특성중요도(Feature importance)
-
랜덤포레스트에서는 학습 후에 특성들의 중요도 정보(Gini importance)를 기본으로 제공한다.
-
중요도는 노드들의 지니불순도(Gini impurity)를 가지고 계산하는데 노드가 중요할 수록 불순도가 크게 감소한다는 사실을 이용한다.
-
노드는 한 특성의 값을 기준으로 분리가 되기 때문에 불순도를 크게 감소하는데 많이 사용된 특성이 중요도가 올라갈 것이다.
-
종속변수에 미치는 독립변수의 영향력을 알아보기 위해 feature importance를 확인해보는 방법도 있다.
rf = pipe.named_steps['randomforestclassifier']
importances = pd.Series(rf.feature_importances_, X_train.columns)
%matplotlib inline
import matplotlib.pyplot as plt
n = 20
plt.figure(figsize=(10,n/2))
plt.title(f'Top {n} features')
importances.sort_values()[-n:].plot.barh();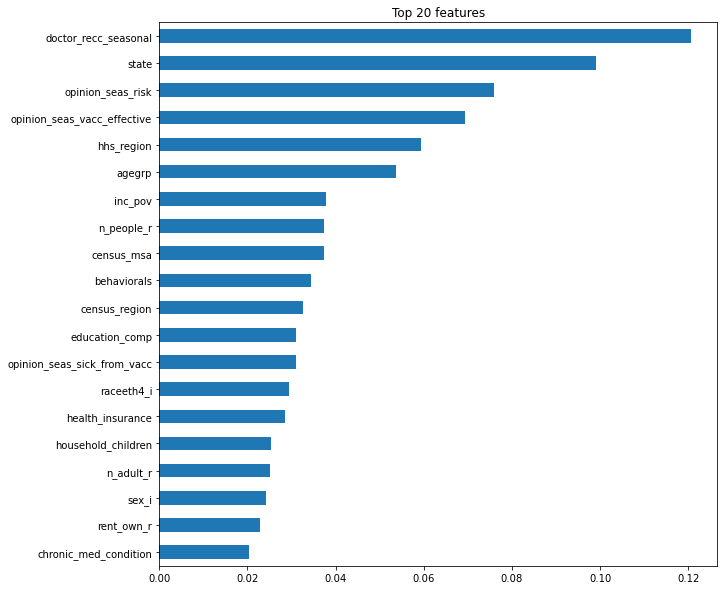
위의 코드와 출력물은 특성중요도 순으로 그래프를 그린것이다.
-
하지만 이러한 특성중요도는 속도는 빠르지만 high-cardinarity가 있는 특성의 경우, 트리 구성중 분기에 이용될 확률이 높기 때문에 과적합의 위험이 있다.
-
위의 그림에서 state가 이에 속하며, state는 50개의 종류를 가지고있다.
순열중요도 (Premutation Importance)
-
중요도 측정은 관심있는 특성에만 무작위로 노이즈를 주고 예측을 하였을 때 성능 평가지표(accuracy, F1 score, R-square등..)가 얼마나 감소하는지를 측정한다.
-
이렇게 노이즈를 주는이유는 특성중요도에서 high-cardinarity의 경우 생기는 문제를 보완할 수 있다. 예를 들어 순열중요도는 검증데이터에서 각 특성의 특성값에 무작위로 노이즈를 주어 기존 정보를 제거하여 특성이 기존에 하던 역할을 하지 못하게 하고 성능을 측정하는 방법이다. 따라서 이 결과에 따른 특성중요도를 확인하는 방법이다.
-
이때 노이즈를 주는 가장 간단한 방법이 그 특성값들을 샘플들 내에서 섞는 것(shuffle, permutation)이다.
# 변경할 특성 선택
feature = ' '
X_val[feature].head()
>>>
11966 Somewhat Low
1211 Very Low
4407 Somewhat Low
1827 Somewhat High
23988 NaN
# 특성의 분포를 확인
X_val[feature].value_counts()
>>>
Somewhat Low 2300
Somewhat High 1875
Very Low 1505
Very High 780
Dont Know 175
Refused 11
# 특성의 값을 무작위로 섞기(노이즈 주기)
X_val_permuted = X_val.copy()
X_val_permuted[feature] = np.random.RandomState(seed=7).permutation(X_val_permuted[feature])
# 바뀐값 확인하기
X_val_permuted[feature].head()
>>>
11966 Somewhat Low
1211 Somewhat High
4407 Somewhat High
1827 NaN
23988 Very Low
# 값은 변경 되었지만 카테고리들의 분포는 변경되지 않음.
X_val_permuted[feature].value_counts()
>>>
Somewhat Low 2300
Somewhat High 1875
Very Low 1505
Very High 780
Dont Know 175
Refused 11
# 순열중요도 값 확인하기
score_permuted = pipe.score(X_val_permuted, y_val)
print(f'검증 정확도 ({feature}): {score_with}')
print(f'검증 정확도 (permuted "{feature}"): {score_permuted}')
print(f'순열 중요도: {score_with - score_permuted}')
>>>
검증 정확도 (opinion_seas_risk): 0.7526983750444787
검증 정확도 (permuted "opinion_seas_risk"): 0.7205550942948642
순열 중요도: 0.03214328074961448- 이렇게 위와 같이 확인해 볼 수 있지만 라이브러리를 통해 편하게 확인해 보자
from sklearn.pipeline import Pipeline
#encoder, imputer를 preprocessing으로 묶었다. 이후 eli5 permutation계산에 사용한다.
pipe = Pipe([
('preprocessing', make_pipeline(OrdinalEncoder(), SimpleImputer())),
('rf', RandomForestClassifier(n_estimators=100, random_state=2, n_jobs=-1))
])
# pipeline 생성을 확인
pipe.named_steps
>>> {'preprocessing': Pipeline(steps=[('ordinalencoder', OrdinalEncoder()),
('simpleimputer', SimpleImputer())]),
'rf': RandomForestClassifier(n_jobs=-1, random_state=2)}
# 정확도 확인
pipe.fit(X_train, y_train)
print(pipe.score(X_val, y_val))
>>> 0.7526983750444787# eil5적용해보기
import eli5
from eli5.sklearn import PermutationImportance
# permuter 정의
permuter = PermutationImportance(
pipe.named_steps['rf'], # model
scoring='accuracy', # metric
n_iter=5, # 다른 random seed를 사용하여 5번 반복
random_state=2
)
# permuter 계산은 preprocessing 된 X_val을 사용합니다.
X_val_transformed = pipe.named_steps['preprocessing'].transform(X_val)
# 실제로 fit 의미보다는 스코어를 다시 계산하는 작업입니다
permuter.fit(X_val_transformed, y_val);
# 순열중요도 확인
feature_names = X_val.columns.tolist()
pd.Series(permuter.feature_importances_, feature_names).sort_values()
>>>
n_adult_r -0.003511
hhs_region -0.003108
census_region -0.003084
behavioral_face_mask -0.003060
sex_i -0.002942
state -0.002918
behavioral_wash_hands -0.002657
n_people_r -0.002562
health_worker 0.003060
opinion_seas_sick_from_vacc 0.004792
agegrp 0.007733
opinion_seas_risk 0.041039
opinion_seas_vacc_effective 0.043814
doctor_recc_seasonal 0.071427# 특성별 score확인
eli5.show_weights(
permuter,
top=None, # top n 지정 가능, None 일 경우 모든 특성
feature_names=feature_names # list 형식으로 넣어야 합니다
)
>>>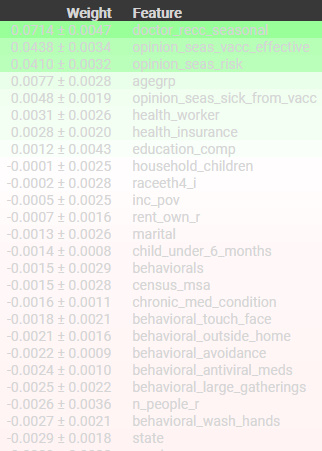
위의 과정으로 이렇게 순열중요도를 시각적으로도 확인할 수 있다.
그렇다면 이 방법을 이용하여 특성을 선택하려면 어떻게해야할까??
답은 정해져 있지 않다. 데이터마다 분석가마다 다르기때문에 하지만, 예시를 위해 음수 즉, 중요하지 않은 데이터를 지워볼 수 있다.
minimum_importance = 0.001
mask = permuter.feature_importances_ > minimum_importance
features = X_train.columns[mask]
X_train_selected = X_train[features]
X_val_selected = X_val[features]- 양수를 기준으로 잡은 이유는 먼저 순열중요도는 feature를 넣었을때 정확도에서 뺏을때 정확도를 뺀 값이다.
- 만약에 해당 feature가 중요한 특성일 경우 감소가 생기게 된다 따라서 양수값이 나오게 되지만,
- 반대로 해당 feature를 뺏을때 더 높게 나온다면 이전 정확도에서 빼면 음수가 나오기 때문이다.
