쿼리
단순 키워드 검색이 아닌 텍스트, 이미지, 오디오 등의 의미 기반 유사성 검색
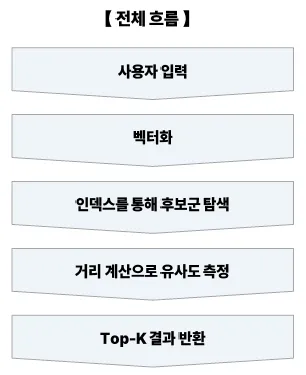
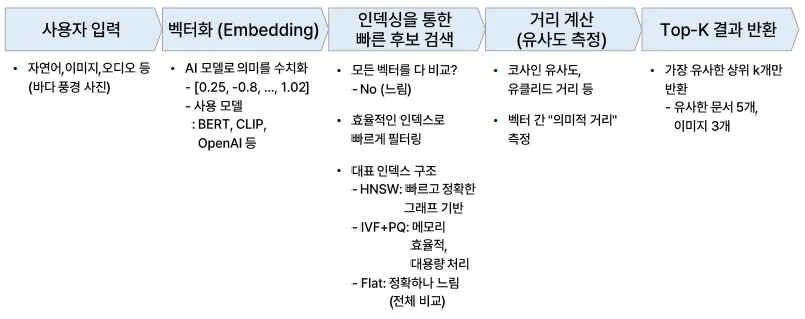
벡터 DB 쿼리 단계
전통 DB와 벡터 DB 비교
| 구분 | 전통 RDB | 벡터 DB |
|---|---|---|
| 목적 | 조건 일치 검색 | 의미 기반 유사 검색 |
| 쿼리 방식 | SQL | 벡터 유사도 기반 |
| 인덱스 | B-Tree 등 | HNSW, IVF 등 |
| 반환 결과 | 일치하는 값 | 유사한 결과 (확률/유사도 기반) |
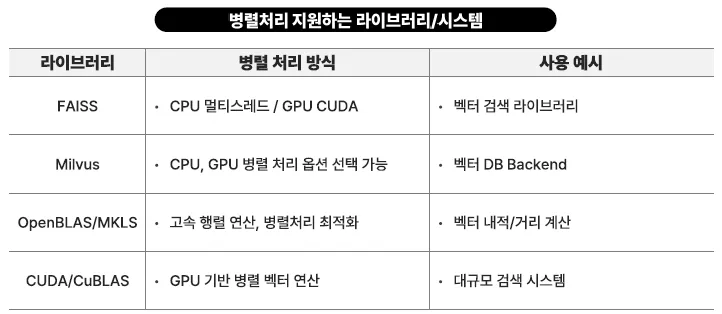
병렬 처리와 분산 시스템 - 병렬 처리
병렬처리 개요
| 항목 | 내용 |
|---|---|
| 정의 | 하나의 머신(서버) 안에서 여러 개의 CPU 또는 GPU 코어가 동시에 계산을 수행하는 것 |
| 필요 이유 | - 하나의 쿼리 벡터 실행 시 - 수백만 개 벡터와 유사도 계산 필요 - 벡터 간 연산은 128~1536차원 사이의 수치 연산 반복 → 거리 계산 반복으로 인해 병렬 처리 필수 |
이런 연산을 하나하나 직렬로 처리하면 느려서 병렬처리 필요
병렬 처리 방식
| 처리 방식 | 설명 |
|---|---|
| CPU 멀티스레드 | 여러 CPU 코어가 벡터 계산을 나눠서 처리 |
| GPU 가속 | 수천 개의 코어를 가진 GPU가 병렬로 벡터 연산 수행 |
| SIMD 명령어 | CPU 내부에서 동일 명령을 동시에 실행 (예: AVX, SSE) |
예시
- 사용자가
query_vector하나로 1,000만 개 벡터와 유사도 비교 요청 시- 직렬 처리: 1 CPU가 1개씩 비교 → 시간 매우 오래 걸림
- 병렬 처리 예시:
- 8코어 CPU → 코어당 125만 개씩 병렬 비교
- GPU 수천 개 코어 → 병렬 벡터 내적 연산으로 훨씬 빠름
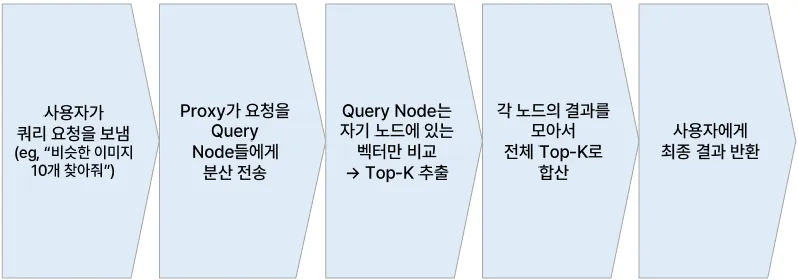
병렬 처리와 분산 시스템 - 분산 시스템
분산 시스템 개요
| 항목 | 내용 |
|---|---|
| 정의 | 벡터 데이터를 여러 대의 서버(노드)에 나눠서 저장하고, 검색 요청도 동시에 분산해서 처리하는 구조 |
| 필요 이유 | - 벡터 데이터 증가 시 저장용량/연산량이 기하급수적으로 증가 - 단일 서버의 처리 능력(CPU, 메모리 등)에 한계 존재 - 예: 벡터 1개가 512차원, float32(4byte)일 때 → 1억 개 벡터: 512 × 4 × 100,000,000 = 200GB → 인덱스 및 메타데이터 추가 시 수백 GB ~ TB급 용량 필요 |
여러 서버에 나눠서 저장하고 동시에 검색하는 구조가 필요
구성요소 및 역할
| 구성요소 | 역할 |
|---|---|
| Proxy/Router | 클라이언트 요청을 적절한 노드에 분배 |
| Query Node | 쿼리 요청을 처리하고 유사도 계산 |
| Data Node | 벡터 데이터를 저장 |
| Index Node | 벡터 인덱스 생성 및 유지 |
| Coordinator | 전체 클러스터 상태를 관리 |
예시
- 1억 개 벡터 데이터를 10대의 서버에 나눠 저장
- 쿼리가 들어오면 10대 서버가 동시에 검색 수행
- 각 서버는 1,000만 개씩 검색 → 속도 10배 향상
- 결과는 병합해서 최종 Top-K 반환

요약: 병렬처리 vs 분산 시스템
| 항목 | 병렬 처리 | 분산 시스템 |
|---|---|---|
| 처리 위치 | 1대 서버 내부 | 여러 대의 서버 간 |
| 사용 리소스 | CPU, GPU 코어 | 전체 클러스터 자원 |
| 확장 방법 | 코어 수 늘리기 | 서버 수 늘리기 |
| 장점 | 빠른 연산, 적은 네트워크 비용 | 고용량 데이터 처리, 높은 확장성 |
요약 정리:
- 벡터 검색은 수많은 벡터 간 고차원 거리 계산으로 연산량이 큼
- 병렬 처리는 한 서버 안에서 연산을 빠르게 → CPU/GPU 활용
- 분산 시스템은 여러 서버에 데이터를 나눠 → 속도 및 저장 확장
- 실제 서비스에서는 두 가지를 함께 활용하는 것이 일반적
- 예: Milvus + CUDA + 클러스터 구성
