# EDA
1. 라이브러리 불러오기 (import)
: pandas 라이브러리를 pd 이름으로 불러오기
import pandas as pd
2. 파일 불러오기 (read_csv())
: 파이썬에서 데이터 파일(csv 파일)을 불러오기 위해서는 pandas 라이브러리를 이용해야 한다.
: 약어로 지정한 pd를 사용하여 read_csv함수를 통해 csv 파일을 불러 올 수 있다.
: 데이터 다운로드 링크로 데이터를 코랩에 불러오기
!wget 'https://bit.ly/3gLj0Q6' import zipfile with zipfile.ZipFile('3gLj0Q6', 'r') as existing_zip: existing_zip.extractall('data')
: data 폴더에 있는 test.csv 파일과 train.csv 파일 불러오기
train = pd.read_csv('data/train.csv') test = pd.read_csv('data/test.csv')
3. 행열갯수 관찰하기(shape)
: 불러온 데이터의 행과 열의 갯수를 shape attribute 로 관찰할 수 있다.
: shape를 이용해 train과 test의 행과 열의 갯수를 파악하기
train.shape test.shape


4. 데이터 확인하기(head())
: head() 메서드는 데이터 전부를 보여주지 않고 데이터의 상단부분만 출력하여 보여준다.
: head()와 유사한 메서드로는 tail()메서드가 있고, tail() 메서드는 데이터의 하단 부분을 출력하여 보여준다.
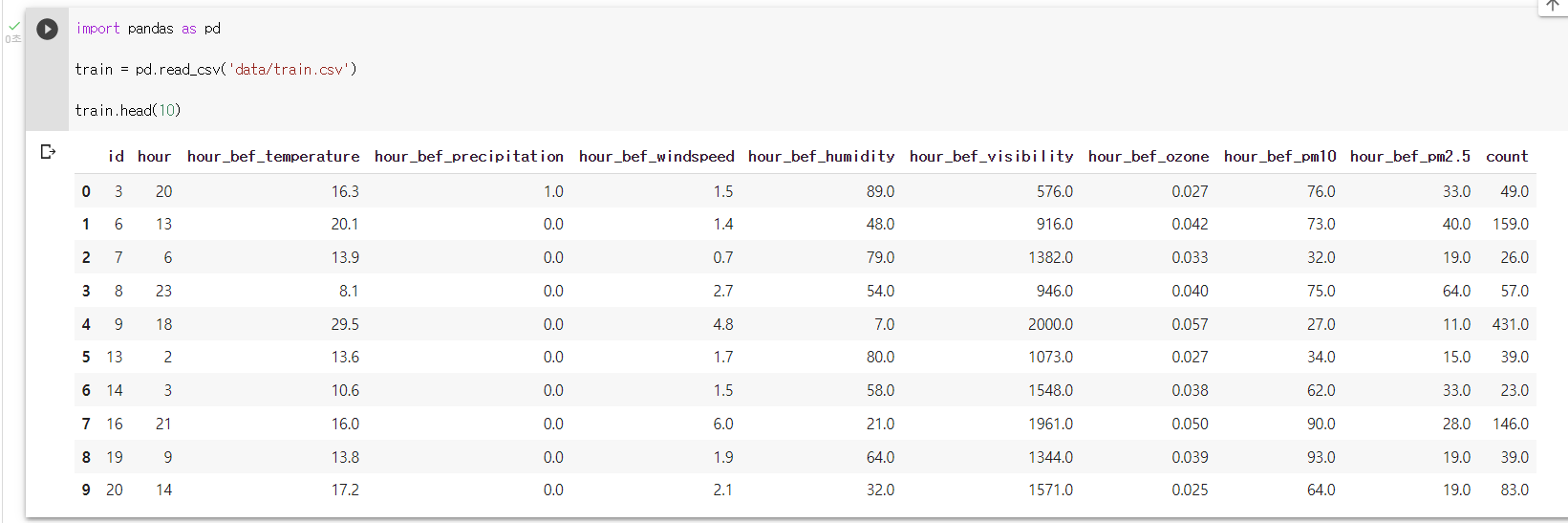
: head() 메서드를 이용해 train 데이터의 상위 10개 행을 출력하기
train.head(10)
5. 결측치 확인하기(is_null())
: 결측치(Missing Value)는 말 그대로 데이터에 값이 없는 것을 뜻한다.
: 줄여서 'NA'라고 표현하기도 하며, 다른 언어에서는 Null 이란 표현을 많이 쓴다.
: Pandas 에서는 결측치를 NaN 값으로 표현한다.
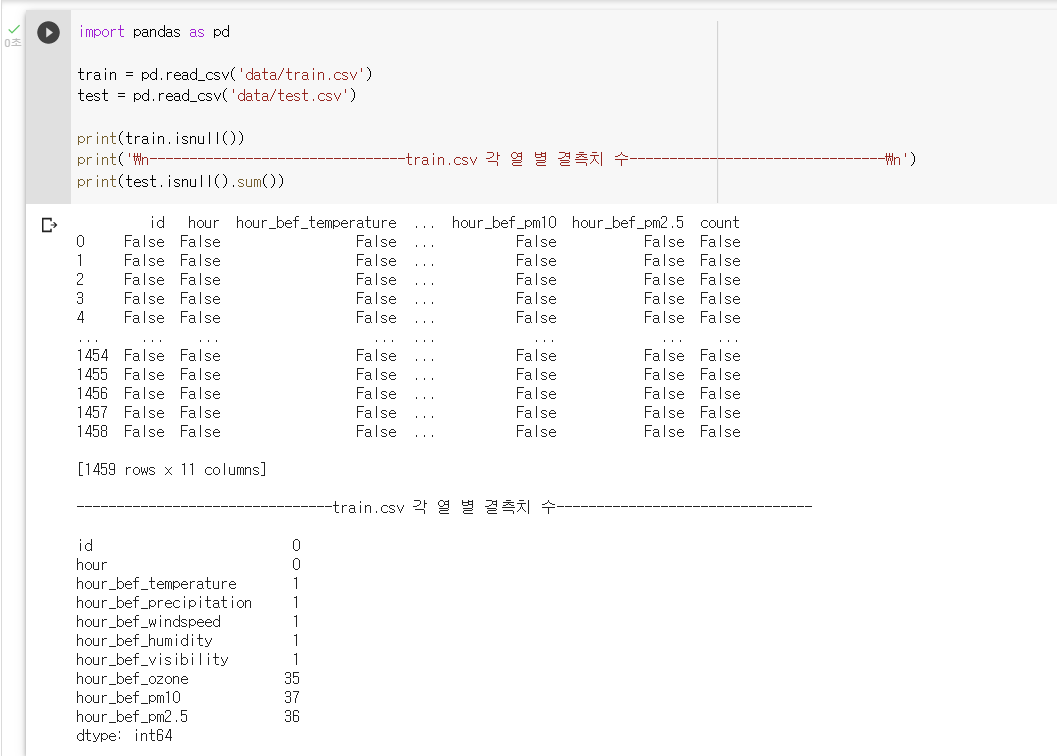
: Pandas에서 isnull() 메서드를 사용하면 DataFrame에서 NaN 값을 확인 가능
: isnull() 메소드는 Dataframe에서 데이터가 NaN 값이면 True로, 그렇지 않으면 False로 값을 리턴
: isnull() 메서드 뒤에 sum() 메서드를 추가 해주면 데이터 프레임의 각 열 별 결측치의 수를 확인 할 수 있다.
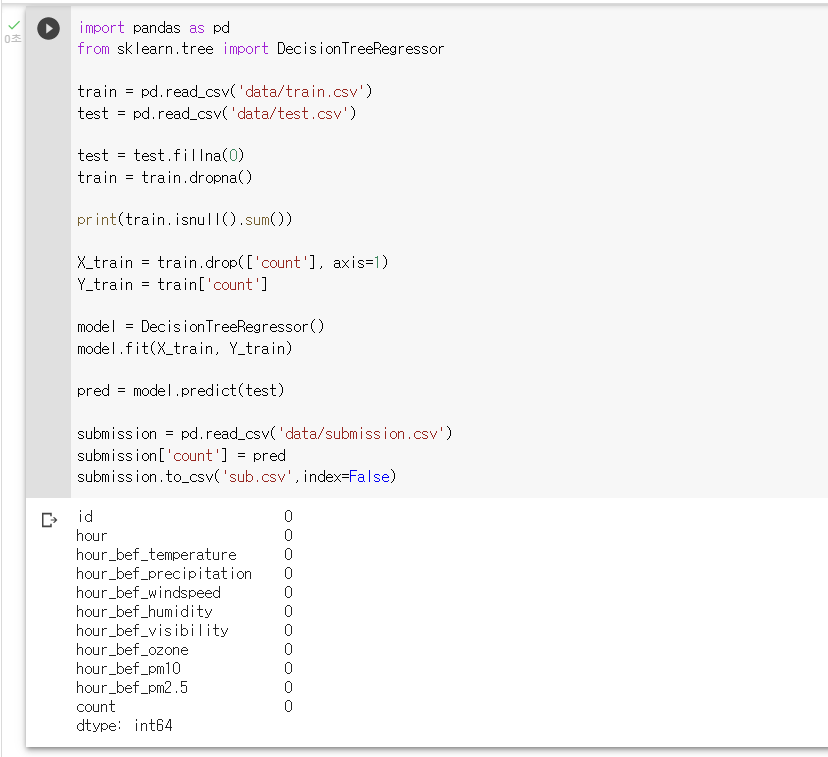
: train.csv 데이터 프레임에서 각 데이터의 결측치 여부를 확인하기
: train 데이터의 열별 결측치 수를 확인하기print(train.isnull()) print('\n------------------------train.csv 각 열 별 결측치 수------------------------\n') print(test.isnull().sum())
# 전처리
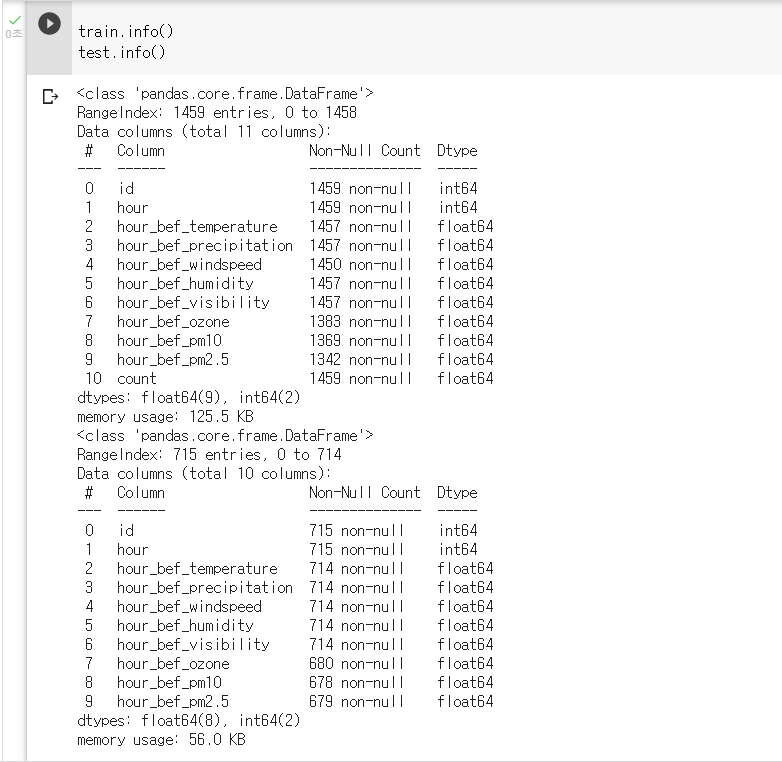
1. 데이터 결측치 확인하기(info())
: Dataframe에 info() 매서드를 사용하면, 피쳐들의 기본 정보(결측치와 데이터 타입 등)를 확인할 수 있다.
: 모델링에 앞서 결측치가 있다면, 결측치들을 어떻게 다뤄야할지 고민하고 처리하는 과정이 필요
: DataFrame 객체의 info() 매서드를 사용해서 train과 test의 데이터 타입을 확인하기
train.info() test.info()
2. 결측치 삭제하기, 대체하기(dropna(),fillna())
: dropna() 를 사용하면, 결측치를 갖는 행을 DataFrame 객체에서 삭제한다.
: fillna() 를 사용해 모든 결측치를 인자값으로 대체할 수 있다.
: DataFrame 객체의 dropna() 매서드를 사용해서 train과 test의 결측치를 삭제하기
train = train.dropna() test = test.fillna(0)

# 모델링
1. scikit-learn (DecisionTreeClassifier)
: scikit-learn 라이브러리 불러오기
import sklearn
2. 모델개념 (의사결정나무)
-
의사결정나무란?
: 결정 트리는 의사 결정 규칙과 그 결과들을 트리 구조로 도식화한 의사 결정 지원 도구의 일종이다. 즉 스무고개 방식으로 구조화되는 것이다. -
원리
: EDA 를 통해 data를 살펴보면 각 행(row) 들은 피쳐들을 갖고 있다.
: 이 중 하나의 피쳐를 정해서 해당 피쳐의 값에 대해 특정한 하나의 값을 정한다면, 이를 기준으로 모든 행(row) 들을 두 개의 노드(node) 로 분류(Binary decision rule. 이진분할) 할 수 있다.: 만약 특정하게 2개를 정한다면 3진분할이 되는 것이다.
: 대표적인 의사결정나무인 CART 의사결정 나무 는 이진분할을 사용한다.: 파생된 두 개의 노드에 대해서 또 다시 새로운 피쳐의 특정한 값을 정하고 분류를 진행한다.
: 이 과정을 반복하게 되면 점차 피쳐의 값에 따라 data 들이 분류가 되며 이것이 의사결정 나무의 원리입니다.: 특정한 값을 정하는 의사결정 나무의 대원칙 -> "한쪽 방향으로 쏠리도록"
: 분류될 때는 공평하게 비슷한 양으로 나뉘도록 값을 정하는 것이 아니라, "한쪽 방향으로 쏠리도록" 해주는 특정한 값을 찾는 것이며, 이를 불순도를 계산해서 찾아낸다.
: scikit-learn 에서 의사결정나무 모델의 모듈 불러오기
import sklearn from sklearn.tree import DecisionTreeClassifier
3.모델선언 (DecisionTreeClassifier())
: scikit-learn 으로부터 의사결정나무 모듈을 불러오는 코드
model = DecisionTreeClassifier() # model = DecisionTreeRegressor()
4. 모델훈련 (fit())
: 모델을 선언한 후, fit(X, Y) 함수를 사용해서 모델을 훈련시킬 수 있음
: X 데이터는 예측에 사용되는 변수들이고, Y 데이터는 예측결과 변수임을 주의
: X 데이터는 train data 에서 drop([‘제외할컬럼명’], axis=1) 함수를 이용해 예측할 피쳐를 제외할 수 있음
: Y 데이터는 train[‘예측할컬럼명'] 으로 인덱싱할 수 있음
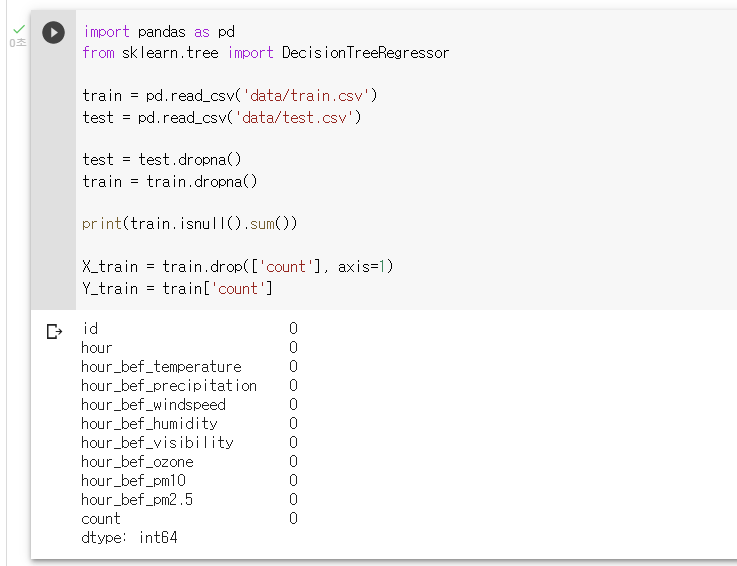
: train 데이터 중 예측해야 할 count 피쳐를 drop()함수를 사용하고, axis=1 옵션을 사용해 해당 열을 제외한 데이터들을 X_train 이라는 이름의 DataFrame 객체로 만들고, count 피쳐만을 데이터로 갖는 Y_train 이라는 이름의 DataFrame 객체로 만들기
X_train = train.drop(['count'], axis=1) Y_train = train['count']
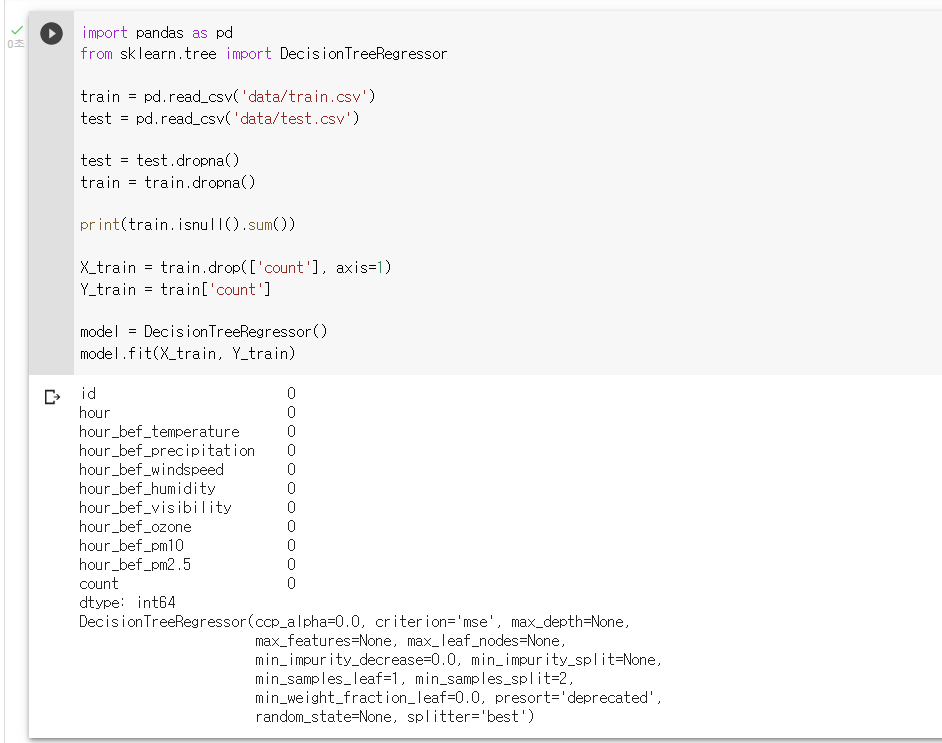
: 이제 모델을 선언하고, fit() 함수를 이용해 모델을 훈련시킬 수 있음
: model 변수명으로 모델을 선언하고, fit() 함수를 사용해서, X_train 을 input 으로 삼고, Y_train 을 output 으로 삼아 모델을 훈련시키기
model = DecisionTreeRegressor() model.fit(X_train, Y_train)
5. 테스트예측(predict())
: 테스트 파일을 훈련된 모델로 예측해보기
: 훈련된 모델에서 predict() 매서드에 예측하고자 하는 data를 인자로 넣어주게 되면 해당 결과 array 를 할당할 수 있다.
: predict() 를 이용해 test data 를 훈련된 모델로 예측한 data 를 생성하고 예측결과 상위 5개를 출력하기
pred = model.predict(test) pred[:5]
6. 제출파일생성(to_csv())
1) 백지의 답안지인 submission.csv 파일을 df 파일로 불러와서 예측결과를 덧입혀주기
2) 덧입혀준 df 파일을 csv 파일로 내보내기
- submission.csv 파일을 read_csv() 를 이용해 df 클래스로 불러오기
- submission df 파일의 count 피쳐를 예측결과로 할당하기
- submission df 파일을 to_csv() 를 이용해 csv 파일로 내보내기
- 여기서 index 옵션은 False 로 지정해주어야 정답 형식과 맞아 떨어져 헤더 오류가 나지 않음.
submission = pd.read_csv('data/submission.csv') submission['count'] = pred submission.to_csv('sub.csv',index=False)