원천 테이터 청킹 전략
청크
Vector화 할 대상이 되는 데이터
청크로 구분된 데이터는 임베딩 처리를 통해 고정된 크기의 Vector 값으로 변환
-
청크 크기와 응답시간 간의 관계는 정보 검색 및 자연어 처리 시스템의 전체적인 성능에 매우 중요한 영향을 미침
-
청크 크기를 적절하게 설정하는 것이 시스템의 효율성과 정확도를 좌우함
-
따라서, RAG 시스템의 효율성과 정확성에 영향을 미칠 수 있는 중요한 결정 중 하나는 적절한 청크 크기(Chunk Size)를 선택하는 것
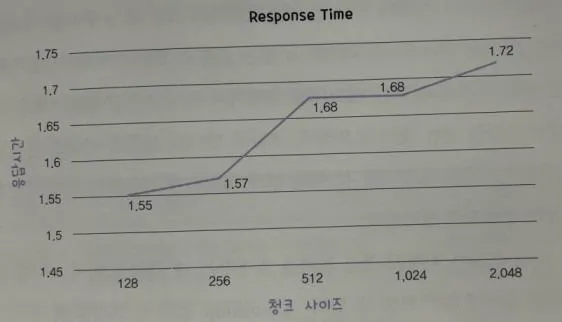
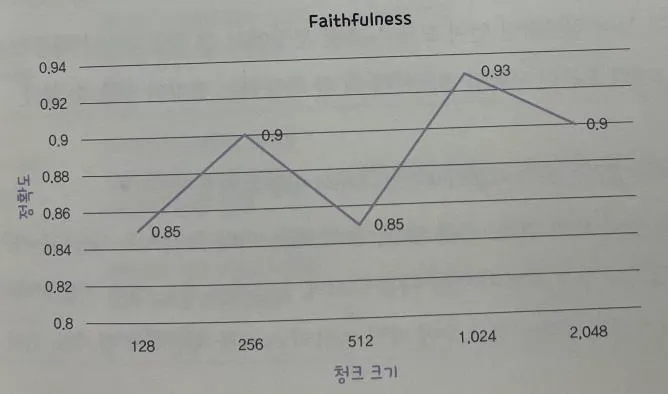
→ 청크 사이즈가 증가할수록 정확도가 감소하고, 속도가 늘어남
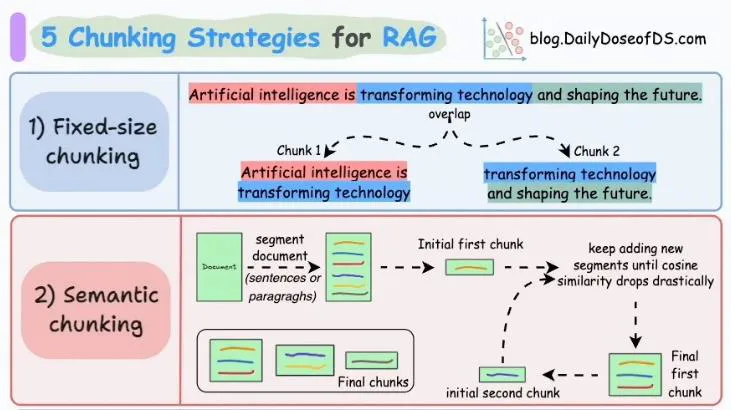
Fixed Size Chunking
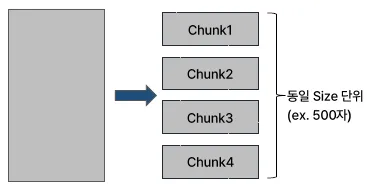
장점
-
구현이 간단
-
균일한 데이터 분포
-
예측 가능한 성능
단점
-
비효율성: 고정된 크기를 채우지 못할 경우 공간이 비효율적으로 사용됨
-
데이터 경계의 의미 상실: 데이터의 논리적 경계를 무시하게 되어 의미를 온전히 이해하기 어려움
사용 예시
- 대량의 로그 데이터
Overlapping Chunking
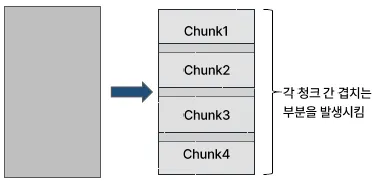
장점
-
높은 검색 포괄성
-
검색 정확성 증가
단점
- 저장 공간 증가
사용 예시
-
문서 검색: 문단 간 연결 정보를 보존하고 싶을 때
-
멀티 미디어 데이터: 장면 단위로 나눌 때, 장면 간 전환 부분을 중복 포함하고 싶을 때
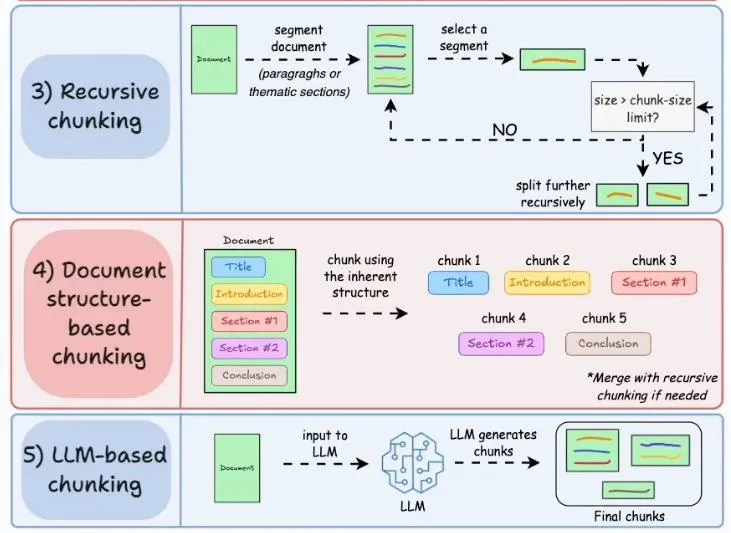
Recursive Chunking
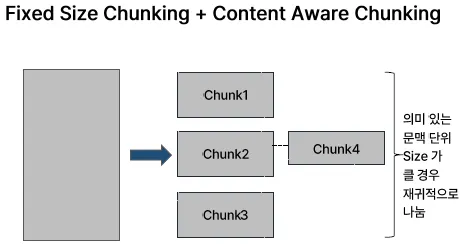
Chunk2와 Chunk4 처럼 의미 있는 문맥 단위가 너무 커서 고정 크기를 넘는 경우에는
→ 재귀적으로 또는 추가적으로 문맥을 고려한 분할(Content Aware)을 적용함
Semantic Chunking
의미
-
청크의 유사성을 기준으로 텍스트를 분할하는 방법
-
문장을 단위로 청크한 후, 각 청크를 임베딩하여 벡터화
-
청크 간 코사인 유사도를 계산하고,
- 설정한 임계값보다 유사도가 낮을 때 분할 수행
- 분할 기준 이전은 하나의 청크로 간주, 이후도 같은 방식으로 반복
장점
-
높은 이해도
-
정확한 검색 결과
-
효율적인 처리 가능
단점
- 구현 복잡성: 의미 단위를 인식하고 정확하게 분할하는 알고리즘이 복잡할 수 있음
Summarization Chunking
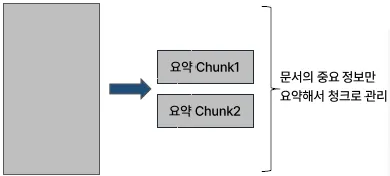
의미
-
데이터를 요약된 형태로 나누는 방법
-
긴 텍스트나 문서를 요약하여 중요한 정보만 포함하는 청크를 만드는 것이 목적
장점
-
빠른 정보 파악
-
효율적인 검색
-
데이터 축소
단점
-
정보 손실
-
요약 정확도 품질 저하 가능
사용 예시
-
뉴스 요약
-
리포트 요약
Parent Child Chunking
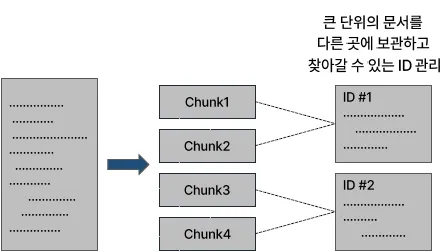
의미
-
데이터를 계층 구조로 나누는 방식
-
큰 청크(부모)와 작은 청크(자식)로 분할하고, 각 청크를 계층적으로 연결
-
청크 자체에는 원문 전체를 저장하지 않고, 원문은 별도 저장소에 저장
- 검색 시, 청크에 연결된 포인터를 통해 원문 위치를 찾아감
장점
-
효율적 탐색
-
구조적 접근
-
세분화된 분석 가능
단점
-
구현 복잡성
-
데이터 중복 가능성
사용 예시
-
문서 구조화
-
웹사이트 구조화
단계를 내려가며 청크를 쪼갬, 원문을 각 청크로 요약해서 원문을 찾아갈 수 있도록
Rag를 위한 5가지 청킹
https://blog.dailydoseofds.com/p/5-chunking-strategies-for-rag
