LangChain Tool과 Agent
Agent는 사용자의 요청에 대해, 툴(Tool)로 표현되는 외부 모듈을 활용하여 문제를 해결하는 기능.
Tool은 LLM이 답변을 출력하기 위해 활용할 수 있는 다양한 수단을 의미.
LLM은 Tool을 사용하기 위해 Tool 이름과 Argument를 생성하는데,
이 Tool 실행을 자동화하여 LLM을 반복적으로 실행하여 최종 단계에 도달하는 방법이 Agent.
Agent의 작동 방식은 아래와 같습니다.
1. 에이전트에 입력이 주어지면, 툴을 사용하는 액션(Action)을 결정.
2. 툴의 사용 결과가 에이전트에 전달되면, 이를 활용하여 다음 액션을 정함.
3. 이후, 원하는 결과에 도달할 때까지 반복.
구글 코랩 마운트
from google.colab import drive
drive.mount('/content/drive')
!pip install langchain langchain-openai langchain-community langgraph pypdf chromadb wikipedia tavily-python wikipedia matplotlib langchain-experimentalOpenAI API로 Agent 구현하기
import os
import openai
os.environ["OPENAI_API_KEY"] = "OPENAI KEY"
client = openai.OpenAI()# Agent는 포맷에 맞는 입/출력의 반복을 통해 문제를 해결합니다.
class Agent:
# __init__ : Agent 클래스가 생성될 때 호출되는 함수
def __init__(self, system_prompt=""):
self.system_prompt = system_prompt
self.messages = []
# message를 저장
self.messages.append({"role": "system", "content": system_prompt})
# __call__ : Agent 클래스가 호출될 때 호출되는 함수
# message와 result를 생성하고 이를 messages에 추가
def __call__(self, message):
self.messages.append({"role": "user", "content": message})
result = self.execute()
self.messages.append({"role": "assistant", "content": result})
return result
# execute : 현재까지의 message로 답변 생성
def execute(self):
completion = client.chat.completions.create(
model="gpt-4o-mini",
temperature=0,
messages=self.messages)
return completion.choices[0].message.content
청크를 나누는 기준
- 검색할 쿼리에 맞춰서 나누기(토큰 사이즈를 고려하지 않아 효율성 감소)
- 토큰 사이즈에 맞춰서 설정
LLM Agent
LLM기반Multi-Agent 개발시LangChain활용
-
전문성:
각 에이전트는 특정 도메인 지식이나 작업에 특화되어 효율성을 높일 수 있습니다.
-
협업:
에이전트 간 상호작용을 통해 복잡한 문제를 해결하고 시너지를 창출할 수 있습니다.
-
확장성:
새로운 에이전트를 추가하여 시스템 기능을 확장하고 다양한 작업을 수행할 수 있습니다.
Tool (~= Function)
LLM이 외부 함수를 이용할 수 있도록 구현된 모듈
→ LLM이 함수 실행 포맷의 출력을 생성할 수 있는 능력을 사전에 학습해야 함
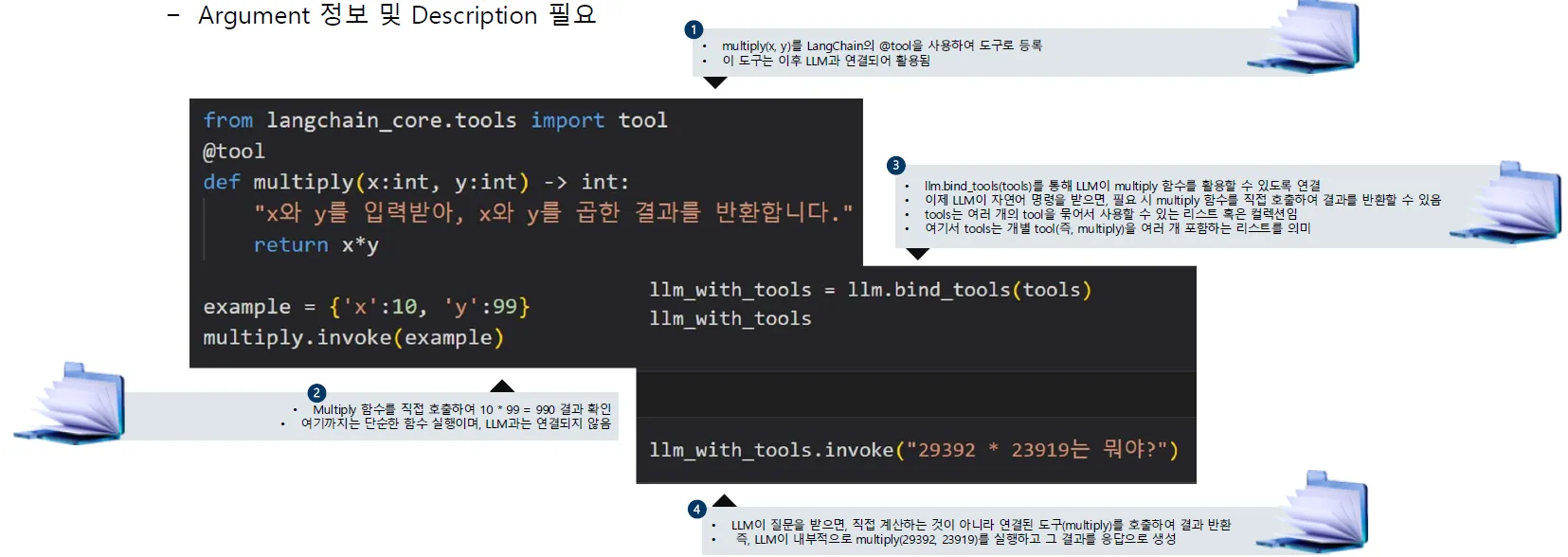
Tools in LangChain
⇒ Custom 함수의 경우에도, Decorator를 통해 Tool로 변환 가능
⇒ Argument 정보 및 Description 필요
ReAct Agent 프롬프트
⇒ 생각-행동-관찰을 통해 다음 행동을 계획하고 실행
역할: 당신은 최신 연구 트렌드를 검색하고 요약하는 인공지능 연구 도우미입니다.
프로세스:
-
생각(Think):** 사용자의 요청을 분석하고, 필요한 검색 키워드를 결정하세요.
-
행동(Act):** 적절한 웹 검색을 실행하여 관련 정보를 가져오세요.
-
관찰(Observe):** 검색 결과를 분석하고, 유용한 정보를 요약하세요.
-
반복(Repeat):** 추가적인 세부 정보가 필요하면 다시 검색하여 보완하세요.
실행 단계:
Step 1 - 생각(Think):**
-
사용자의 요청을 분석하고, 어떤 키워드가 가장 적절한지 결정하세요.
-
예: "AI 연구 트렌드 2024", "최신 생성형 AI 논문", "딥러닝 발전 방향"
Step 2 - 행동(Act):** -
위에서 결정한 키워드를 사용하여 최신 정보를 검색하세요.
Step 3 - 관찰(Observe):** -
검색된 정보를 확인하고, 관련성이 높은 내용을 선별하세요.
-
신뢰할 수 있는 출처(논문, 공식 보고서 등)를 우선시하세요.
Step 4 - 결정:** -
충분한 정보를 확보했으면, 최종적으로 연구 트렌드를 요약하여 제공하세요.
-
부족하다면 추가적인 검색을 수행하세요.
출력 형식 (예시):
-
트렌드 1: 생성형 AI 모델의 확장 (예: GPT-5, Gemini)
-
트렌드 2: 멀티모달 AI 연구 증가 (텍스트, 이미지, 음성 통합 모델)
-
트렌드 3: AI 안전성 및 윤리적 이슈 강화
Multi-Agent
각 역할 별로 에이전트를 생성하여 에이전트 간 서로 소통하며 팀으로 업무를 수행
-
두 명 이상의 에이전트가 존재하고,
-
서로 협력하거나 경쟁하며,
-
공동 또는 개별 목표를 향해 행동함
최근 연구
MARL (Multi-Agent Reinforcement Learning): 에이전트 간의 상호작용을 학습하여 정책을 최적화
상호 의존성 기반 학습, 공정한 협상 모델, 분산 학습 구조 등이 연구 중
#5. Open-Weight LLMs
모델의 파일이 공개된 모델
⇒ 모델의 파일이 공개된 모델
⇒ Open-Weight LLM, Open-Sourced LLM , Open LLM을 혼용하여 부르는 중
| 비교 항목 | Open LLM | Closed LLM |
|---|---|---|
| 접근 방식 | 모델 다운로드 및 로컬 실행 가능 | API 기반 (직접 다운로드 불가) |
| 학습 데이터 | 일부 공개 | 비공개 |
| 소스 코드 | 오픈소스 제공 가능 | 비공개 |
| 활용 방식 | 직접 실행, 커스터마이징 가능 | 기업이 제공하는 클라우드 서비스 활용 |
| 대표 모델 | LLaMA, Mistral, Falcon | GPT-4, Gemini, Claude |
Supervised Fine Tuning (SFT) + Reinforcement Learning with Human Feedback(RLHF)
GPT3 → ChatGPT 다시보기
Supervised Fine Tuning : 목적이 생긴 입출력
문장 이어쓰기가 아닌, 질문이 주어지면 답을 하는 방식의 학습 방법
RLHF : 모델의 Alignment (정렬)을 위한 방법
정렬: LLM의 출력을 유익하게 만드는 과정
좋은 질문입니다! 최근 대규모 언어 모델(LLM)의 학습 방식에서 자주 등장하는 조합인
Supervised Fine Tuning (SFT) + Reinforcement Learning with Human Feedback (RLHF)는
모델의 품질을 높이기 위한 2단계 학습 프로세스로 이해할 수 있습니다.
| 단계 | 목적 | 방법 |
|---|---|---|
| 1. SFT (지도학습 미세조정) | 좋은 정답을 빠르게 따라하도록 학습 | 사람이 만든 정답 데이터로 fine-tuning |
| 2. RLHF (인간 피드백 기반 강화학습) | "더 나은" 또는 "더 바람직한" 응답을 학습 | 사람의 선호도를 모델이 직접 강화학습으로 반영 |
1. Supervised Fine-Tuning (SFT)
정의
-
Pre-trained 모델에 대해 사람이 수집한 문장-답변 쌍을 사용하여 지도학습을 진행
-
예:
질문: 인공지능이 뭐야? 정답: 인공지능은 인간의 지능을 모방하는 기술입니다.
목적
-
모델이 "어떻게 대답해야 하는지"를 기본적으로 학습
-
기초적인 포맷, 톤, 정확도를 잡는 단계
2. Reinforcement Learning with Human Feedback (RLHF)
정의
-
사람이 직접 모델의 응답을 비교하고 선호도를 평가함
-
예:
Prompt: GPT가 AI를 설명해줘 → A 답변, B 답변 → 사람이 "B가 더 자연스럽다"고 선택
구성
-
Reward Model 학습
- 사람이 응답을 비교한 데이터를 바탕으로 어떤 답변이 더 좋은지를 평가하는 보상 모델을 만듦
-
PPO (Proximal Policy Optimization) 등 RL 알고리즘으로 Fine-Tuning
- 이 보상 모델을 기준으로 원래 모델을 강화학습으로 더 좋게 만듦
왜 이 조합이 좋은가?
-
SFT는 "답을 하게끔" 만들고
-
RLHF는 "더 나은 답을 하게끔" 만든다
즉, 기본적인 품질을 잡고 → 인간이 선호하는 방향으로 미세하게 다듬는 구조.
예시 (ChatGPT, GPT-4 개발에도 적용됨)
OpenAI의 GPT 시리즈는 다음과 같이 학습됨:
-
Pre-training: 인터넷 데이터를 대량으로 학습
-
SFT: 수작업으로 만든 고품질 QA 데이터를 사용해 지도학습
-
RLHF: 사람의 피드백을 바탕으로 학습 → 대화 품질 향상
모델 양자화 (Model Quantization)
모델의 숫자(Weight)를 작게 변환하여 메모리 사용량을 줄이고, 연산을 빠르게 만드는 기법
⇒ LLaMA, Qwen, Mistral 같은 LLM도 양자화하여 가볍게 실행 가능!
#6. Fine-Tuning
미리 학습된 대규모 언어 모델(LLM, Large Language Model)을 특정 작업이나 도메인에 적합하게 조정하는 과정
⇒ 특정 작업에 맞는 모델 개선
⇒ 데이터 준비 및 모델 학습
⇒ 성능 평가 및 개선
파인 튜닝 결과 개선을 위한 LangChain기법
-
데이터 증강: 더 많은 데이터로 모델을 훈련하여 성능을 향상시키고 일반화를 개선할 수 있다.
-
전이 학습:이미 훈련된 모델에서 학습된 지식을 사용하여 새 작업에 대한 훈련시간과 데이터를 줄일 수 있다.
-
하이퍼 파라미터 튜닝: 이미 훈련된 모델에서 학습된 지식을 사용하여 새 작업에 대한 훈련시간과 데이터를 줄일 수 있다.
