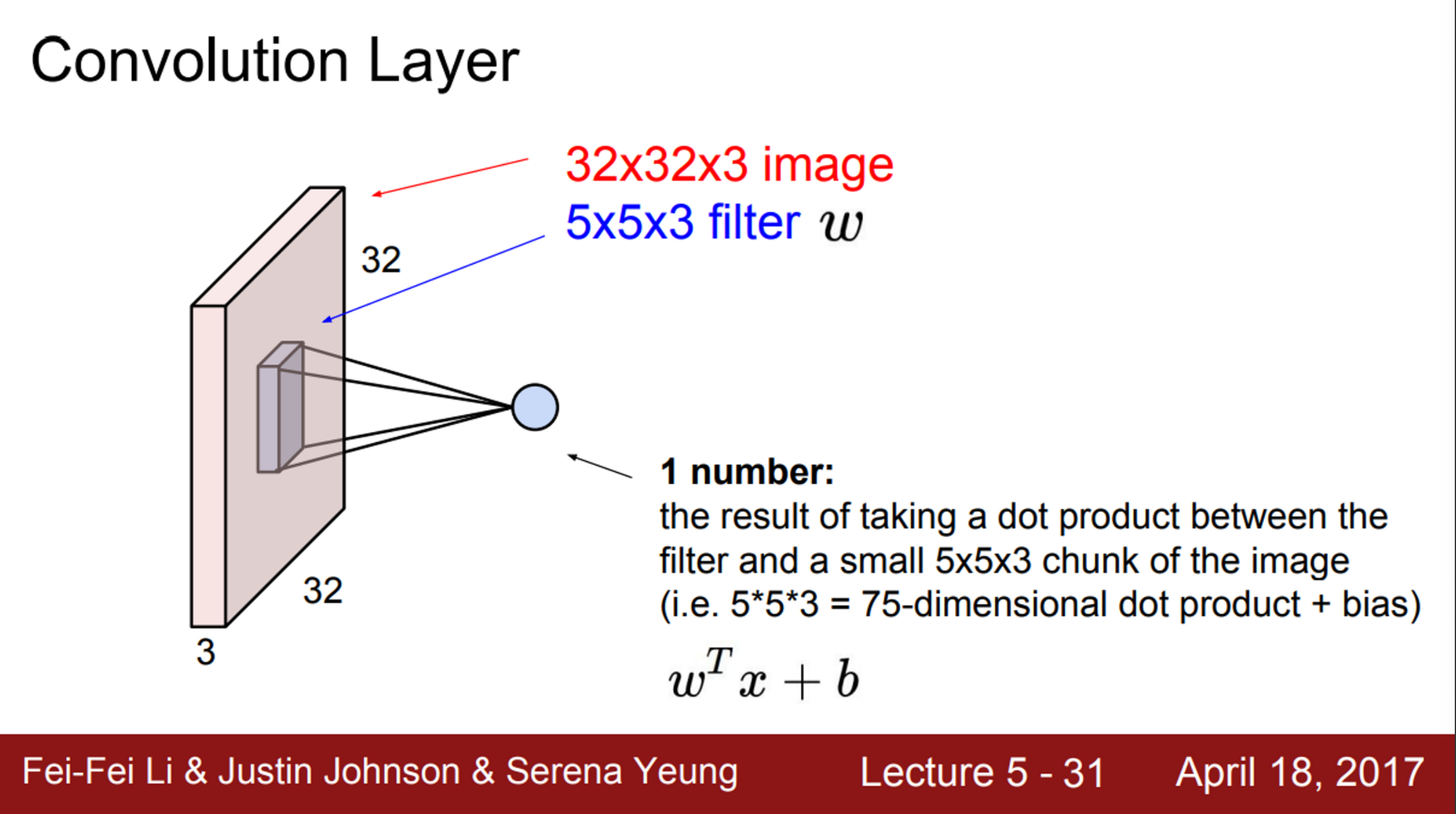
- Convolution Layer와 기존의 FC Layer의 주된 차이는, Convolution Layer는 기존의 구조를 보존시킨다는 것
- 기존의 FC Layer가 입력 이미지를 길게 쭉 폈다면, Convolution Layer는 이미지 구조를 그대로 유지
- 파란색의 작은 필터가 우리가 가진 가중치
- 이 필터를 가지고 이미지를 슬라이딩하면서 공간적으로 내적을 수행
- 우선 필터는 입력의 깊이(Depth)만큼 확장
- 하나의 필터는 아주 작은 부분만 취할 수 있음
- 해당 예시에서는, 32X32 이미지에서 5X5만 취함
- 하지만 깊이를 보면, 전체 깊이를 전부 취함 (즉, 5X5X3)
-
이 필터를 가지고 전체 이미지에 내적
- 필터를 이미지의 어떤 공간에 겹친 후 내적을 수행
- 필터의 각 와, 이에 해당하는 이미지의 픽셀을 곱해줌
- 기본적으로 를 수행하는 것
-
Q. 내적을 진행할 때, 5X5X3 짜리 긴 벡터를 사용하는 것인지? (flatten 후 사용에 대한 질문)
- A. 각 원소끼리 Convolution을 하는 것과 벡터를 flatten해서 내적을 하는 것은 똑같은 일을 하는 것
-
Q. 왜 를 transpose 하는지에 대한 직관이 있는지?
- 내적을 수학적으로 표현하기 위해, 표현만 이렇게 한 것
- Convolution 연산을 표현할 때, 우리가 보기 쉽도록 필터를 이미지에 겹쳐 놓는 방식으로 표현
- 실제 연산에서는 모두 펴서 벡터 간 내적을 구함
- Convolution은 이미지의 좌상단부터 시작, 필터의 중앙에 값들을 모음
- 필터의 모든 요소를 가지고 내적을 수행하게 되면, 하나의 값을 얻음
- 이후 슬라이딩을 진행
- Conv 연산을 수행하는 값들을 다시 output activation map의 해당하는 위치에 저장
- 해당 예제에서, 입력 이미지와 출력 activation map의 차원이 다른 것을 알 수 있음 (입력은 32X32, 출력은 28X28)
- 이는 Convolution 연산 때문에 발생하는 현상
- 출력 행렬의 크기는 슬라이드를 어떻게 하느냐에 따라 다름
- 기본적으로는 하나씩 연산을 수행
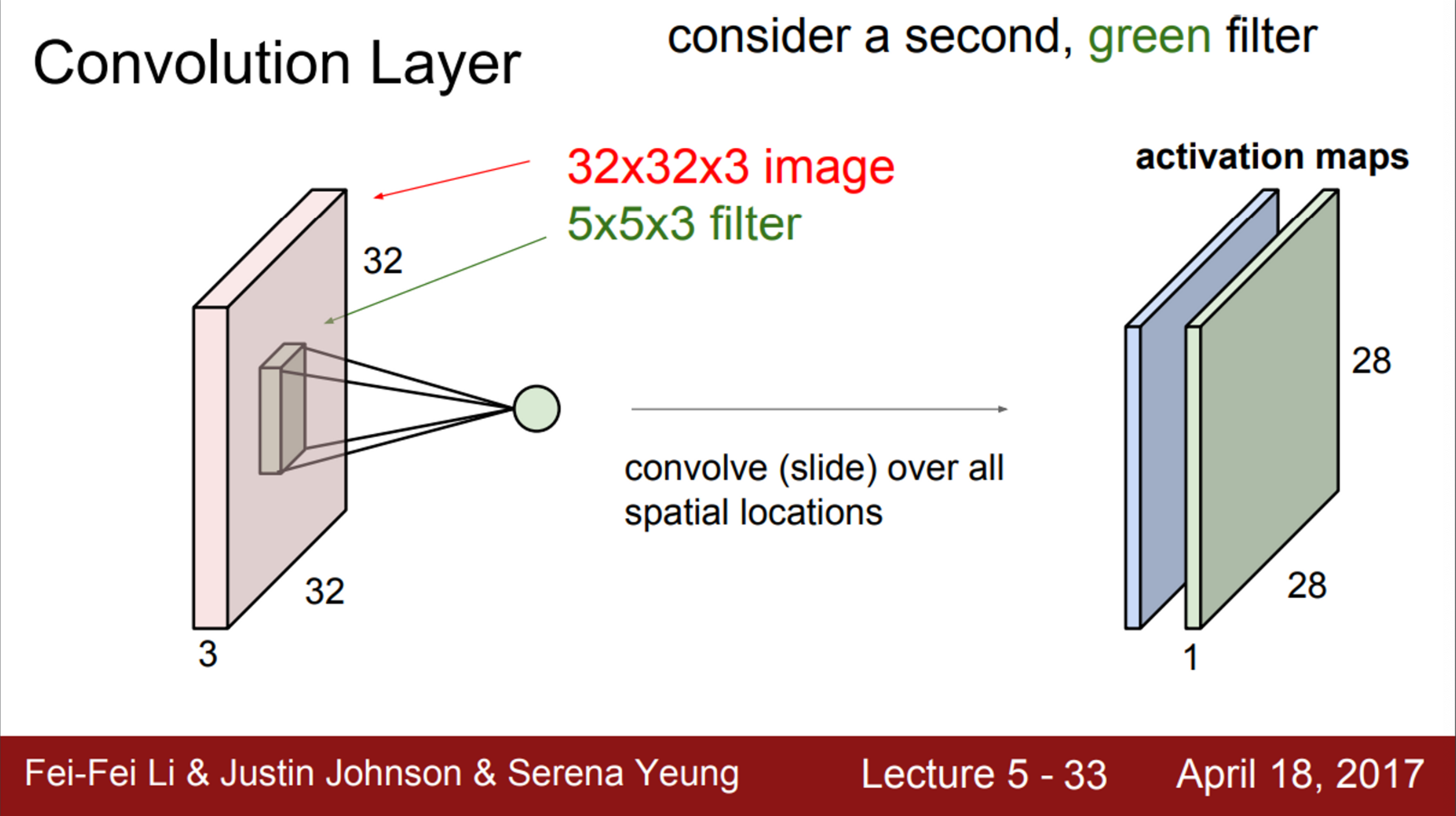
- 하나의 필터를 가지고 전체 이미지에 Convolution 연산을 수행
- 그러면, activation map이라는 출력값을 얻음
- 보통 Convolution Layer에서는 여러개의 필터를 사용함
- 필터마다 다른 특징을 추출하고 싶기 때문에
- 따라서, 보통 여러 개의 필터를 사용함

- 하나의 Convolution Layer에서 원하는 만큼 여러 개의 필터를 사용할 수 있음
- 5X5 필터가 6개가 있다면, 총 6개의 activation map을 얻음
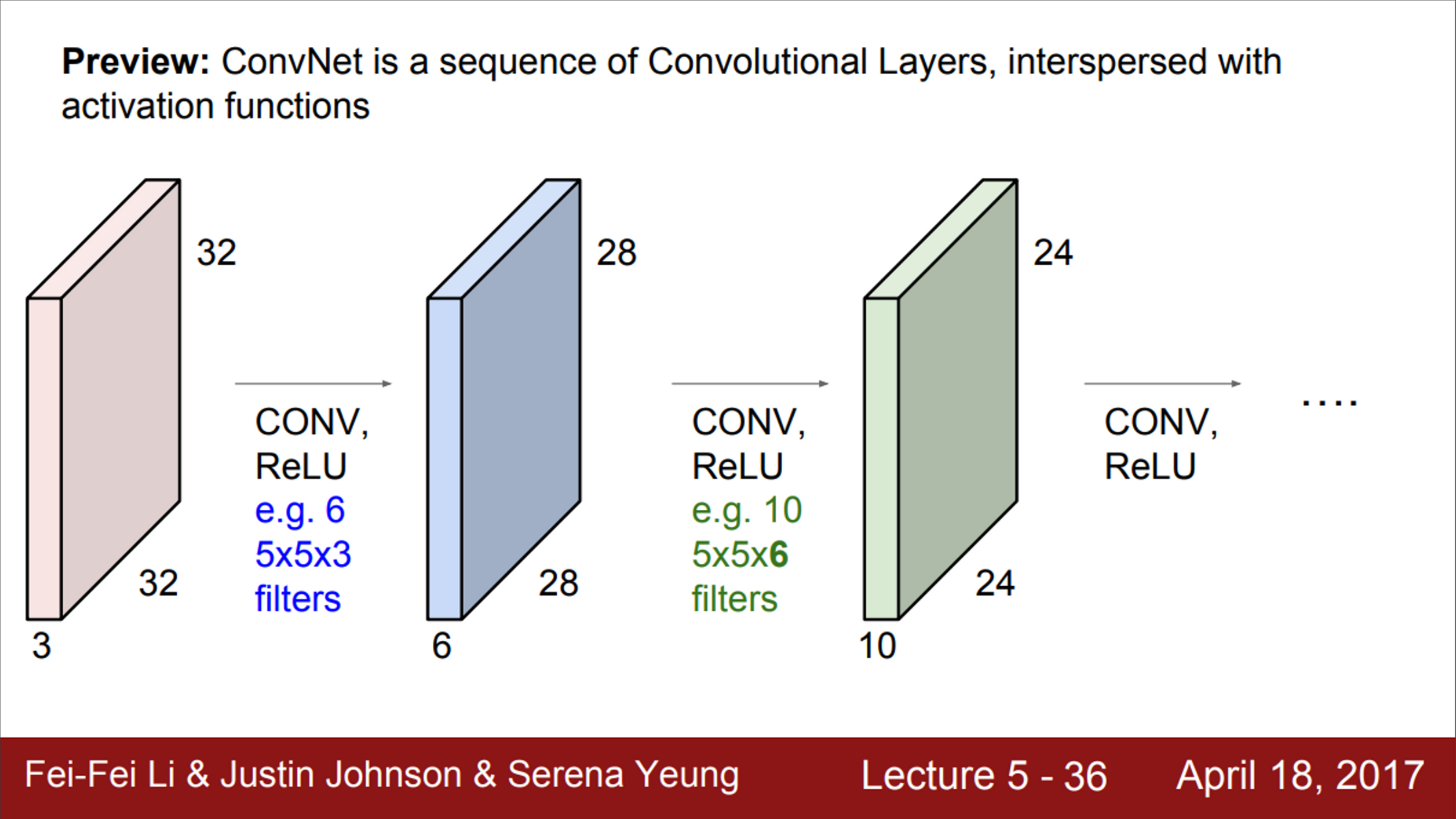
- Convolution Layer들의 연속된 형태
- 각각을 쌓아 올리게 되면, 간단한 Linear Layer로 된 Neural Network
- 사이 사이에 activation function을 넣을 것 (ex. ReLU)
- 즉, Conv-ReLU 가 반복 (가끔씩 pooling layer도 들어감)
- 각 Layer의 출력은 다음 Layer의 입력
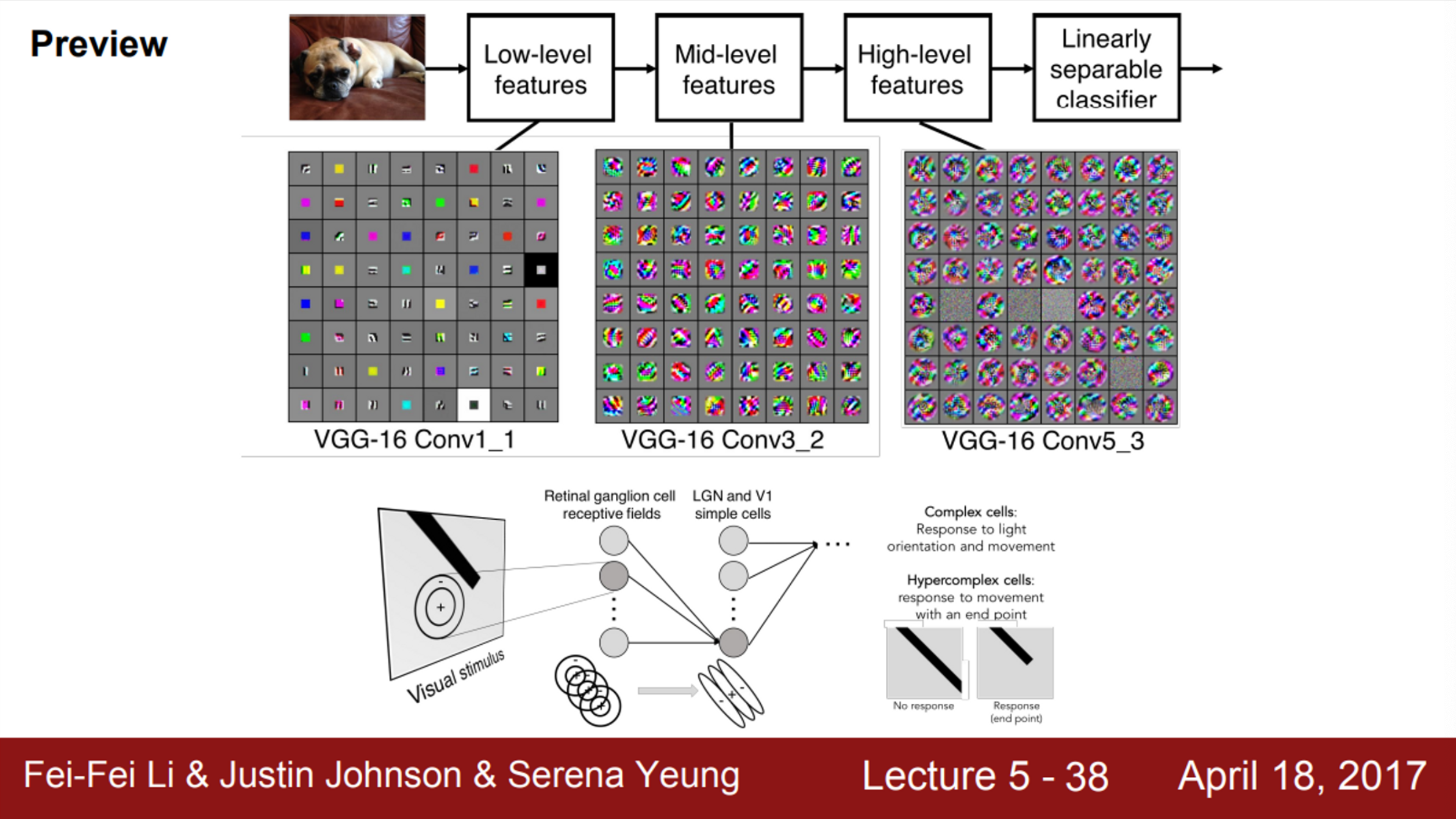
- 각 Layer는 여러 개의 필터를 가지고 있음
- 그리고 각 필터마다 각각의 출력 map을 만듦
- 따라서, 여러 개의 Layer들을 쌓고 나서 보면, 결국 각 필터들이 계층적으로 학습을 하는 것을 보게 됨
- 앞쪽에 있는 필터들은 low-level feature를 학습 (edge)
- mid-level feature를 보면, 조금 더 복잡한 특징을 가짐 (코너, blob 등)
- high-level feature는 좀 더 객체와 닮은 것들이 출력
- 즉, Layer의 계층에 따라서 단순/복잡한 feature들이 존재한다는 것
- 지금까지는 Convolution Layer를 계층적으로 쌓아서 단순한 특징을 뽑고, 그것을 조합해서 더 복잡한 특징으로 활용했음
- Network의 앞쪽에서는 단순한 것들을 처리하고, 뒤로 갈수록 점점 더 복잡한 것들을 처리
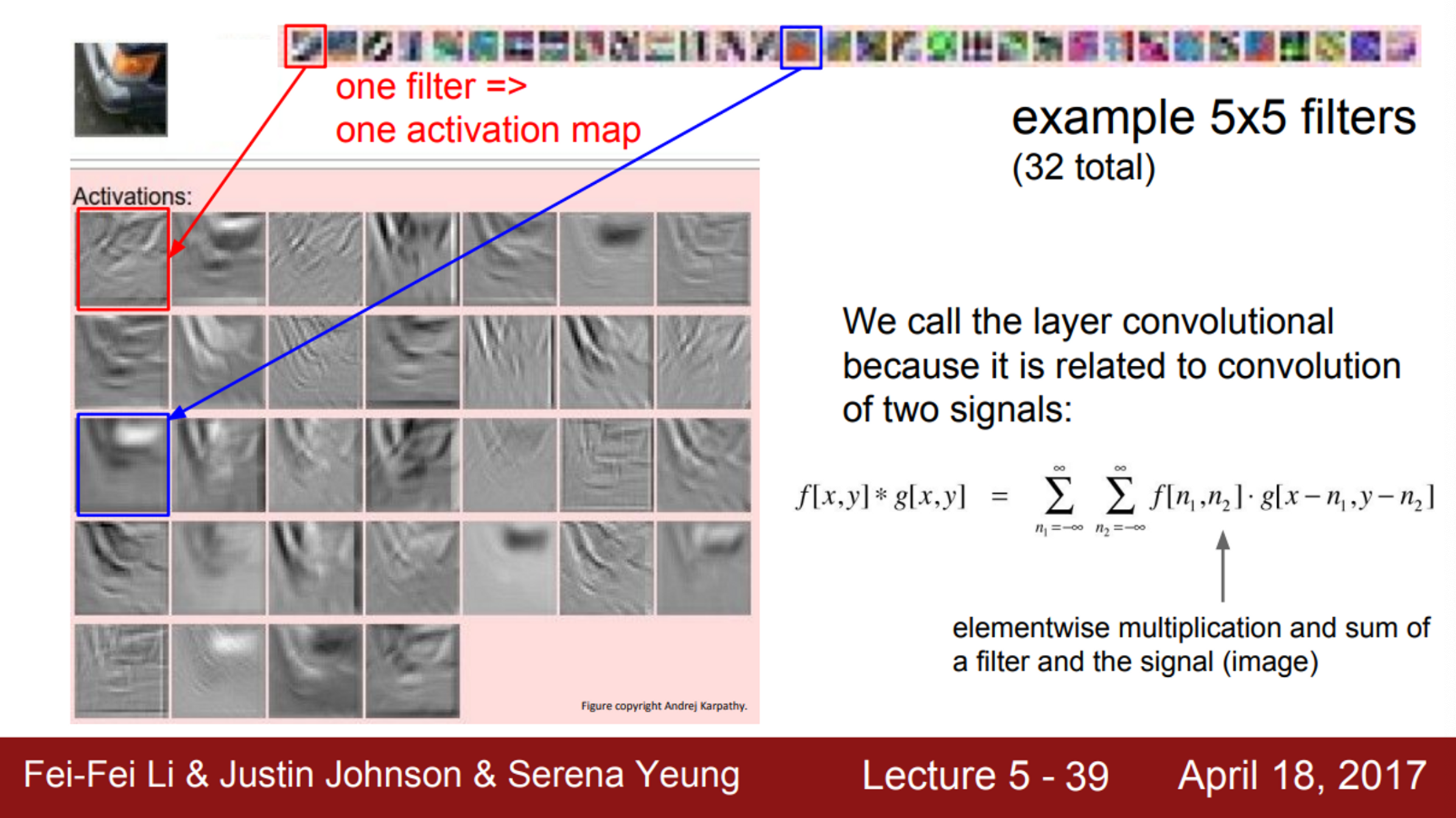
- Activation map의 예제 (각 필터가 만든 출력값)
- 빨간색 필터는 edge를 찾는 필터
- 이 필터를 슬라이딩 시키면, 이 필터와 비슷한 값들은 값이 더 커지게 됨
- 즉, 각 activation map은 이미지가 필터를 통과한 결과가 되며, 이미지 중 어느 위치에서 이 필터가 크게 반응하는지 보여줌
- 빨간색 필터는 edge를 찾는 필터

- CNN의 수행 과정을 보면,
- 입력 이미지는 여러 layer를 통과
- ex. 첫 번째 Conv layer를 통과한 후 non-linear layer(ReLU)를 통과
- Conv - ReLU - Conv - ReLU 를 통과한 후, pooling layer를 거치게 됨
- pooling은 activation map의 사이즈를 줄이는 역할을 수행
- CNN의 끝단에는 FC-layer가 있음
- 마지막 Conv 출력 모두와 연결되어 있으며, 최종 스코어를 계산하기 위해 사용함
- 입력 이미지는 여러 layer를 통과
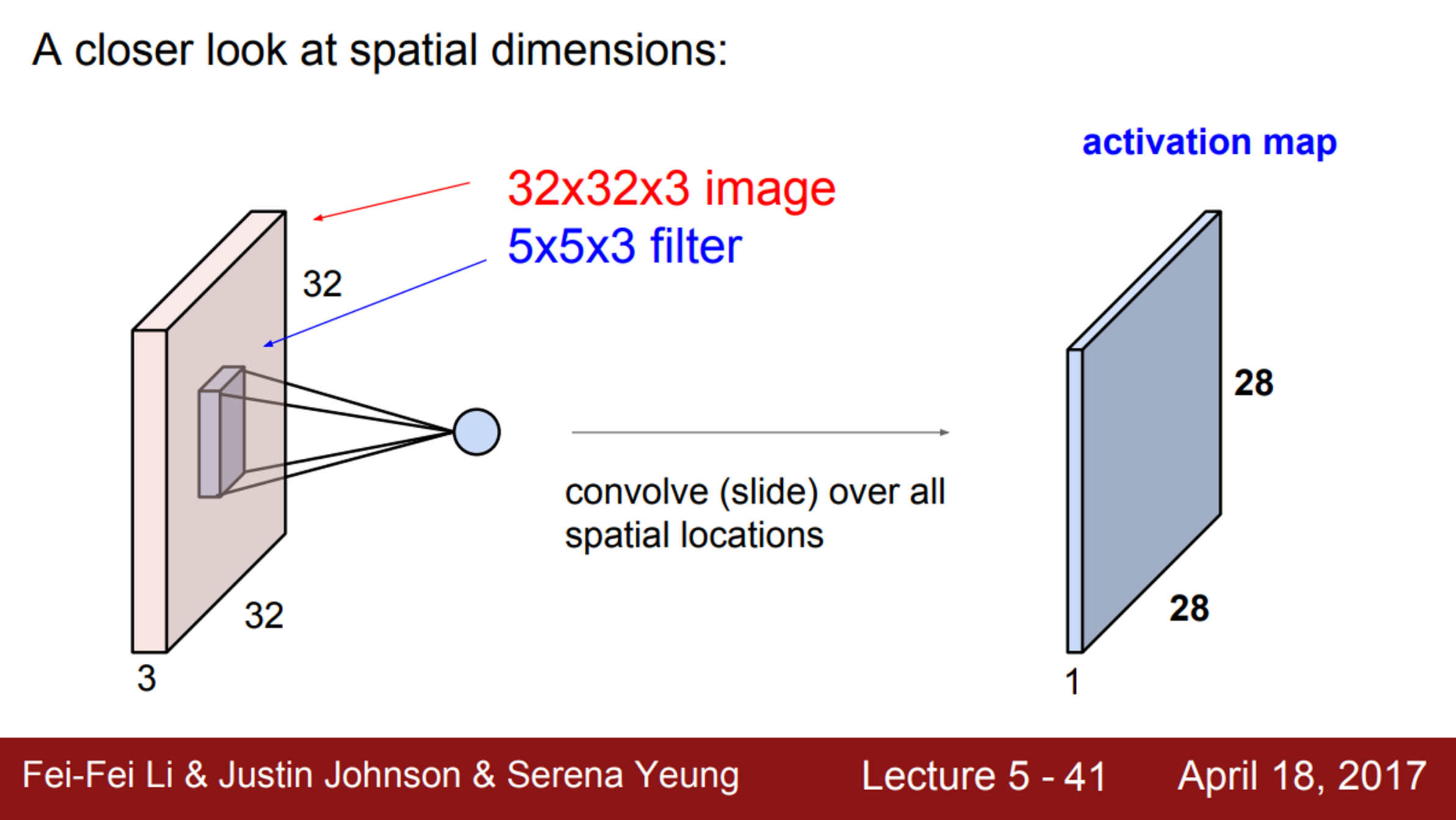
- Spatial dimension이란…
- 32X32X3 이미지가 있고, 5X5X3 필터를 가지고 Conv 연산을 수행
- 수행 결과로 28X28 activation map이 생성되는데, 어떻게 생기는지 알아보자
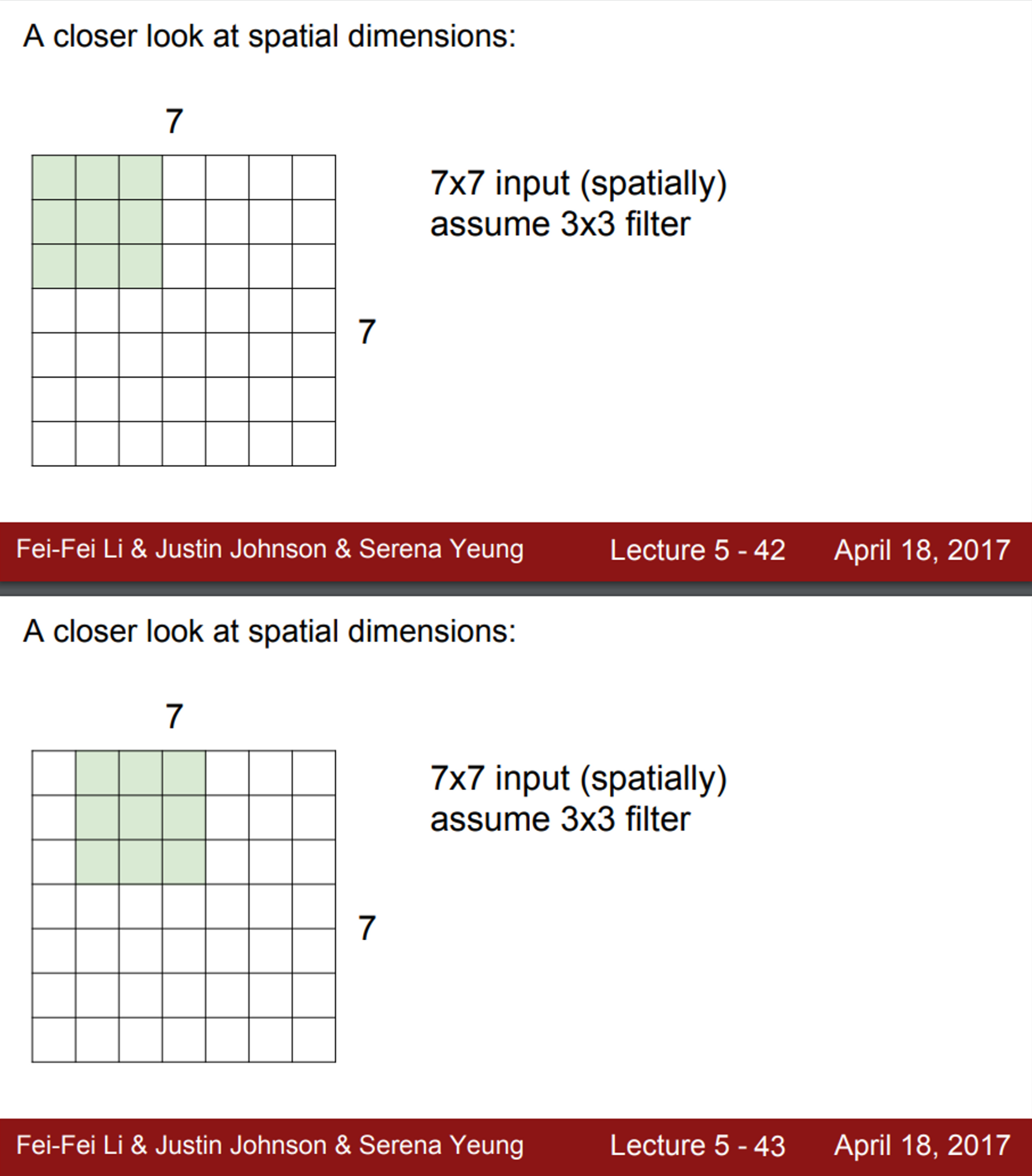
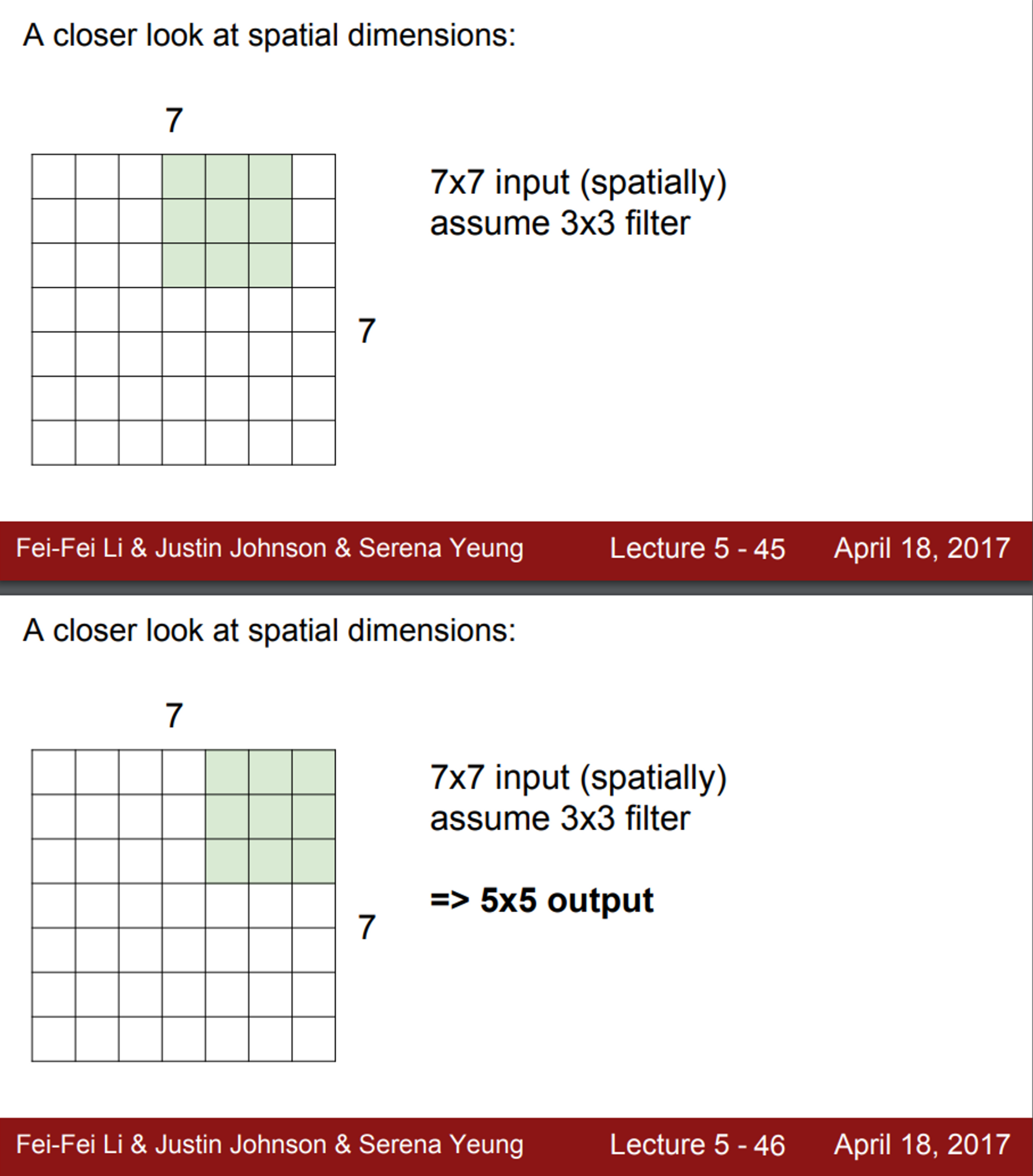
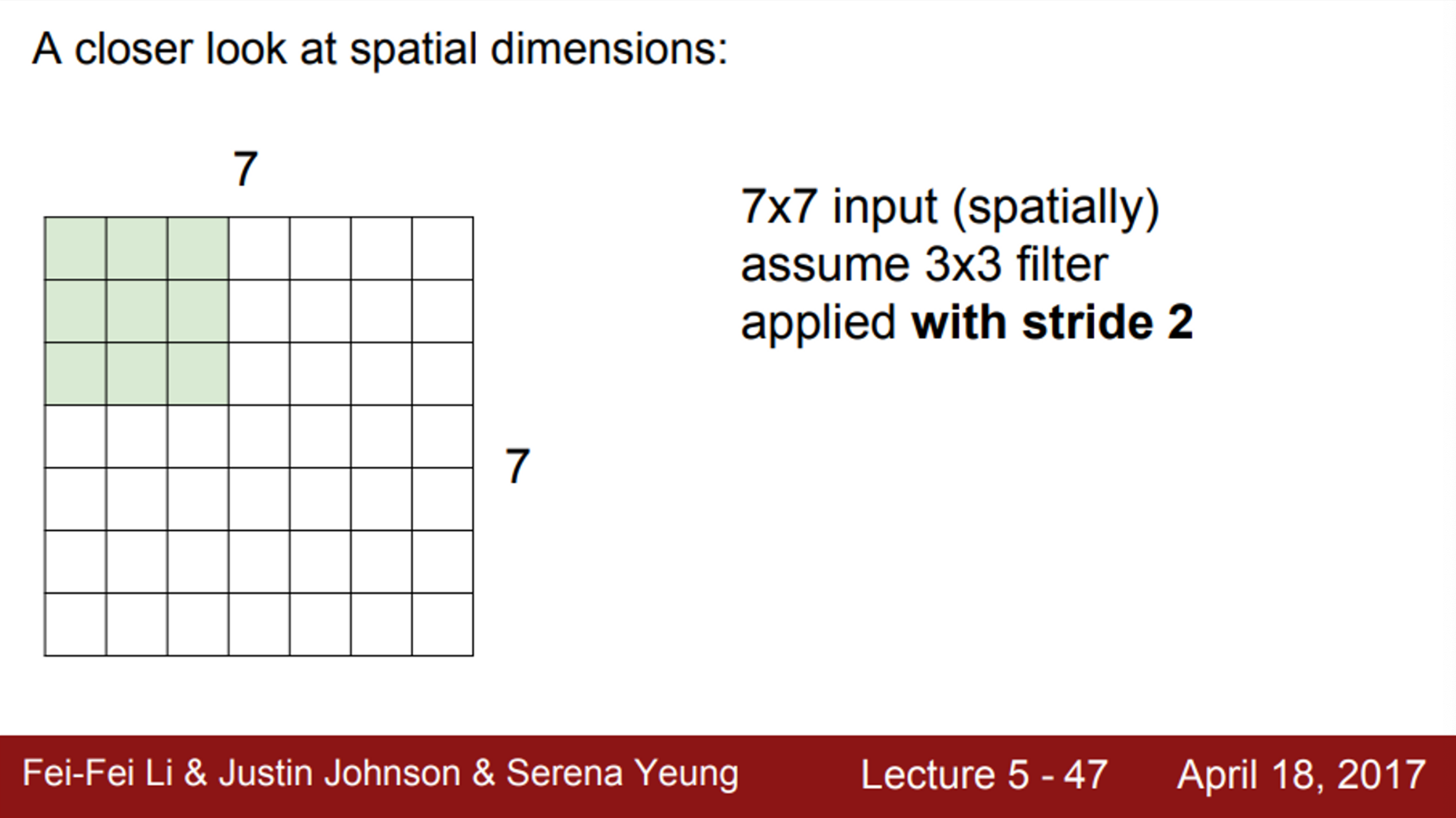
- 간단한 예시로, 7X7 입력에 3X3 필터가 있다고 가정해보면, (stride=1)
- 필터를 이미지의 왼쪽 상단부터 씌우고, 해당 값들의 내적을 수행
- 연산 후 값들은 activation map의 왼쪽 상단에 위치
- 다음 단계로 필터를 오른쪽으로 한 칸 움직임
- 또 다른 연산 값을 얻을 수 있음
- 이 과정을 반복하게 되면, 최종적으로 5X5 출력을 얻게 됨
- 이 슬라이드 필터는 좌우 방향으로 5번, 상하 방향으로 5번 수행 가능
- 필터를 이미지의 왼쪽 상단부터 씌우고, 해당 값들의 내적을 수행
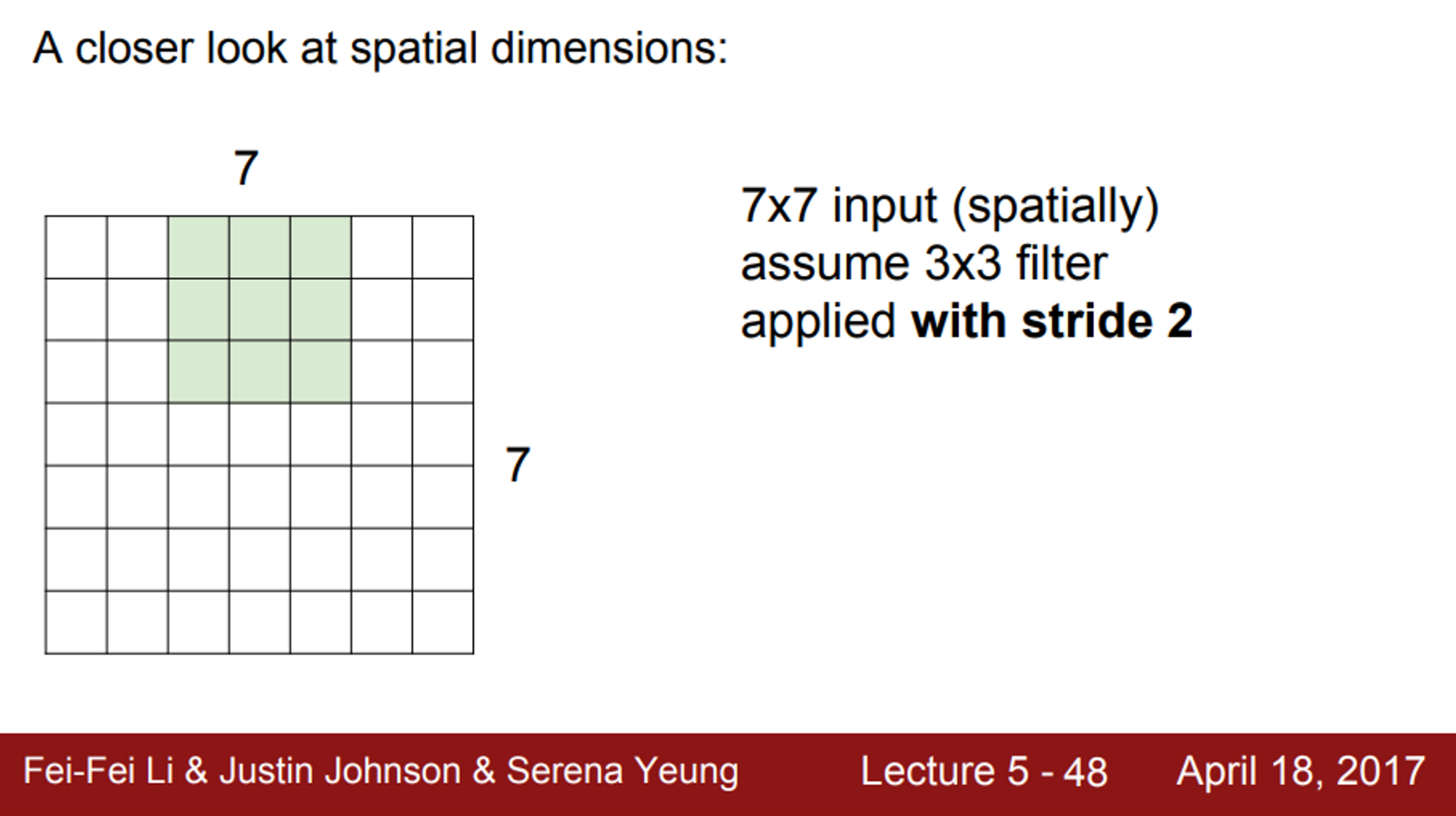
- 다음으로는 stride=2 인 경우,
- stride는 움직이는 칸의 갯수를 의미
- 이미지의 왼쪽 상단부터 시작해서, 움직임
- 단, 움직일때 1칸씩 이동하는 것이 아니라, 2칸씩 이동
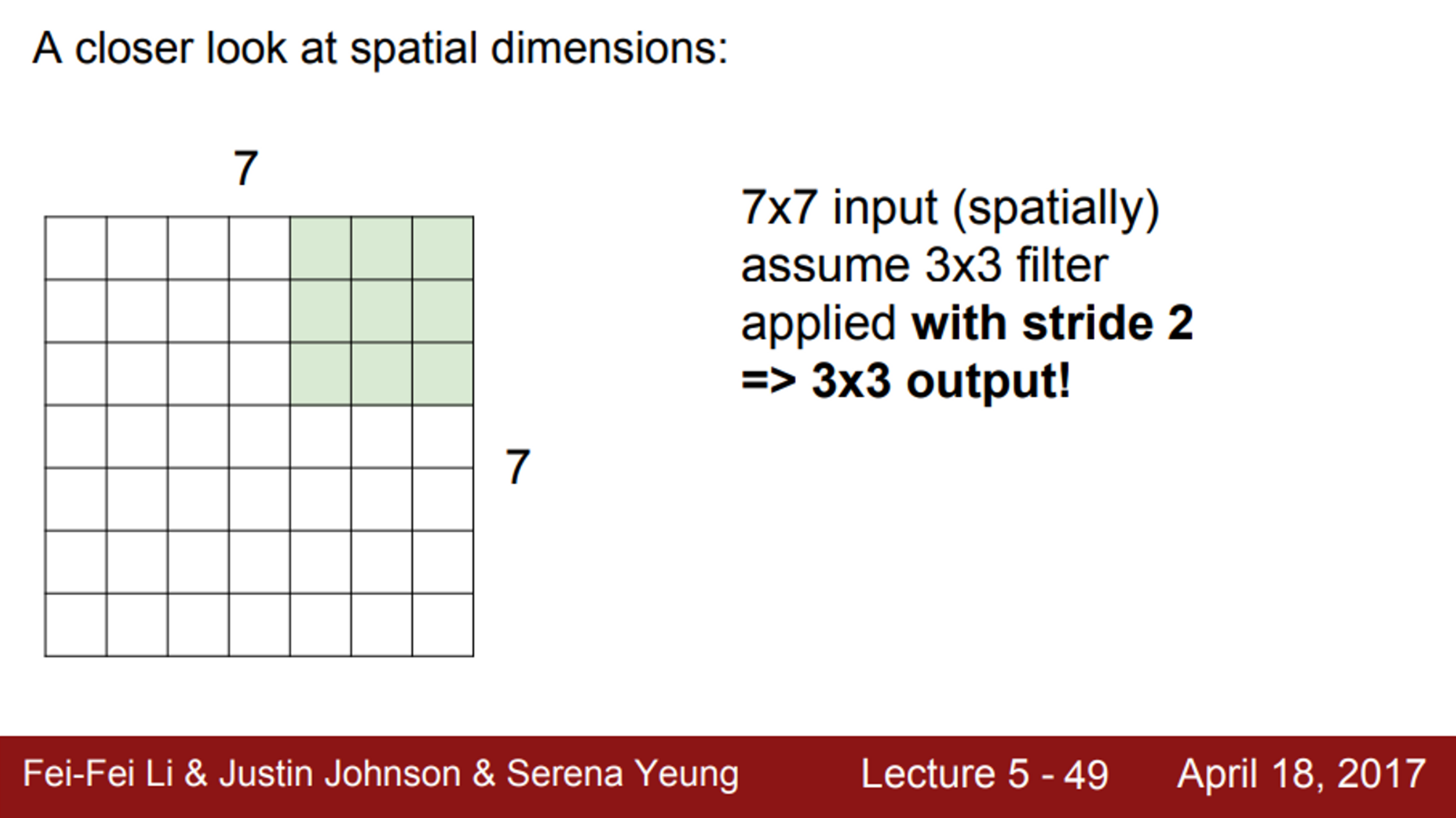
- stride=2이면, 최종 출력은 3X3

- 그렇다면, stride=3이면 출력의 사이즈는 얼마인가?
- stride=3인 경우에는, 필터가 모든 이미지를 커버할 수 없음
- 실제로 이렇게 되면 잘 동작하지 않음

- 상황에 따라 출력의 사이즈가 어떻게 될 것 인지를 계산할 수 있는 수식이 존재
- 입력의 차원이 N이고, 필터 사이즈가 F이고, stride의 값이 주어지면,
- 출력의 크기는
- 이를 이용해서, 어떤 필터 크기를 사용해야 하는지 알 수 있음
-
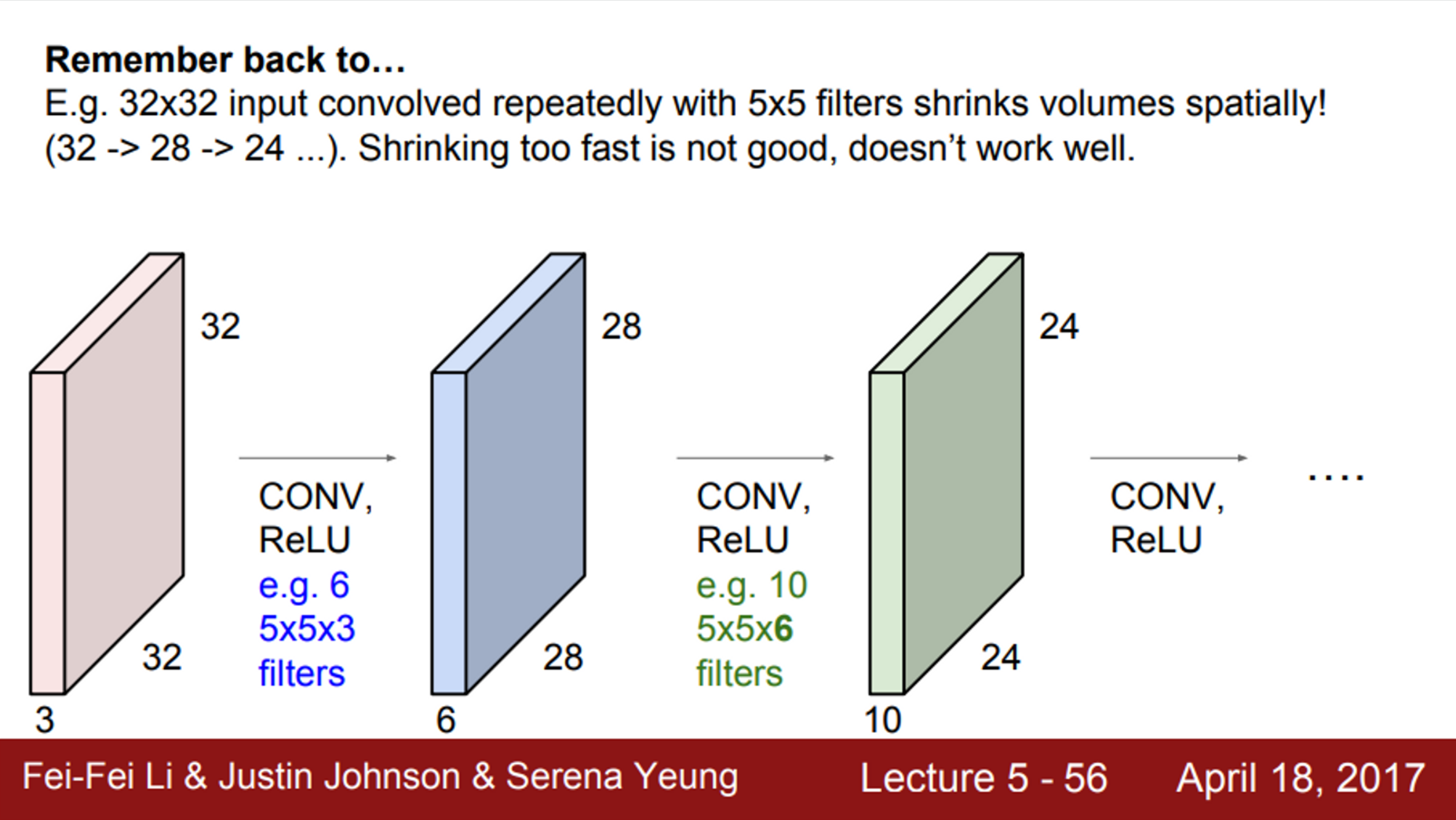
하지만, 앞서 본 Conv 연산의 문제는 이미지의 테두리 정보를 잘 수용하지 못한다는 문제가 있음
-
추가적으로, Conv 연산을 수행하면 출력 activation map이 작아지기 때문에, 사이즈가 계속 줄어든다는 문제도 존재
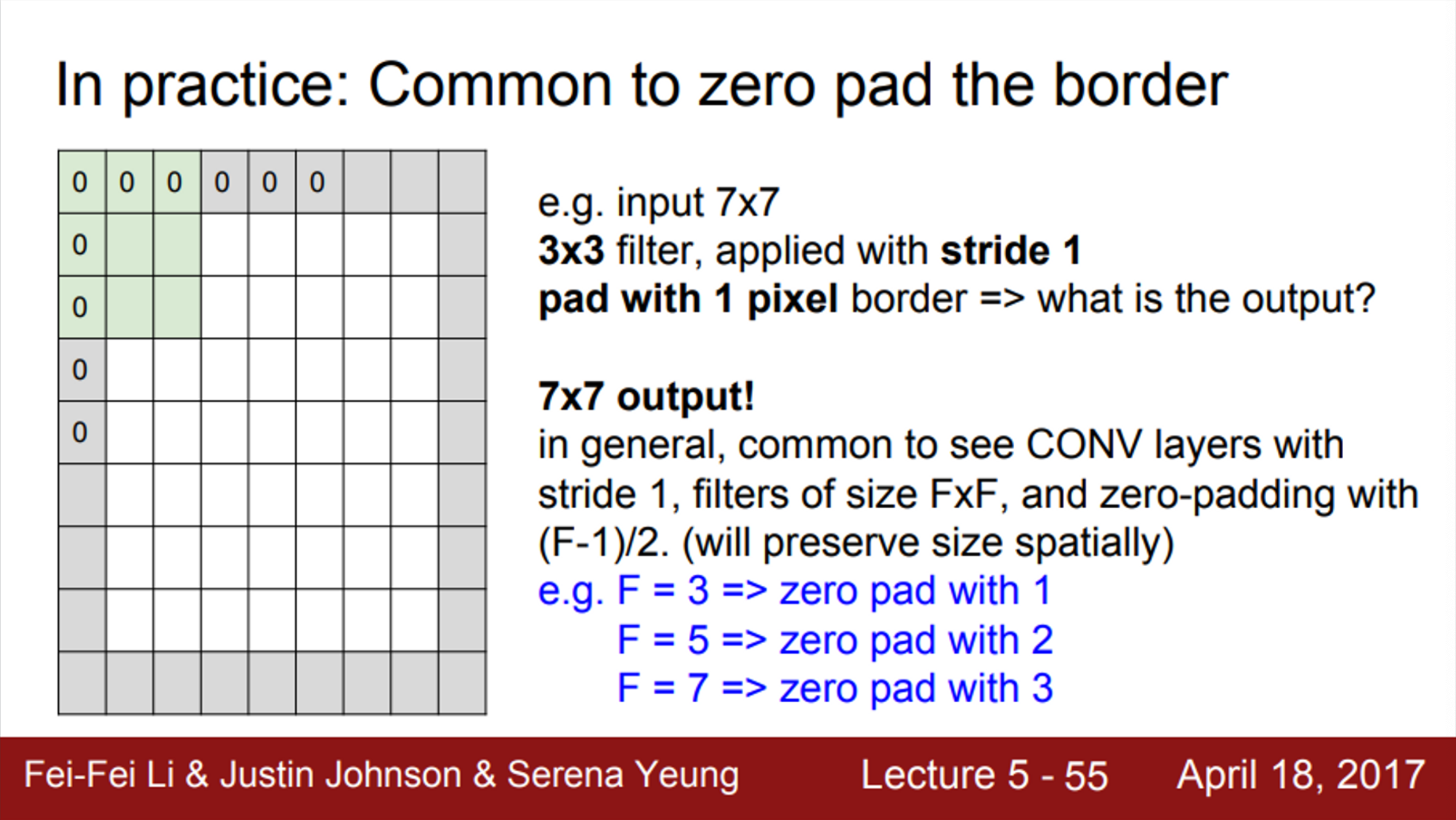
- 이를 해결하기 위해, 가장 흔히 쓰는 기법은 zero-padding
- 이미지의 가장자리에 0을 채워 넣는 방법
- 이렇게 되면, 이미지의 가장자리에서도 필터 연산을 수행할 수 있음
- 또한, activation map의 사이즈가 입력 이미지 사이즈와 동일하게 유지됨
-
Q. zero-padding을 하게 되면, 모서리에 필요 없는 특징을 추가하게 되는 것이 아닌지?
- A. 우리가 원하는 것은 이미지 내 어떤 모서리 부분에서 값을 얻고 싶은 것이고, zero-padding은 이를 할 수 있는 하나의 방법
- Conv 연산을 수행할 때, zero-padding을 하지 않는다면,
- 출력 사이즈는 계속 줄어듦
- 이는 우리가 원하는 결과가 아님
- 이를 해결하기 위해서, padding을 이용
- 출력 사이즈는 계속 줄어듦

- Conv 연산 예제 - Output 사이즈 계산

- Conv 연산 예제 - 파라미터의 총 갯수

- 정리해보면,
- 어떤 N차원의 입력이 있을 때, 다음의 내용들을 정해줘야함
- 어떤 필터를 사용할지
- 몇 개의 필터를 사용할지
- 필터 크기는 얼마인지
- stride는 얼마로 할지
- zero-padding은 얼마로 할지
- 어떤 N차원의 입력이 있을 때, 다음의 내용들을 정해줘야함

- 일반적으로 Convolution 필터의 크기는 3X3, 5X5, 7X7을 많이 사용함
- 그렇다면, 1X1 필터는? (Pointwise Convolution)
- 5X5 처럼, 공간적인 정보를 이용하진 않지만, Depth 만큼 연산을 수행함
- 즉, 1X1 Conv는 입력의 전체 Depth에 대한 내적을 수행
- 1X1 Convolution의 역할은 다음과 같음
- 행과 열의 크기 변환 없이 Channel의 수를 조절
- 행과 열, Channel의 수를 변환하지 않고 단순히 weight 및 비선형성을 추가하는 역할로도 사용할 수 있음 (1X1 Conv 연산 후 ReLU와 같은 activation function을 사용하기 때문에)
- 즉, 차원 축소, 계산량 감소, 비선형성 증가, overfitting 방지 가능
- 추가적으로, Depthwise Convolution 도 함께 찾아보자
- Convolution layer 예제 (feat. Pytorch, Caffe)
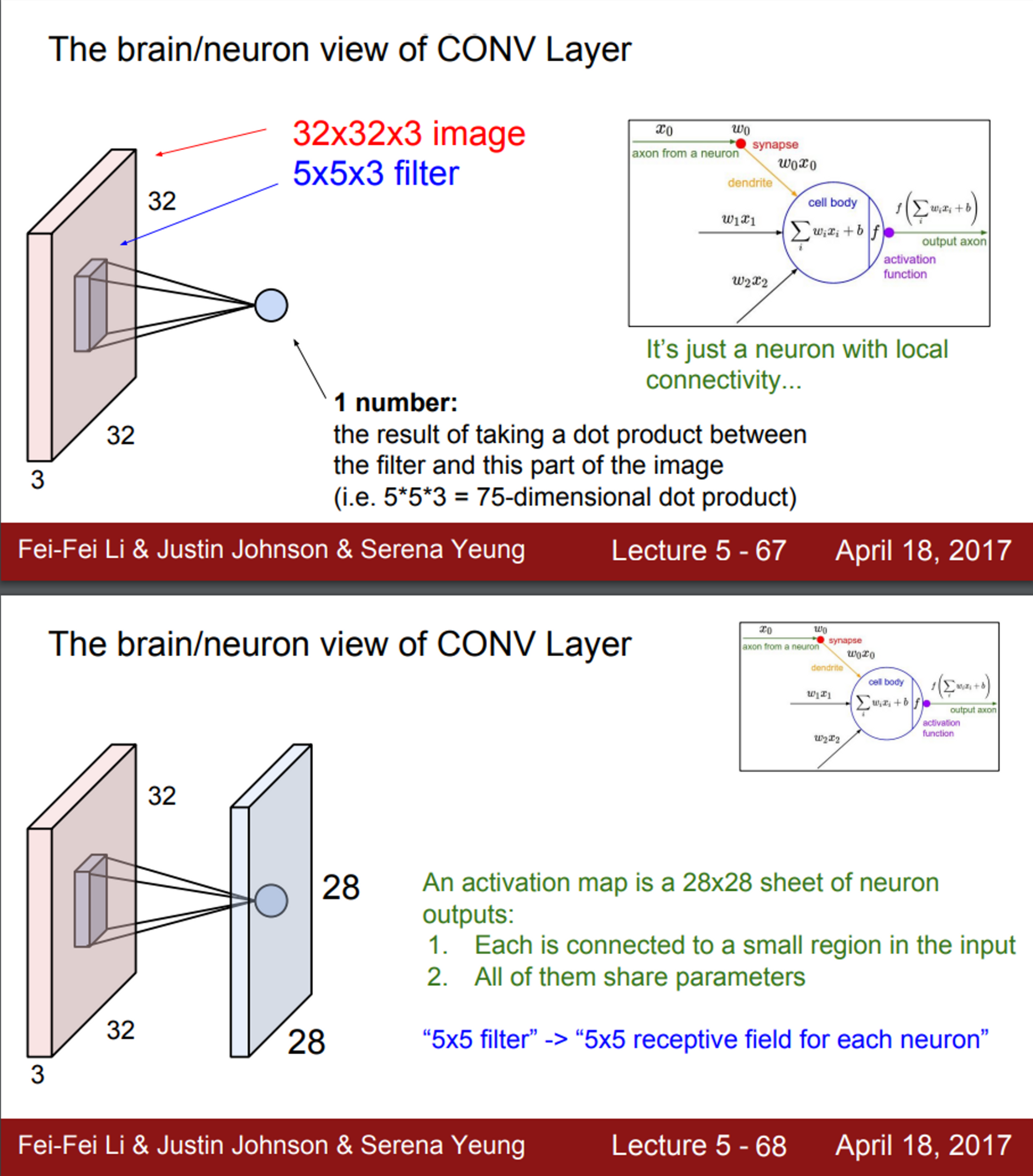
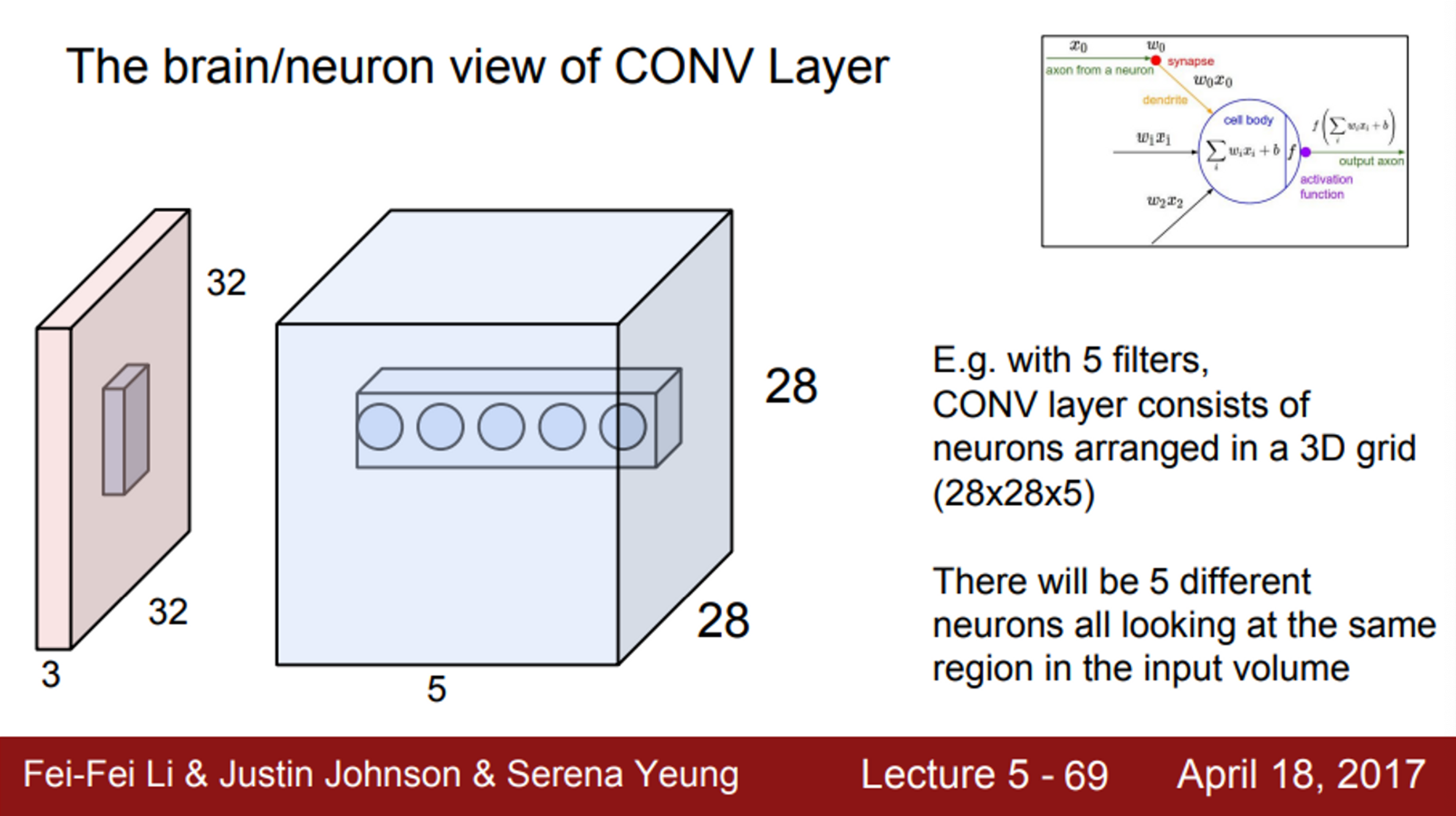
- 실제 neuron과 비교한 Conv 연산
- CNN에서 사용되는 다른 Layer
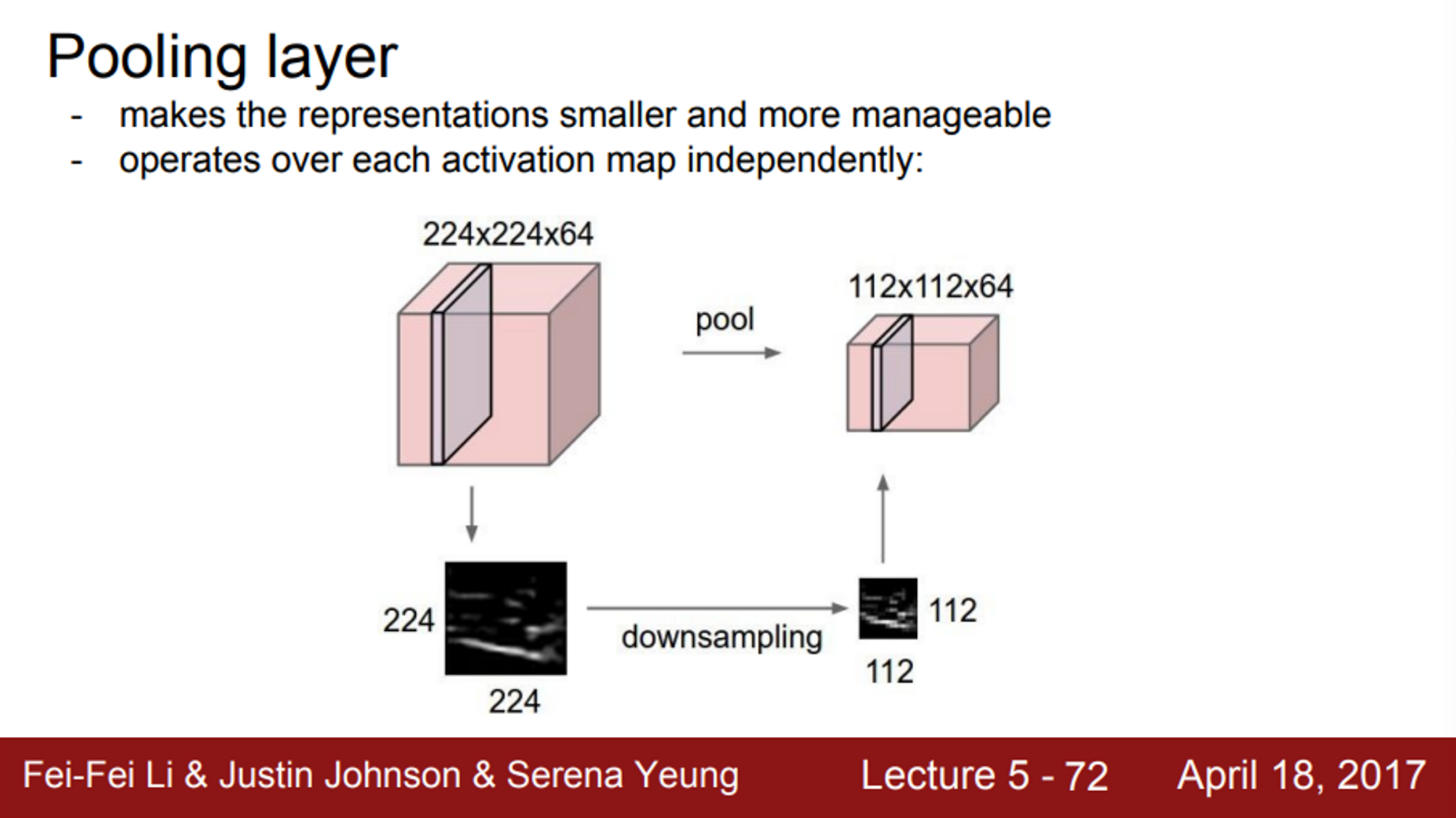
- Pooling layer (비선형 layer)
- 이미지 사이즈를 줄이는 역할 (Downsampling)
- output size를 더 작고 관리하기 쉽게 해줌
- output size가 작아지면, 파라미터의 수가 줄어듦
- 일종의 공간적인 불변성을 얻을 수도 있음
- 중요한 점은 Depth에는 아무 짓도 안함
- W, H에만 수행
- 일반적으로 Max Pooling을 사용
-
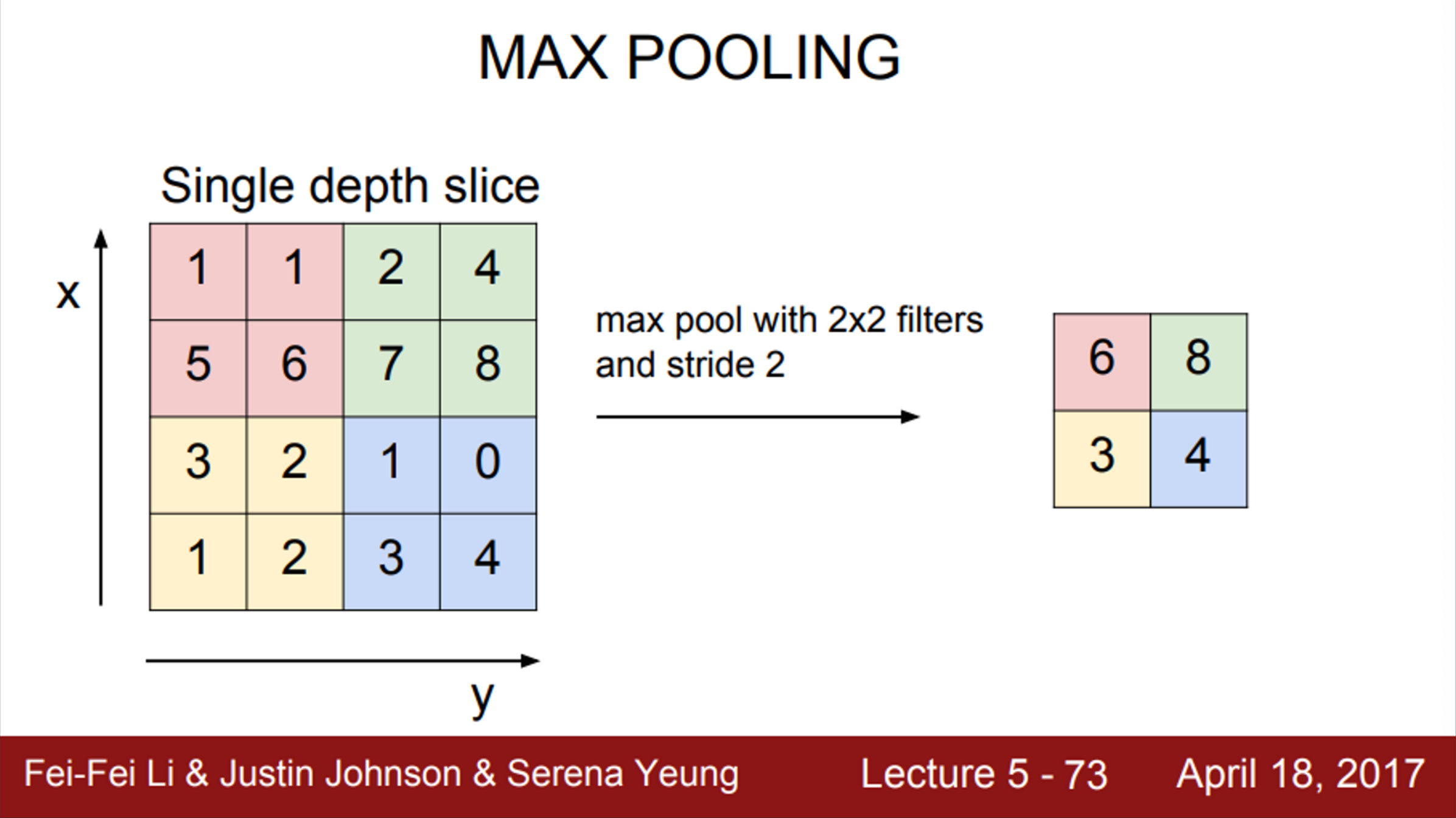
Pooling도 필터 크기를 정할 수 있음
- 얼마만큼의 영역을 하나로 묶을 것인지를 결정
- 예제는 2X2 filter, stride=2
- Conv layer가 했던 것처럼, 슬라이딩하면서 연산을 수행
- 대신 내적이 아니라, 필터 안의 값들 중 가장 큰 값 하나를 고르는 것
-
Q. Pooling을 할 때, 겹치지 않는 것이 일반적인지?
- A. Downsampling을 하고 싶은 것이기 때문에 보통은 겹치지 않는 것이 일반적.
-
Q. Max Pooling이 Average Pooling보다 좋은 이유는?
- A. 우리가 다루는 값들은, 얼마나 뉴런이 활성화 되었는 지를 나타내는 값들
- 즉, 이 필터가 각 위치에서 얼마나 활성되었는지
- Max Pooling은 그 지역이 어디든, 어떤 신호에 대해 ‘얼마나’ 그 필터가 활성화 되었는지를 알려줌
- 즉, 그 값이 어디에 있었는지 보다는, 그 값이 얼마나 큰지가 중요한 것
-
Q. Pooling이나 Conv layer의 stride나 마찬가지 아닌지?
- A. 실제로 최근에는 Downsampling 할 때, Pooling을 하기 보단 stride를 많이 사용하는 추세
- Pooling도 일종의 stride 기법이라고 볼 수 있음
- 그리고, stride가 더 좋은 성능을 보이는 것 같음
- 따라서, Pooling 대신 stride를 사용해도 무방함

- Pooling Layer에는 몇 가지 Design choice가 있음
- 입력이 W(width), H(height), D(depth)일 때, 이를 통해서 필터 사이즈를 정해줄 수 있음
- 여기에 stride까지 정해주면, 앞서 Conv Layer에서 사용했던 수식을 그대로 이용해서 Design Choice를 할 수 있음
- 한 가지 특징이 있다면, Pooling layer에서는 보통 padding을 하지 않음
- 우리는 Pooling 을 통해서 downsampling을 하고 싶고, Conv 연산처럼 코너의 값을 계산하지 못하는 경우도 없기 때문에
- 가장 널리 쓰이는 필터 사이즈는 2X2, 3X3 이고, 보통 stride는 2로 사용

- 결국 CNN은,
- Conv - ReLU - Conv - ReLU - Pooling 와 같은 연산들의 반복 후,
- Conv - ReLU - Pooling을 통해서 나온 최종 연산 output을 전부 펴서 (Flatten) 1차원 벡터로 만듦
- 이렇게 만든 1차원 벡터를 가장 마지막에 연결되어 있는 FC layer의 입력으로 사용
- 이때부터는 공간적 구조 (spatial structure)를 신경 쓰지 않음
- 전부 다 하나로 통합시키고, 최종적인 추론을 진행
- 이후 FC layer는 최종 스코어를 계산


코딩하는 물리학도