탐색적 데이터 분석(EDA:Exploratory Data Analysis), 데이터의 여러 패턴이나 잠재적인 문제점을 발견하는 등 데이터 이해를 하는 과정이다.
문제를 해결하기 위해서는 모델과 데이터의 조합, 궁합이 중요하다!!
💡탐색적 데이터 분석 과정
데이터에 대해 최대한 많은 정보를 뽑아내면 된다.
데이터의 평균값, 중앙값, 최솟값, 최댓값, 범위, 분포, 이상치(Outlier) 등이 있다. 이후 히스토그램, 그래프 등 시각화하면서 데이터에 대한 직관을 얻어야 한다.
💡영화 리뷰 데이터로 데이터 분석해보기
🔎 히스토그램으로 문장 구성 단어의 개수와 알파벳 개수 알아보기
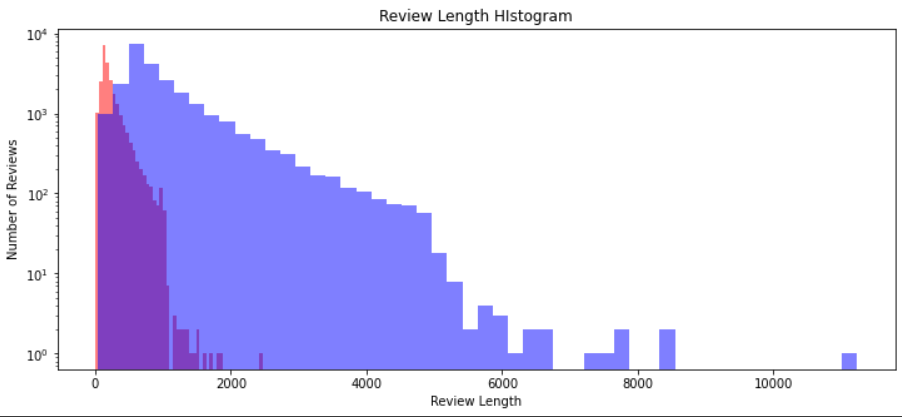
빨간색 히스토그램은 단어 개수에 대한 히스토그램이고,
파란색 히스토그램은 알파벳 개수의 히스토그램이다.
단어 단위와 알파벳의 전체적인 분포를 시각적으로 볼 수 있으며 이상치(Outliers) 값을 확인할 수 있다.
🔎 단어 길이에 대한 통계값 살펴보기
문장 최대 길이: 2470
문장 최소 길이: 10
문장 평균 길이: 233.79
문장 길이 표준편차: 173.73
문장 중간 길이: 174.0
제1사분위 길이: 127.0
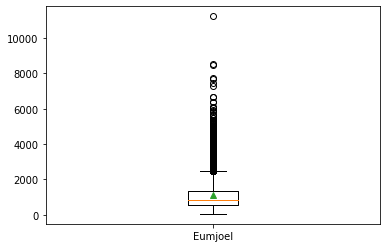
제3사분위 길이: 284.0🚩 박스 플롯으로 데이터 시각화
다양한 값을 한눈에 직관적으로 볼 수 있다는 장점이 있다.
이상치가 심한 데이터를 확인할 수 있다.
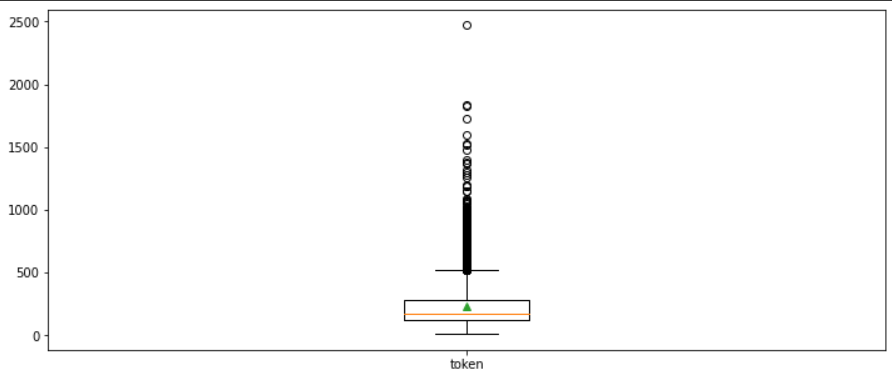
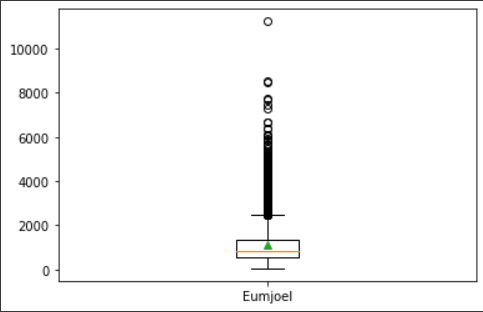
이상치가 심하면 데이터의 범위가 너무 넓어 학습이 효율적으로 이뤄지지 않는다.
🚩 워드클라우드로 데이터 시각화하기
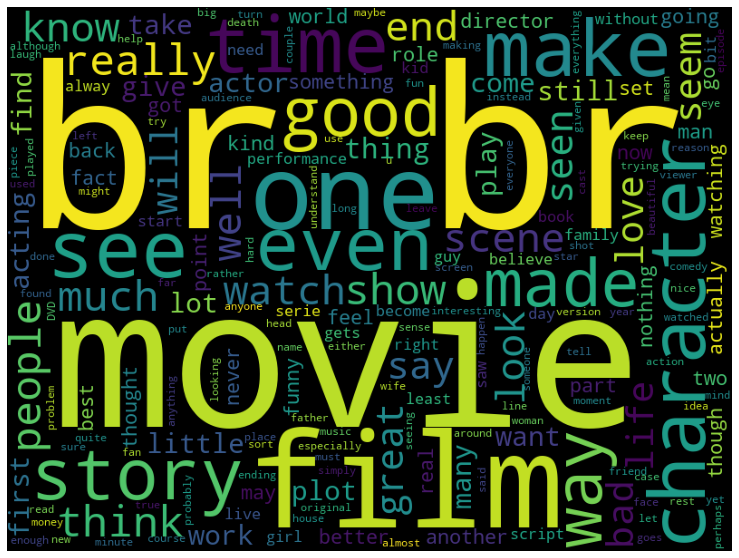
데이터에 포함된 단어의 등장 횟수에 따라 단어의 크기가 커지는데, "br"처럼 학습에 도움되지 않는 데이터는 전처리 단계에서 별도로 처리해줘야 한다.
🚩 긍정/부정 분포 확인하기
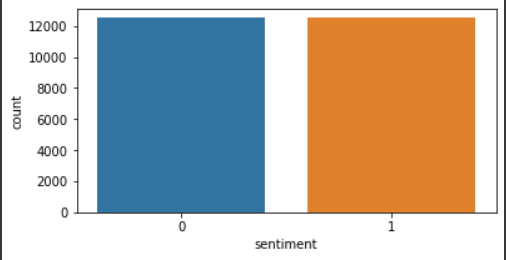
데이터의 균형이 아주 좋음을 볼 수 있다.
그렇다면 균형이 좋지 않는 데이터는 어떻게 처리해야 할까?
출처: "텐서플로 2와 머신러닝으로 시작하는 자연어 처리" - 전창욱, 최태균, 조중현, 신성진 지음

Make your lives Extraordinary!