이번 데이터는 영토대비 인구수와 총 인구수를 가지고 데이터 Feature Engineering을 해보려고 한다.
Feature Engineering이란?
데이터에 대한 도메인 지식을 가지고 특징을 만들어내는 것이다. 특히 머신러닝을 사용할 때 이것을 이용한다. 데이터 컬럼을 생성하거나 선택해서 머신러닝의 성능을 높일 수 있기 때문이다.
데이터
df_pd = pd.read_csv('C:/Users/gasak/OneDrive/바탕 화면/big data/covid19 data/feature_engineer/Pupulation density by countries.csv')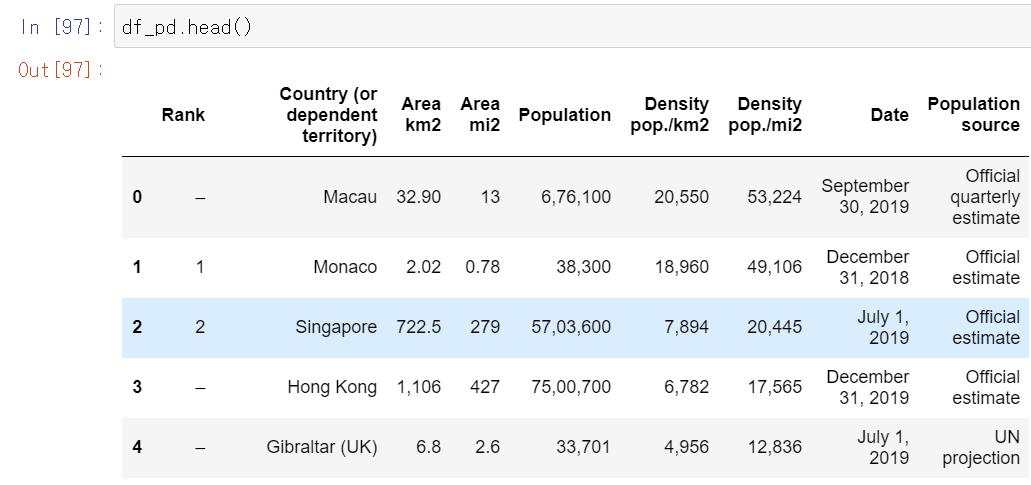
여기서 Country (or dependent territory) 컬럼을 보면

전에 사용하던 데이터의 Country_Region처럼 다양한 나라의 모고록을 나열한다. 그래서 전에 만들었던 fetch_iso3함수를 이용하여 iso3 코드를 생성한다.
df_pd['iso_code3'] = df_pd.apply(lambda x: obj.fetch_iso3(x['Country (or dependent territory)'].strip()), axis=1)df_train 데이터를 가지고 가장 마지막 날의 데이터를 따로 추출한다. 그리고 나서 df_train을 기준으로 df_pd와 병합한다.
df = df_train[df_train['Date']==train_date_max]
df = df.groupby(['Date', 'Country_Region'], as_index=False)['ConfirmedCases', 'Fatalities'].sum()
df['iso_code3'] = df.apply(lambda x: obj.fetch_iso3(x['Country_Region']), axis=1)
df = df.merge(df_pd, how='left', on='iso_code3')병합한 데이터를 활용하여 나라의 인구수 대비 코로나 확진자 및 사망자 수를 알 수 있다.
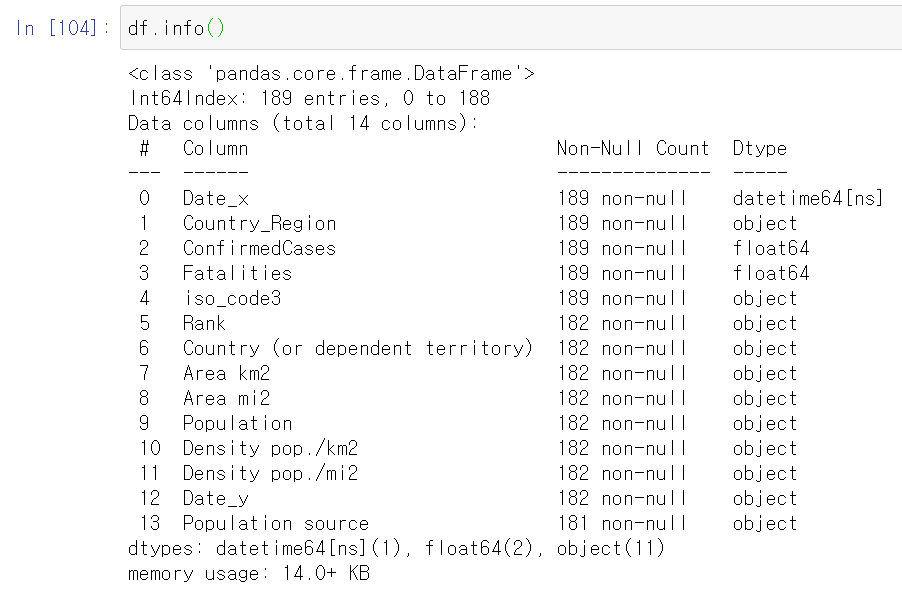
여기서 바로 데이터를 활용하기에는 적합하지가 않다. 그 이유는 Population과 Density pop./km2 열을 보면 데이터 타입이 object로 되어 있는 것을 볼 수 있다. 실제 데이터를 확인해보면 3,90,757처럼 숫자 사이에 ,가 포함되어 있다. Population과 Density pop./km2는 숫자로 활용되어야 하는 데이터부분이다. 이를 전처리해준다.
def convert(pop):
if pop == float('nan'):
return 0.0
return float(pop.replace(',', ''))
df['Population'].fillna('0', inplace=True)
df['Population'] = df.apply(lambda x: convert(x['Population']), axis=1)
df['Density pop./km2'].fillna('0', inplace=True)
df['Density pop./km2'] = df.apply(lambda x: convert(x['Density pop./km2']), axis=1)이 코드를 짜신분의 의도는 모르겠으나 내 추축하기로는 데이터 이상값을 처리할 때 ESD, 기하평균 등을 이용하는 법이 있지만, 그중에서도 box plot을 이용한 이상값 처리가 있다. 이는 사분위수를 이용하는것인데,
Q1 - 1.5(Q3 - Q1)과 Q3 + 1.5(Q3 - Q1)을 벗어나는 데이터를 이상값으로 치부한다.
따라서 여기서도 Q1, Q3를 구하고 위 사분위수 이상값을 구하여 그 안에 존재하는 데이터만 가지고 처리한다. ConfirmedCases데이터는 Fatalities데이터보다 분산이 크기 때문이다.

여기서만 봐도 ConfirmedCases의 사분위수 데이터와 max 데이터를 비교해보면 max 데이터가 훨씬 더 큰 값임을 알 수 있다.
IQR = q3 - q1
low = q1 - 1.5*IQR
high = q3 + 1.5*IQR
df = df[(df['ConfirmedCases']>low) & (df['ConfirmedCases'] < high)]
df['conitnent'] = df.apply(lambda x: obj.fetch_continent(x['Country_Region']), axis=1)그리고 이러한 데이터를 이용하여 scatter 그래프를 도식화한다.
시각화
df['Date_x'] = df['Date_x'].astype(str)
px.scatter(df, x='ConfirmedCases', y='Density pop./km2', size='Population',
color='conitnent', hover_data=['Country_Region'], title='Variation of Population density wrt Confirmed Cases', range_y=[0,1500])
px.scatter(df, x='Fatalities', y='Density pop./km2', hover_data=['Country_Region'], size='Population', color='conitnent', title='Variation of Population density wrt Fatalities', range_y=[0,1500]).png)
.png)
마지막으로 df데이터에 대해서 상관관계를 분석해보자
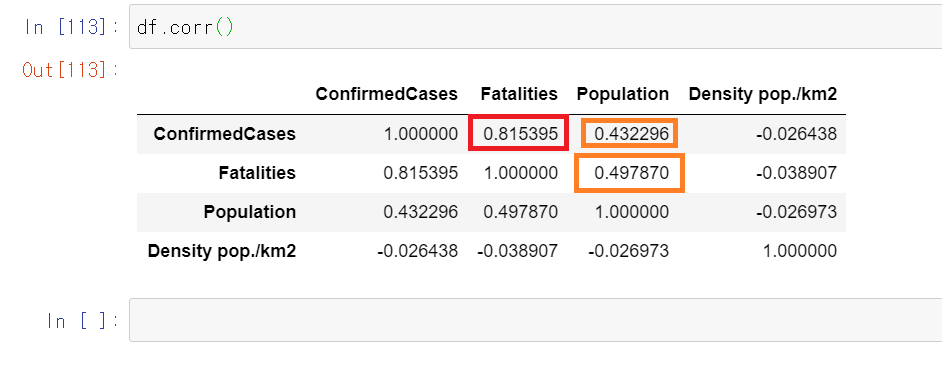
당연히 생각해보면 ConfirmedCases와 Fatalities는 강한 양의 상관관계를 갖는다. 이는 당연한 상식이니 제외한다 치고 의외인 부분은 ConfirmedCases와 Fatalities와 Density pop./km2의 관계가 거의 아무 관계가 없다는 것이다. 개인적으로 생각했을 때 인구밀도가 높으면 확진자와 동선이 겹쳐지는 인구가 상대적으로 높기 때무에 상관이 높다라고 생각했었다. 이는 인과관계이긴 하지만 상관관계도 어느정도 높을것이라고 생각했다. 대신에 Population과는 강하진 않지만 약한 양의 상관관계를 갖는 것을 알 수 있다.
