1. 유클리디안 정렬 → 코사인 점수
# !pip install chromadbfrom sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
import chromadb
from chromadb.utils.embedding_functions import SentenceTransformerEmbeddingFunction# 1. 문서 정의
docs = [
"Python is a programming language.",
"Pandas is a library for data analysis.",
"Transformers are used in NLP tasks.",
"Vector databases store high-dimensional embeddings.",
"ChromaDB supports fast vector search."
]# 2. Sentence-BERT 모델 로딩
model = SentenceTransformer('all-MiniLM-L6-v2')벡터DB화와 유사도를 측정하기 위한 실습이므로, 'all-MiniLM-L6-v2' 모델을 사용함.
# 3. ChromaDB 클라이언트 생성
chroma_client = chromadb.Client()ChromaDB의 클라이언트 객체를 생성하여, ChromaDB와 상호작용함.
# 4. ChromaDB에 사용할 Sentence-BERT 기반 임베딩 함수 정의
embedding_function = SentenceTransformerEmbeddingFunction(model_name="all-MiniLM-L6-v2")ChromaDB가 내부적으로 문서나 쿼리를 벡터로 바꿀 때 사용할 임베딩 생성기를 지정
collection_name = "qa-docs"
# 기존 컬렉션이 존재하는지 확인
existing_collections = chroma_client.list_collections()
collection_names = [col.name for col in existing_collections]
if collection_name in collection_names:
collection = chroma_client.get_collection(name=collection_name, embedding_function=embedding_function)
print("vectorDB가 이미 존재합니다.")
else:
collection = chroma_client.create_collection(name=collection_name, embedding_function=embedding_function)
print("새로운 vectorDB를 생성합니다.")ChromaDB가 텍스트를 SBERT 기반 벡터로 변환할 수 있도록 다시 연결해주는 과정
# 6. 쿼리 정의 및 임베딩
query = "What is used in natural language processing?"
query_embedding = model.encode([query])질문을 변수로 할당하고, 이를 기존 모델을 통해서 벡터화를 진행.
# 7. ChromaDB에서 후보 문서 검색 (빠른 검색)
results = collection.query(
query_texts=[query],
n_results=3 # top-k 후보
)collection.query(...)를 통해서 주어진 쿼리 벡터(=질문)를 기반으로 가장 유사한 문서 3개를 반환
| 구성 요소 | 설명 |
|---|---|
collection.query(...) | 주어진 쿼리 벡터(=질문)를 기반으로 가장 유사한 문서들을 반환 |
query_texts=[query] | 검색 기준이 될 자연어 문장 (이 경우 사용자가 입력한 질문) |
n_results=3 | 유사도가 높은 상위 3개의 문서를 반환 (Top-K 검색) |
반환되는 결과 구조 (results 변수)
{
'ids': [['doc2', 'doc4', 'doc1']],
'documents': [[...]],
'distances': [[...]] # (L2 거리 or 유사도 기반 거리값)
}documents[0]: Top 3 유사 문장distances[0]: 각 문장과의 거리 값 (작을수록 유사함)ids[0]: 해당 문서의 ID 값
# 8. 후처리: cosine similarity 계산
print("query: ", query)
for i in range(len(results['documents'][0])):
doc_text = results['documents'][0][i]
doc_embedding = model.encode([doc_text])
sim_score = cosine_similarity(query_embedding, doc_embedding)[0][0]
print(f"\n[Top {i+1}] 문장: {doc_text}")
print(f"→ cosine similarity: {sim_score:.4f}")왜 cosine 유사도를 다시 계산하나요?
| 이유 | 설명 |
|---|---|
| ChromaDB 기본은 L2 거리 | SBERT에는 부적합 |
| Cosine이 의미 유사성에 강함 | SBERT는 cosine 유사도에 최적화 |
| 후처리로 정밀 비교 가능 | 후보 필터링 후 정확도 보완 |
💡 해당 코드의 문제점은 L2 거리 기반으로 먼저 랭킹을 매긴 뒤 cosine 유사도를 보는 구조로 정확한 의미 기반 정렬이 아니라고 생각된다.query: What is used in natural language processing?
[Top 1] 문장: Transformers are used in NLP tasks.
→ cosine similarity: 0.5670[Top 2] 문장: Python is a programming language.
→ cosine similarity: 0.3393[Top 3] 문장: Pandas is a library for data analysis.
→ cosine similarity: 0.2515
→ 따라서, 코사인 유사도를 통해서 문서의 유사도를 확인하는 코드를 다시 작성함
2. 코사인 유사도를 통한 정렬
# 1. 문서 정의
docs = [
"Python is a programming language.",
"Pandas is a library for data analysis.",
"Transformers are used in NLP tasks.",
"Vector databases store high-dimensional embeddings.",
"ChromaDB supports fast vector search."
]
doc_ids = [f"doc{i}" for i in range(len(docs))]# 2. SBERT 모델 로딩
model = SentenceTransformer('all-MiniLM-L6-v2')# 3. ChromaDB 클라이언트 및 임베딩 함수 설정
chroma_client = chromadb.Client()
embedding_function = SentenceTransformerEmbeddingFunction(model_name="all-MiniLM-L6-v2")collection_name = "qa-docs"
existing_collections = [col.name for col in chroma_client.list_collections()]
# 컬렉션 불러오거나 생성
if collection_name in existing_collections:
collection = chroma_client.get_collection(name=collection_name, embedding_function=embedding_function)
print("기존 컬렉션을 불러왔습니다.")
else:
collection = chroma_client.create_collection(name=collection_name, embedding_function=embedding_function)
print("새 컬렉션을 생성했습니다.")
# 이미 저장된 문서 확인 (문장 기준으로 중복 제거)
existing_data = collection.get()
existing_docs = set(existing_data['documents'])
# 새롭게 추가할 문장만 필터링
new_docs = [doc for doc in docs if doc not in existing_docs]
new_ids = [f"doc{i}" for i, doc in enumerate(docs) if doc not in existing_docs]
# 문서 추가
if new_docs:
collection.add(documents=new_docs, ids=new_ids)
print(f"{len(new_docs)}개의 문서를 추가했습니다.")
else:
print("추가할 문서가 없습니다.")
해당 코드를 통해서 컬렉션이 존재하면 기존의 컬렉션을 확인하고, 문서의 존재 여부를 확인하여 해당 문서가 없다는 새롭게 추가하도록 작성

# 5. 의미 검색 함수 (Chroma에서 벡터 꺼내서 직접 비교)
def semantic_search_cosine(query: str, collection, model: SentenceTransformer, top_n: int = 3):
# query 임베딩
query_embedding = model.encode([query])[0]
# Chroma에서 문서 및 벡터 가져오기
all_data = collection.get()
doc_texts = all_data['documents']
doc_ids = all_data['ids']
doc_embeddings = model.encode(doc_texts)
# cosine 유사도 계산
similarities = cosine_similarity([query_embedding], doc_embeddings)[0]
scored_docs = sorted(zip(doc_texts, similarities), key=lambda x: x[1], reverse=True)
return scored_docs[:top_n]VectorDB의 각 문장의 벡터와 새로 입력되어 비교될 벡터의 유사도를 코사인 유사도를 기준으로 비교
# 6. 실행
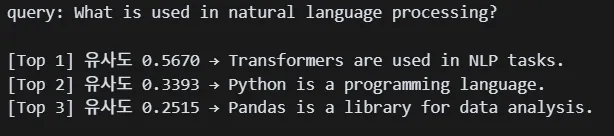
query = "What is used in natural language processing?"
results = semantic_search_cosine(query, collection, model, top_n=3)
print("query:", query)
print()
for i, (doc, score) in enumerate(results, 1):
print(f"[Top {i}] 유사도 {score:.4f} → {doc}")