Transformer 모델의 핵심
multi-head self-attention을 이용해 sequential computation을 줄여 더 많은 부분을 병렬처리가 가능하게 만들면서 동시에 더 많은 단어들 간 dependency를 모델링할 수 있다.
-
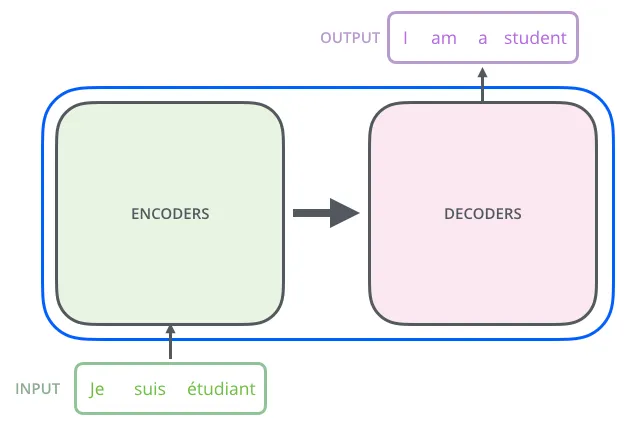
Transformer는 크게 Encoder와 Decoder로 이루어져 있음.
-
각각의 Encoding, Decoding 부분은 여러 개의 Encoder와 decoder로 구성된다.
-
하지만 그렇다고 해서 각각의 Encoder들은 weight를 공유하지 않는다.
Encoder의 구조
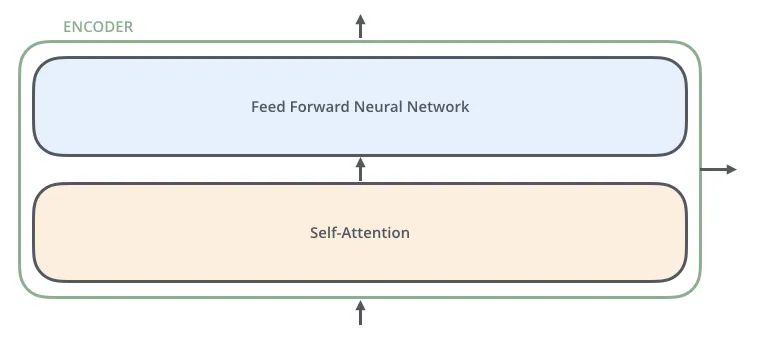
하나의 encoder를 나눠보면 위의 그림과 같이 두 개의 sub-layer으로 구성되어 있음을 알 수 있다.
그 후에 self-attention layer에서 나온 출력값은 feed-forward 신경망으로 들어가게 됨.
인코더에 들어온 입력은 일단 먼저 self-attention layer을 지나가게 되는데,
해당 layer 은 encoder가 하나의 특정한 단어를 encode 하기 위해서 입력 내의 모든 다른 단어들과의 관계를 살펴본다.
Decoder의 구조
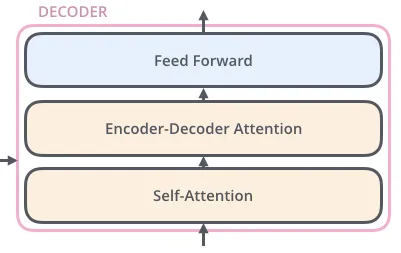
Encoder와 비숫하지만 두 개의 층 외에도 encoder-decoder attention 층을 가지고 있으며 해당 층은 decoder가 입력 문장 중에서 각 타임 스텝에서 가장 관련 있는 부분에 집중할 수 있도록 해준다.
흐름
1. 임베딩
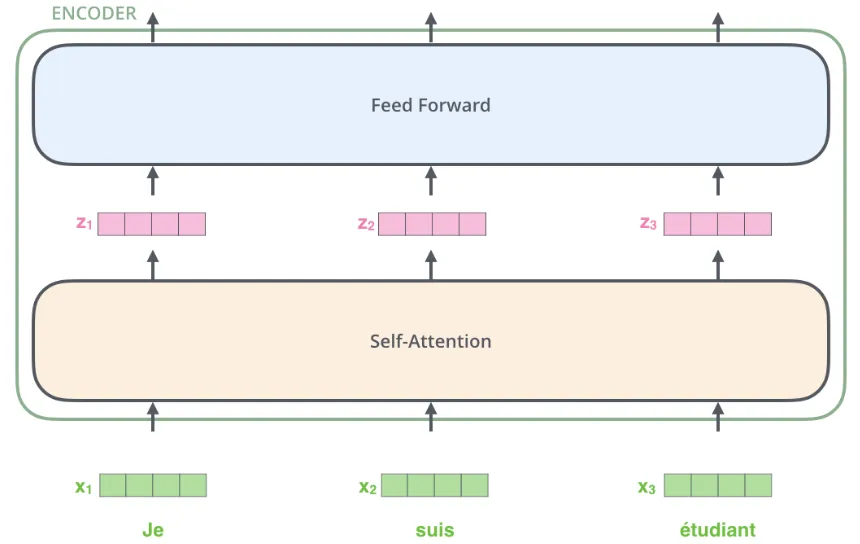
가장 밑단의 encoder 에서 단어를 Embedding하는 과정을 거친다.
입력 문장의 단어들을 embedding 한 후에, 각 단어에 해당하는 벡터들은 encoder 내의 두 개의 sub-layer으로 들어가게 된다.
- sub-layer
잔차 연결(residual connection) 및 정규화(layer normalization)와 함께 동작
인코더
Attention
문맥에서 모든 단어에 집중하는 것이 아닌, 핵심 단어라고 생각되는 단어에 집중하여 가중치를 더 두는 방법론
Self-Attention
문장 내에서 각 단어 간의 관계를 파악

모델이 입력 문장 내의 각 단어를 처리해 나감에 따라, self-attention은 입력 문장 내의 다른 위치에 있는 단어들을 보고 거기서 힌트를 받는다.
따라서 현재 타겟 위치의 단어를 더 잘 encoding 할 수 있다.
Self-Attention 계산 과정
1. 벡터 생성
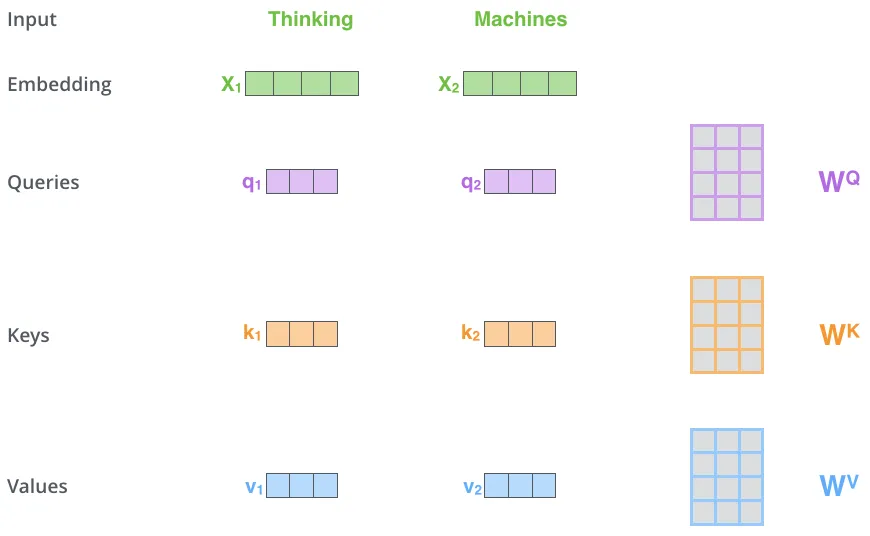
encoder에 입력된 후 임베딩된 벡터들로부터 각각 3개의 벡터를 만들어 낸다.
-
Query 벡터
-
Key 벡터
-
Value 벡터
이 새로운 벡터들이 기존의 벡터들 보다 더 작은 사이즈를 가진다.
⇒ multi-head attention의 계산 복잡도를 일정하게 만들기 위하여
2. 점수 계산
이렇게 만들어진 벡터들을 기반으로 step의 점수를 계산한다.
각각의 단어와 입력 문장 속의 다른 모든 단어들에 대해서 각각 점수를 계산
⇒ 해당 점수를 바탕으로 해당 단어의 중요도가 결정됨.
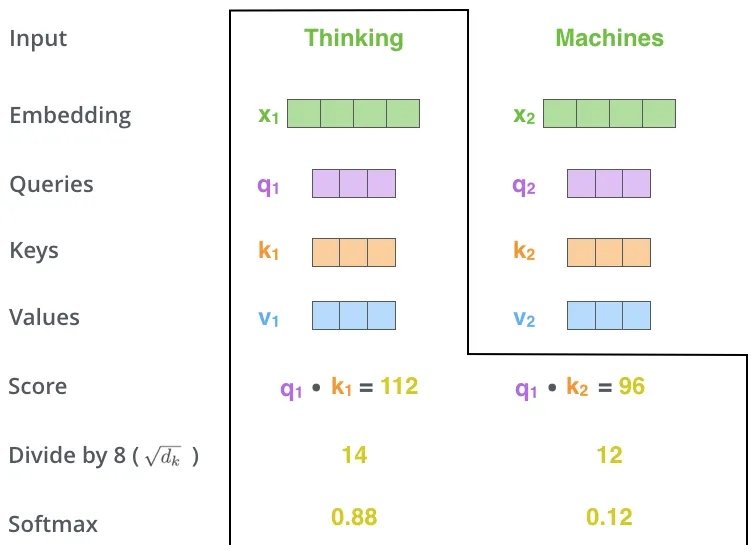
현재 단어(Thinking 중심)
- 현재 단어의 Query vector와 다른 단어의 Key vector를 내적함 ⇒ Self-Attention을 계산
- 해당 숫자들에 대하여 sqrt(size of key vector)로 나누어줌 ⇒ 안정적인 gradient를 얻고자
- softmax 함수 적용
해당 softmax 점수는 해당 단어가 Encoding되는 데에 있어서 각 단어들의 표현이 얼마나 반영될지 결정함.
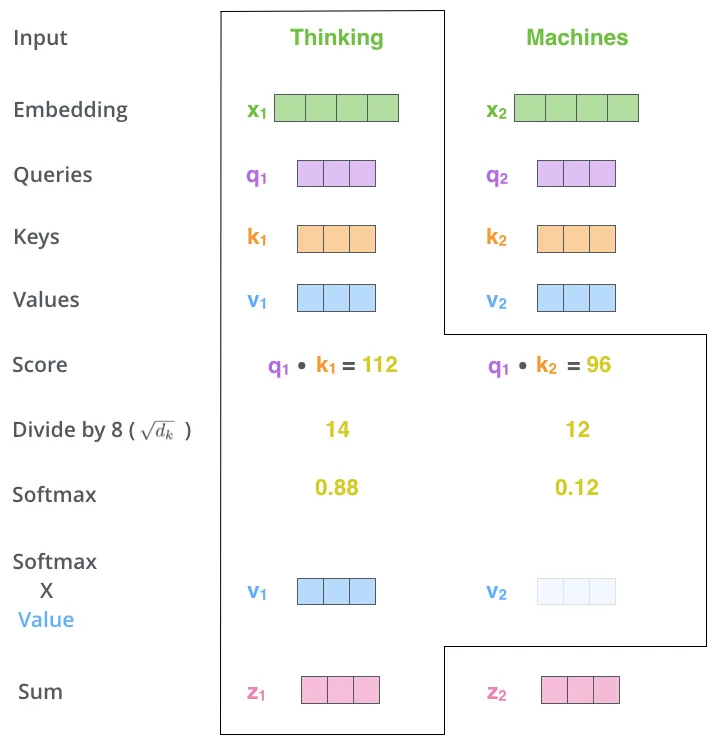
이렇게 계산된 점수에 value를 곱합 ⇒ 관련이 없는 단어들을 없애기 위함.
각 점수로 곱해진 weighted value 벡터들을 합한다.
⇒ 이 단계의 출력이 바로 현재 위치에 대한 self-attention layer의 출력.
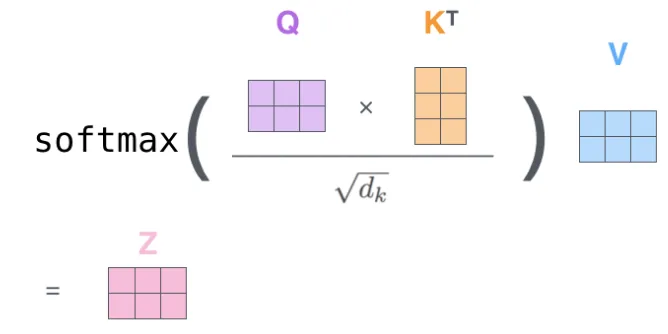
위의 과정을 다음과 같은 하나의 식으로 정리될 수 있다.
“multi-headed” attention
말 그래도 여러 개의 Head를 사용한 Attention이다. 즉, 하나의 문장 내에서도 여러 개의 위치에 집중하도록 한다.
-
모델이 다른 위치에 집중하는 능력을 확장
-
attention layer 가 여러 개의 “representation 공간”을 가짐
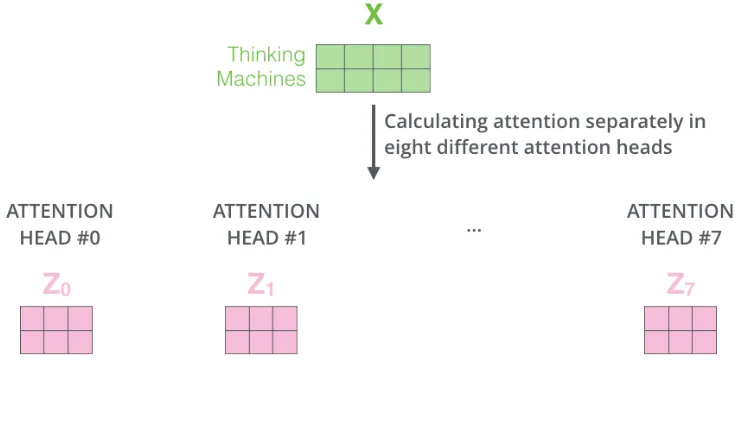
multi-headed attention을 이용함으로써 여러 개의 query/key/value weight 행렬들을 가지게 된다.
각각의 행렬들은 랜덤으로 생성되어 각자 다른 값을 가지게 되고, 결국 서로 다른 8개의 Z 행렬을 가지게 된다.
하지만 이런 식의 여러 개의 Z행렬은 바로 FeedForward layer로 보내질 수 없으므로, 하나의 행렬로 합쳐주어야 함.

모두 이어 붙여서 하나의 행렬로 만들어버리고, 그 다음 하나의 또 다른 weight 행렬인 W0을 곱합.
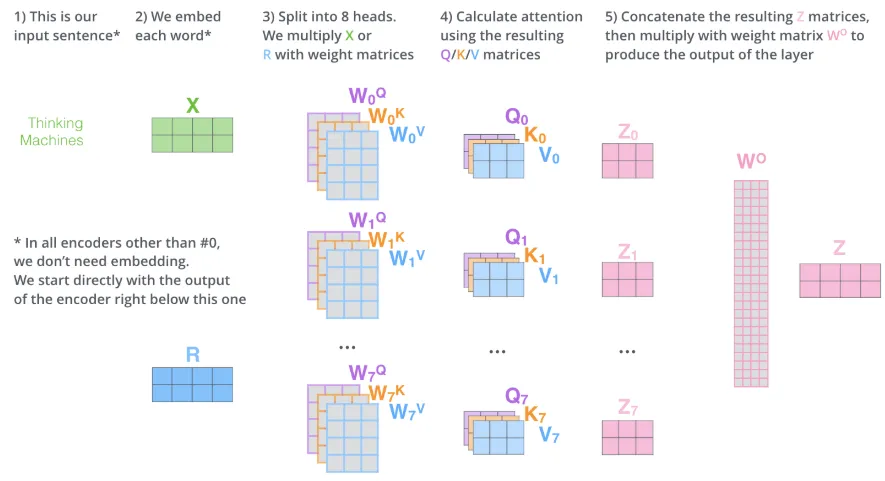
위의 이미지는 전체 과정을 하나의 이미지로 정리한 것이다. 이러한 방식으로 Multi-Head Attention이 이루어진다.

앞에서 있던 예제에 Multi-Head Attention을 적용하면, 모두에 대한 representation을 포함할 수 있다.
Positional Encoding
앞서 있던 방법들의 문제점은 문장에서 각 단어의 위치 및 순서를 고려하지 않는다는 점이다.
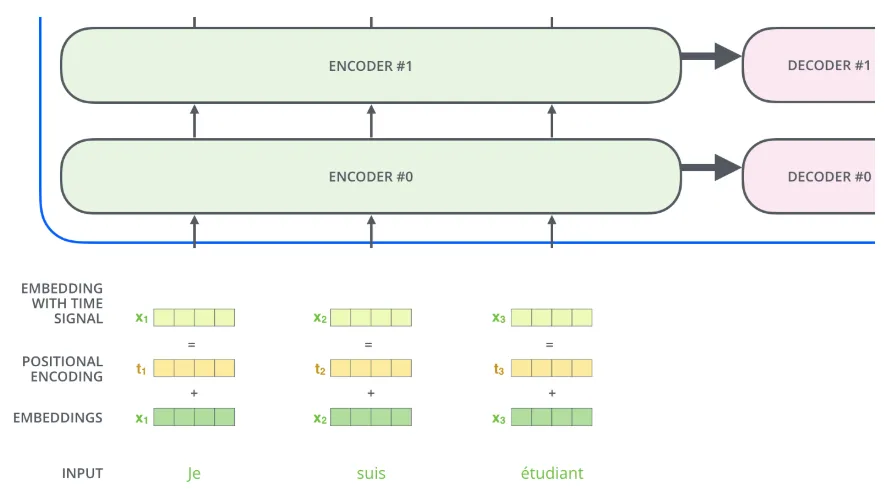
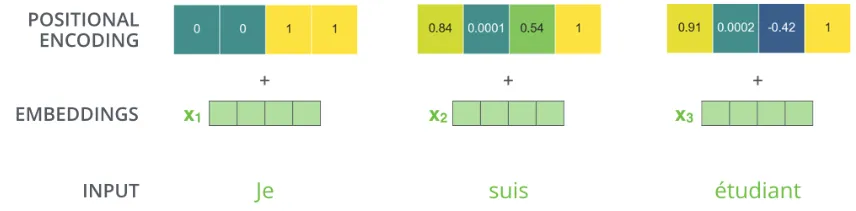
⇒ Transformer 모델은 각각의 입력 embedding에 “positional encoding”이라고 불리는 하나의 벡터를 추가한다.
⇒ 이 값들을 단어들의 embedding에 추가하는 것이 query/key/value 벡터들로 나중에 투영되었을 때 단어들 간의 거리를 늘릴 수 있다.
The Residuals
각 encoder 내의 sub-layer 가 residual connection으로 연결되어 있으며, 그 후에는 layer-normalization 과정을 거친다.
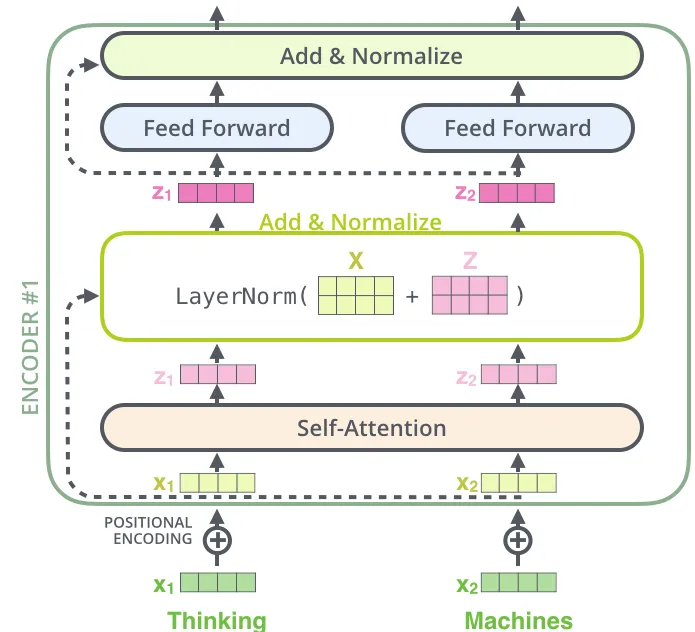
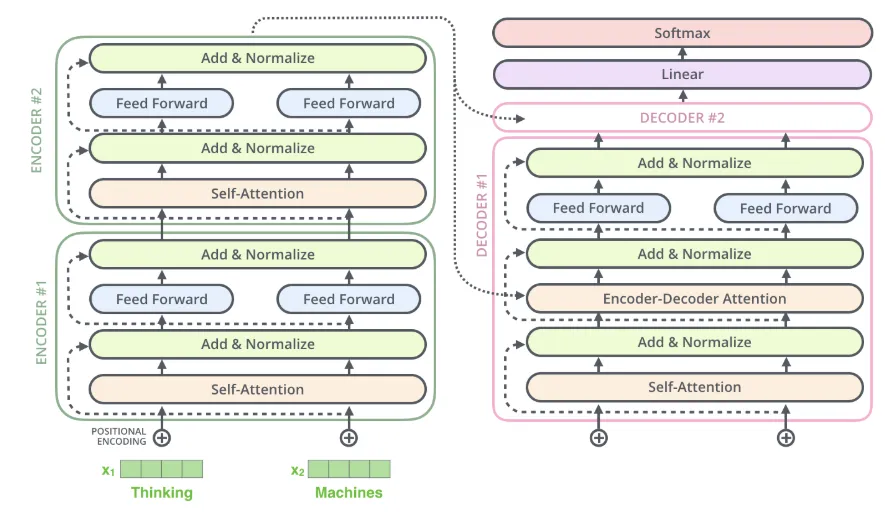
위의 이미지와 같이 Encoder와 Decoder에서 sub-layer 가 residual connection으로 연결되어 있고 각각 정규화 과정을 거친다.
디코더
인코딩
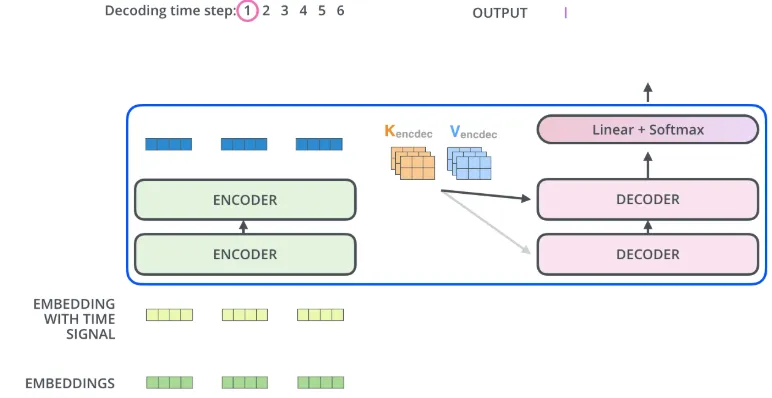
-
encoder가 먼저 입력 시퀀스를 처리하기 시작
-
그다음 가장 윗단의 encoder의 출력은 attention 벡터들인 K와 V로 변형
-
이 벡터들은 이제 각 decoder의 “encoder-decoder attention” layer에서 decoder 가 입력 시퀀스에서 적절한 장소에 집중할 수 있도록 도와준다.
디코딩
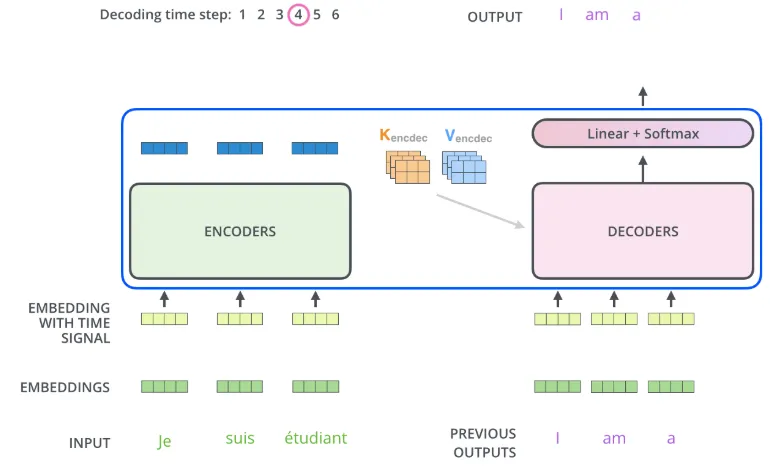
-
decoding 단계의 각 스텝은 출력 시퀀스의 한 element를 출력함
-
<end of sentence>를 출력할 때까지 반복 -
embed를 한 후 positional encoding을 추가하여 decoder에게 각 단어의 위치 정보를 더함
“Encoder-Decoder Attention” layer 은 multi-head self-attention 과 한 가지를 제외하고는 똑같은 방법으로 작동한다.
한가지 차이점은 Query 행렬들을 그 밑의 layer에서 가져오고 Key 와 Value 행렬들을 encoder의 출력에서 가져온다는 점이다.
Linear Layer과 Softmax Layer
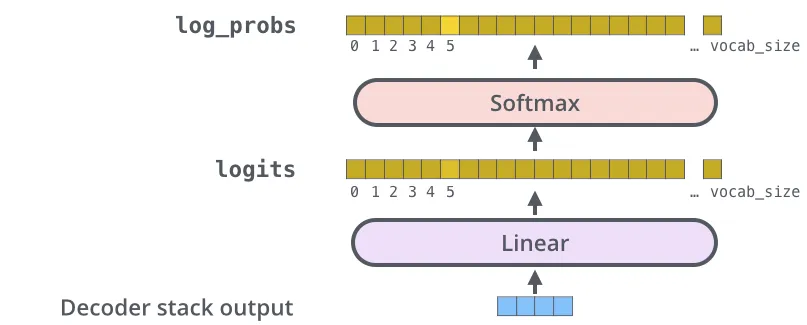
-
Linear layer
fully-connected 신경망으로 decoder가 마지막으로 출력한 벡터를 그보다 훨씬 더 큰 사이즈의 벡터인 logits 벡터로 투영시킴.
-
softmax layer
가장 높은 확률 값을 가지는 셀에 해당하는 단어가 해당 스텝의 최종 결과물로서 출력
