
🤗 소개
이 글은 Szegedy et al.(2014)의 Going Deeper with Convolutions 을 원 논문의 전개(문제 제기 → 관련 연구 → 동기/설계 원칙 → Inception 모듈 설계 → GoogLeNet 구체화 → 학습 방법론 → ILSVRC 분류/검출 결과 → 결론)를 가능한 한 그대로 따라가며 촘촘히 풀어쓴 상세 리뷰다.
이 논문에서 제안하는 아키텍처는 Inception이고, ILSVRC14 제출에 사용한 22-layer 구체 인스턴스가 GoogLeNet이다. 즉 GoogLeNet은 Inception 아키텍처의 한 구현(incarnation) 이다. 논문이 강조하는 핵심은 단지 더 깊게 만들었다가 아니라, 동일하거나 제한된 연산 예산(computational budget) 안에서 depth/width를 늘릴 수 있도록, 네트워크 내부의 계산 자원을 더 효율적으로 쓰는 구조를 만들었다는 점이다.
논문 초반에서 이미 정량적 메시지를 던진다.
- GoogLeNet은 AlexNet(2012) 대비 파라미터가 12× 적다고 주장하면서도 성능은 더 좋다.
- 실험 설계에서 inference-time 연산 예산을 대부분 1.5 billion multiply-adds로 제한했다고 말한다.
- 이 효율성은 희소(sparse) 구조가 이상적이지만 당시 하드웨어/라이브러리 환경에서 희소 연산은 비효율적이므로, 희소 구조를 조밀한(dense) 블록 조합으로 근사하는 방향을 택했다는 논리로 연결된다.
또한 이 논문은 분류(classification)뿐 아니라 검출(detection)에서도 ILSVRC14에서 강력한 성능을 냈다고 보고한다. 특히 검출에서는 R-CNN류 파이프라인과 결합한 딥러닝과 고전 CV의 시너지가 성능 향상의 핵심이었다고 정리한다.
1️⃣ 배경 상황
🔹 최근 3년의 급격한 진전과 아이디어/아키텍처의 중요성
논문은 지난 몇 년간(2012~2014) 이미지 인식/검출 성능이 급격히 향상된 배경을 짚는다. 중요한 주장 하나는 이 진전이 단지 더 좋은 하드웨어/더 큰 데이터/더 큰 모델 때문만은 아니라는 점이다. ILSVRC14에서 상위권 팀들 역시 detection을 위해 새로운 외부 데이터 소스를 추가로 쓰지 않았고, 주된 개선은 아이디어, 알고리즘, 네트워크 아키텍처의 발전에서 나왔다고 말한다.
이 문맥에서 GoogLeNet은 두 가지 축을 동시에 잡는다.
- 정확도(accuracy): 분류/검출에서 SOTA 달성
- 효율성(efficiency): 파라미터 수와 연산량을 억제해 현실적인 비용으로 inference 가능
특히 모바일/임베디드 환경에서 메모리/전력 제약이 중요해지고 있으므로, 알고리즘 효율이 점점 더 중요한 설계 목표가 된다고 강조한다.
🔸 논문이 설정한 목표: 고정된 자원에서 더 깊고/넓게
논문은 대부분의 실험에서 inference 시 1.5 billion multiply-adds 수준의 연산 예산을 유지하려고 했다고 명시한다. 여기서 multiply-add는 흔히 MAC(Multiply–Accumulate)처럼 생각하면 되고, conv 연산에서 대략
크기의 곱셈-덧셈이 발생한다는 점을 떠올리면 된다.
즉 이 논문이 하고자 하는 건 단순히 모델을 키우자가 아니라,
- depth(층 수)와 width(채널 수/유닛 수)를 늘리고 싶지만,
- 그에 따라 연산량과 파라미터가 폭발하지 않도록,
- 네트워크 내부에서 계산이 낭비되는 병목(bottleneck) 을 제거하는 구조를 설계하자는 것이다.
이 문제 설정이 이후의 희소 구조 → 조밀 블록 근사 → Inception 모듈로 자연스럽게 이어진다.
2️⃣ 관련 연구
🔹 고전적 CNN의 표준 구조
논문은 LeNet-5 이후 CNN이 보통 따르는 구조를 먼저 요약한다.
- (여러) convolution layer 스택 (옵션: contrast normalization, max-pooling)
- 그 뒤에 fully-connected layer들
그리고 대규모 데이터셋(ImageNet)에서는 최근 트렌드가
- 더 많은 레이어(깊이 증가)
- 더 큰 레이어(폭 증가)
- dropout으로 과적합 억제
로 요약된다고 말한다.
또한 max-pooling이 공간 정보를 잃는다는 우려가 있음에도, 동일한 CNN 구조가 localization/detection/pose 추정 등으로 확장되어 성공적으로 쓰였다는 점을 들며, CNN 표현이 다양한 과제에 강력하다는 배경을 깔아준다.
🔸 Network-in-Network와 이 논문이 가져온 핵심 조각들
이 섹션에서 논문이 직접 연결하는 실마리들은 다음이다.
-
Network-in-Network (Lin et al.)
1×1 conv를 추가해 representational power를 늘리는 접근이다. 논문은 여기서 한 발 더 나아가, 1×1 conv를 표현력 증가뿐 아니라 차원 축소(dimension reduction) 로써 계산 병목 제거 목적에 매우 적극적으로 사용한다고 밝힌다. 즉 이 논문에서 1×1 conv는 중요한 모듈이다. -
멀티스케일 처리(Serre et al.)
고정 Gabor 필터를 여러 크기로 두는 방식과 유사하게, Inception은 여러 스케일의 conv를 병렬로 두어 멀티스케일을 다루지만, Inception에서는 필터가 학습되고, 모듈이 반복되어 22-layer 수준의 깊은 모델이 된다는 점이 차별점이다.
이 섹션의 결론은 기존 아이디어(1×1 conv, 멀티스케일, 검출 파이프라인)를 가져오되, 계산 효율 관점에서 재조합해 더 깊고 넓은 네트워크를 만들겠다는 방향으로 정리할 수 있다.
3️⃣ 상위 레벨 고려사항들
🔹 단순한 확장(더 깊게/더 넓게)의 두 가지 문제
논문은 성능을 올리는 가장 직관적인 방법으로 네트워크를 키우는 것을 먼저 말한다.
- depth 증가: 더 많은 레벨(층)
- width 증가: 각 레벨의 유닛/필터 수
하지만 이 단순 해법에는 두 가지 큰 단점이 있다고 한다.
- 파라미터 증가 → 과적합 위험 증가
데이터가 무한정 많지 않다면, 큰 모델은 더 쉽게 과적합될 수 있다. 특히 ImageNet처럼 fine-grained 분류에서는 정교한 라벨링이 필요하므로 고품질 데이터셋 제작 비용 자체가 병목이 될 수 있다고 말한다. 이를 보여주기 위해 서로 시각적으로 가까운 두 클래스를 예로 든다.

- 연산량 증가
예를 들어 conv 레이어 두 개가 연속될 때, 두 레이어의 필터 수를 동일 비율로 늘리면 (채널 곱으로 인해) 연산량이 대략 제곱 형태로 증가한다. 게다가 많은 가중치가 0에 가깝게 낭비된다면, 제한된 예산에서 계산을 비효율적으로 쓰는 셈이 된다.
즉 논문이 말하는 더 크게의 문제는 단순히 느리다/메모리 크다를 넘어, 제한된 예산을 성능 향상에 가장 잘 쓰는 구조가 무엇인가라는 자원 배분 문제로 넘어간다.
🔸 Sparse 구조의 이상과, Dense 블록으로의 현실적 근사
논문은 이상적으로는 fully-connected 대신 희소(sparse) 연결을 네트워크 내부에도 더 적극적으로 도입하는 것이 두 문제(과적합, 연산 낭비)를 동시에 해결할 근본 해법이라고 본다.
여기서 Arora et al.를 핵심 이론적 근거로 끌어온다. 논문이 요약하는 메시지는 대략 다음이다.
- 데이터 분포가 큰데 희소한 deep net으로 표현될 수 있다면,
- 각 레이어의 activation 간 상관(correlation) 통계를 보고,
- 높은 상관을 갖는 뉴런들을 클러스터링하면,
- 다음 레이어의 토폴로지를 layer-by-layer로 구성할 수 있다.
이 이야기는 Hebbian 원리 (같이 발화하는 뉴런은 같이 연결된다)와도 직관적으로 맞닿아 있다고 말한다.
하지만 문제는 당시 하드웨어/소프트웨어 인프라가 비균일 희소 데이터 구조에서의 수치 연산에 매우 비효율적이라는 점이다. 희소 연산의 산술량이 100× 줄어도, 메모리 접근/캐시 미스/인덱싱 오버헤드가 지배적이라 실제 속도가 잘 안 나올 수 있다는 것이다.
그래서 이 논문은 희소 구조를 직접 쓰는 대신, 희소 구조가 요구할 법한 최적 로컬 토폴로지를 조밀한(dense) 구성요소로 덮어서(cover) 근사하자는 현실적 전략을 선택한다. 그 조밀한 구성요소가 바로 다음 섹션의 Inception 모듈이다.
🔹 Inception 모듈의 핵심 아이디어
이 섹션에서 논문은 translation invariance를 전제로, 네트워크가 convolutional building block들로 구성된다고 본다. 핵심 질문은 최적의 로컬 희소 구조를 어떻게 찾고, 이를 공간적으로 반복할 것인가다.
논문은 상관 기반 클러스터링 직관을 가져와 다음 같은 그림을 그린다.
- 낮은 레벨에서는 지역적으로 강하게 상관된 특징들이 많을 것 → 작은 지역에 클러스터가 몰림
→ 1×1 conv 같은 국소적인 결합이 유용 - 더 높은 레벨로 갈수록 더 넓게 퍼진(spatially spread out) 상관 구조가 생길 것
→ 더 큰 패치(3×3, 5×5)로 보는 conv가 유용
그래서 한 stage에서 서로 다른 receptive field를 가진 연산들을 병렬로 두고, 그 출력 채널들을 depth 방향으로 concat해서 다음 stage의 입력으로 넘기는 구조를 제안한다. 여기에 pooling 경로도 병렬로 추가하면 도움이 될 것이라고 말한다.
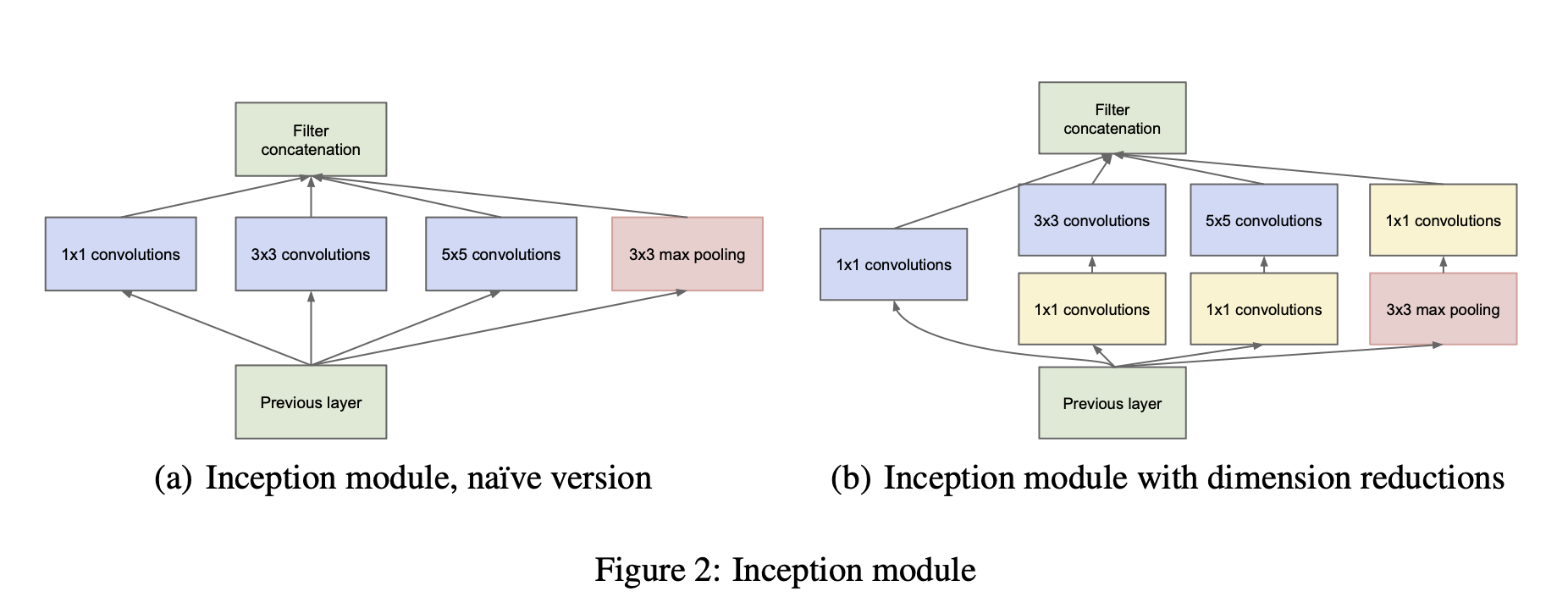
🔸 차원 축소(dimension reduction)가 필요한 이유
하지만 (Fig. 2(a)) 같은 naive 구조에는 큰 문제가 있다.
- 5×5 conv는 매우 비싸다.
- pooling 경로를 concat하면 출력 채널 수가 계속 늘어나 stage마다 폭이 커질 수 있다.
- 결국 몇 stage만 가도 연산량이 폭발한다.
여기서 논문이 제시하는 두 번째 핵심 아이디어가 차원 축소를 병목 구간에 전략적으로 넣자는 것이다. 즉 expensive conv(3×3, 5×5) 전에 1×1 conv로 채널 수를 줄여서 계산량을 낮춘다.
논문은 이를 embeddings의 성공에 기대어 설명한다. 낮은 차원 임베딩도 많은 정보를 담을 수 있다는 직관을 받아들이되, 너무 이른 압축은 표현을 너무 조밀하게 만들어 모델링이 어려울 수 있으니 많이 합쳐야 하는 구간에서만 압축하자고 말한다.
여기서 1×1 conv는 두 가지 역할을 한다.
- 차원 축소(계산량 감소)
- ReLU를 포함한 비선형성 추가(표현력 증가)
이 결과가 (Fig. 2(b))이며, 오늘날 우리가 흔히 떠올리는 Inception 모듈의 표준 형태다.
Inception 모듈의 수식적 형태(채널 concat 관점)
입력 feature map을 라 하자(배치 , 채널 ). Inception 모듈은 서로 다른 변환 를 병렬로 적용하고 채널 축으로 이어붙인다.
각 는 (1×1), (1×1→3×3), (1×1→5×5), (pool→1×1) 같은 연산 그래프로 구성된다. 이때 reduction이 들어가면 (1×1)에서 출력 채널 수를 줄여 로 만든 뒤 큰 커널을 적용하므로, 연산량이 크게 줄어든다.
왜 이런 형태가 필요한가
Inception 모듈이 하는 일은 사실상 같은 입력에서 서로 다른 receptive field로 정보를 뽑아 동시에 제공하고, 다음 stage가 그들 위에서 더 추상적인 특징을 만든다는 것이다. 이전 CNN들이 보통 한 stage에 한 종류의 커널을 쓰던 것과 달리, Inception은 stage 내부에서 멀티스케일을 결합한다.
🔹 Inception 네트워크의 전체 형태
논문은 Inception 모듈을 여러 번 쌓고, 중간중간 stride 2 max-pooling으로 해상도를 반으로 줄이는 구조를 기본으로 한다고 말한다. 다만 기술적 이유(훈련 시 메모리 효율)로 Inception 모듈을 아주 초반부터 쓰지 않고, 낮은 레벨은 전통적인 conv 스택으로 시작하는 것이 유리해 보였다고 설명한다. 이는 원리적 필연이 아니라 당시 구현 인프라의 제약에 가까운 선택이라는 점도 덧붙인다.
5️⃣ GoogLeNet
🔹 GoogLeNet이라는 이름과, 22-layer 인스턴스의 위치
논문은 Inception이 아키텍처 패밀리이고, 그중 ILSVRC14 제출에서 쓴 구체 인스턴스를 GoogLeNet이라고 부른다고 명확히 한다. 이름은 LeNet-5에 대한 오마주라고 말한다.
또한 아래 표에 가장 성공한 particular instance(GoogLeNet)를 제시하며, 앙상블 7개 중 6개 모델은 동일한 토폴로지(sampling 방법만 다름)를 썼다고 한다.
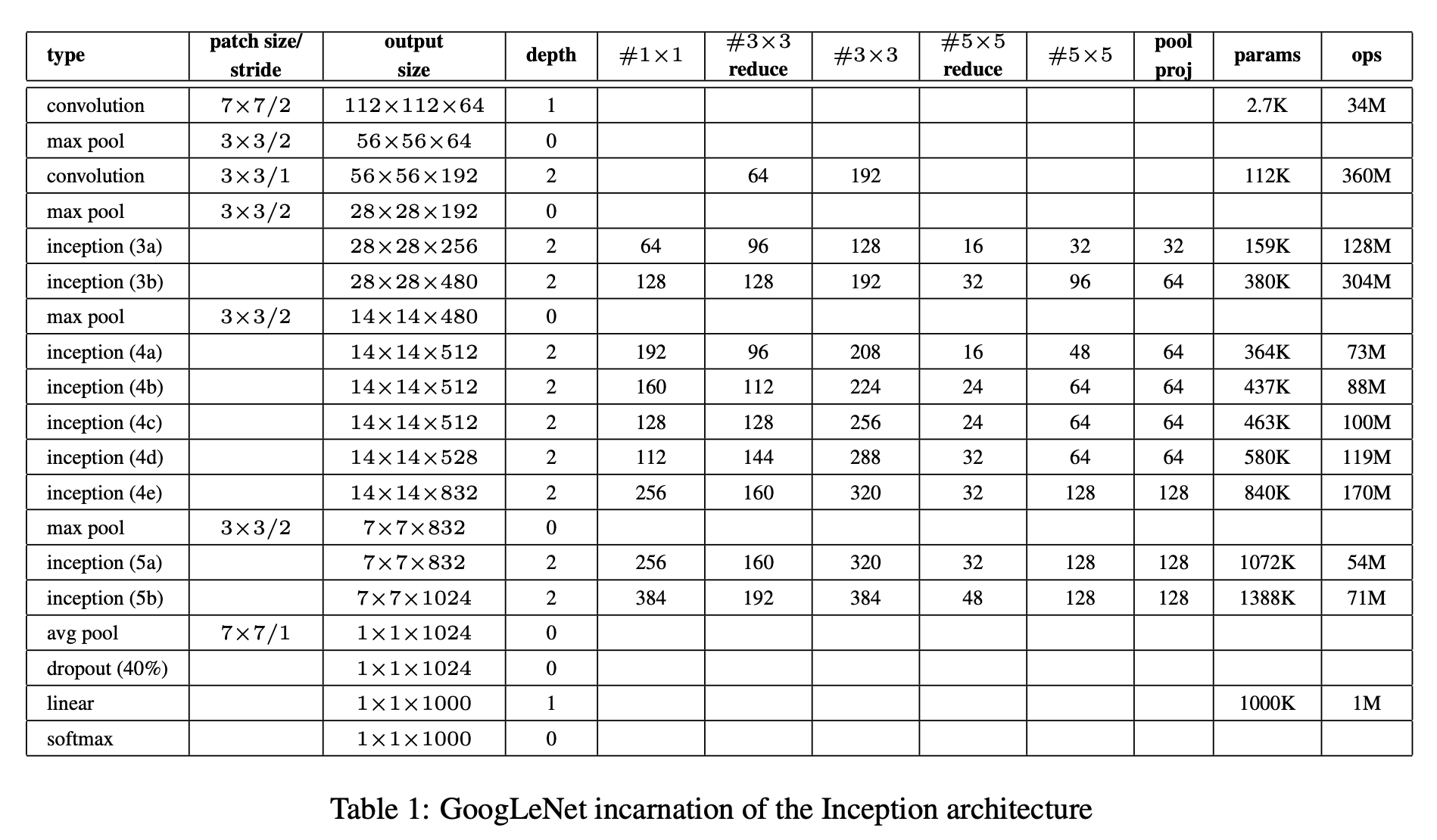
- 각 Inception 모듈에서
#1×1#3×3 reduce,#3×3#5×5 reduce,#5×5pool proj
같은 채널 수를 지정한다.
- 모든 conv는 ReLU를 쓴다.
- 입력은 224×224 RGB, mean subtraction을 한다.
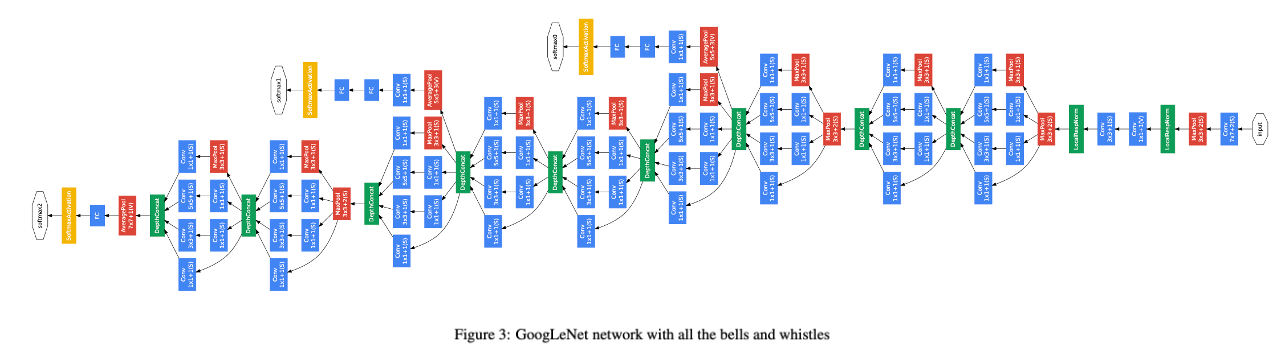
아키텍처 전체 흐름은 아래 도표에서 보조 분류기까지 포함해 도식화된다.
🔸 Average Pooling 기반 분류기와 dropout의 역할
논문은 Network-in-Network를 따라 classifier 앞에 average pooling을 두는 것이 도움이 된다고 말한다. 다만 GoogLeNet 구현은 average pooling 뒤에 추가 linear layer를 하나 두는데, 이는 다른 label set으로 fine-tuning 할 때 편의성 때문이며 성능에 큰 영향을 주진 않을 것으로 본다고 말한다.
흥미로운 정량적인 수치 언급도 있다.
- fully-connected를 average pooling으로 바꾸면 top-1 accuracy가 약 0.6% 개선되었다.
- 그렇다고 dropout이 불필요해지는 것은 아니며, FC를 제거해도 dropout은 여전히 중요했다.
즉 GoogLeNet은 거대한 FC 스택을 줄이고, 글로벌 평균 pooling 성격을 강화하면서도, regularization(dropout)을 유지하는 설계를 택했다.
🔹 보조 분류기(auxiliary classifier)
22-layer 깊이에서 gradient가 잘 전파될지(backprop signal) 우려가 있었고, 논문은 중간 레이어의 특징도 충분히 discriminative할 것이라는 관찰에 기대어, 중간에 보조 분류기를 달아 학습을 돕는 아이디어를 사용한다.
핵심 목적은 세 가지다.
- lower stage에서 더 분별적인 특징을 만들도록 유도
- backprop 신호를 중간에서 주입해 gradient 흐름 강화
- 추가 regularization 효과
논문은 보조 분류기를 Inception (4a)와 (4d) 출력 위에 붙이며, 학습 시 이 보조 손실을 전체 손실에 더하되 가중치 0.3으로 discount한다고 말한다. inference 때는 보조 분류기를 버린다.
보조 분류기의 구조는 본문에서 bullet로 명시된다.
- average pooling: 5×5, stride 3 → (4a)에서 4×4×512, (4d)에서 4×4×528
- 1×1 conv 128 filters (dimension reduction + ReLU)
- FC 1024 + ReLU
- dropout 70% dropped outputs(= dropout p=0.7)
- linear + softmax loss(1000 클래스), inference에서 제거
전체 손실의 수식적 정리
메인 분류기 손실을 , 보조 분류기 손실을 라고 하면, 학습에서 최종 손실은 논문 설명을 그대로 옮기면 다음처럼 정리할 수 있다.
이 식의 통찰은 보조 분류기를 메인 목적(정답 분류)을 바꾸지 않는 선에서, 학습을 돕는 정규화/gradient 보조 신호로 쓰자는 것이다. 가중치 은 보조 손실이 메인 손실을 지배하지 않도록 조절하는 장치다.
6️⃣ 학습 방법론
🔹 DistBelief, 비동기 SGD, 모멘텀, Polyak averaging
논문은 학습을 DistBelief 분산 학습 시스템으로 수행했다고 한다. CPU 기반 구현만 썼지만, 고급 GPU 몇 개면 1주 이내에 수렴시킬 수 있을 것이라 추정하며, 주된 제한은 메모리 사용량이라고 덧붙인다.
학습 최적화는 다음처럼 요약된다.
- asynchronous SGD + momentum 0.9
- 고정 스케줄: 8 epochs마다 learning rate를 4% 감소
- Polyak averaging으로 inference용 최종 모델 생성
모멘텀 업데이트는 보통
로 이해하면 되고, 여기서 다. 비동기 SGD는 worker들이 서로 다른 배치로 업데이트를 병렬로 수행하는 형태로 떠올리면 된다.
Polyak averaging은 학습 과정에서 여러 시점의 가중치를 평균해 더 안정적인 모델을 얻는 방법으로 이해할 수 있다.
🔸 데이터 샘플링 및 증강
논문은 흥미롭게도 경쟁까지 몇 달 동안 이미지 샘플링 방법이 계속 바뀌었고, 이미 수렴한 모델을 다른 옵션으로 재학습(fine-tune)하기도 했으며, dropout/lr 같은 하이퍼파라미터도 함께 바뀌었다고 말한다. 그래서 가장 효과적인 단 하나의 학습법을 딱 잘라 말하기 어렵다고 솔직하게 적는다.
그럼에도 경쟁 후 검증된 레시피로 다음을 제시한다.
- 이미지에서 다양한 크기의 패치를 샘플링하되,
- 패치 면적이 전체 이미지의 8%~100% 사이에서 균등 분포
- 종횡비(aspect ratio)는 3/4~4/3 사이에서 랜덤
- Andrew Howard의 photometric distortions가 과적합 완화에 유용
- Resize 시 bilinear/area/nearest/cubic을 랜덤으로 섞는 interpolation도 사용(다만 효과를 확정적으로 말하긴 어렵다고 함)
이 문단은 학습 레시피가 성능에 매우 중요하지만, 실전에서는 여러 선택이 얽혀 있어 clean한 ablation이 어렵다는 현실을 보여준다.
학습 절차 의사코드
논문 내용을 그대로 절차로 정리하면 다음과 같다.
Algorithm: GoogLeNet training (Sect. 6)
Inputs:
- Training set (ImageNet ILSVRC)
- GoogLeNet/Inception architecture with auxiliary classifiers
- Loss weights: aux_weight = 0.3
Optimizer:
- Asynchronous SGD with momentum 0.9
- Learning rate decays by 4% every 8 epochs
- Polyak averaging for final inference model
Augmentation/Sampling (one recommended recipe):
- Sample random patches with area in [8%, 100%] of image
- Random aspect ratio in [3/4, 4/3]
- Photometric distortions
- Random resize interpolation method
Training loop:
- Forward main + aux heads
- Compute L = L_main + 0.3*L_aux1 + 0.3*L_aux2
- Backprop + async SGD update
Output:
- Polyak-averaged weights7️⃣ ILSVRC 2014 분류 문제 설정과 결과
🔹 태스크/데이터/평가 지표: top-5 error가 공식 랭킹 기준
논문은 ILSVRC14 classification을 다음처럼 요약한다.
- 1000 클래스(leaf-node categories)
- train 1.2M / val 50K / test 100K
- 각 이미지당 GT 레이블 1개
- top-1 accuracy와 top-5 error를 보고하며, 랭킹 기준은 top-5 error
top-5 error는 정답이 상위 5개 예측 안에 없을 비율이다. 즉 GT가 top-5에 있으면 정답으로 친다.
🔸 테스트 시점 기법: 앙상블 + 멀티크롭 + 단순 평균
논문은 외부 데이터 없이 참가했다고 강조한다. 그 위에서 성능을 끌어올리기 위해 테스트 시점에 다음을 수행했다고 말한다.
-
동일 토폴로지의 GoogLeNet 7개를 독립 학습하고 앙상블
- 1개는 더 넓은(wider) 버전
- initialization/learning rate 정책은 동일, sampling/입력 순서만 차이
-
Krizehvsky et al.보다 더 공격적인 cropping
- 짧은 변을
{256, 288, 320, 352}로 리사이즈(4 scales) - 각 scale에서 좌/중/우(세로 이미지면 상/중/하) square를 선택(3 squares)
- 각 square에서 4 corners + center 224×224 crop(5 crops)
- 그리고 그 square 자체를 224×224로 리사이즈한 것을 추가(1 crop)
- 그리고 좌우 반전(2)
→ 총 crops:
- 짧은 변을
-
softmax 확률을 crops와 모델들에 대해 평균
- max pooling 등 대안을 val에서 비교했지만 평균이 더 좋았다고 말한다.
이 절차를 알고리즘으로 정리하면 아래처럼 쓸 수 있다.
Algorithm: GoogLeNet classification inference (Sect. 7)
Input: image I, ensemble models {M_j}
1) For each scale s in {256, 288, 320, 352}:
a) Resize I so shorter side = s
b) Take 3 squares (left/center/right or top/center/bottom)
c) For each square:
- take 4 corners + center 224x224 crops (5)
- take the whole square resized to 224x224 (1)
- add mirrored versions (x2)
2) For each crop c and each model M_j:
p_{j,c} = softmax(M_j(c))
3) Average probabilities:
p = mean_{j,c} p_{j,c}
Output: predicted class ranking from p🔹 정량 결과: Top-5 Error 6.67%와 Crops/모델 수의 Trade-Off
논문은 최종 제출 결과로 val/test 모두 top-5 error 6.67% 를 얻어 1위를 했다고 말한다. 또한 2012 SuperVision 대비 상대적으로 56.5% error 감소라고 강조한다.
여기서 경쟁 전체 결과 비교가 다음 표로 제시된다.
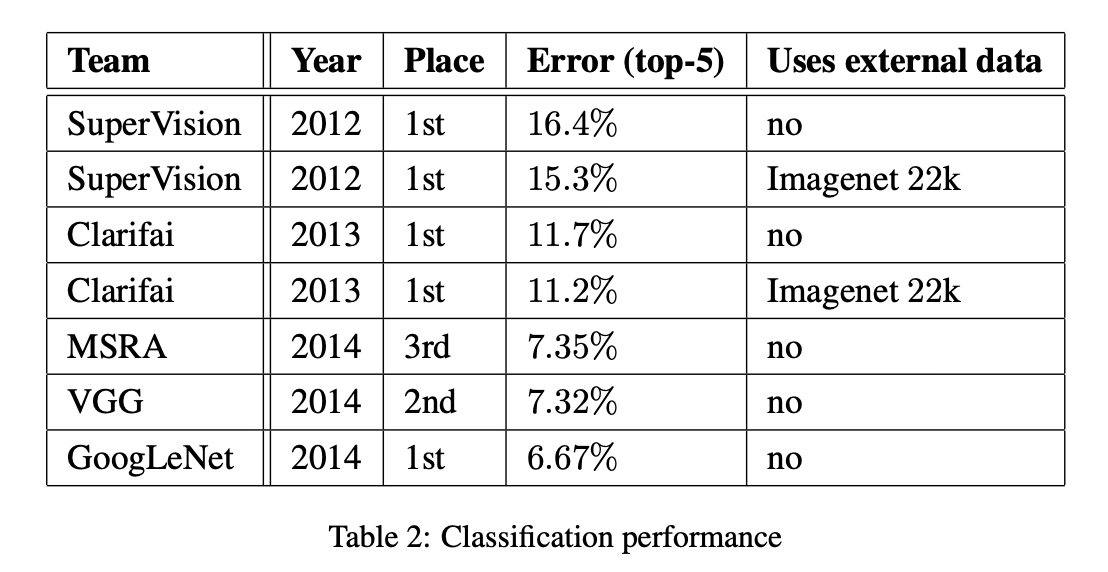
그리고 crops/모델 수에 따른 성능/비용 변화가 아래 표로 제시된다. 텍스트 추출본에서 표가 완전히 정렬되진 않지만, 핵심 메시지는 다음이다.
- crop 수를 10 → 144로 늘리면 성능이 좋아진다.
- 1개 모델보다 7개 앙상블이 더 좋다.
- 하지만 crop 수를 계속 늘릴수록 이득이 점점 작아진다(marginal)고 언급한다.
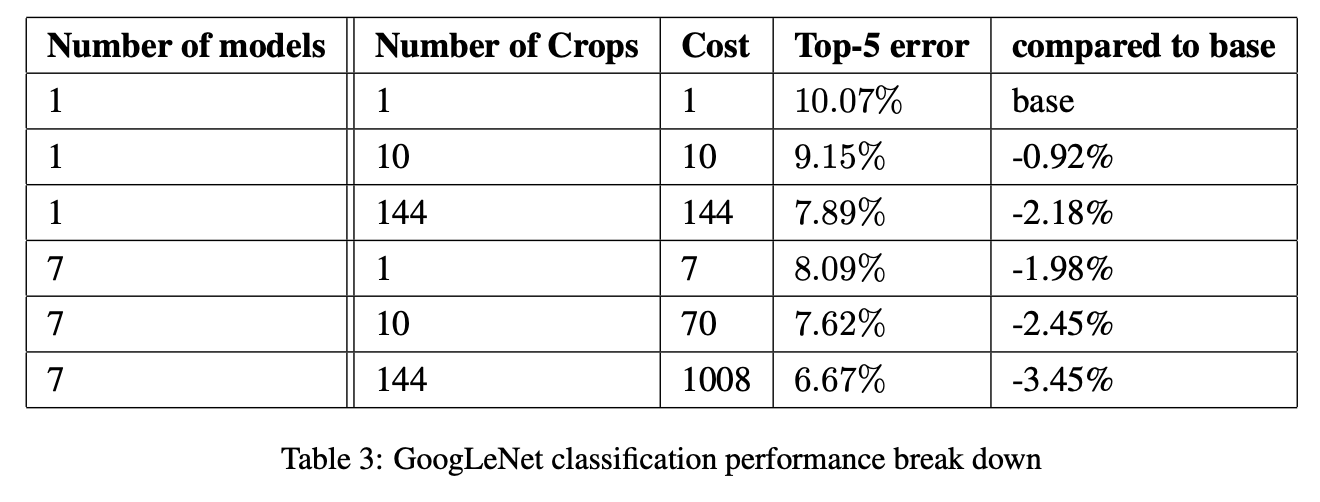
이 구간의 해석을 한 문장으로 요약하면 GoogLeNet 자체 아키텍처가 강한 것은 기본이고, ILSVRC 순위 수준의 최종 성능은 test-time computation(멀티크롭/앙상블)과 강하게 결합되어 있다.
💡 해당 논문의 시사점과 한계
이 논문의 의의는 Inception 모듈이라는 블록을 만든 것 이상으로, 제약(연산 예산)을 명시한 상태에서 아키텍처를 설계하는 사고 방식을 대중화했다는 점에 있다.
- 희소 구조가 이상적이라는 이론적 동기와,
- 희소 연산이 당시엔 느리다는 시스템 현실 사이를 연결해서,
- Dense 블록의 병렬 결합 + 1×1 reduction이라는 설계로 타협점을 만들었다.
또한 Inception 모듈은 한 stage에서 멀티스케일을 병렬로 처리하고 concatenate한다는 관점으로 이후 수많은 변형(v2/v3/v4, Xception, Inception-ResNet 등)으로 확장된다. 즉 GoogLeNet은 단일 모델이라기보다 아키텍처 패밀리의 출발점이다.
한계도 있다.
- 논문 스스로도 인정하듯, 설계 원칙(Arora/Hebbian/멀티스케일)이 정말로 최적이어서 성능이 나온 것인지, 혹은 다른 요인이 더 컸는지에 대한 엄밀한 검증은 부족하다.
- ILSVRC 순위 수준의 성능은 테스트 시점에 144 crops × 여러 모델 앙상블 같은 큰 계산을 쓰는 프로토콜과 결합되어 있다. 즉 단일 패스 inference 관점에서의 비용-성능 곡선은 별도 논의가 필요하다.
그럼에도 이 논문은 효율을 고려한 깊은 네트워크 설계라는 주제를 강하게 제시했고, 이후의 아키텍처 연구가 단순한 더 크고 더 깊게에서 벗어나 자원 배분/모듈 설계/병렬 경로/차원 축소 같은 키워드로 전개되게 만든 대표적 전환점이라고 볼 수 있다.
👨🏻💻 InceptionNet-v1 구현하기
논문 본문에서는 GoogLeNet이라는 이름을 쓰지만, lucid 구현에서는 같은 모델을 inception_v1(InceptionNet-v1)로 지칭한다. 이 파트에서는 inception.py를 직접 읽고, 논문이 코드에서 어떻게 구현되는지 단계적으로 연결한다.
0️⃣ 사전 설정 및 준비 단계
먼저 파일 상단은 import와 공개 심볼, 그리고 공통 베이스 클래스를 정의한다.
class Inception(nn.Module):
def __init__(self, num_classes: int, use_aux: bool | None = True) -> None:
super().__init__()
self.num_classes = num_classes
self.use_aux = use_aux
@override
def forward(self, x: Tensor) -> Tuple[Tensor | None, ...]:
return super().forward(x)여기서 핵심은 Inception이 nn.Module을 상속하는 공통 베이스이고, num_classes와 use_aux를 저장한다는 점이다. forward는 Tuple[Tensor | None, ...] 형태를 반환하는 것으로 타입을 넓혀두고, 실제 forward는 하위 클래스들이 구현한다.
1️⃣ Inception 모듈 구현
논문의 Inception 모듈(병렬 1×1 / 3×3 / 5×5 / pool 경로 + concat)은 _InceptionModule로 구현되어 있다.
class _InceptionModule(nn.Module):
def __init__(
self,
in_channels: int,
out_channels_1x1: int,
reduce_3x3: int,
out_channels_3x3: int,
reduce_5x5: int,
out_channels_5x5: int,
out_channels_pool: int,
) -> None:
super().__init__()
self.branch1 = nn.ConvBNReLU2d(in_channels, out_channels_1x1, kernel_size=1)
self.branch2 = nn.Sequential(
nn.ConvBNReLU2d(in_channels, reduce_3x3, kernel_size=1),
nn.ConvBNReLU2d(reduce_3x3, out_channels_3x3, kernel_size=3, padding=1),
)
self.branch3 = nn.Sequential(
nn.ConvBNReLU2d(in_channels, reduce_5x5, kernel_size=1),
nn.ConvBNReLU2d(reduce_5x5, out_channels_5x5, kernel_size=5, padding=2),
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
nn.ConvBNReLU2d(in_channels, out_channels_pool, kernel_size=1),
)
def forward(self, x: Tensor) -> Tensor:
return lucid.concatenate(
[self.branch1(x), self.branch2(x), self.branch3(x), self.branch4(x)],
axis=1,
)논문과의 대응을 branch 단위로 읽으면:
branch1: 1×1 conv 경로 (Fig. 2의 1×1 path)branch2: 1×1 reduction → 3×3 conv (Fig. 2(b)의#3×3 reduce→ 3×3)branch3: 1×1 reduction → 5×5 conv (Fig. 2(b)의#5×5 reduce→ 5×5)branch4: 3×3 maxpool(stride 1, padding 1) → 1×1 projection (pool proj)
그리고 마지막 lucid.concatenate([...], axis=1)이 논문에서 말하는 filter bank concatenation(DepthConcat) 이다. 즉 Inception 모듈의 본질인 병렬 경로의 출력 채널을 쌓아서 다음 stage 입력으로 만든다가 코드에서 그대로 보인다.
여기서 nn.ConvBNReLU2d는 (conv + batchnorm + ReLU) 계열의 블록이며, 논문 GoogLeNet은 LRN을 언급하는 반면, Lucid 구현은 BN을 포함한 conv 블록을 기본 단위로 사용한다는 점이 논문과 구현의 차이로 남는다.
2️⃣ 보조 분류기 구현
논문에서 보조 분류기는 avgpool → 1×1 conv(128) → FC 1024 → dropout 0.7 → linear로 정의됐다. Lucid의 _InceptionAux는 이를 매우 직접적으로 구현한다.
class _InceptionAux(nn.Module):
def __init__(
self, in_channels: int, num_classes: int, pool_size: tuple[int, int]
) -> None:
super().__init__()
self.avgpool = nn.AdaptiveAvgPool2d(pool_size)
self.conv = nn.ConvBNReLU2d(in_channels, 128, kernel_size=1)
self.fc1 = nn.Linear(128 * pool_size[0] * pool_size[1], 1024)
self.fc2 = nn.Linear(1024, num_classes)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=0.7)
def forward(self, x: Tensor) -> Tensor:
x = self.avgpool(x)
x = self.conv(x)
x = x.reshape(x.shape[0], -1)
x = self.fc1(x)
x = self.dropout(self.relu(x))
x = self.fc2(x)
return x논문에서는 average pooling 5×5 stride 3로 4×4 output을 만들었다고 설명하지만, Lucid는 AdaptiveAvgPool2d(pool_size)로 출력을 (4,4)로 강제한다. 결과적으로 4×4 feature를 만든다는 목적은 같고, 구현은 입력 크기 변화에도 robust하게 만든 형태로 볼 수 있다.
또한 dropout이 p=0.7로 설정되어 있어 논문 bullet(70% dropped outputs)과 정합된다.
3️⃣ GoogLeNet 본체 구현
이제 핵심인 Inception-v1(GoogLeNet) 전체 네트워크는 Inception_V1에 구현되어 있다.
class Inception_V1(Inception):
def __init__(self, num_classes: int = 1000, use_aux: bool = True) -> None:
super().__init__(num_classes, use_aux)
in_channels = 3
self.conv1 = nn.ConvBNReLU2d(
in_channels, 64, kernel_size=7, stride=2, padding=3
)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv2 = nn.Sequential(
nn.ConvBNReLU2d(64, 64, kernel_size=1),
nn.ConvBNReLU2d(64, 192, kernel_size=3, stride=1, padding=1),
)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.incep_3 = nn.Sequential(
_InceptionModule(192, 64, 96, 128, 16, 32, 32),
_InceptionModule(256, 128, 128, 192, 32, 96, 64),
)
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.incep_4a = _InceptionModule(480, 192, 96, 208, 16, 48, 64)
self.incep_4bcd = nn.Sequential(
_InceptionModule(512, 160, 112, 224, 24, 64, 64),
_InceptionModule(512, 128, 128, 256, 24, 64, 64),
_InceptionModule(512, 112, 144, 288, 32, 64, 64),
)
self.incep_4e = _InceptionModule(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.incep_5 = nn.Sequential(
_InceptionModule(832, 256, 160, 320, 32, 128, 128),
_InceptionModule(832, 384, 192, 384, 48, 128, 128),
)
if use_aux:
self.aux1 = _InceptionAux(512, num_classes, pool_size=(4, 4))
self.aux2 = _InceptionAux(528, num_classes, pool_size=(4, 4))
else:
self.aux1 = None
self.aux2 = None
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p=0.4)
self.fc = nn.Linear(1024, num_classes)
def forward(self, x: Tensor) -> Tuple[Tensor, Optional[Tensor], Optional[Tensor]]:
x = self.maxpool1(self.conv1(x))
x = self.maxpool2(self.conv2(x))
x = self.maxpool3(self.incep_3(x))
x = self.incep_4a(x)
if self.aux1 is not None and self.training:
aux1 = self.aux1(x)
else:
aux1 = None
x = self.incep_4bcd(x)
if self.aux2 is not None and self.training:
aux2 = self.aux2(x)
else:
aux2 = None
x = self.maxpool4(self.incep_4e(x))
x = self.avgpool(self.incep_5(x))
x = x.reshape(x.shape[0], -1)
x = self.dropout(x)
x = self.fc(x)
return x, aux2, aux1이 코드는 논문 GoogLeNet의 전통적 stem → Inception 스택 → 평균풀링+드롭아웃+선형 분류기 흐름을 매우 직접적으로 담고 있다.
stem: 7×7 conv + pooling + (1×1→3×3) + pooling
논문 Table 1/Fig 3에서 앞단은 전통적 conv로 시작한다고 했고, Lucid도 동일하게 7×7 conv로 시작한다.
conv1:7×7, stride 2, padding 3 → 공간 해상도를 빠르게 줄이는 AlexNet류 stemmaxpool1:3×3, stride 2conv2:1×1후3×3(padding 1) → 채널 재구성 + 지역 문맥maxpool2:3×3, stride 2
Inception stage 3/4/5: 모듈 설정값이 곧 논문 표의 채널 수
_InceptionModule(in_channels, out1, red3, out3, red5, out5, poolproj)의 숫자들은 논문 Table 1에 나오는 각 경로의 채널 수를 코드로 직접 박아 넣은 것이다. 예를 들어 stage3 첫 모듈은
- in=192
- 1×1: 64
- 3×3: reduce 96 → 128
- 5×5: reduce 16 → 32
- pool proj: 32
로 읽히며, 이는 차원 축소를 먼저 하고 큰 커널을 적용한다는 Fig. 2(b)의 원칙을 그대로 구현한 형태다.
보조 분류기의 위치와 self.training 조건
논문은 보조 분류기를 (4a)와 (4d)에 붙인다고 했다. Lucid는
incep_4a출력에서aux1incep_4bcd(4b,4c,4d의 묶음) 출력에서aux2
를 뽑는다. 즉 aux2는 4d 이후 출력에 해당한다고 볼 수 있다.
또한 중요한 구현 디테일이 있다.
- 보조 분류기는
self.training일 때만 계산한다. - inference 시에는 자동으로
None이 된다.
즉 논문에서 말한 inference time에 auxiliary network discard가
if self.aux1 is not None and self.training같은 조건으로 구현되어 있다.
출력: (main, aux2, aux1) 순서
forward가 return x, aux2, aux1 형태로 반환한다는 점은 일반적인 (main, aux1, aux2) 순서와 다를 수 있다. 따라서 학습 코드에서 이 반환 순서를 어떻게 소비하는지(예: loss 가중치 0.3 적용)를 맞춰야 한다.
5️⃣ 모델 레지스트리 등록
파일 하단의 팩토리 함수들은 Lucid의 모델 레지스트리에 각 Inception 변형을 등록한다.
@register_model
def inception_v1(
num_classes: int = 1000,
use_aux: bool = True,
**kwargs,
) -> Inception:
return Inception_V1(num_classes, use_aux, **kwargs)즉 Lucid에서 GoogLeNet을 쓰려면 inception_v1()을 호출하면 된다.
✅ 정리
GoogLeNet 논문은 "더 깊고 더 넓게" 라는 슬로건을 무작정 밀어붙이는 대신, 희소 구조의 아이디어(상관 기반 클러스터링, Hebbian 원리)과 멀티스케일 처리를 바탕으로, dense 블록 조합으로 희소 구조를 근사하는 Inception 모듈을 제안했다. 이 모듈은 1×1 reduction을 통해 3×3/5×5의 비용을 제어하면서, 병렬 경로의 출력을 concat해 다음 stage가 다양한 스케일의 정보를 동시에 활용할 수 있게 만든다. 실전에서는 보조 분류기(auxiliary classifier) 로 학습 신호를 보강하고, ILSVRC에서는 멀티크롭/앙상블 같은 테스트 기법과 결합해 매우 낮은 top-5 error를 달성했다. Lucid의 구현은 이 논문의 핵심 아이디어를 _InceptionModule(Fig. 2), _InceptionAux(보조 분류기), Inception_V1(Fig. 3의 전체 네트워크)로 직접 대응시키며, 논문에서 GoogLeNet이라 부른 모델을 inception_v1이라는 이름으로 제공한다는 점만 기억하면 논문-코드 연결이 깔끔해진다.
📄 출처
Szegedy, Christian, et al. "Going Deeper with Convolutions." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
