💡텍스트 분류(Text Classification)
2가지 범주에 대해 구분하는 문제를 이진 분류(Binary Classification) 문제라 하고, 3개 이상의 범주에 대해 분류하는 문제를 통틀어 다중 범주 분류(Multi class Classification)라고 한다.
📌 텍스트 분류 예시
스팸 분류
자동으로 일반 메일과 스팸 메일을 분류하는 문제!
즉 범주(class)는 스팸 메일과 일반 메일로 2가지다.
감정 분류
주어진 글이 긍정적인지 부정적인지 판단하는 문제!
대표적으로 영화 리뷰에 대해 각 리뷰가 긍정적인지 부정적인지 판단하는 문제가 있다.
뉴스 기사 분류
수많은 뉴스 기사를 주제에 맞게 분류해주는 문제!
스포츠, 경제, 사회, 연예 등 다양한 주제의 기사를 주제에 맞게 분류해는 문제가 있다.
분류하는 단위를 글 전체로 하지 않고 각 단어를 한 단위로 분류하는 문제도 있다. (품사, POS tagging 문제처럼)
📌 지도 학습과 비지도 학습
🔎 지도 학습을 통한 텍스트 분류
지도 학습은 데이터에 대해 클래스 값(라벨)이 이미 주어져 있다.
따라서 주어진 클래스로 모두 학습한 후 학습 결과를 이용해 새로운 글의 클래스를 예측하는 방법이다.
학습 시, 각 데이터에서 특징을 뽑아내서 예측한 뒤 라벨과 맞는지 확인하면서 학습한다.
지도 학습 모델의 예는
- Naive Bayes Classifier, 나이브 베이즈 분류
- Support Vector Machine, 서포트 벡터 머신
- Neural Network, 신경망
- Linear Classifier, 선형 분류
- Logistic Classifier, 로지스틱 분류
- Random Forest, 랜덤 포레스트
🔎 비지도 학습을 통한 텍스트 분류 (=텍스트 군집화)
데이터만 존재하고, 각 데이터는 범주로 미리 나눠져 있지 않다.
따라서 특성을 찾아내서 적당한 범주를 만들어 각 데이터를 나누면 된다.
대표적인 예로, K-means clustering이 있다.
각 문장 데이터를 벡터화한 후 좌표측에 표현한다.
이후 k-평균 군집화 모델로 데이터를 몇 개의 군집으로 나눈다.
비지도 학습을 통한 분류는 어떤 특정한 분류가 아닌 데이터 특성에 따라 비슷한 데이터끼리 묶어주는 개념이다.
비지도 학습 모델의 예는
- K-means Clustering
- Hierarchical Clusterin, 계층적 군집화
데이터에 정답 라벨이 있느냐 없느냐라는 기준으로 지도 학습 vs 비지도 학습을 선택하면 된다.
💡텍스트 유사도(Text Similarity)
유사도를 판단하는 척도는 매우 주관적이라 데이터를 구성하기 쉽지 않고 정량화하는 데 한계가 있다.
일반적으로 유사도를 측정하기 위해 정량화 하는 방법에는 여러 가지가 있는데, (1) 단어의 개수를 사용해서 유사도 판단, (2) 형태소로 나누어 형태소를 비교하는 방법, (3)자소 단위로 나누어 단어를 비교하는 방법 등 다양하다.
딥러닝을 기반으로 텍스트의 유사도를 측정하는 방식이라면, 단어, 형태소, 유사도의 종류에 상관 없이 텍스트를 벡터화한 후 벡터화된 각 문장 간의 유사도를 측정하는 방식이다.
유사도 측정 방법에는 자주 쓰이는 4가지 방식이 있다.
📌 1. 자카드 유사도(Jaccard Similarity)
두 문장을 각각 단어의 집합으로 만든 뒤 두 집합을 통해 유사도를 측정하는 방식이다.
🔎두 집합의 교집합(공통된 단어의 개수) / 두 집합의 합집합(전체 단어 개수)
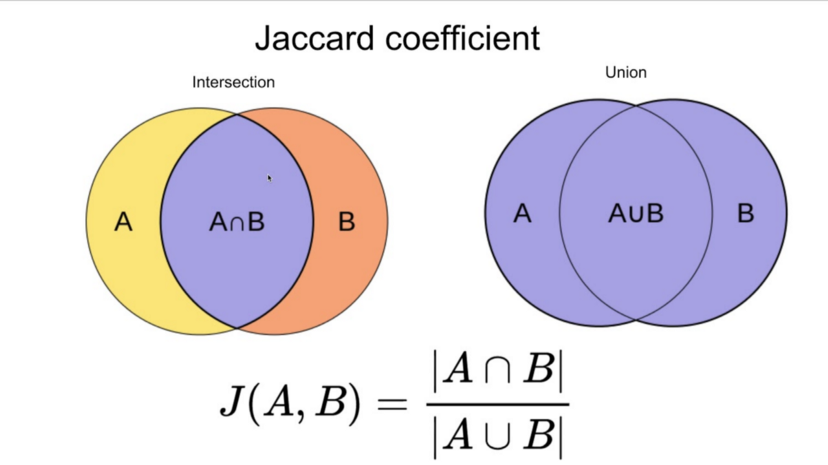
공통된 단어의 개수에 따라 0과 1 사이의 값이 나올 것이고, 1에 가까울수록 유사도가 높다는 의미이다.
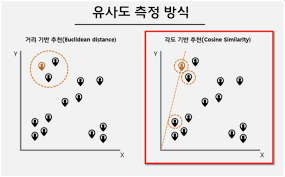
📌 2. 코사인 유사도(Cosine Similarity)
두 개의 벡터값에서 코사인 각도를 구하는 방법이다.
-1과 1 사이의 값을 가지고 1에 가까울수록 유사하다는 것을 의미한다.
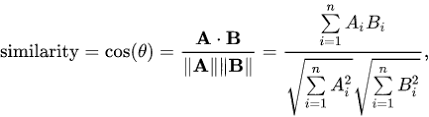
일반적으로 성능이 좋아 가장 널리 쓰이는 방법 중 하나다. 두 벡터 간의 각도를 구하는 방법이기 때문에 '방향성'의 개념이 더해진다는 점이 특징이
다.
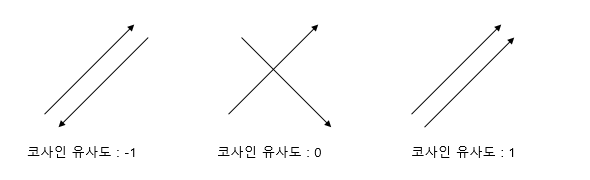
두 문장이 유사하다면 같은 방향으로 가리킬 것, 반대로 유사하지 않을수록 직교로 표현될 것이다.
📌 3. 유클리디언 유사도(Euclidean Similarity)
가장 기본적인 거리를 측정하는 유사도 공식이다.
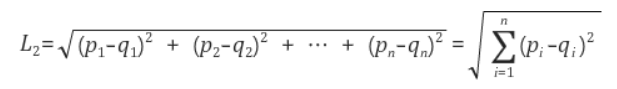
유클리디언 거리(Euclidean Distance) 혹은 L2 거리(L2-Distance)라고 부른다. 두 점 사이의 거리를 구하는 방식이 유클리디언 거리를 뜻한다.
1보다 큰 값이 나올 수 있는데, 이는 단순히 두 점 사이의 거리를 뜻하기 때문에 값에 제한이 없는 것이다.
따라서 값을 제한해야 하는데, 0과 1 사이의 값을 갖도록 만들어주려면 각 문장의 벡터 값을 일반화(Normalization)한 후 다시 측정하면 된다.
L1 정규화 방법(L1-Normalization) : 각 벡터 안의 요소 값을 모두 더한 것의 크기가 1이 되도록 벡터들의 크기를 조절하는 방법 (벡터의 모든 값을 더한 뒤 이 값으로 각 벡터의 값을 나누면 됨)
📌 4. 맨해튼 유사도(Manhattan Similarity)
맨해튼 거리란 사각형 격자로 이뤄진 지도에서 출발점 ~ 도착점까지 🚩가로지르지 않고🚩 갈 수 있는 최단거리를 구하는 공식.
맨해튼 거리를L1 거리(L1 Distance)라고 부른다.
측정 방법에 따라 유사도가 달라질 수 있으므로 적절하게 선택하는 것이 중요하다.
출처: "텐서플로 2와 머신러닝으로 시작하는 자연어 처리" - 전창욱, 최태균, 조중현, 신성진 지음
https://medium.com/h-document/%EC%9E%90%EC%B9%B4%EB%93%9C-%EA%B1%B0%EB%A6%AC-jaccard-distance-e5b246603775
