Introduction
-
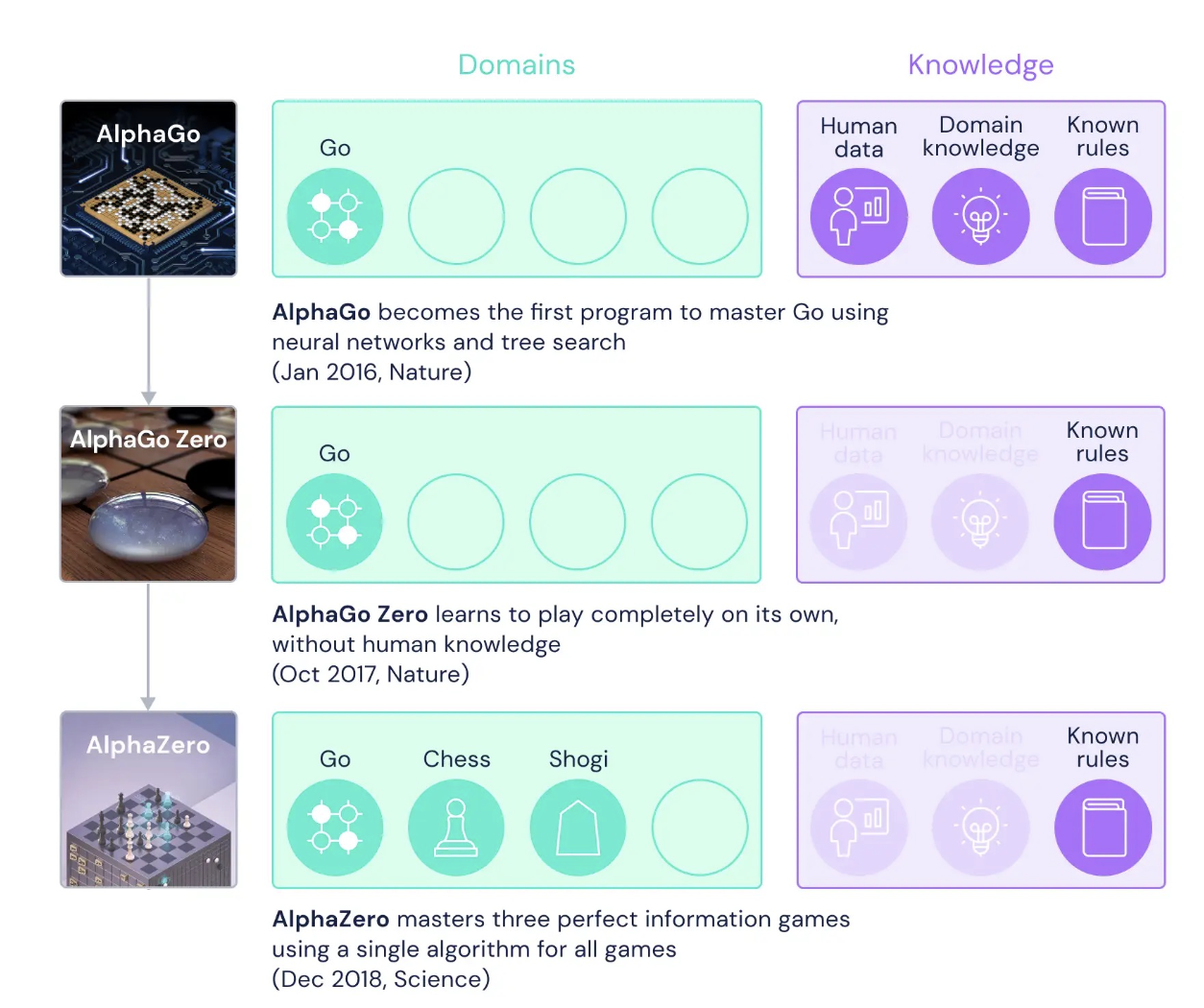
본 논문에서는 2016년 AlphaGo, 2017년 AlphaGo Zero를 통해 바둑(Go)에 대한 성공을 경험한 후, AlphaGo Zero의 more generic version 인 AlphaZero를 소개하고 있음.
(https://www.deepmind.com/blog/muzero-mastering-go-chess-shogi-and-atari-without-rules) -
Game 의 복잡도를 보았을 때, Go가 가장 복잡하고, shogi (일본식 장기) 와 chess 순으로 복잡도를 가지고 있는데, AlphaZero는 동일한 알고리즘을 이용하여 Go, Chess, Shogi 모두에 대응하는 generic algorithm을 제안함.
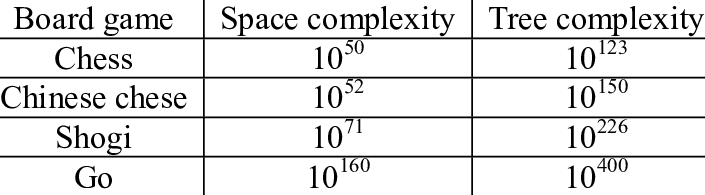
(https://www.researchgate.net/publication/337871637_Application_of_Q-Learning_and_RBF_Network_in_Chinese_Chess_Game_System)
Background
Alpha Go
Alpha Go는 실제 전문가의 기보 데이터를 기반으로 모델을 학습하고 해당 모델을 활용하여 MCTS(Monte Carlo Tree Search) 를 진행하는 방법론임.
💡 Alpha Go 학습 방법-
실제 전문가의 기보 데이터가 있으면, 이를 통해 Rollout Policy 나 SL Policy / Rollout Policy 를 학습.
- 이때 State를 보고 돌을 배치해야 할 위치를 예측하기 때문에 classification 문제임.
- SL Policy의 경우 13 layers 를 이용했고, 3천만 수의 데이터를 이용하여 57% 정확도를 달성했다고 함.
- Rollout Policy는 네트워크의 크기를 줄이고, SL policy 와 동일한 데이터를 사용한 policy 임. 정확도는 24%.
-
RL policy network 에서는 SL policy로 weight initialization 하여 self-play 를 진행하고, network를 업데이트 함.
- 이때 value network는 RL policy 로 어느쪽이 이길지 해당 state의 value 를 예측하는 network.
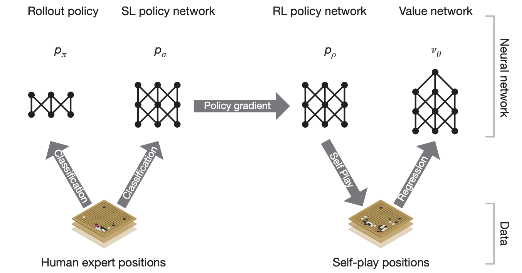
- 이때 value network는 RL policy 로 어느쪽이 이길지 해당 state의 value 를 예측하는 network.
-
Inference 시에는 앞선 train 단계에서 학습 시켰던 모델을 활용하여 MCTS 를 진행함.
- MCTS는 현 상황에서 N 번째까지 ( 끝까지 ) 둬보면서 가장 좋은 수를 고르는 방법론임.
- N : visit count, P : SL policy, z : terminal step에 도달할 때까지 진행된 outcome.
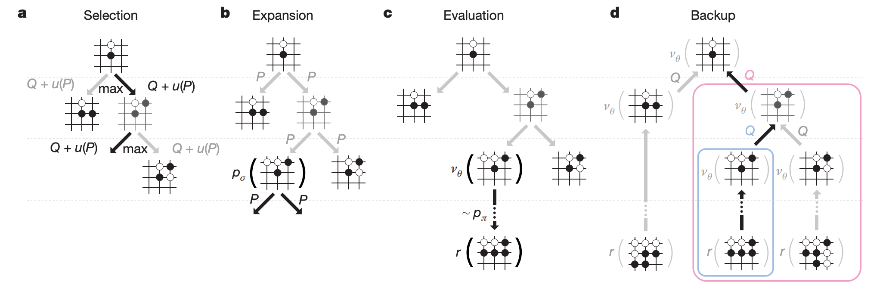

- MCTS는 현 상황에서 N 번째까지 ( 끝까지 ) 둬보면서 가장 좋은 수를 고르는 방법론임.
AlphaGO Zero
AlphaGo Zero는 사람의 지식을 제거하면서도, 좋은 성능을 낼 수 있다는 점에서 AlphaGo 보다 진보한 알고리즘이라고 함.
[AlphGo 와의 차이점]
- 전문가 데이터가 없기 때문에 Rollout Policy 와 SL Policy 존재하지 않음. 따라서 스크래치로 학습한다고 함.
- Domain knowledge를 반영한 hand craft feature가 없이, 바둑판에 대한 정보만을 이용하여 학습함.
- 하나의 network가 RL policy / value policy 의 역할을 모두 함.
- MCTS를 train 시에도 사용함.
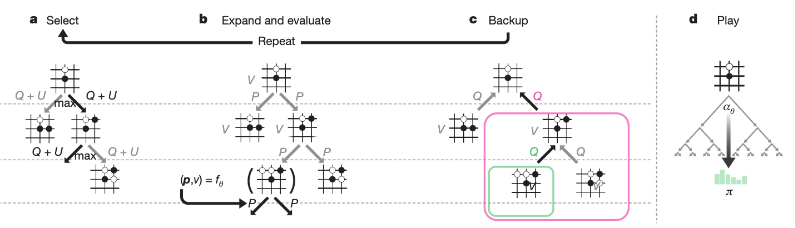
- self play 를 통해 게임을 진행하고, policy 를 계산함.
- 이때 각 수 마다 MCTS를 통해 최적의 action을 선택함.
- 최종적으로는 각 state마다 ( 를 얻게 됨. 여기서 z는 게임이 끝난 후 winner 를 통해 값을 결정하는데 이기면 1, 지면 -1.
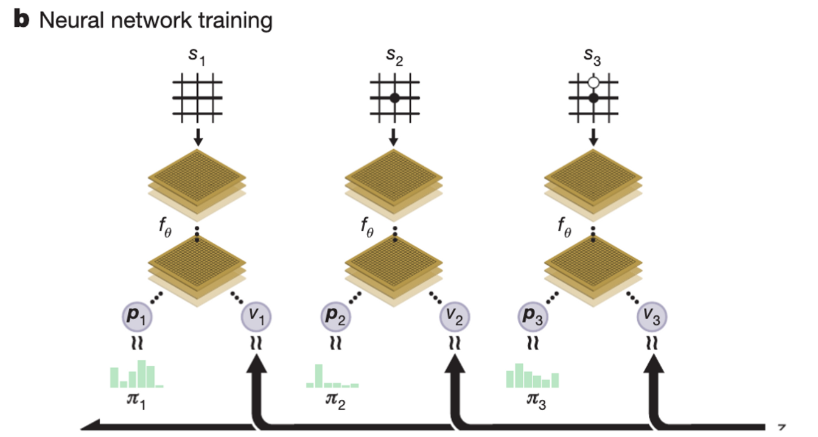
- self play를 통해 모은 데이터를 기반으로 모델 를 학습함.
- 이때 데이터는 단계 1에서 쌓은 (를 random sampling 하여 사용하며, loss 함수는 아래와 같음.
- 이는 z와 v, 와 p 가 같아지는 것을 목적으로 함.
- 맨 마지막 term은 regularization term으로 특정 가 너무 커지지 않도록 방지하는 term.
- 이때 데이터는 단계 1에서 쌓은 (를 random sampling 하여 사용하며, loss 함수는 아래와 같음.
AlphaZero
AlphaZero는 AlphaGo Zero의 generic version 알고리즘임. 학습 방법은 자체는 거의 동일하며, 대상 게임에서 차이가 존재함.
그럼에도 존재하는 차이는 아래와 ‘차이점’과 같음.
AlphaGo zero 와의 차이점
- 최적화에 대한 대상이 다름.
- AlphaGo Zero의 경우 바둑을 대상으로 한 알고리즘이기 때문이 게임을 이길 확률에 대한 optimize를 진행함.
- 하지만 AlphaZero는 바둑 외에도 체스, 쇼기와 같이 무승부를 포함하는 게임을 대상으로 하기 때문에 expected outcome 에 대해서 optimize 를 진행함.
- Self play에서 사용하는 Player 가 차이가 있음.
- AlphaGo Zero의 경우 iteration 마다 best player를 평가하고, 교체하여 현 시점에서의 best player 기반의 self play를 진행함.
- 이때 새로운 player 가 55% 이상의 승률을 보이는 경우 best player를 교체함.
- AlphaZero는 매 iteration마다 best player를 교체하며, 단일 신경망을 유지한채 최신 parameters를 이용하여 self play를 진행함.
- AlphaGo Zero의 경우 iteration 마다 best player를 평가하고, 교체하여 현 시점에서의 best player 기반의 self play를 진행함.
- data augment 진행 유무에 대한 차이가 존재함.
- AlphaGo Zero는 data augment를 위해 board position을 돌리는 등의 작업을 하기도 함.
- 바둑의 경우 rotation과 reflection이 없는 게임이기 때문에 data augment가 가능함.
- 하지만 Chess, Shogi 같은 게임은 비대칭성을 가지기 때문에 이와 같은 data augment 가 불가능함.
- 따라서 AlphaZero의 경우 data augment를 하지 않는다고 함.
- AlphaGo Zero는 data augment를 위해 board position을 돌리는 등의 작업을 하기도 함.
- State에서 사용하는 feature가 다름.
- AlphaGo Zero의 경우 바둑 대상이기 때문에 바둑판의 상태나 흑백 차례 등을 state로 사용함.
- AlphaZero는 다양한 게임 대상이기 때문에 다양한 게임의 상태를 state로 사용할 수 있음.
- 예를 들어, Chess의 경우 말의 위치와 차례 등을 포함한다고 함.
학습 방법 및 code
💡 AlphaZero 학습 방법
for i in range(10):
print('Train', i, '====================')
# 셀프 플레이 파트
**self_play()**
# 파라미터 변경 파트
**train_network()**
# 신규 파라미터 평가 파트
**evaluate_network()**-
Self play를 통해 학습 데이터를 모으고 저장함.
def self_play(): # 학습 데이터 history = [] # 베스트 플레이어 모델 로드 model = load_model('./model/best.h5') # 여러 차례 게임 실행 for i in range(SP_GAME_COUNT): # 1ゲームの実行 h = play(model) history.extend(h) # 출력 print('\rSelfPlay {}/{}'.format(i + 1, SP_GAME_COUNT), end='') print('') # 학습 데이터 저장 write_data(history) # 모델 파기 K.clear_session() del model
-
-
모은 학습 데이터를 이용하여 network를 학습함.
# 듀얼 네트워크 학습 def train_network(): # 학습 데이터 로드 history = load_data() xs, y_policies, y_values = zip(*history) # 학습을 위한 입력 데이터 셰이프로 변환 a, b, c = DN_INPUT_SHAPE xs = np.array(xs) xs = xs.reshape(len(xs), c, a, b).transpose(0, 2, 3, 1) y_policies = np.array(y_policies) y_values = np.array(y_values) # 베스트 플레이어 모델 로드 model = load_model('./model/best.h5') # 모델 컴파일 model.compile(loss=['categorical_crossentropy', 'mse'], optimizer='adam') # 학습률 def step_decay(epoch): x = 0.001 if epoch >= 50: x = 0.0005 if epoch >= 80: x = 0.00025 return x lr_decay = LearningRateScheduler(step_decay) # 출력 print_callback = LambdaCallback( on_epoch_begin=lambda epoch, logs: print('\rTrain {}/{}'.format(epoch + 1, RN_EPOCHS), end='')) # 학습 실행 model.fit(xs, [y_policies, y_values], batch_size=128, epochs=RN_EPOCHS, verbose=0, callbacks=[lr_decay, print_callback]) print('') # 최신 플레이어 모델 저장 model.save('./model/latest.h5') # 모델 파기 K.clear_session() del model
-
-
학습한 network를 평가함.
# 네트워크 평가 def evaluate_network(): # 최신 플레이어 모델 로드 model0 = load_model('./model/latest.h5') # 베스트 플레이어 모델 로드 model1 = load_model('./model/best.h5') # PV MCTS를 활용해 행동 선택을 수행하는 함수 생성 next_action0 = pv_mcts_action(model0, EN_TEMPERATURE) next_action1 = pv_mcts_action(model1, EN_TEMPERATURE) next_actions = (next_action0, next_action1) # 여러 차례 대전을 반복 total_point = 0 for i in range(EN_GAME_COUNT): # 1 게임 실행 if i % 2 == 0: total_point += play(next_actions) else: total_point += 1 - play(list(reversed(next_actions))) # 출력 print('\rEvaluate {}/{}'.format(i + 1, EN_GAME_COUNT), end='') print('') # 평균 포인트 계산 average_point = total_point / EN_GAME_COUNT print('AveragePoint', average_point) # 모델 파기 K.clear_session() del model0 del model1 # 베스트 플레이어 교대 if average_point > 0.5: update_best_player() return True else: return False
-
Experiments
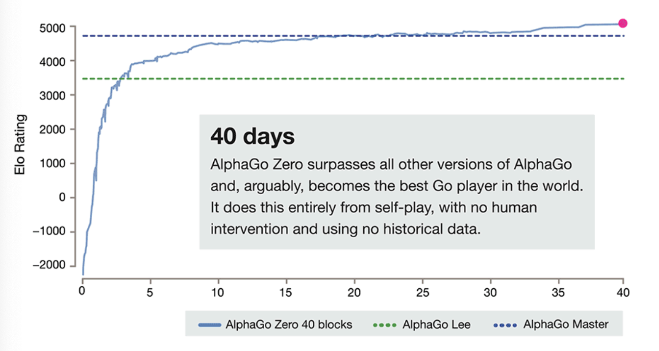
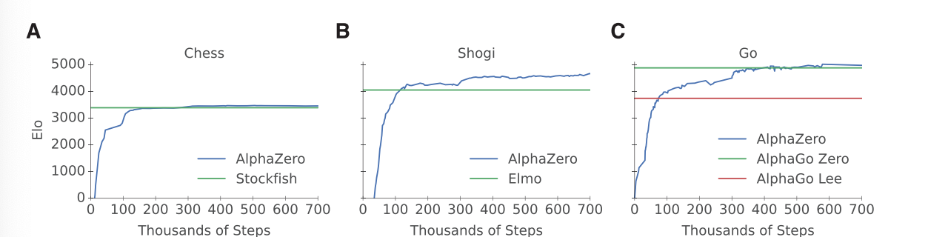
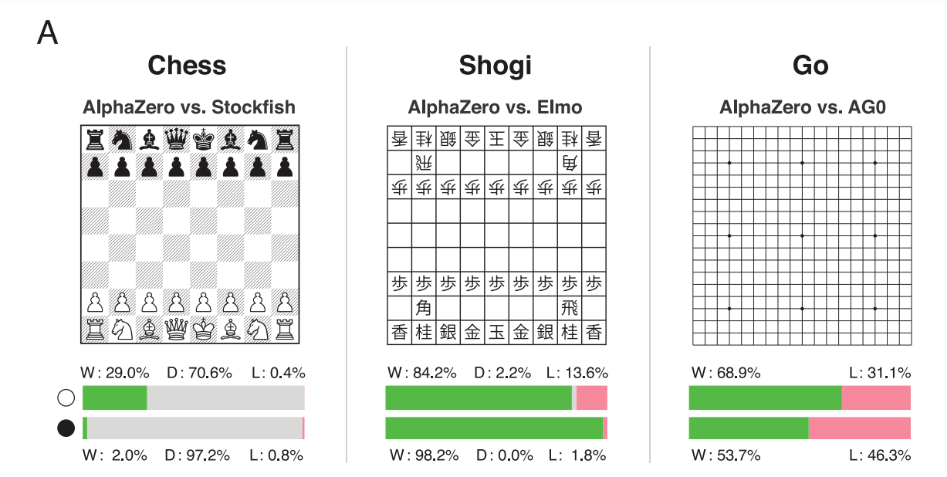
결과적으로 실험을 진행했을 때, AlphaZero를 이용하는 경우 Chess, Shogi, Go 모두에서 높은 승률을 볼 수 있었다고 함.
Reference
- A general reinforcement learning algorithm that masters chess, shogi and Go through self-play
- muzero (deepmind blog)
- 팡요랩 AlphaGo Zero 논문 리뷰
- Mastering the game of Go with deep neural networks and tree search
- Mastering the game of Go without human knowledge
- https://github.com/Jpub/AlphaZero/blob/master/8_game/8_3_simple_shogi/train_cycle.py
- https://theorydb.github.io/review/2020/01/17/review-book-alphazero/
