해당 글은 FastCampus - '[skill-up] 처음부터 시작하는 딥러닝 유치원 강의를 듣고,
추가 학습한 내용을 덧붙여 작성하였습니다.
1. Regularization이란?
-
Overfitting(과적합)을 방지하기 위해 Generalization Error를 줄이는 다양한 기법
-
일반적으로 training error를 최소화하는 것을 일부러 방해하는 형태
→ 이 과정에서 training error가 높아질 수 있음 -
loss가 최소화 될수록 최대화 되는 term을 추가하는 원리
→ 최소화 term과 최대화 term의 균형을 찾도록 함 -
모델이 noise에 강하고 unseen 데이터에도 잘 작동하도록 유도
Overfitting
Training error가 generalization error에 비해 현저히 낮아지는 현상
2. 주요 Regularization 기법 분류
| 적용 영역 | 기법 |
|---|---|
| 데이터 | Data Augmentation, Noise Injection |
| 손실 함수 | Weight Decay (L1, L2) |
| Layer 추가 | Dropout, Batch Normalization |
| 학습 방식 | Early Stopping, Bagging & Ensemble |
Ensemble Learning
여러 개의 모델을 조합해 하나의 강력한 예측 모델을 만드는 기법
Bagging (Bootstrap Aggregating)
Ensemble의 한 종류로, 여러 모델을 각각 다른 데이터 샘플에 학습시켜 예측을 평균 또는 투표로 결합하는 방식
e.g. 랜덤포레스트(Random Forest)
Boosting
약한 모델(weak learner)을 순차적으로 연결해서 성능을 점점 높이는 방식
이전 모델이 틀린 부분을 보완하는 방향으로 다음 모델이 학습
Stacking
여러 다른 종류의 모델의 출력을 다시 조합해서 최종 예측을 하는 방식
보통 1단계 모델들의 결과를 메타 모델(meta-model)이 입력으로 받아 최종 예측
3. Weight Decay
- Weight parameter는 노드와 노드 간의 관계를 나타냄
→ 숫자가 커질수록 강한 관계 - 또한, 보통 학습이 진행될수록 Weight의 크기가 커짐
- 손실 함수에 Weight의 가중치 크기에 대한 패널티 항을 추가
→ 전체적인 관계의 강도를 제한하여 출력 노드가 다수의 입력 노드로부터 많이 배우지 않도록 제한
→ 과도한 weight 확장을 방지하여 과적합 방지
L2 Regularization (가장 일반적)
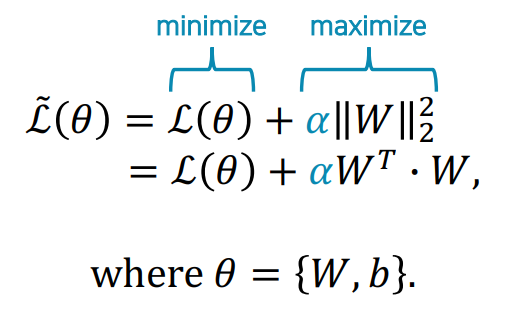
L1 Regularization
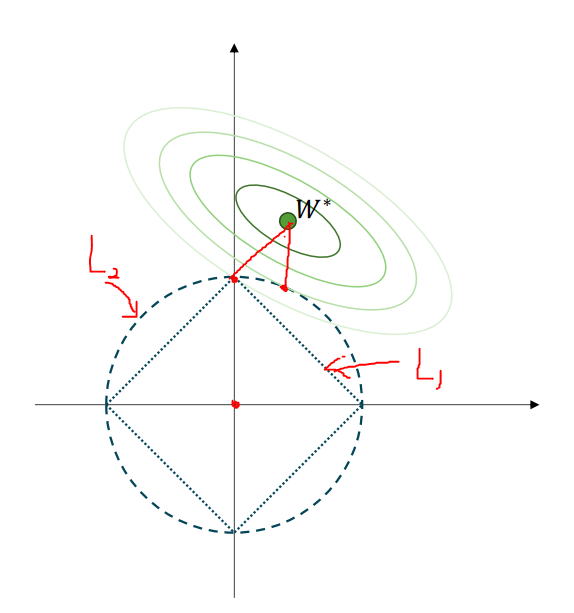
| 항목 | L1 Norm | L2 Norm |
|---|---|---|
| 수식 | ||
| 별명 | Lasso | Ridge |
| 가중치 처리 | 일부 가중치를 완전히 0으로 만듦 | 모든 가중치를 작게 유지 |
| 효과 | Feature Selection 가능 | Regularization 중심 |
| 결과 | 희소한 모델 생성 | 부드러운 모델 생성 |
- 일반적으로 bias는 regularization 대상에서 제외
- Hyper-parameter α를 통해 두 term 사이의 균형을 조절
- PyTorch에서는 optimizer 파라미터로
weight_decay사용 - 너무 강하게 regularization을 걸게 되는거라, 실제로 많이 쓰는 방법은 아님
4. Data Augmentation
- 기존 데이터에 노이즈나 변형을 주어 학습 데이터를 확장
- 특히, 데이터가 적은 상태에서 주로 사용하는 방법
→ 데이터가 적으면 bias가 되게 심할것이니까! - 핵심 특징(feature)을 유지한 채, 입력 분포를 다양화하여 과적합 방지
- 보통은 핵심 특징을 보존하기 위해 휴리스틱한 방법을 사용
- 규칙을 통해 증강(augment)하는 것은 옳지 않음
→ 모델이 그 규칙을 배워버림
→ Ramdomness가 필요함!
이미지 분야 예시
- Salt & Pepper noise: 노이즈를 추가하여 화질을 일부로 안 좋게 하는 것
(이미지에 갑자기 생기는 흰 점(소금)과 검은 점(후추) 같은 잡음) - RGB 노이즈 추가
- 회전 (Rotation)
- 좌우 반전 (Flipping)
- 위치 이동 (Shifting)
텍스트 분야 예시
- 단어 생략 (Dropping): 문장에 임의로 단어 빵꾸 뚫기
- 단어 위치 바꾸기 (Exchange): 임의로 대상 단어를 주변 단어와 위치 교환 (한국어는 매우 효과적)
생성 모델 활용
- AutoEncoder(AE), GAN 등을 통해 새로운 샘플 생성
- 단점: 완전히 새로운 개념 학습은 어려움 (생성 모델도 이미 특정 데이터만 보고 학습된 모델이기 때문에)
- 장점: 최적화에서 유리, 노이즈 강건성 향상
5. Dropout
- 과적합(overfitting)을 막기 위한 Regularization 기법 중 하나로, 학습 시 임의로 뉴런을 비활성화하여 특정 노드에 의존하지 않도록 함
효과
- 공동 적합(Co-adaptation) 방지
공동 적합 (Co-adaptation)
여러 뉴런들이 같은 방식으로 항상 함께 작동하면 학습이 편중될 수 있음
e.g. 뉴런 A가 항상 B와 같이 작동해서 결과를 내는 방식이면, A나 B가 없어지면 성능이 확 떨어짐
→ 학습 중 랜덤으로 뉴런을 제거해서, 각 뉴런이 독립적으로도 잘 작동하도록 강제 - 학습 시마다 다른 뉴런 조합으로 네트워크가 만들어짐
→ 즉, 매번 다른 작은 모델들이 학습되고, 추론할 때는 그것들을 평균낸 효과가 발생
→ 앙상블 효과 (과적합 방지, 일반화 성능 ↑)
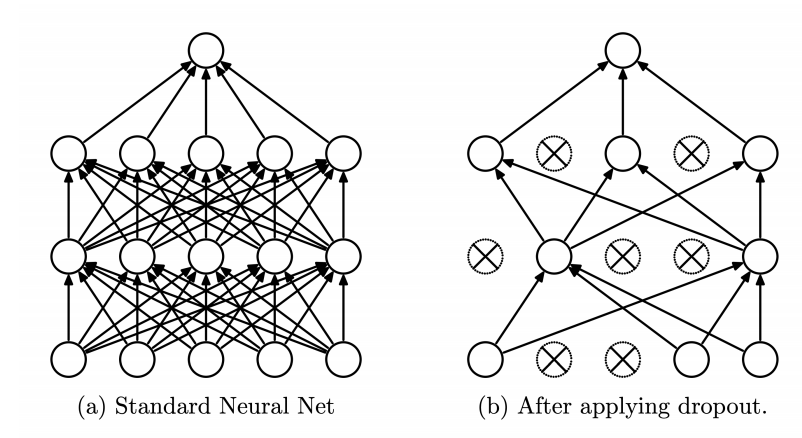
동작 방식
- 학습(Training) 시
model.train()- 확률 p로 뉴런을 랜덤하게 drop (turn-off)
- 추론(Validataion, Test) 시
model.eval()- drop out 꼭 꺼줘야 함!
- 모든 뉴런 사용, 대신 weight에 p를 곱해 보정
- 하지만 학습 때보다 평균적으로 배 더 큰 입력을 받게 될 것
- 즉, 더 적은 뉴런을 사용해서 학습되었으니, 추론 시에도 동일한 스케일로 보정 필요!
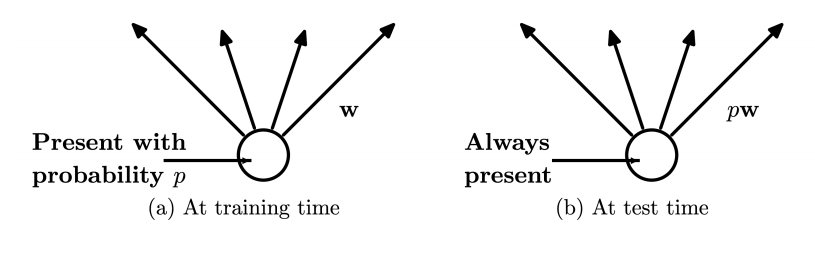
적용 위치
- 일반적으로: Linear Layer → Activation → Dropout → 다음 Layer
- 하이퍼 파라미터 p 필요
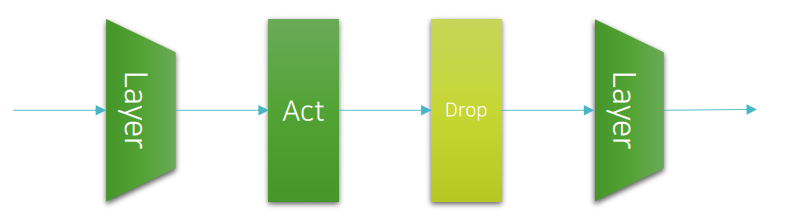
- 하이퍼 파라미터 p 필요
장단점
- 장점:
- Generalization error 감소
- 단점:
- 학습 속도 저하
- 하이퍼파라미터 p 추가
6. Batch Normalization
개요
- 학습 속도를 높이고 일반화 성능 향상
- 각 층의 입력을 정규화하여 internal covariance shift 문제 완화
- 입력을 정규화(Standardization)후 scaling(γ), shifting(β) 파라미터로 보정
- Hyper-Parameter의 추가 없이 빠른 학습과 높은 성능 모두 보장!
- RNN 빼고 모두 사용가능 (대신 Layer Normalization 사용 가능)
내부 공변량 변화(Internal Covariance Shift)
- 학습 중 네트워크 각 층에 들어오는 입력값의 분포가 계속 바뀌는 현상
- 즉, Layer마다 Input data의 분포가 달라지게 되어, 모델은 결국 일관적인 학습이 어려워짐
e.g.어떤 층의 출력이 원래 평균 0, 표준편차가 1 그런데 학습이 되면서 평균이 10, 표준편차가 5로 바뀐다면? → 다음 층은 완전히 다른 분포의 입력을 받게 되고, 다시 적응해야 함공변량 변화(covariate shift)
학습 데이터의 분포가 테스트 데이터의 분포와 다른 상황을 의미
수식
- x: 입력, μ: 평균, σ: 표준편차, γ, β: 학습 가능한 파라미터, ε: 매우 작은 값
- |μ| = |σ| = (vector_size, )

- 정규화하고 표현력을 잃지 않도록 다시 스케일 조정 및 이동
학습 vs 추론
- Drop out과 마찬가지로 학습과 추론 단계에서 모드가 달라져야 함
- 학습(Training) 시
model.train()- mini-batch 기준 평균/표준편차 계산
- 추론(Validataion, Test) 시
model.eval()- moving average 통계 사용 (미래 데이터 보는 것은 cheating)
- 지금까지의 입력을 통해 평균/표준편차 계산
적용 위치
- 보통 두 가지 방식:
1) Linear → Activation → BN
2) Linear → BN → Activation - Dropout 대체 가능
7. Dropout vs Batch Normalization
| 항목 | Dropout | Batch Normalization |
|---|---|---|
| 목적 | 과적합 방지 | 학습 안정화 및 일반화 |
| 방식 | 뉴런 무작위 비활성화 | 입력 정규화 + 재스케일링 |
| 장점 | Generalization 향상 | 빠른 수렴, 성능 향상 |
| 단점 | 학습 느림, p 설정 필요 | 추가 계산 필요 |
| Mode 전환 | 필요 (train/eval) | 필요 (train/eval) |
model.eval()을 호출하면 Dropout과 Batch Normalization이 자동으로 "inference 모드"로 전환
