시계열은 준비되어 있어야 함
Rag를 이용해서, 증명된 투자자의 자료, 기록을 학습시켜 답변을 뱉어내도록
One-Hot Vector
One-Hot Vector는 주로 자연어 처리(NLP)나 머신러닝에서 카테고리형 데이터를 숫자로 변환하는 방법 중 하나입니다.
이 방법은 각 카테고리를 이진 벡터로 표현하여, 모델이 카테고리 데이터를 이해할 수 있도록 돕습니다.
One-Hot Vector의 개념
-
One-Hot Vector는 각 카테고리(예: 단어, 레이블 등)를 고유한 이진 벡터로 변환합니다. 이 벡터는 해당 카테고리가 선택되었을 때 1, 그렇지 않을 때 0으로 구성됩니다.
-
예를 들어, 세 개의 카테고리(A, B, C)가 있을 때, 각 카테고리는 다음과 같이 표현됩니다:
- A: [1 0 0]
- B: [0 1 0]
- C: [0 0 1]
One-Hot Vector의 장점
-
카테고리 데이터 처리: One-Hot Vector는 모델이 카테고리 데이터를 숫자로 이해할 수 있도록 돕습니다.
-
독립성: 각 카테고리가 독립적으로 표현되므로, 모델이 각 카테고리 간의 관계를 명확히 학습할 수 있습니다.
One-Hot Vector의 단점
-
차원 증가: 카테고리의 수가 많아질수록 벡터의 차원이 급격히 증가하여, 차원 저주 문제가 발생할 수 있습니다.
-
스파스 벡터: 대부분의 요소가 0인 스파스 벡터가 많아지므로, 메모리 사용량이 증가할 수 있습니다.
One-Hot Vector의 적용
-
단어 인코딩: 자연어 처리에서 단어를 인덱싱하여 One-Hot Vector로 변환할 수 있습니다. 예를 들어, "apple", "banana", "cherry"라는 단어가 있을 때, 각 단어는 고유한 인덱스를 가지며, 이를 One-Hot Vector로 표현할 수 있습니다.
-
레이블 인코딩: 분류 문제에서 레이블을 One-Hot Vector로 변환하여 모델에 입력할 수 있습니다.
Bag Of Word, BoW
Bag-of-Words (BoW) 모델은 자연어 처리(NLP)에서 텍스트 데이터를 숫자로 변환하는 방법 중 하나입니다.
이 모델은 각 문서를 단어의 빈도로 표현하며, 이는 텍스트의 의미를 분석하는 데 사용됩니다. BoW 모델의 주요 특징은 다음과 같습니다:
Bag-of-Words 모델의 특징
-
단어 빈도: BoW 모델은 각 문서에서 단어가 몇 번 나타나는지를 기록합니다. 이를 통해 문서의 주제나 내용을 파악할 수 있습니다.
-
단어 순서 무시: 이 모델은 단어의 순서를 무시합니다. 즉, "man bites dog"와 "dog bites man"은 동일한 BoW 표현을 가집니다.
-
문맥 정보 손실: 단어 순서를 무시하기 때문에 문맥 정보가 손실됩니다. 이는 의미 분석이나 번역과 같은 복잡한 NLP 작업에는 부적합할 수 있습니다.
Bag-of-Words 모델의 장점
-
단순성: BoW 모델은 구현이 간단하고 이해하기 쉽습니다. 이는 텍스트 분류, 감성 분석 등의 기본적인 NLP 작업에 적합합니다.
-
효율성: 대부분의 문서 벡터가 희소(sparse)하기 때문에 메모리 사용량이 적고, 효율적으로 저장 및 처리할 수 있습니다.
Bag-of-Words 모델의 단점
-
문맥 정보 부족: 단어 순서와 문맥을 무시하기 때문에, 문맥에 민감한 작업에는 적합하지 않습니다.
-
차원 증가: 고유 단어 수가 많아질수록 벡터의 차원이 증가하여, 차원 저주 문제가 발생할 수 있습니다.
TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency)는 자연어 처리(NLP)에서 텍스트 데이터를 분석할 때 사용하는 중요한 기술입니다.
이 방법은 단어의 빈도와 문서 전체에서의 희소성을 결합하여 단어의 중요도를 수치화합니다.
TF-IDF의 구성 요소
-
Term Frequency (TF):
- TF는 특정 문서에서 단어가 나타나는 빈도를 측정합니다. 이는 문서 내에서 단어가 얼마나 자주 등장하는지를 나타냅니다.

-
Inverse Document Frequency (IDF):
- IDF는 문서 전체에서 단어가 얼마나 희소한지를 측정합니다. 즉, 문서 집합(corpus)에서 단어가 얼마나 드물게 나타나는지를 나타냅니다.
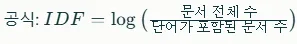
TF-IDF의 계산
TF-IDF는 TF와 IDF의 곱으로 계산됩니다. 이는 단어가 특정 문서에서 자주 등장하면서도 문서 전체에서 드물게 나타나는 경우 높은 점수를 받도록 합니다.
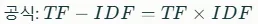
TF-IDF의 장점
-
중요 단어 강조: TF-IDF는 문서에서 중요한 단어를 강조합니다. 이는 문서의 주제나 내용을 파악하는 데 유용합니다.
-
공통 단어 감소: 문서 전체에서 자주 등장하는 공통 단어(예: "the", "and")의 중요도를 낮춰, 의미 있는 단어에 집중할 수 있습니다.
TF-IDF의 한계
- 문맥 정보 부족: TF-IDF는 단어 간의 문맥적 관계를 고려하지 않습니다. 이는 단어의 의미를 더 잘 이해하는 다른 방법(예: word embeddings)과 비교할 때 한계가 될 수 있습니다.
- 대규모 어휘 문제: 대규모 어휘를 다루는 경우, TF-IDF는 계산이 복잡해질 수 있습니다.
N-gram
N-gram은 자연어 처리(NLP)에서 텍스트 데이터를 분석하는 데 사용되는 중요한 기술입니다. N-gram은 연속된 N 개의 단어 또는 문자의 묶음을 의미하며, 이는 텍스트의 맥락을 파악하는 데 유용합니다.
N-gram의 정의
-
N-gram은 텍스트나 음성 데이터에서 연속된 N 개의 항목으로 구성된 시퀀스를 말합니다. N의 값에 따라 unigram (n=1), bigram (n=2), trigram (n=3) 등으로 구분됩니다.
-
예를 들어, 문장 "I love reading books"에서:
- Unigram: "I", "love", "reading", "books"
- Bigram: ("I", "love"), ("love", "reading"), ("reading", "books")
- Trigram: ("I", "love", "reading"), ("love", "reading", "books")
N-gram의 장점
-
맥락 정보 제공: N-gram은 단어 간의 순서와 관계를 고려하여 텍스트의 맥락을 더 잘 이해할 수 있도록 돕습니다.
-
언어 모델링: N-gram 모델은 언어 모델링에 사용되어 다음 단어가 나타날 확률을 예측하는 데 유용합니다. 이는 언어 번역, 음성 인식, 감성 분석 등 다양한 NLP 작업에 활용됩니다.
N-gram의 한계
-
차원 증가: N의 값이 커질수록 N-gram의 수는 급격히 증가하여 차원 저주 문제가 발생할 수 있습니다.
-
장거리 의존성: N-gram은 단어 간의 장거리 의존성을 잘 포착하지 못합니다. 이는 재귀 신경망(RNN)이나 변환기(Transformer)와 같은 다른 모델이 더 적합할 수 있습니다.
N-gram의 적용
-
언어 번역: N-gram 모델은 언어 번역에서 문맥을 이해하고 번역의 정확성을 높이는 데 사용됩니다.
-
감성 분석: 감성 분석에서 N-gram은 문장의 긍정 또는 부정적인 감정을 더 잘 파악할 수 있도록 돕습니다.
-
텍스트 분류: 텍스트 분류 작업에서도 N-gram이 사용되며, 이는 문서의 주제나 카테고리를 예측하는 데 유용합니다.
Word Embedding
Word Embedding은 자연어 처리(NLP)에서 단어 간의 관계와 맥락을 파악하는 데 사용되는 기술입니다. 이 방법은 단어를 dense vector로 표현하여, 단어 간의 의미적 관계를 수치적으로 나타냅니다.
Word Embedding의 개념
-
Word Embedding은 Distributional Hypothesis에 기반하여 작동합니다. 이 가설은 "유사한 맥락에서 등장하는 단어는 유사한 의미를 가진다"는 아이디어를 바탕으로 합니다.
-
Word Embedding은 각 단어를 dense vector로 변환하여, 단어 간의 의미적 관계를 공간적으로 표현합니다. 예를 들어, "apple"과 "orange"는 모두 과일이므로, 이 두 단어의 벡터는 서로 가까이 위치하게 됩니다.
Concept-Reasoning: 단어 간 관계, 맥락 파악, 순서 고려
-
단어 간 관계 파악: Word Embedding은 단어 간의 의미적 관계를 잘 포착합니다. 예를 들어, "king"과 "queen"은 의미적으로 가까운 관계를 가지며, 벡터 공간에서도 가까이 위치합니다.
-
맥락 파악: Word Embedding은 단어가 등장하는 맥락을 고려하여 단어의 의미를 더 잘 이해할 수 있도록 돕습니다. 이는 문맥에 따라 단어의 의미가 달라질 수 있음을 반영합니다.
-
순서 고려: Word Embedding 자체는 단어의 순서를 직접적으로 고려하지 않지만, contextual embeddings와 같은 후속 기술은 문장 내에서 단어의 순서와 맥락을 모두 고려하여 단어를 표현합니다.
Concept-Dense Vector: 차원 개수 줄이기
-
Sparse한 기존 문제 해결: 기존의 one-hot encoding이나 TF-IDF와 같은 방법은 sparse vector를 사용하여, 벡터의 차원이 매우 높고 대부분의 요소가 0인 문제가 있습니다. 이는 메모리 사용량이 많고, 계산이 비효율적입니다.
-
차원 개수 줄이기: Word Embedding은 dense vector를 사용하여, 벡터의 차원을 크게 줄일 수 있습니다. 예를 들어, 300차원으로 표현하는 것이 일반적입니다. 이는 계산 효율성을 높이고, 메모리 사용량을 줄입니다.
-
의도하는 차원의 개수: Word Embedding은 의도적으로 차원의 개수를 줄여, 단어 간의 의미적 관계를 더 잘 포착할 수 있도록 설계되었습니다. 이는 NLP 작업에서 중요한 장점입니다.
Word Embedding의 장점
-
의미적 관계 포착: Word Embedding은 단어 간의 의미적 관계를 잘 포착하여, NLP 작업에서 중요한 역할을 합니다.
-
차원 감소: 벡터의 차원을 줄여 계산 효율성을 높이고, 메모리 사용량을 줄입니다.
-
전이 학습: 사전 학습된 Word Embedding을 다른 NLP 작업에 적용하여, 학습 시간과 데이터 요구량을 줄일 수 있습니다.
Word Embedding의 한계
-
문맥 의존성: Word Embedding은 기본적으로 문맥에 독립적이지만, 이는 문맥에 민감한 작업에서는 한계가 될 수 있습니다. 이를 해결하기 위해 contextual embeddings가 개발되었습니다.
-
어휘 확장성: 새로운 단어나 변형된 단어에 대한 표현이 부족할 수 있습니다.
Skip-gram
Skip-gram은 Word2Vec의 두 가지 주요 아키텍처 중 하나로, 주변 단어를 사용하여 타겟 단어를 예측하는 방식으로 작동합니다.
이 방법은 동시출연 정보를 기반으로 하여 단어 간의 관계를 임베딩 공간에 투영합니다.
Skip-gram의 개념
-
동시 출연 단어: Skip-gram은 문장 내에서 타겟 단어 주변에 있는 주변 단어를 사용하여 학습 데이터를 구성합니다. 예를 들어, 문장 "I love reading books"에서 "reading"을 타겟 단어로 선택하면, 주변 단어는 "I", "love", "books"가 될 수 있습니다.
-
분류 문제로 접근: Skip-gram은 주변 단어와 타겟 단어 간의 관계를 이진 분류 문제로 변환합니다. 즉, 주변 단어가 실제로 타겟 단어 주변에 있는지 여부를 예측하는 문제로 접근합니다.
-
관계의 임베딩 공간 투영: Skip-gram은 단어 간의 관계를 벡터 공간에 투영합니다. 이는 단어 간의 의미적 관계를 공간적으로 표현하여, 유사한 맥락에서 등장하는 단어가 가까운 위치에 배치되도록 합니다.
Skip-gram의 학습 과정
-
데이터 준비: 문장에서 각 단어를 타겟 단어로 선택하고, 주변 단어를 식별합니다.
-
학습 데이터 구성: 타겟 단어와 주변 단어를 쌍으로 하여 학습 데이터를 구성합니다.
-
모델 학습: 주변 단어를 입력으로 하여 타겟 단어를 예측하는 모델을 학습합니다. 이는 주로 신경망을 사용하여 수행됩니다.
-
벡터 공간 생성: 학습 과정에서 각 단어는 벡터 공간에서 고유한 위치를 가지게 됩니다. 이 위치는 단어 간의 의미적 관계를 반영합니다.
Skip-gram의 장점
-
효율적인 학습: Skip-gram은 주변 단어를 사용하여 타겟 단어를 예측하므로, 학습 데이터가 효율적으로 활용됩니다.
-
맥락 정보 포착: Skip-gram은 단어 간의 맥락적 관계를 잘 포착하여, 의미적으로 유사한 단어가 가까운 위치에 배치됩니다.
Skip-gram의 한계
-
단어 순서 무시: Skip-gram은 주변 단어의 순서를 무시하므로, 문맥에 민감한 작업에서는 한계가 있을 수 있습니다.
-
어휘 확장성: 새로운 단어나 변형된 단어에 대한 표현이 부족할 수 있습니다.
Word2Vec의 두 가지 주요 아키텍처 중 하나가 Skip-gram인 반면, 나머지 하나는 Continuous Bag of Words (CBOW)입니다.
CBOW (Continuous Bag of Words)
-
개념: CBOW는 주변 단어를 사용하여 중간에 있는 단어를 예측하는 방식입니다. 이는 주변 단어의 분포를 통해 중간 단어의 의미를 학습합니다.
-
작동 방식: CBOW는 주변 단어의 벡터를 평균하여 중간 단어를 예측하려고 합니다. 이는 주변 단어의 순서를 무시하고, 단어 간의 의미적 관계를 학습하는 데 중점을 둡니다.
-
장점: CBOW는 Skip-gram보다 빠르게 학습될 수 있으며, 주변 단어의 맥락을 잘 포착합니다.
Skip-gram vs. CBOW
| 특징 | Skip-gram | CBOW |
|---|---|---|
| 예측 방식 | 타겟 단어로 주변 단어 예측 | 주변 단어로 타겟 단어 예측 |
| 학습 속도 | CBOW보다 느림 | Skip-gram보다 빠름 |
| 빈도 낮은 단어 | 빈도 낮은 단어에 더 적합 | 빈도 높은 단어에 더 적합 |
| 맥락 정보 | 주변 단어의 순서와 거리에 따라 가중치를 부여함 | 주변 단어의 순서를 무시 |
각 아키텍처는 서로 다른 장단점을 가지고 있으며, 사용하는 문제에 따라 적합한 아키텍처를 선택할 수 있습니다.
RNN
RNN (Recurrent Neural Network)는 순차적 데이터를 처리하는 데 사용되는 신경망 아키텍처입니다. RNN은 문장의 단어를 순차적으로 처리하여, 이전 단어의 정보를 현재 단어의 처리에 활용할 수 있습니다.
그러나 RNN은 기울기 소실 문제를 겪을 수 있으며, 이를 해결하기 위해 LSTM (Long Short-Term Memory)와 GRU (Gated Recurrent Unit)가 도입되었습니다.
RNN의 개념
-
순차적 데이터 처리: RNN은 시간 순서에 따라 데이터를 처리하며, 이는 자연어 처리(NLP)나 시계열 분석에 유용합니다.
-
기억 유지: RNN은 이전 입력의 정보를 숨은 상태(hidden state)로 유지하여, 이를 다음 입력에 활용합니다.
기울기 소실 문제
-
문제 발생 원인: RNN은 역전파를 통해 기울기를 계산할 때, 기울기가 시간 단계를 거치면서 점차 작아지는 기울기 소실 문제가 발생합니다. 이는 긴 시퀀스에서 초기 시간 단계의 정보가 손실되게 만듭니다.
-
장기 의존성 문제: 기울기 소실 문제는 RNN이 긴 시퀀스의 장기 의존성을 학습하는 데 어려움을 겪게 합니다.
LSTM과 GRU의 도입
-
LSTM (Long Short-Term Memory):
-
게이트 구조: LSTM은 forget gate, input gate, output gate를 사용하여 정보 흐름을 제어합니다. 이는 중요 정보를 장기적으로 유지하고, 불필요한 정보는 잊어버리도록 합니다.
-
기울기 소실 문제 해결: LSTM의 게이트 구조는 기울기를 안정적으로 유지하여, 장기 의존성을 더 잘 학습할 수 있도록 합니다.
-
-
GRU (Gated Recurrent Unit):
- 간소화된 게이트 구조: GRU는 LSTM보다 간소화된 구조로, reset gate와 update gate만 사용합니다. 이는 LSTM보다 계산이 효율적이며, 여전히 장기 의존성을 잘 포착합니다.
- 기울기 소실 문제 완화: GRU도 LSTM과 유사하게 기울기 소실 문제를 완화하지만, LSTM보다 덜 복잡합니다.
Sequence-to-Sequence
Sequence-to-Sequence (Seq2Seq) 모델은 두 개의 Recurrent Neural Network (RNN)를 사용하여 인코더(Encoder)와 디코더(Decoder)로 구성됩니다. 이 모델은 주로 기계 번역과 같은 시퀀스-투-시퀀스 작업에 사용됩니다.
Seq2Seq 모델의 구성
-
인코더 (Encoder):
-
역할: 인코더는 입력 시퀀스를 순차적으로 처리하여, 입력의 모든 정보를 컨텍스트 벡터(Context Vector)로 압축합니다.
-
구조: 인코더는 RNN, LSTM, GRU 등 다양한 순차적 신경망을 사용할 수 있습니다. 마지막 시점의 은닉 상태가 컨텍스트 벡터로 사용됩니다.
-
-
디코더 (Decoder):
- 역할: 디코더는 인코더에서 전달받은 컨텍스트 벡터를 사용하여 출력 시퀀스를 생성합니다. 이는 한 단어씩 순차적으로 이루어집니다.
- 구조: 디코더도 RNN, LSTM, GRU 등으로 구성될 수 있으며, 컨텍스트 벡터는 디코더의 첫 번째 은닉 상태로 사용됩니다.
Seq2Seq 모델의 작동 과정
-
인코더의 입력 처리:
-
인코더는 입력 시퀀스를 순차적으로 읽어들이며, 각 단어의 정보를 은닉 상태에 저장합니다.
-
마지막 시점의 은닉 상태가 컨텍스트 벡터로 사용됩니다.
-
-
컨텍스트 벡터 전달:
-
인코더가 모든 입력을 처리한 후, 컨텍스트 벡터를 디코더로 전달합니다.
-
이 벡터는 입력 시퀀스의 모든 정보를 압축한 형태입니다.
-
-
디코더의 출력 생성:
-
디코더는 컨텍스트 벡터를 첫 번째 은닉 상태로 사용하여, 출력 시퀀스를 한 단어씩 생성합니다.
-
각 단어는 이전 단어의 출력과 은닉 상태를 기반으로 예측됩니다.
-
Seq2Seq 모델의 장점
-
시퀀스-투-시퀀스 작업에 적합: Seq2Seq 모델은 입력과 출력의 길이가 다를 수 있는 작업에 유용합니다.
-
맥락 정보 유지: 컨텍스트 벡터를 통해 입력 시퀀스의 맥락 정보를 디코더에 전달할 수 있습니다.
Seq2Seq 모델의 한계
-
장기 의존성 문제: RNN 기반의 Seq2Seq 모델은 장기 의존성을 잘 포착하지 못할 수 있습니다.
-
정보 손실: 컨텍스트 벡터로 모든 정보를 압축하는 과정에서 일부 정보가 손실될 수 있습니다.
Attention
Attention Mechanism은 Sequence-to-Sequence (Seq2Seq) 모델에서 디코더가 인코더의 출력을 참고할 때, 전체 입력 문장의 중요도를 동적으로 조정하여 관련 정보를 선택적으로 사용할 수 있도록 하는 기술입니다.
이는 기존 Seq2Seq 모델의 정보 병목 현상을 완화하고, 장기 의존성을 더 잘 포착할 수 있도록 돕습니다.
Attention Mechanism의 작동 방식
-
Query, Key, Value 벡터:
-
Query (Q): 디코더의 현재 상태를 나타내는 벡터입니다. 이는 디코더가 현재 어떤 정보를 요청하는지를 나타냅니다.
-
Key (K): 인코더의 각 시간 단계의 출력을 나타내는 벡터입니다. 이는 인코더가 제공하는 정보의 레이블 역할을 합니다.
-
Value (V): 인코더의 각 시간 단계의 실제 정보를 담고 있는 벡터입니다. 이는 인코더가 제공하는 실제 데이터입니다.
-
-
Attention Score 계산:
-
Attention Score는 Query와 Key 간의 유사도를 계산하여 얻습니다. 이는 일반적으로 내적(dot product)이나 다층 퍼셉트론(MLP)을 통해 수행됩니다.
-
계산된 Score는 Softmax 함수를 통해 정규화되어, 각 Key에 대한 가중치(Attention Weight)가 됩니다.
-
-
Context Vector 생성:
-
Attention Weight와 Value 벡터를 곱한 후, 모든 시간 단계의 결과를 합하여 Context Vector를 생성합니다.
-
이 Context Vector는 디코더가 현재 출력을 생성할 때 사용할 관련 정보를 담고 있습니다.
-
Attention Mechanism의 장점
-
장기 의존성 해결: Attention Mechanism은 디코더가 입력 시퀀스의 모든 부분을 참고할 수 있게 하여, 장기 의존성을 더 잘 포착합니다.
-
정보 병목 현상 완화: 기존 Seq2Seq 모델에서 인코더의 출력을 단일 Context Vector로 압축하는 문제를 해결합니다.
-
효율적인 정보 사용: 관련 정보에 더 높은 가중치를 부여하여, 모델이 효율적으로 정보를 사용할 수 있도록 합니다.
