1. BERT-base (bert-base-uncased)
1. 필요 라이브러리 설치
pip install transformers sentence-transformers scikit-learn matplotlib2. 라이브러리 불러오기
from transformers import AutoTokenizer, AutoModel
import torch
import numpy as np
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt3. BERT 모델 로드
해당 텍스트들을 어떠한 용도로 사용할지 모르기 때문에, 범용성을 가지는 일반 Bert를 활용
# 1. Hugging Face BERT (일반 BERT 사용)
# 해당 텍스트들을 어떠한 용도로 사용할지 모르기 때문에, 범용성을 가지는 일반 Bert를 활용
model_name = 'bert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)4. 벡터화할 텍스트 데이터 정의
# 문장 리스트
sentences = [
"I love artificial intelligence.",
"Machine learning is fascinating.",
"Natural language processing is a subfield of AI.",
"Deep learning improves neural networks.",
"Transformers have changed AI forever."
]- 문장 리스트로 구성된 입력 데이터
5. 텍스트 토크나이즈
# 2. 토큰화
encoded = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')padding=True: 문장 길이를 맞춤truncation=True: 최대 길이 초과 시 자름return_tensors="pt": PyTorch 텐서 형태로 반환
6. BERT 모델을 이용한 임베딩 추출
# 3. 모델 통과
with torch.no_grad():
output = model(**encoded)torch.no_grad(): 학습이 아닌 추론 모드
# 4. mean pooling 구현 : 문장의 의미를 더 잘 반영하도록 유도
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output.last_hidden_state
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = (token_embeddings * input_mask_expanded).sum(1)
sum_mask = input_mask_expanded.sum(1)
sum_mask = torch.clamp(sum_mask, min=1e-9) # 0 방지
return sum_embeddings / sum_mask
embeddings = mean_pooling(output, encoded['attention_mask']).numpy()
print(embeddings.shape)(5, 768)
- 모델 출력 (
model_output)과attention_mask를 받아서 평균 임베딩을 계산하는 함수. - 분모가 0이 되는 것을 방지하기 위해 최소값 설정
# 5. PCA로 3차원 축소
pca = PCA(n_components=3)
reduced = pca.fit_transform(embeddings)n_components=3은 원래 임베딩 벡터(예: 768차원) 를 3차원으로 줄이겠다는 의미
# 6. PCA 시각화
fig = plt.figure(figsize=(10, 14))
ax = fig.add_subplot(111, projection='3d')
colors = ['r', 'g', 'b', 'y', 'c']
for i, sentence in enumerate(sentences):
ax.scatter(*reduced[i], c=colors[i], marker='o', s=100, label=sentences[i])
ax.text(reduced[i][0]+0.2, reduced[i][1]+0.2, reduced[i][2]+0.2, f"{i+1}", size=12, zorder=1, color='black')
ax.set_title("3D PCA of BERT Embeddings: bert-base-uncased + mean pooling")
ax.set_xlabel("PC1")
ax.set_ylabel("PC2")
ax.set_zlabel("PC3")
ax.legend()
plt.show()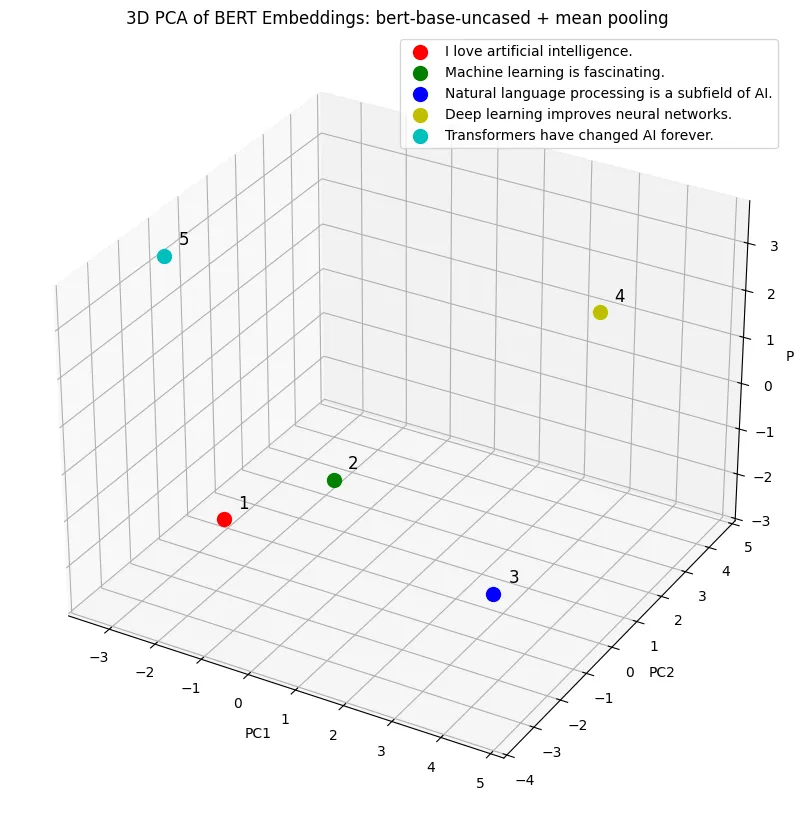
2. Sentence-BERT
import torch
from transformers import BertTokenizer, BertModel, AutoTokenizer, AutoModel
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# 1. 입력 문장
sentences = [
"I love artificial intelligence.",
"Machine learning is fascinating.",
"Natural language processing is a subfield of AI.",
"Deep learning improves neural networks.",
"Transformers have changed AI forever."
]
# 2. BERT-base (순수 BERT) 준비
bert_tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
bert_model = BertModel.from_pretrained('bert-base-uncased')
# 3. Sentence-BERT 준비
sbert_tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
sbert_model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
# 4. BERT-base 임베딩 (CLS 토큰)
def get_bert_embeddings(sentences):
embeddings = []
for sentence in sentences:
inputs = bert_tokenizer(sentence, return_tensors='pt', truncation=True, padding=True)
with torch.no_grad():
outputs = bert_model(**inputs)
# mean pooling 적용
token_embeddings = outputs.last_hidden_state # [1, seq_len, hidden_size]
attention_mask = inputs['attention_mask'] # [1, seq_len]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = (token_embeddings * input_mask_expanded).sum(1)
sum_mask = input_mask_expanded.sum(1)
mean_pooled = sum_embeddings / torch.clamp(sum_mask, min=1e-9)
embeddings.append(mean_pooled.squeeze(0).numpy())
return np.array(embeddings)
# 5. Sentence-BERT 임베딩 (CLS 토큰)
def get_sbert_embeddings(sentences):
inputs = sbert_tokenizer(sentences, return_tensors='pt', padding=True, truncation=True)
with torch.no_grad():
outputs = sbert_model(**inputs)
cls_embeddings = outputs.last_hidden_state[:, 0, :] # (batch_size, hidden_size)
return cls_embeddings.numpy()
# 6. 임베딩 추출
bert_embeddings = get_bert_embeddings(sentences)
sbert_embeddings = get_sbert_embeddings(sentences)
# 7. PCA로 3D 축소
pca_bert = PCA(n_components=3)
pca_sbert = PCA(n_components=3)
bert_3d = pca_bert.fit_transform(bert_embeddings)
sbert_3d = pca_sbert.fit_transform(sbert_embeddings)
# 8. 3D 시각화
fig = plt.figure(figsize=(16, 7))
# BERT 결과
ax1 = fig.add_subplot(121, projection='3d')
for i, sentence in enumerate(sentences):
x, y, z = bert_3d[i]
ax1.scatter(x, y, z, label=f"{i+1}")
ax1.text(x, y, z, f'{i+1}', fontsize=9)
ax1.set_title("BERT-base (bert-base-uncased) Embeddings")
ax1.set_xlabel('PCA1')
ax1.set_ylabel('PCA2')
ax1.set_zlabel('PCA3')
# Sentence-BERT 결과
ax2 = fig.add_subplot(122, projection='3d')
for i, sentence in enumerate(sentences):
x, y, z = sbert_3d[i]
ax2.scatter(x, y, z, label=f"{i+1}")
ax2.text(x, y, z, f'{i+1}', fontsize=9)
ax2.set_title("Sentence-BERT (all-MiniLM-L6-v2) Embeddings")
ax2.set_xlabel('PCA1')
ax2.set_ylabel('PCA2')
ax2.set_zlabel('PCA3')
plt.tight_layout()
plt.show()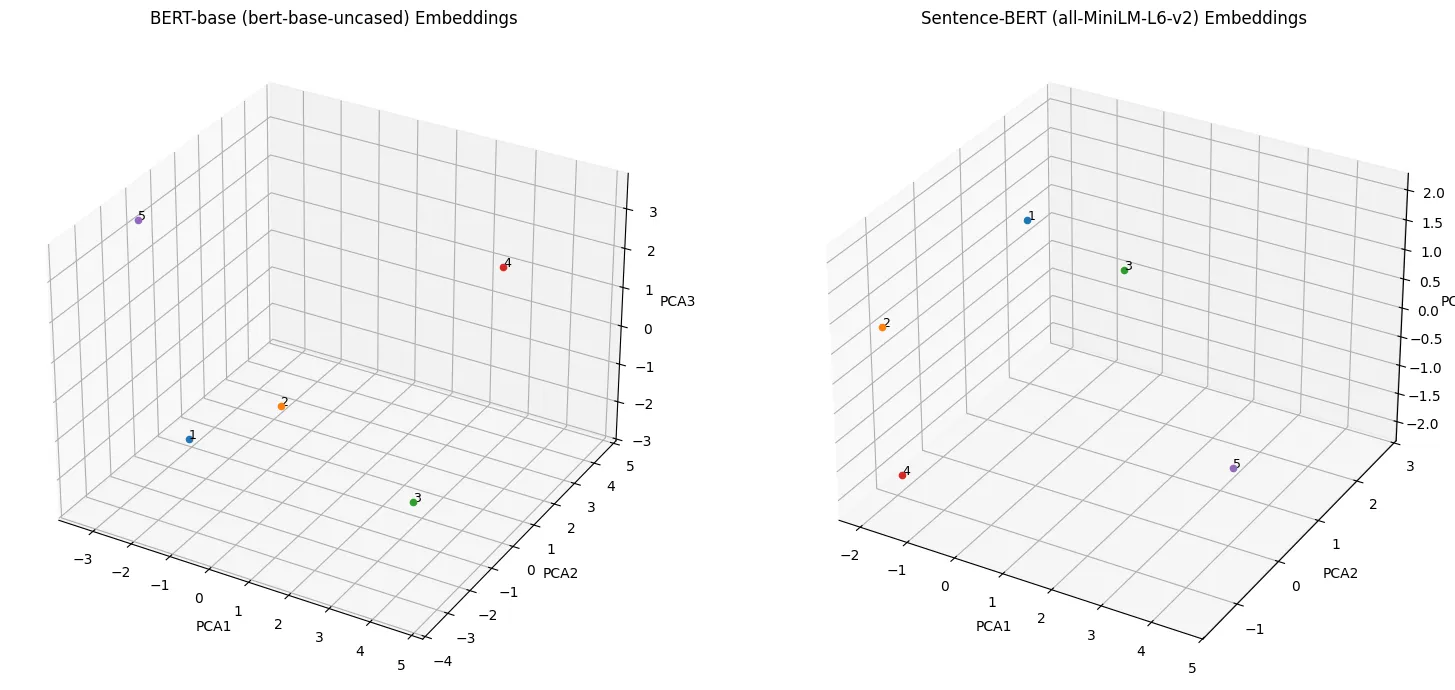
BERT-base (bert-base-uncased)에서 [CLS] 토큰은 분류 태스크용이라 문장 의미를 잘 표현하지 못하는 문제점이 존재합니다. 따라서 문장 간의 유사도를 비교하는 데에 있어서 성능이 떨어집니다.
⇒ Sentence-BERT를 활용하여 학습 과정 자체가 의미 기반으로 진행되어, 문자의 의미를 내포하는 데에 더욱 효과적입니다.
⇒ 또한, 이러한 문제점을 해결하기 위해 실습 과정에서 BERT-base (bert-base-uncased)에 mean-pooling을 적용하여 문장의 의미를 더 잘 표현하도록 유도하였습니다.
