추천 시스템
벡터가 왜 필요할까?
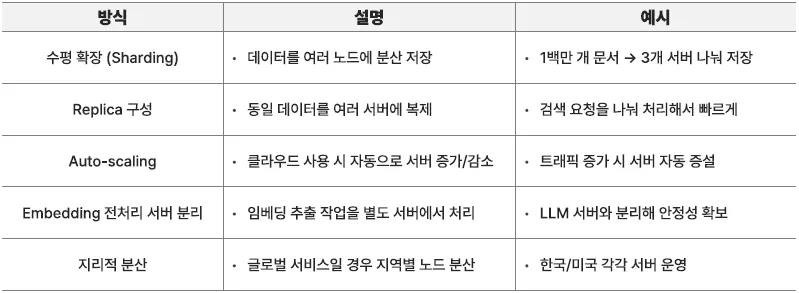
1. 기존 추천 시스템의 한계
- 명시적 행동 기반 추천 (예: A를 샀으니 B 추천)
- 유저의 구매 이력 + 제품 속성 조합으로 추천 → 의미 기반 유사성 파악에 어려움 존재
벡터 기반 추천 시스템
| 항목 | 내용 |
|---|---|
| 정의 | 사용자의 행동이나 관심사를 벡터로 표현하고, 제품/콘텐츠도 벡터로 만들어 의미상 가까운 것을 추천 |
| 예시 | 유저 A가 본 영화 → 로맨틱 코미디 → 해당 벡터 생성 → 유사한 영화 벡터 추천 (장르 다르지만 분위기 유사 등) |
작동 방식
- 사용자 행동 데이터 수집 (클릭, 시청, 좋아요 등)
- AI 모델로 사용자와 아이템을 임베딩 (Embedding)
- 벡터 DB에 저장
- 유저가 들어오면 해당 유저의 벡터와 가장 유사한 아이템 벡터 검색
장점
- 콜드 스타트 문제 해결: 행동 데이터 적어도 의미 기반 추천 가능
- 의미 기반 추천: 카테고리, 장르가 달라도 분위기 유사한 콘텐츠 추천 가능
- 실시간 반영: 벡터 변화 반영 시 즉시 추천 가능
실제 사용 예시
| 플랫폼 | 활용 방식 |
|---|---|
| Netflix | 시청 기록 → 벡터 → 유사 콘텐츠 추천 |
| Spotify | 음악 벡터 → 분위기 유사 음악 추천 |
| 쿠팡/아마존 | 상품 벡터 + 유저 행동 → 유사 상품 추천 |
이미지 검색
벡터 기반 이미지 검색
정의
- 이미지 자체를 AI 모델로 분석하여 벡터로 변환
- 이미지의 시각적 특성을 수치로 표현
- 쿼리 이미지와 유사한 벡터를 찾아 의미적으로 유사한 이미지 검색
예시
- 사용자가 사진을 업로드 → AI 모델이 벡터로 변환 → DB에 있는 수백만 벡터 중 가장 유사한 5개 이미지 검색 예: "강아지가 모래사장에서 노는 사진" → 비슷한 분위기의 강아지 사진 반환
기존 이미지 검색 방식의 한계
- 텍스트 기반 검색: 이미지에 태그나 파일명이 있어야 검색 가능 예: "노을 사진" →
sunset.jpg또는#sunset태그 필요 → 텍스트 정보 없으면 검색 불가
작동 방식
- 이미지 → AI 모델(CNN, CLIP 등) → 고차원 벡터
- 벡터 DB에 저장
- 쿼리 이미지 → 동일 모델로 벡터화
- 쿼리 벡터와 가장 유사한 벡터를 Top-K로 검색
장점
- 텍스트 없이도 검색 가능 (이미지 그 자체로 검색)
- 색감, 구성, 분위기 등의 시각적 유사성까지 반영
- 패션, 디자인, 건축 등 비정형 시각 데이터에 강력

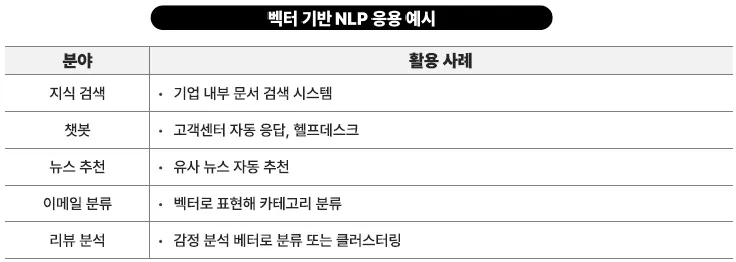
자연어 처리 응용
텍스트 벡터화란?
- 벡터화(embedding): 문장, 문서, 질문 등을 AI 모델을 통해 숫자의 배열(벡터)로 변환
- 이 숫자 배열은 텍스트의 의미, 감정, 주제, 스타일 등을 반영
주요 응용 분야
| 분야 | 설명 |
|---|---|
| 의미 기반 검색 (Semantic Search) | - 사용자가 입력한 문장의 의도에 맞는 결과를 검색 - 예시: “휴가용 가벼운 책 추천” → 여행 에세이, 소설 추천 - 과학 기술 관련 서적 → 기술 서적 목록 출력 |
| 유사 문서 찾기 | - 논문, 기사, 리뷰 등에서 비슷한 문서 자동 연결 - 예시: 특정 논문과 관련된 다른 논문 자동 찾기 |
| 챗봇 응답 검색 (RAG 방식) | - 질문 → 벡터화 → 벡터 DB에서 유사한 문서 검색 - 검색된 문서를 LLM에 넣어 답변 생성 → 최신 정보 + 정확한 응답 가능 (예: ChatGPT with Retrieval) |
대표 벡터 모델
| 모델 | 용도 |
|---|---|
| BERT | 문장/단어의 문맥 벡터화 |
| Sentence-BERT | 문장 간 유사도 계산에 특화 |
| OpenAI Embedding | 문장 → 벡터 변환에 강력 |
| CLIP | 텍스트 + 이미지 공동 벡터화 |
이 분야 공통점
- 텍스트 / 이미지 / 사용자 / 상품 → 벡터로 변환
- 벡터 DB에 저장
- 유사도 기반 검색 수행
벡터 DB는 AI 시스템의 의미 기반 검색 엔진 역할을 수행함.
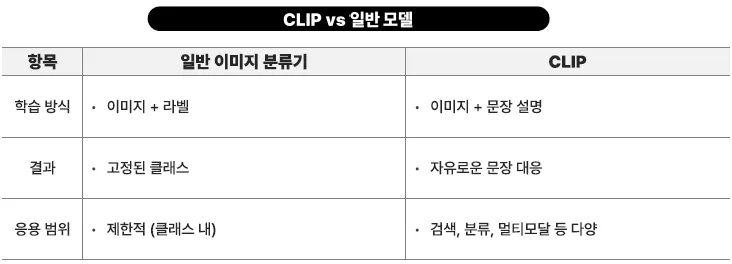
CLIP
OPENAI가 만든, 텍스트와 이미지를 함께 이해할 수 있는 AI 모델

CLIP은 이미지와 텍스트를 같은 공간(벡터 공간)에 매핑

CLIP은 2개의 인코더를 가지고 있음
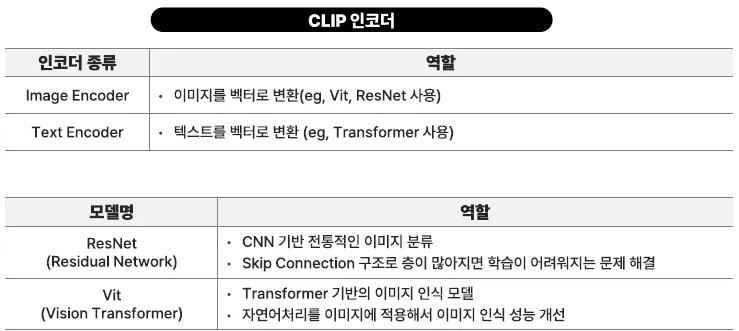
CLIP은 텍스트와 이미지를 같은 벡터 공간에서 비교할 수 있기 때문에 텍스트로 이미지 찾기, 이미지로 텍스트 찾기 둘 다 가능
import clip
import torch
from PIL import Image
model, preprocess = clip.load("ViT-B/32")
image = preprocess(Image.open("cat.jpg")).unsqueeze(0)
text = clip.tokenize(["a cat", "a dog", "a car"])
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
# 유사도 계산 (Cosine similarity)
similarity = (image_features @ text_features.T).softmax(dim=-1)
print(similarity)대규모 언어 모델 LLM 과의 통합
RAG

- 필요한 정보를 먼저 찾아오고
- 그걸 참고해서 답변을 생성하는 방식

RAG를 구성하는 핵심 요소
| 구성 요소 | 역할 | 쉽게 말하면 |
|---|---|---|
| 질문 임베딩 (Embedding) | 질문을 숫자(벡터)로 변환 | "의미를 계산하는 방식" |
| 벡터 DB | 의미가 비슷한 문서를 저장하고 검색 | "AI용 검색창" |
| LLM (GPT 등) | 문서를 참고해서 응답 생성 | "지식과 언어 능력 담당" |
장점
| 항목 | 설명 |
|---|---|
| 최신 정보 사용 가능 | 실시간으로 새로운 문서를 검색해서 반영 가능 |
| 사내 문서 기반 응답 | 기업 내부 매뉴얼, 정책 등을 연결해 정확한 응답 가능 |
| 환각(Hallucination) 줄이기 | LLM이 "모른다" 하지 않고, 문서를 기반으로 응답하여 신뢰도 향상 |
| 유연한 시스템 확장 | 모델을 다시 학습할 필요 없이 문서만 바꾸면 됨 |
LLM 모델의 제약으로 벡터 DB가 필요
| LLM 한계 | 설명 |
|---|---|
| 오래된 지식 | 최신 뉴스나 문서는 알지 못함 |
| 긴 문서 기억 어려움 | 긴 텍스트를 한 번에 모두 입력할 수 없음 |
| 헛소리(?) 가능성 | 모르면 그럴듯한 거짓말을 함 (AI 환각 현상) |
이 문제를 해결하기 위해 등장한 것이 바로 벡터 데이터베이스 + RAG 조합
벡터 Database 구축 및 관리
벡터 저장 공간 구분
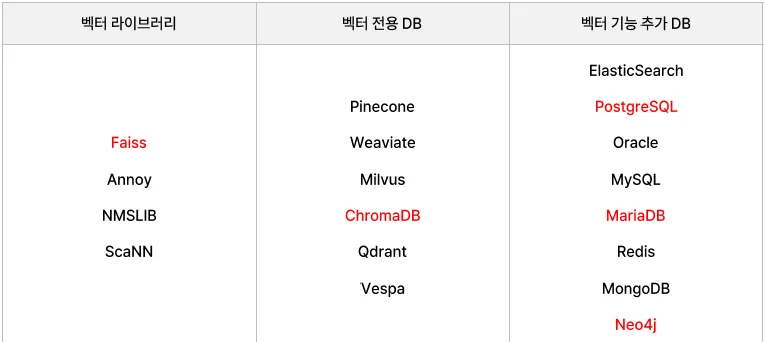
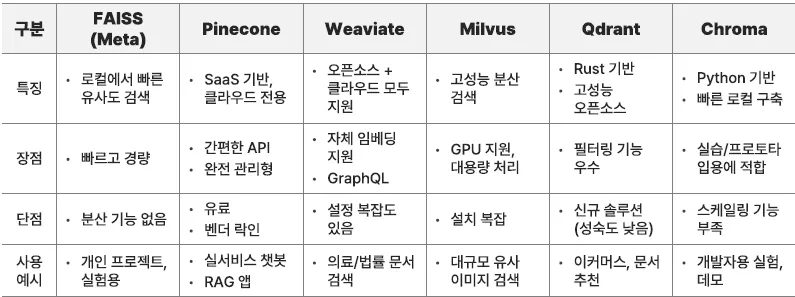
주요 벡터 Database 솔루션 비교
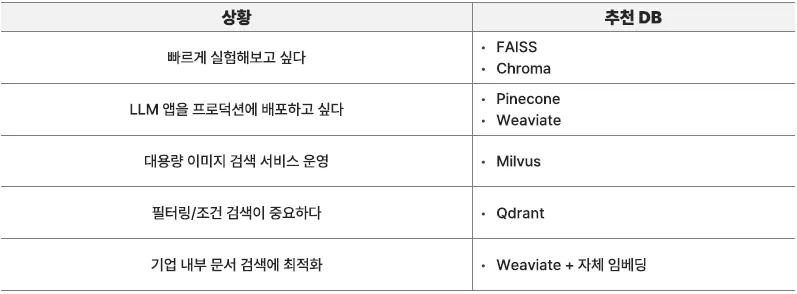
성능 최적화 전략
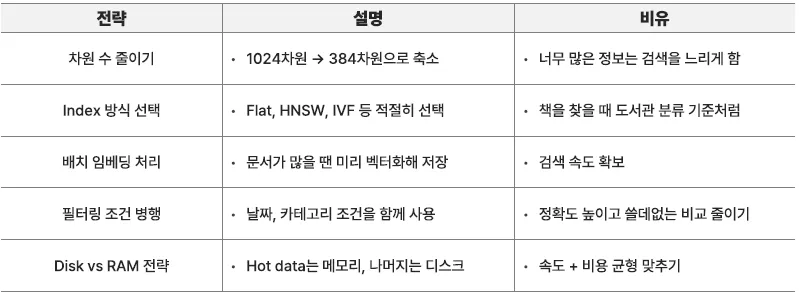
스케일링 전략, 규모 확장