이번엔 한국의 코로나 발발 케이스에 대해서 분석해보려고 한다.
한국 코로나 현황
df_plot = df.groupby(['Date','Country_Region','Province_State'], as_index=False)['ConfirmedCases', 'Fatalities'].sum()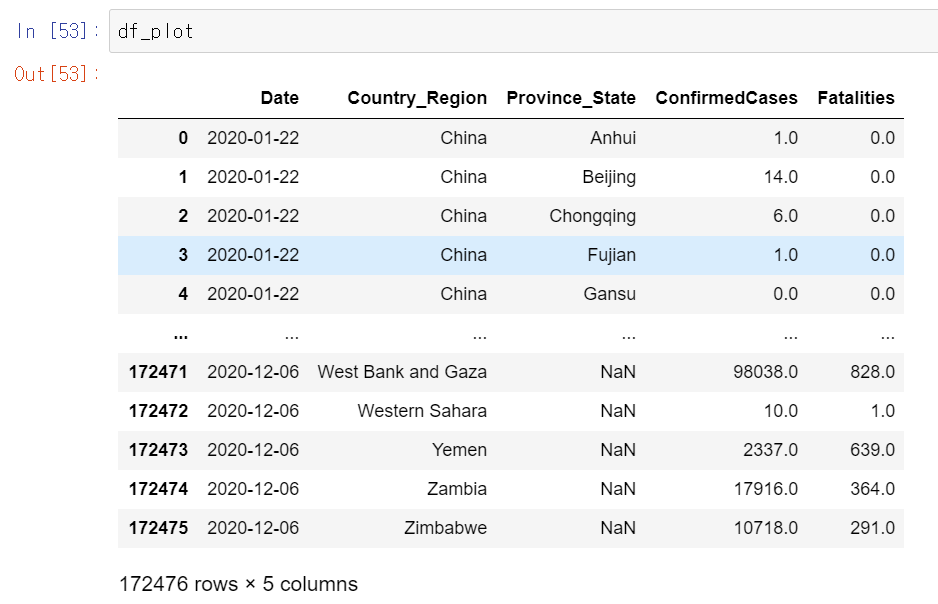
def add_daily_measures_country(df, country):
df = df[df.Country_Region==country]
df = df.groupby('Date', as_index=False)['ConfirmedCases','Fatalities'].sum()
df['Daily Cases'] = df['ConfirmedCases'] - df['ConfirmedCases'].shift(1)
df['Daily Deaths'] = df['Fatalities'] - df['Fatalities'].shift(1)
return df특정 나라에 대해서 데이터를 전처리하는 함수를 만든다.
df_sk = add_daily_measures_country(df_plot, 'South Korea')
fig = go.Figure(data=[
go.Bar(name='Cases', x=df_sk['Date'], y=df_sk['Daily Cases']),
go.Bar(name='Deaths', x=df_sk['Date'], y=df_sk['Daily Deaths'])
])
fig.update_layout(barmode='overlay', title='Daily Case and Death cout(South Korea)')
fig.update_layout(hovermode='closest', template='seaborn', width=700,
xaxis=dict(mirror=True, linewidth=2, linecolor='black', showgrid=False),
yaxis=dict(mirror=True, linewidth=2, linecolor='black')).png)
가장 기본적인 데이터 시각화를 해보았다. Date별 한국의 코로나 확진자 및 사망자를 알 수 있다.
df_sk_cases = pd.read_csv('C:/Users/gasak/OneDrive/바탕 화면/big data/covid19 data/case.csv')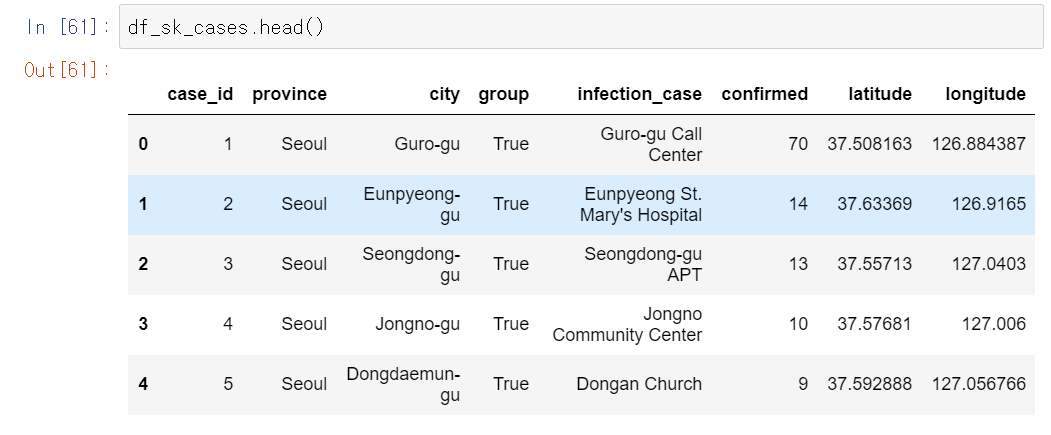
이번엔 한국의 코로나 데이터를 가져와서 분석해보려고 한다.
이 데이터로 한국의 코로나 확진 케이스에 대해서 알 수 있다.
df_hotspots = df_sk_cases[(df_sk_cases['group']==True)&(df_sk_cases['city']!='from other city')]
df_hotspots['latitude'] = df_hotspots.apply(lambda x: float(x['latitude'] if x['latitude']!='-' else float('nan'))
, axis=1)
df_hotspots['longitude'] = df_hotspots.apply(lambda x: float(x['longitude'] if x['longitude']!='-' else float('nan'))
, axis=1)
df_hotspots한국에서의 코로나 핫스팟 지점을 파악하기 위해 정제했다. df_sk_cases 데이터를 확인해보면 위도, 경도가 -로 결측치가 표현된 것이 있어 이에 대한 것도 전처리하였다.
이 데이터를 가지고 한국 지도에 시각화를 하기 위해 mapbox을 사용해보려고 한다.
mapbox_token = "set_mapbox_access_token"
px.set_mapbox_access_token("pk.eyJ1IjoibHNtbWF5MzIyIiwiYSI6ImNraXZkNDd1ajAyc3EycW15b2dsYm81amMifQ.8taLXuw2os0D0VHiXt-lbQ")
fig = px.scatter_mapbox(df_hotspots,
lat="latitude",
lon="longitude",
size="confirmed",
hover_data=['infection_case','city','province'],
mapbox_style='streets',
zoom=5,
size_max=50,
title= 'COVID19 Hotspots in South Korea')
fig.show().png)
mapbox는 Mapbox라는 온라인 지도를 제작하는 회사에서 베포하는 지도이다. 이 mapbox 지도는 geo map보다 더 디테일이 세세하다. plotly에서 이 mapbox를 지원한다.
mapbox는 위도, 경도 데이터를 받고 지도 위에 표현할 수 있다.
df_sk = pd.read_csv("C:/Users/gasak/OneDrive/바탕 화면/big data/covid19 data/korea_covid/PatientInfo.csv")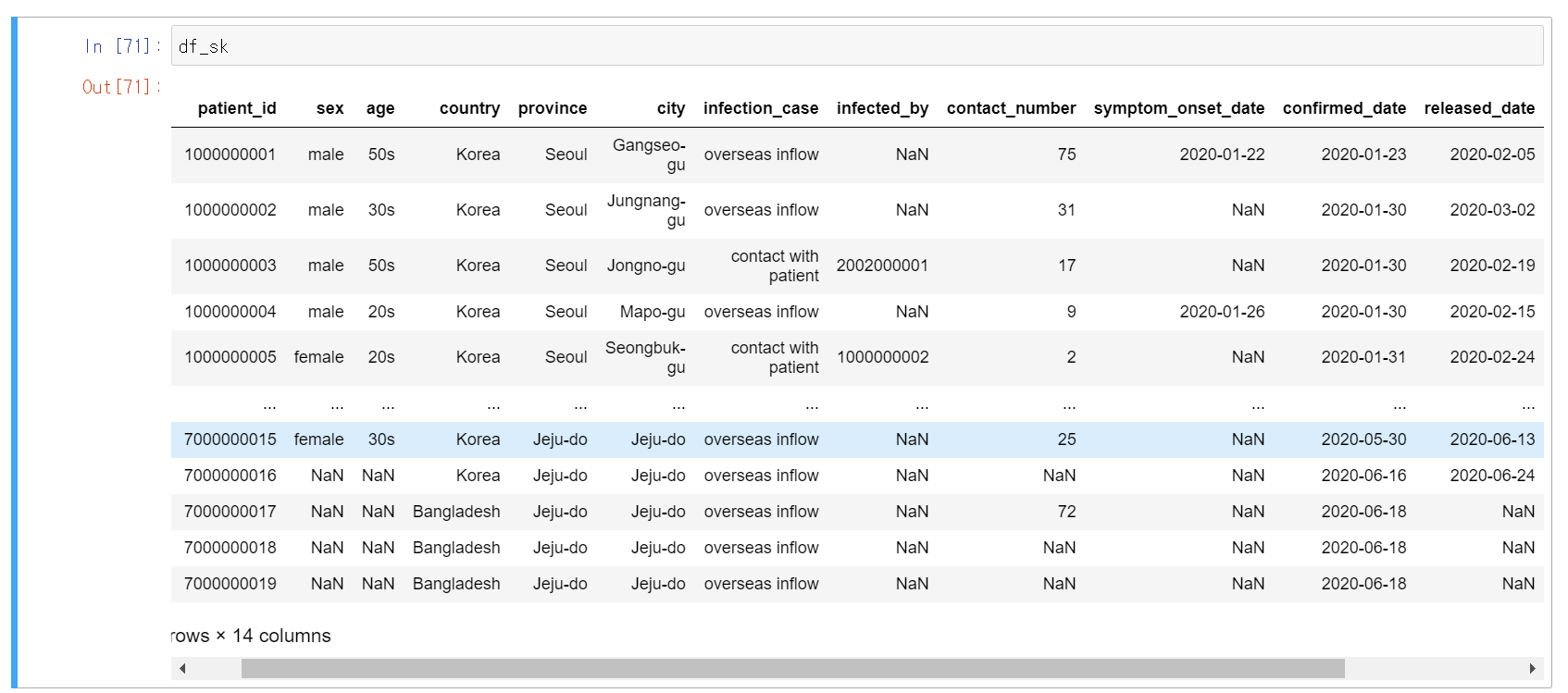
이번 분석에서 쓰일 데이터를 보면 한국에서 도시별, 성별, 나이별, 발생케이스를 알 수 있다. 이러한 데이터를 이용하여 한국에서의 발생 케이스가 어떤 형태를 띄는지 보려고 한다.
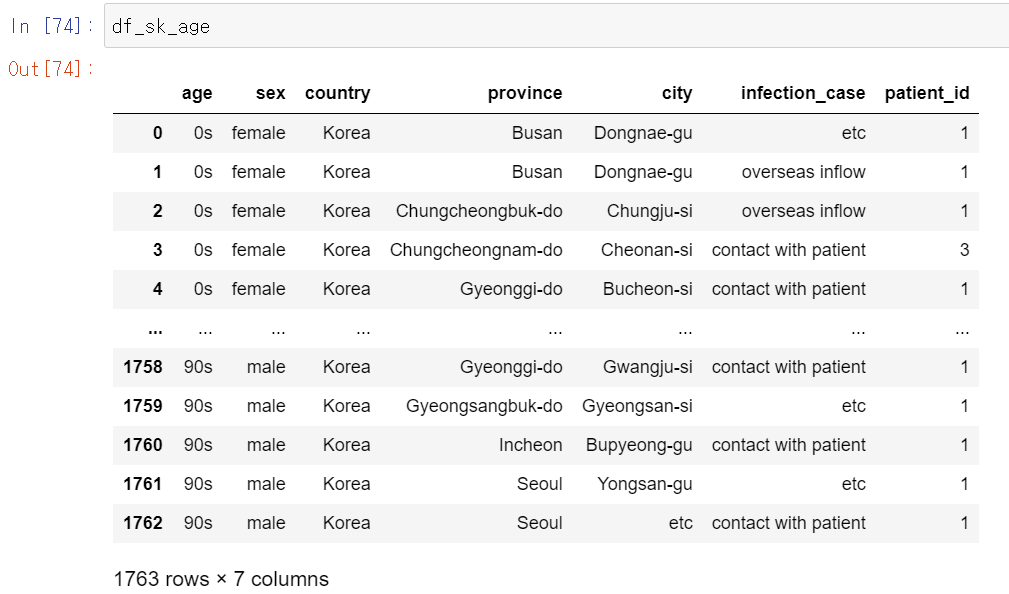
df_sk_age = df_sk.groupby(['age','sex','country','province','city','infection_case'], as_index = False)['patient_id'].count()우선 분석 데이터를 6주제별로 묶어서 환자의 수를 보려고 한다.
시각화를 하기에 앞서 4가지 주제로 표현을 하려고 한다.
1. 성별과 나이대별 환자 수
2. 지역별 환자 수
3. 감염 케이스별 환자 수
4. 성별과 감염자 상태별 환자수(사망, 고립 등등)
시각화
https://plotly.com/python-api-reference/generated/plotly.subplots.make_subplots.html
참고
위 네가지 주제로 시각화 하기에 앞서 subplot을 제작하려고 한다.
fig = make_subplots(rows=2, cols=2,
subplot_titles=("Age-wise distribution of Cases", "Province-wise distribution of Cases"\
, "Infection Origin", "Gender-wise distribution of Patient Statuses"),
specs=[[{"type": "bar"}, {"type": "pie"}],
[{"type" : "pie"}, {"type" : "bar"}]]
)rows = 2, cols = 2 인 2x2 행렬의 일종의 팜플렛(?)을 만든다.
각 시각화의 title은 행 우선 순서대로
1. Age-wise distribution of Cases
2. Province-wise distribution of Cases
3. Infection Origin
4. Gender-wise distribution of Patient Statuses
이고 각 시각화의 종류는 bar와 pie 형태를 이룬다.
1. 성별과 나이대별
df_males = df_sk_age[df_sk_age['sex'] == 'male'].groupby('age', as_index = False)['patient_id'].sum()
df_females = df_sk_age[df_sk_age['sex'] == 'female'].groupby('age', as_index = False)['patient_id'].sum()df_sk_age에서 성별에 따른 나이대별 환자수를 종합하였다.
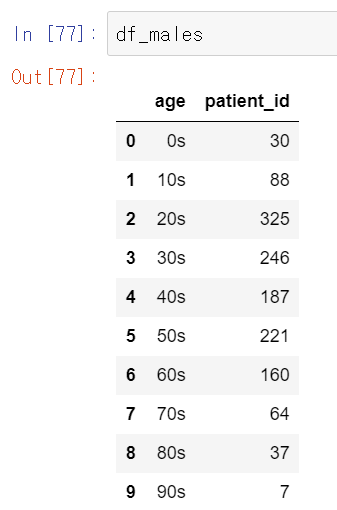
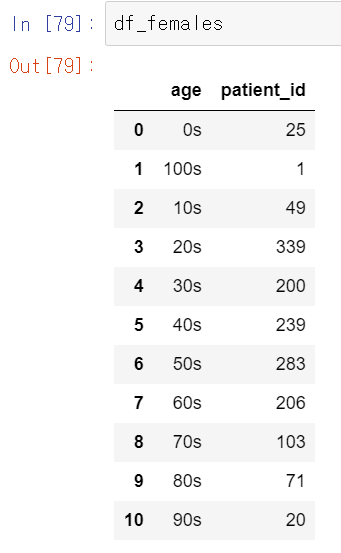
그리고 x축은 나이대, 색깔은 성별로 구분하여 Bar 그래프로 표현하고자 했다. 남녀에 따른 그래프르르 subplots에서 (1,1)에 삽입한다.
fig.add_trace(go.Bar(name='Males', x = df_males['age'], y = df_males['patient_id']), row = 1, col = 1)
fig.add_trace(go.Bar(name='Females', x=df_females['age'], y=df_females['patient_id']), row=1, col=1).png)
2. 지역별
df_province = df_sk_age.groupby('province',as_index=False)['patient_id'].sum()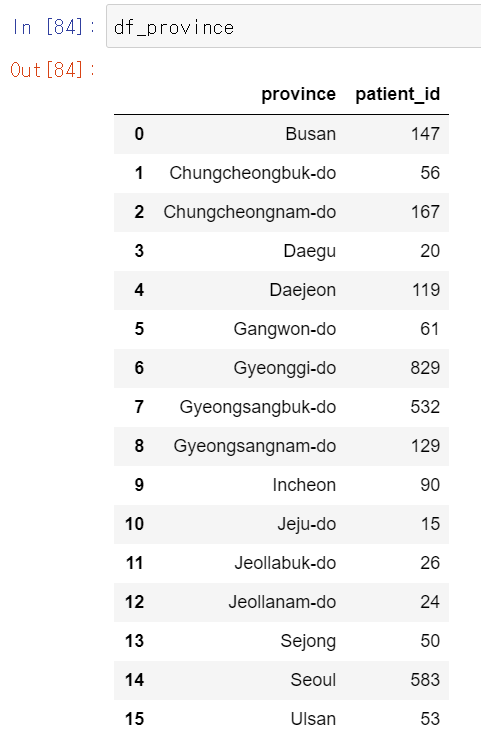
지역별 총 환자수를 알기위해 province로 그룹별로 묶으면서 patient_id의 합을 구한다.
이번엔 Bar 그래프가 아닌 Pie그래프로 표현해보았다.
fig.add_trace(go.Pie(labels=df_province['province'], values=df_province['patient_id'], hole=0.3), row=1, col=2).png)
아직은 layout에 대한 설정을 하지 않아서 제목과 그래프가 겹치지만 나중에 이를 수정한다.
3. 감염 케이스별
df_inf_case = df_sk_age.groupby('infection_case', as_index = False)['patient_id'].sum()이번엔 감염 케이스별로 묶기 위해 infection_case별로 환자수의 총합을 구했다.
감염 케이스의 종류를 보면

엄청 다양한 케이스가 존재하는 것을 알 수 있다. 이 모든것을 다 한 그래프에 넣기는 힘들어서 환자수가 50 미만인 케이스는 기타로 묶었다.
df_inf_case.loc[df_inf_case['patient_id'] < 50, 'infection_case'] = 'etc'그리고 감염 케이스도 Pie 그래프로 구현하였다.
fig.add_trace(go.Pie(labels=df_inf_case['infection_case'], values=df_inf_case.patient_id, hole=0.3), row=2, col=1).png)
4. 성별과 감염자 상태별
우선 성별에 따른 state의 감염자 총합을 구한다.
df_males = df_sk[df_sk['sex']=='male'].groupby('state', as_index = False)['patient_id'].sum()
df_males
df_females = df_sk[df_sk['sex']=='female'].groupby('state', as_index=False)['patient_id'].sum()
df_females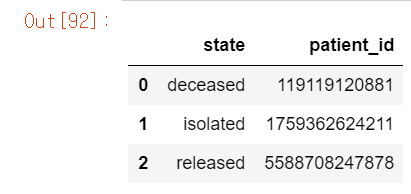
그리고 나서 첫번째 케이스처럼 남녀에 따른 시각화를 한 그래프에 넣기 위해 Bar 그래프를 사용한다.
fig.add_trace(go.Bar(name="Males", x=df_males['state'], y=df_males['patient_id']), row=2, col=2)
fig.add_trace(go.Bar(name="Females", x=df_females['state'], y=df_females['patient_id']), row=2, col=2).png)
시각화 정리
마지막으로 Bar 그래프의 x축, y축의 제목을 정해주고 layout의 정리를 한다.
# x축, y축 제목 추가
fig.update_xaxes(title_text="Age", row=1, col=1)
fig.update_xaxes(title_text="Status", row=2, col=2)
fig.update_yaxes(title_text='Confirmed Cases', row=1, col=1)
fig.update_yaxes(title_text='Total number of People', row=2, col=2)
# layout의 제목과 크기 수정
fig.update_layout(title_text='South Korea: Some more visualizations', height = 700, width = 800, showlegend=False).png)
결론
일단 각 주제별로 어떤 유형이 나타나는지 보려고 한다.
1. 성별과 나이대별
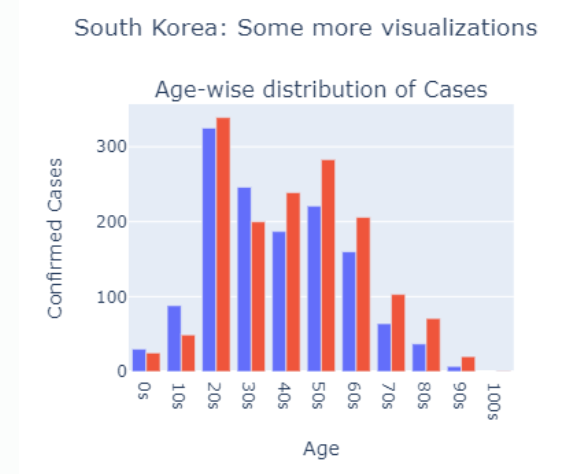
가장 높게 나타나는 부분은 20대 그 다음은 50대이다. 일단 각 연령별 인구수의 비율도 따져야 하지만 일단 이 데이터만 보고 왜 20대부터 50~60대 까지의 인구의 확진자 수가 높은지 생각해보았다.
일단은 0대와 70대 이상부터는 영유아와 노인분들이 포함된 연령대이다. 이 구간은 내가 생각했을 때 집밖으로 외출을 자주 하지 않는 연령대라고 생각했다. 그에 반해 젊은축에 속하는 20대부터 40대까지는 외출을 자주해서 그렇지 않을까?라고 생각한다. 근래에 뉴스만 봐도 스키장에 놀러가거나 카페 등 공공시설을 자주 이용하는 연령대는 이 구간에 속한다. 따라서 확진자와 동선이 겹치기가 쉽기 때문에 확진자가 많을 수 밖에 없다. 의외인건 10대의 확진자가 낮다는 것이다. 50대와 60대는 어째서 높을까? 70대 이상의 연령대보다는 외출을 하게 되거나(출근 ...) 젊은세대보다 상대적으로 면연력이 약하기 때문에 확진자가 많이 나온다고 생각했다.
2. 지역별
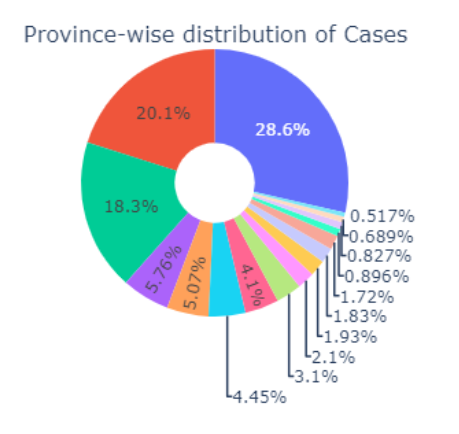
지역별 가장 확진자 수가 많은 곳은 1. 경기도, 2. 서울, 3. 경상북도이다.
일단 경상북도는 신천지 사건으로 확진자가 많이 나타난 곳이고, 수도권은 지방보다 인구밀도가 높다. 따라서 인구대비 확진자와 겹치기가 쉽기 때문에 급격히 환자가 늘어난거 같다.
