벡터 DB 스키마 설계
벡터 DB 스키마 설계는 벡터 임베딩을 효율적으로 저장하고 검색하는 구조를 계획하는 과정 데이터 특성과 Application의 요구사항을 고려하여 수행
1. 데이터 구조 계획
-
데이터 유형 결정
- 벡터 임베딩의 출처(이미지, 텍스트, 지리 좌표 등)에 따라 저장할 데이터 유형을 정의
-
벡터 차원 정의
- 각 임베딩 벡터의 차원 수를 설정 (예: 일반적으로 768차원)
2. 필드 정의
-
벡터 필드
- 실제 임베딩을 저장할 필드들(example)
image_vector,summary_dense_vector등
- 실제 임베딩을 저장할 필드들(example)
-
메타데이터 필드
- 문서나 항목에 대한 추가 정보를 저장할 필드들(example)
summary,publish_ts등
- 문서나 항목에 대한 추가 정보를 저장할 필드들(example)
3. 확장성 및 성능
-
수평 확장 고려
- 데이터 양 또는 쿼리 부하가 증가해도 성능을 유지할 수 있도록 노드 증설 계획
-
부하 분산
- 여러 노드에 쿼리 요청을 효율적으로 분배하기 위한 로드 밸런싱 전략
4. 인덱싱 전략
-
인덱스 유형
- HNSW, IVF 등 다양한 알고리즘 중에서 선택
- 쿼리 성능과 데이터 크기에 따라 최적의 인덱스 구조 결정
-
메트릭 유형
- 유사도를 측정하는 데 사용할 메트릭 선택
- 내적(dot product) 또는 코사인 유사도가 일반적으로 사용됨
5. 데이터 저장 및 검색
-
저장 방식
-
메모리 기반 저장 또는 디스크 기반 저장
- 메모리 기반: 빠른 응답 속도, 메모리 사용량 증가
- 디스크 기반: 대용량 데이터 저장에 유리하나 상대적으로 느림
-
-
검색 최적화
- 캐싱, 병렬 처리 등을 통해 쿼리 속도 최적화
- 요청을 분산 처리하여 부하를 효율적으로 관리
필드 정의 및 인덱싱
| 구분 | 설명 |
|---|---|
| 벡터 필드 | - 고차원 벡터를 저장하는 필드 (예: 이미지나 텍스트의 임베딩 벡터 저장) - 예시: image_vector, text_embedding |
| 메타데이터 필드 | - ID 필드: 각 벡터의 고유 식별자 저장 (예: id, article_id)- 텍스트 필드: 관련 텍스트 데이터 저장 (예: title, summary)- 타임스탬프 필드: 생성/수정 시간 저장 (예: publish_ts)- 기타 메타데이터: 추가 정보 저장 (예: author_info, category) |
| 인덱싱 | - 벡터 인덱스: 벡터 필드에 대한 인덱스 생성으로 효율적 검색 지원 (예: HNSW, IVF, PQ 등) - 메타데이터 인덱스: 메타데이터 필드에 인덱스 생성 및 필터링·검색 기능 지원 |
VectorDB 일반적인 스키마 구조
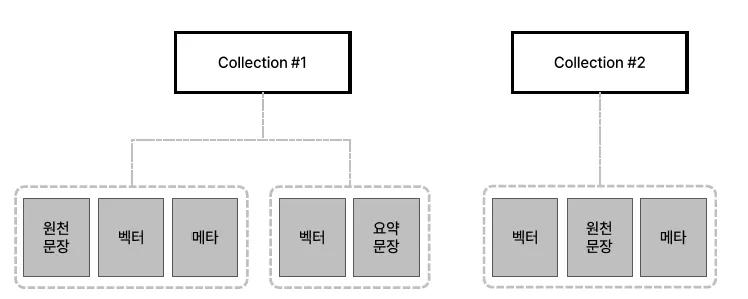
collection 안에 원본 데이터가 존재
단일 Collection vs 멀티 collection
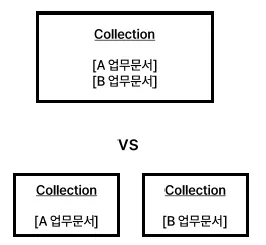
상황, 데이터형태 별로 VectorDB의 분할 저장을 결정할 수 있음
→ 검색 속도 & 정확도
- Collection 관리 기법
Vector DB에서 Collection을 효율적으로 관리하기 위한 전략
-
단일 Collection 관리
- 데이터 양이 적거나 단순한 서비스에서는 하나의 Collection에 모든 데이터를 저장·검색
-
다중 Collection 분리
- 대규모 데이터 또는 높은 동시성 요구 시, 여러 Collection으로 분산 저장
- 병렬 처리로 검색 성능 및 확장성 확보
-
분리 기준 설정
- 정확도: 서로 다른 도메인·속성의 데이터를 별도 Collection으로 분리해 검색 품질 유지
- 성능: 읽기·쓰기 부하 분산, 인덱스 크기 관리 등을 고려하여 분할
-
상황별 판단
- 소량 데이터 & 단일 워크로드 → 단일 Collection
- 대량 데이터 & 복합 워크로드 → 다중 Collection 분리
멀티 모달에서 단일 Collection

장점
- 간소화된 검색: 하나의 벡터로 문서와 동영상의 복합 정보를 표현할 수 있어 검색이 간편해짐.
단점
-
복합 표현의 한계: 문서와 동영상의 정보를 하나의 벡터에 결합하는 과정에서 정보 손실 발생 가능.
-
벡터 크기 증가: 두 벡터를 결합하며 벡터 크기가 커지고, 이에 따라 저장공간과 계산 비용이 증가.
Collection으로 나누는 기준
| 기준 | 설명 |
|---|---|
| 데이터의 크기와 스케일링 | 대용량 데이터를 다룰 때는 Collection을 적절하게 나누어 DB의 성능을 유지하고 스케일링을 용이하게 해야 한다. |
| 데이터의 접근 패턴 | 데이터에 접근하는 패턴을 분석하여, 자주 접근하는 데이터끼리 묶어서 Collection을 설계하는 것이 효과적이다. |
| 데이터의 생명 주기 | 데이터의 라이프사이클에 따라 Collection을 나누면, 오래된 데이터를 쉽게 아카이브하거나 삭제할 수 있다. |
| 데이터의 속성 | 비슷한 속성을 가진 데이터끼리 묶어 관리하면 검색과 인덱싱이 효율적이다. |
| 운영 및 관리의 용이성 | Collection의 수가 너무 많으면 관리가 복잡해질 수 있으므로, 관리의 용이성을 고려해 적절한 단위로 나누어야 한다. |
사례 - 뉴스기사 대상 Collection 설계

-
날짜 기준으로 나누기
- 기준: 날짜 별로 Collection을 나누어, 매일 생성된 뉴스를 별도의 Collection에 저장
- 장점: 최신 뉴스에 대한 빠른 접근이 가능하고, 오래된 뉴스를 쉽게 아카이브할 수 있다.
- 예시: news_20250201, news_20250202
-
주제 또는 카테고리 기준으로 나누기
- 기준: 주제별로 Collection을 나누어, 정치, 경제, 스포츠 등 카테고리 별로 뉴스를 저장
- 장점: 특정 주제에 대한 검색이 빠르고 효율적이다.
- 예시: news_politics, news_economy, news_sports
-
날짜와 주제 기준을 혼합한 기준으로 나누기
- 기준: 날짜와 주제 기준을 혼합하여 Collection을 나눈다. 예를 들어, 매달 주제별로 Collection을 생성
- 장점: 데이터가 너무 세분화되지 않으면서도, 특정 기간과 주제에 대한 검색이 효율적이다.
- 예시: news_202501_politics, news_202501_economy, news_202501_sports
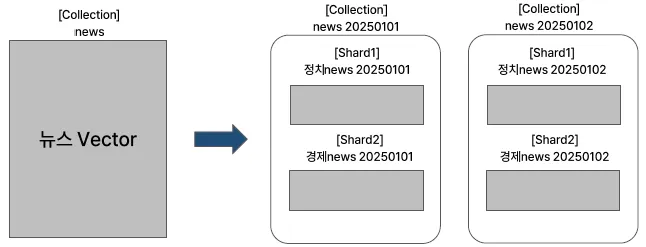
멀티 Collection에서의 유사도 검색
멀티 Collection 유사도 검색을 위해서는 벡터 공간의 일관성 필요
일관된 벡터 공간이란?
벡터 데이터베이스에서 서로 다른 데이터 항목들이 동일한 차원 수와 동일한 의미적 해석을 갖도록 변환된 공간
-
벡터 간 유사도를 정확하게 계산하고 비교할 수 있도록 함
-
서로 다른 Collection의 벡터들도 동일한 임베딩 스페이스에 있어야 함
벡터 공간의 일관성 요건
-
동일한 차원 수: 모든 벡터는 동일한 차원 수를 가져야 함
-
동일한 임베딩 모델: 동일한 임베딩 모델을 사용하여 데이터를 벡터화해야 함
-
동일한 처리 방식: 데이터 전처리와 임베딩 생성 과정이 일관되어야 함
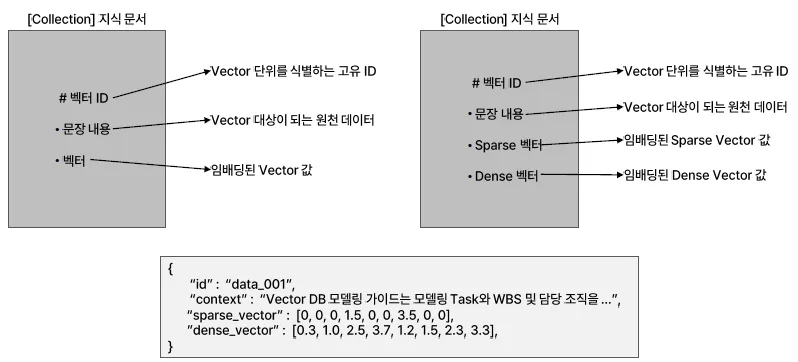
하나의 문서를 다양한 방식(Sparse+Dense)의 벡터로 저장 → 하이브리드 검색(Hybrid Retrieval) 가능
멀티 Vector 값을 관리하는 이유 Sparse + Dense
다양한 인덱싱 전략 사용
- Sparse Vector: 효율적인 저장과 검색을 위한 특화된 인덱싱 방식
- Dense Vector: 빠른 유사도 검색을 위한 인덱싱 방식 사용 가능
복합 검색 기능
- Sparse Vector와 Dense Vector의 혼합 저장을 통해 다양한 검색 조건 동시 적용 가능
- 예: 텍스트와 이미지 데이터를 동시에 검색하여 관련성 평가 가능
확장성
- 다양한 유형의 벡터 데이터를 하나의 Collection에 저장함으로써 시스템의 확장성 향상
- 데이터 타입과 저장 방식에 구애받지 않고 Collection 확장 가능

| 항목 | Sparse Vector | Dense Vector |
|---|---|---|
| 대부분의 값 | 0 | 0이 아님 |
| 크기 | 고차원 | 상대적으로 저차원 |
| 계산 효율 | 일부 계산에서 빠름 | 계산량 많지만 의미가 풍부함 |
| 사용 예 | One-hot, BoW, TF-IDF | Word2Vec, BERT 임베딩 |
| 유사도 측정 | 비효율적일 수 있음 | 코사인 유사도 등 효율적 |
