검색프로세스
벡터 DB는 텍스트, 이미지, 음성 등을 벡터(숫자 배열)로 변환한 뒤, 비슷한 벡터끼리 검색하므로 검색 요청 시 4단계를 거쳐 결과를 출력
1. 쿼리 임베딩 생성 (Query Embedding)
-
검색어나 질문을 벡터로 변환하는 단계
-
사용자가 입력한 텍스트(예: "붉은 드레스")를 벡터로 변환
-
NLP 또는 멀티모달 AI 모델(BERT, CLIP 등)을 사용
-
예시 임베딩 결과:
[0.12, -0.45, 0.89, ...](보통 128~768차원 이상)
검색 품질은 사용하는 모델에 따라 달라짐
2. 인덱스 트리 탐색 (Index Tree Search)
-
전체 벡터 중에서 빠르게 후보 벡터를 찾기 위한 구조적 탐색
-
ANN 알고리즘 사용 (예: HNSW, IVF, PQ 등)
검색 속도 최적화에 핵심적인 역할
3. 유사도 스코어 계산 (Similarity Score Calculation)
-
쿼리 벡터와 후보 벡터 간의 유사도 또는 거리 계산
-
주요 방법:
- Cosine Similarity (0~1): 각도 기반 유사성
- L2 거리: 유클리드 거리 (작을수록 유사)
- Dot Product: 내적 계산
-
예: 코사인 유사도가 0.92면 거의 비슷한 것으로 간주
4. 결과 정렬 및 필터링 (Ranking & Filtering)
-
유사도 점수 기준으로 정렬 (Top-K 등)
-
필터링 조건 적용 가능 (예: 가격, 브랜드, 카테고리 등)
-
메타데이터 기반 필터링도 가능
하이브리드 검색 : 벡터 + 메타데이터 결합
“벡터 검색 결과 + 조건 기반 필터”를 함께 사용하는 방식
예시 쿼리
“붉은 색 드레스 + 가격 < 5만 원”
처리 방식
- “붉은 색 드레스” → 텍스트 벡터화 → 유사도 검색 수행
- 가격 < 50,000 → 메타데이터 필터링 조건으로 적용
동작 순서
- 쿼리
"붉은 드레스"를 임베딩 → 벡터 A 생성 - 벡터 A와 데이터셋 내 임베딩들과 유사도 비교
- 유사도 상위 결과 Top-K 추출
- 그 중 가격이 5만 원 미만인 항목만 필터링
- 최종 결과 반환
즉, 벡터 기반 의미 검색과 속성 기반 필터링이 결합된 형태로, 텍스트 의미 유사성과 숫자 조건을 함께 만족하는 결과를 효율적으로 추출

벡터 DB애서 하이브리드 검색 구현
[하이브리드 검색 구현 가능 대상]
- 벡터 인덱싱
- ANN 탐색
- 메타데이터 필터링 쿼리
- 정렬 및 랭킹 전략
[요약]
| 단계 | 설명 |
|---|---|
| 1. 쿼리 임베딩 | 입력 쿼리를 벡터로 변환 |
| 2. 인덱스 탐색 | ANN 인덱스를 통해 빠르게 후보 벡터 탐색 |
| 3. 유사도 계산 | 코사인, L2, 내적 등을 이용하여 유사도 측정 |
| 4. 결과 정렬/필터 | 유사도 순 정렬 후 메타 조건으로 필터링 |
[하이브리드 검색]
- 설명: 의미 기반 + 구조 기반 필터를 동시에 사용
- 장점: 정확도 향상, 사용자의 외도(의도 외 조건)까지 반영 가능
- 예시:
"빨간색 가방"+ 브랜드 = 구찌- 가격 < 100만 원
Qdrant 기반 벡터 DB 실습
- 사전 설치
pip install qdrant-client sentence-transformers- 예제 코드
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct, Filter, FieldCondition, Range
from sentence_transformers import SentenceTransformer
# 1. 벡터화 모델 로딩 (텍스트 -> 벡터)
encoder = SentenceTransformer('all-MiniLM-L6-v2')
# 2. Qdrant 클라이언트 연결 (로컬 or 클라우드)
client = QdrantClient(host='localhost', port=6333)
# 3. 예시 데이터 (신발 정보 + 가격)
products = [
{"id": 1, "name": "노란색 운동화", "price": 30000},
{"id": 2, "name": "검정 구두", "price": 70000},
{"id": 3, "name": "노란색 슬리퍼", "price": 45000},
{"id": 4, "name": "빨간색 운동화", "price": 40000}
]# 4. 벡터 생성 및 업로드
points = []
for p in products:
벡터 = encoder.encode(p["name"]).tolist()
payload = {"name": p["name"], "price": p["price"]}
points.append(PointStruct(id=p["id"], vector=벡터, payload=payload))
# 5. 컬렉션 생성 및 데이터 업로드
collection_name = "shoes"
client.recreate_collection(
collection_name=collection_name,
vector_size=len(points[0].vector),
distance="Cosine"
)
client.upsert(collection_name=collection_name, points=points)→ 유사도는 코사인을 기준으로 측정함
# 6. 검색 쿼리: "노란색 신발" + 가격 < 50000
query_text = "노란색 신발"
query_벡터 = encoder.encode(query_text).tolist()
# 메타데이터 필터 정의
price_filter = Filter(
must=[
FieldCondition(
key="price",
range=Range(lt=50000)
)
]
)# 7. 벡터 + 필터 검색 (하이브리드)
results = client.search(
collection_name=collection_name,
query_vector=query_벡터,
limit=3,
query_filter=price_filter
)
# 8. 결과 출력
for r in results:
print(f"{r.payload['name']} | {r.payload['price']}원 | 유사도: {r.score:.4f}")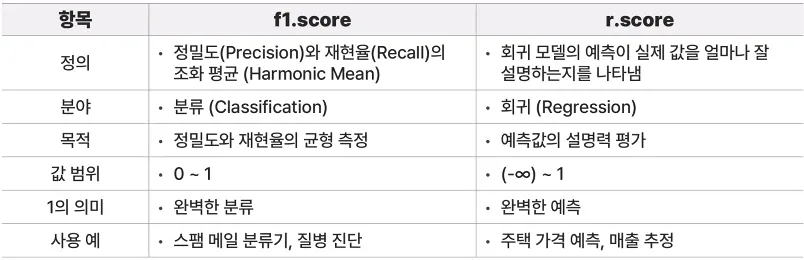
벡터 DB 검색 방식 비교
키워드 검색
단어의 등장 빈도가 비슷한 문서를 검색하거나, 등장 여부를 필터링하여 검색하는 방식
[키워드 검색]
■ 개념
- 사용자가 입력한 정확한 단어(키워드)가 포함된 문서를 찾는 전통적인 검색 방식
- 일반적으로 역 색인 구조 사용
- 입력된 단어와 일치하는 문서를 색인에서 빠르게 조회
■ 기술적 구성
- 텍스트 토큰화 → 불용어 제거(Stopword removal) → 소문자 변환 등 전처리
- 사용자 쿼리도 동일 방식으로 처리하여 색인과 매칭
■ 예시
"인공지능 기술 동향"→ 문서 내 일치 문장 검색"2023년 AI 기술이 급속히 발전"→ 연도 포함 문서 매칭"BERT"→ 기술 키워드 필터링"AI 관련 정보 사례"등 명확 키워드 기반 문장
■ 장점
- 빠른 검색 속도 (역색인 기반)
- 구현이 용이하고 단순
■ 단점
- 동의어, 오탈자, 유사 표현 인식 어려움
- 의미나 문맥 이해 없이 문자 그대로만 매칭되므로 질의 의도 파악이 어렵다
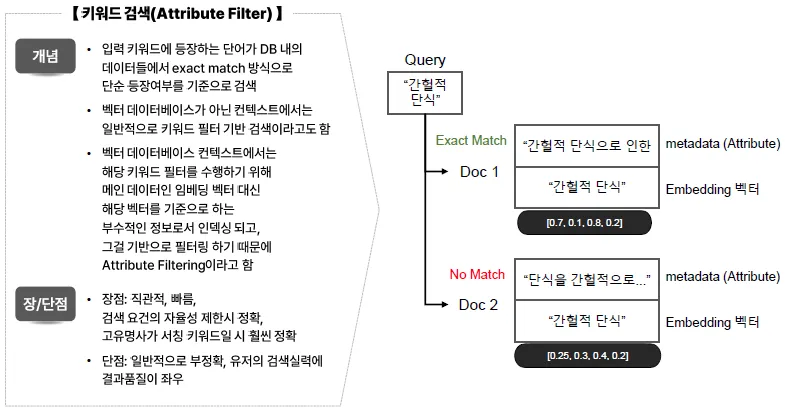
[보완 방식]

- Attribute Filter (속성 필터 검색)
- 검색 조건으로 특정 속성(attribute, column, field)의 값을 기준으로 필터링
- SQL의
WHERE절과 유사 - 예:
가격 < 50000,카테고리 = '신발'
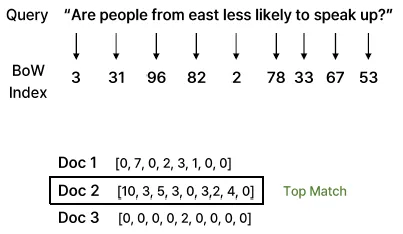
- Sparse 벡터 검색 (희소 벡터 검색)
- 텍스트 문서를 단어 중심의 희소 벡터(sparse vector)로 표현하여 검색
- 대표 알고리즘: TF-IDF, BM25 등
- 단어 등장 빈도 기반으로 관련 문서 검색
키워드 검색 (Sparse 벡터 Search)
개념
- 단순 키워드 기반 필터 검색보다 한 단계 진화한 형태의 키워드 검색 방식
- 문서 내 단어 출현 빈도를 기반으로 문서를 벡터로 표현
구성 방식
- 문서 전체를 대상으로 단어 은행(Vocabulary)을 만들고, 이를 기반으로 n-gram 형태로 벡터화
- *Sparse(희소)**하다고 불리는 이유는 대부분의 단어가 해당 문서에 존재하지 않기 때문에 0이 많은 벡터가 생성되기 때문
장점
- 단어 간 유사성보다는 정확한 단어 매칭에 초점
- 단어가 벡터 차원별로 매핑되고 빈도수로 표현되므로 해당 단어의 중요도 반영 가능
- 단순히 등장 여부뿐만 아니라 빈도 기반의 정밀한 모델링 가능
대표 모델
- BM25, SPLADE 등이 대표적인 sparse 벡터 검색 모델
Sparse 벡터 Search - BM25
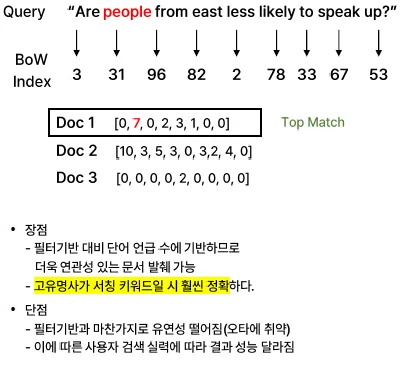
개념
- TF-IDF 기반 메커니즘을 활용한 키워드 중심 검색 모델
- TF (Term Frequency): 문서에서 특정 단어가 얼마나 자주 등장하는지를 기반으로 n-gram 형태로 벡터화
- IDF (Inverse Document Frequency): 전체 문서에서 얼마나 희귀한 단어인지를 반영 → 흔하게 등장하지 않는 단어일수록 높은 가중치를 부여
작동 원리
- 사용자가 쿼리에서 입력한 단어들이 문서에 얼마나 등장했는지(TF), 그리고 해당 단어가 전체 문서 집합에서 얼마나 희귀한지(IDF)를 바탕으로 각 문서에 대해 BM25 점수를 계산
- 높은 점수를 가진 문서가 결과로 반환됨
특징
- Dense 벡터가 아닌 희소 벡터 기반이므로 일반적인 벡터 DB (예: Faiss, Qdrant)에서는 직접 사용이 어려움 → 별도로 sparse 벡터를 위한 인덱싱 시스템 필요
Sparse 벡터 Search - SPLADE

개념
- 기존 Sparse 벡터 검색 방식의 한계인 유연성 부족을 개선하기 위해, BERT 기반 모델을 활용하여 sparse 벡터를 생성하는 방법
- 단순 등장 빈도가 아닌 단어의 문서 내 중요도(score)에 따라 스파스하게 표현
주요 특징
- 중요도 기반 가중치 부여
- 단어가 문서에서 얼마나 중요한지를 수치로 표현하여 벡터 생성
- Term Expansion
- BERT 모델과 결합하여 의미적으로 유사한 단어 표현까지 확장
- 예: "2단", "2중적 표현" 등이 같은 의미로 확장되어 검색 가능
- 유연한 검색 가능
- 단순 키워드 일치 외에도 의미 기반 검색 지원(오타, 간접적 표현을 인식할 수 있음)
- 사용자 쿼리에 포함되지 않은 단어라도 문서의 중요도 기반으로 관련성이 높은 문서를 찾을 수 있음
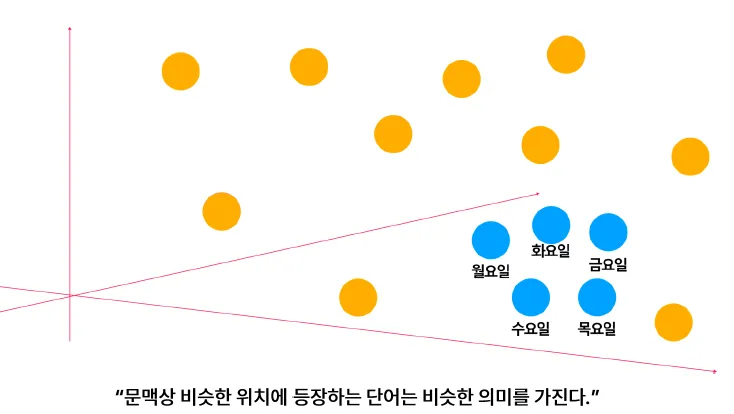
시맨틱 검색
개념
- 사용자의 검색 질의(Query)와 문서 간의 의미적 유사도(Semantic Similarity)를 계산하여 의미가 유사한 문서를 찾아주는 검색 방식
- 핵심 기술: 자연어 문장을 벡터로 변환하는 임베딩(Embedding)
기술적 구성
- 문장을 벡터로 변환 (임베딩)
- 사용자 질의도 같은 방식으로 벡터화
- 두 벡터 간 거리 계산 (예: 코사인 유사도, 유클리디안 거리 등)
예시
- 검색어:
"변비로 고생한 김철민"→ 문서:"고양이를 키우면서 주의해야할 건강요소"→ 유사도 낮음 → 문서:"변비 증상과 해결법"→ 유사도 높음 → 문서:"변화됨을 본질 비교"→ 유사도 낮음
장점
- 의미가 비슷한 문장도 검색 가능
- 고도화된 사용자 질의 대응 가능
단점
- 느린 검색 속도 (벡터 기반 거리 계산 필요)
- 벡터 DB 등 추가 시스템 필요
- 포괄적 결과를 반환하여 정확성이 떨어질 수 있음
추가 설명
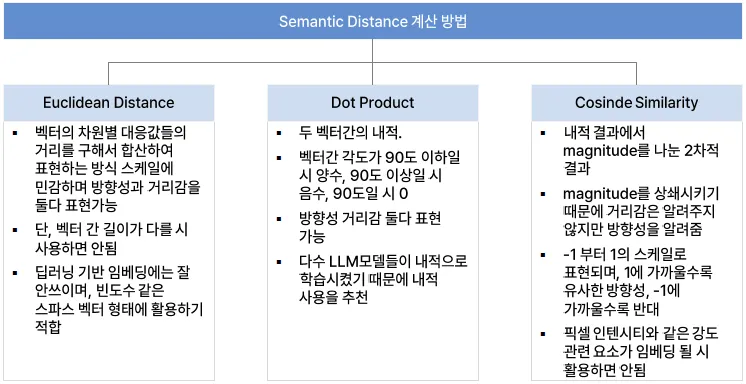
인덱싱 및 거리 계산 알고리즘
- LSH 기반: 해싱 방식, 유클리디안 거리 사용
- HNSW + PQ 기반: 그래프 탐색 + 압축, 반복 탐색 기반
거리 계산 방식
- Euclidean Distance
- Cosine Similarity
- Dot Product Similarity
어떤 인덱싱/알고리즘을 사용하느냐에 따라 정확도 및 속도는 달라짐
일반적으로 임베딩 모델의 벡터를 그대로 사용하는 것이 가장 이상적
| 구분 | Keyword Search(Attribute Filter / Sparse 벡터) | Semantic Search(Dense 벡터) |
|---|---|---|
| 장점 | - 속도가 빠르다 - 비용 효율적이다 - 제한적 검색 요건에 적합 - 표기 형태가 중요한 경우(고유명사 등)에 유리 | - 정확한 표현이 아니어도 검색 가능 - 오타, 표현의 다양성에 강함 - 유사도 기반 결과 제공 가능 - 멀티모달 콘텐츠 지원 (텍스트, 이미지, 오디오 등) |
| 단점 | - 유연성이 떨어진다 - 의미 기반 표현 인식에 약함 - 쿼리의 디테일에 검색 성능이 의존적 | - 속도가 느릴 수 있음 - 리소스 소비가 큼 (Heavy) - 고유명사 중심 콘텐츠에 약할 수 있음 |
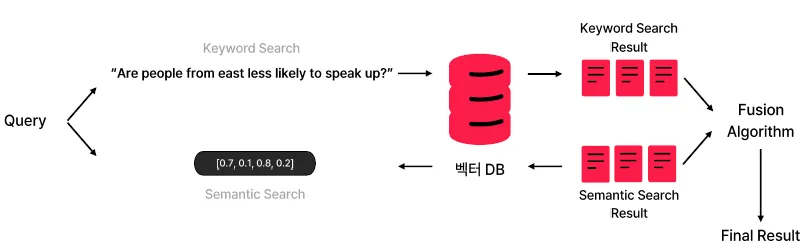
하이브리드 검색
키워드 서칭 방식과 Semantic 서칭 방식을 조합하여 상호 간의 장점만 취하는 방향으로 안정적인 성능
개념
- 키워드 검색과 시맨틱 검색을 결합한 방식
- 정확한 단어 일치 정보와 문맥적 의미 유사성을 동시에 고려하여 검색 품질을 높임
- “키워드 서칭 방식과 Semantic 서칭 방식을 조합하여 상호 간의 장점만 취하는 방향으로 더욱 안정적인 성능을 노리는 방식”
기술적 구성
- 키워드 필터링 후 시맨틱 정렬
- 점수 계산 방식:
최종점수 = 키워드 점수 * 가중치 + 시맨틱 점수 * 가중치
예시
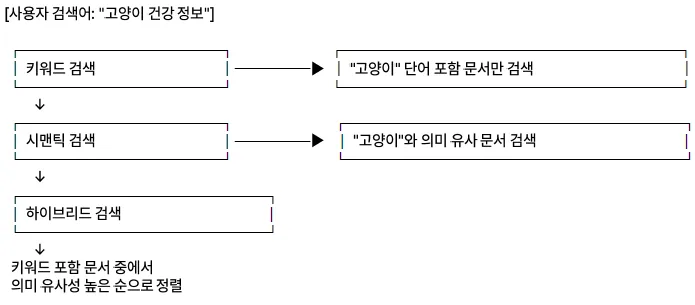
- 검색어: “고양이 건강 정보”
→ 문서 A: 키워드+시맨틱 모두 높음 (정확한 노출)
→ 문서 B: 키워드만 존재, 시맨틱은 낮음
→ 문서 C: 시맨틱만 높음 (유사 표현)
- 예시 쿼리:
→ “○○일에만 한 번 전 발간된 급리 관련 내용을 찾아줘”
→ Attribute Filter(발간일, 발행일) + Semantic Search
→ “축구 관련 기사를 찾는데, 그 중에서도 해외파 선수들의 소속팀에서의 성적과 관련된 부분을 찾아줘”
→ SPLADE(해외파 선수 = 손흥민, 김민재 등) + Semantic Search
장점
- 키워드 정확도 + 시맨틱 문맥 이해 → 검색 정확도 향상
단점
- 구현 복잡도, 리소스 사용 증가
- 검색결과 튜닝 필요 (가중치 설정 등)

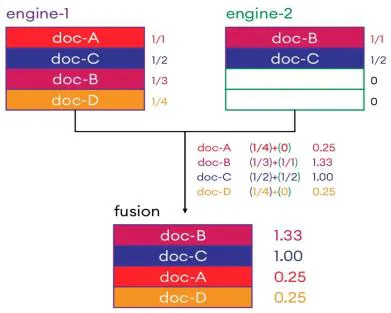
- RRF
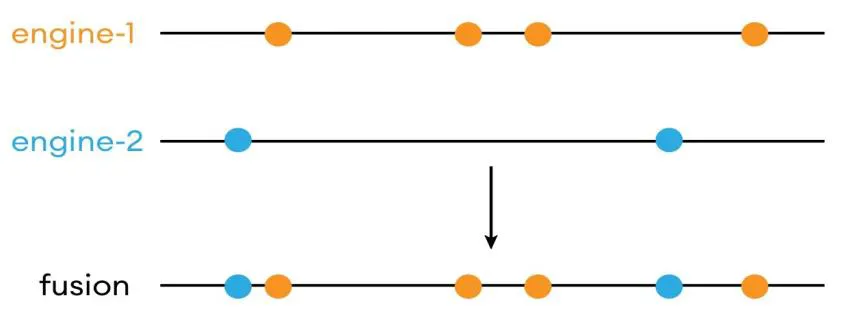
- RSF
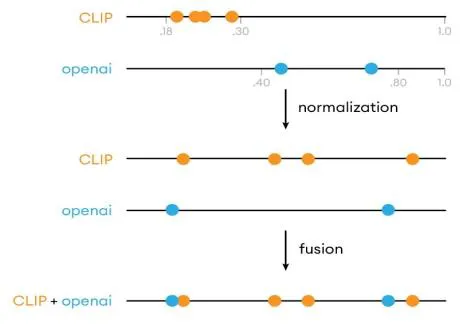
- DBSF

figure들을 인용하여 멋진글 작성해주셨네요
다만 어떤 이해관계자들에게 어필이 될지 그런 부분들을 좀더 develop하길 바라요~^^