해당 글은 FastCampus - '[skill-up] 처음부터 시작하는 딥러닝 유치원 강의를 듣고,
추가 학습한 내용을 덧붙여 작성하였습니다.
1. 행렬 곱 (Matrix Multiplication)
1.1 행렬 곱이란?
- Inner Product (내적) 또는 Dot Product (점곱) 이라고도 불림
- 딥러닝의 핵심 연산 중 하나
- Matrix(+ vector, scalar) 연산까지만 정의가 되어있고,
Tensor끼리의 연산은 이 Matrix 연산을 활용해서 계산
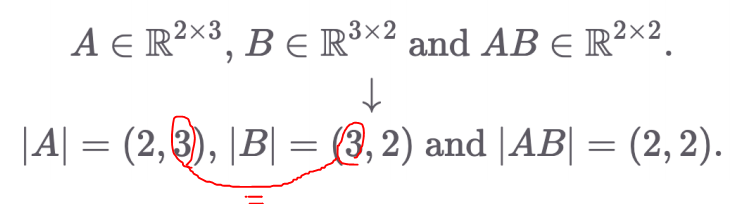
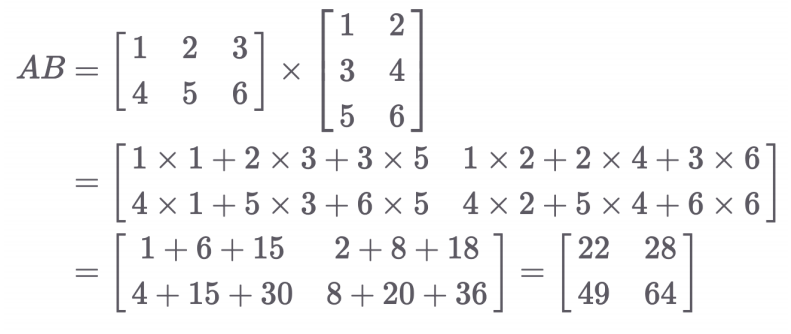
- 각 Matrix의 입력, 출력 차원의 shape을 알아야 왜 에러가 났는지 디버깅 가능
- PyTorch 코드:
z = torch.matmul(x, y)
# x*y는 elemetalwise 곱셈이다!1.2 벡터-행렬 곱셈 (Vector-Matrix Multiplication)
- 입력, 출력 차원 맞춰주는 원리는 동일함
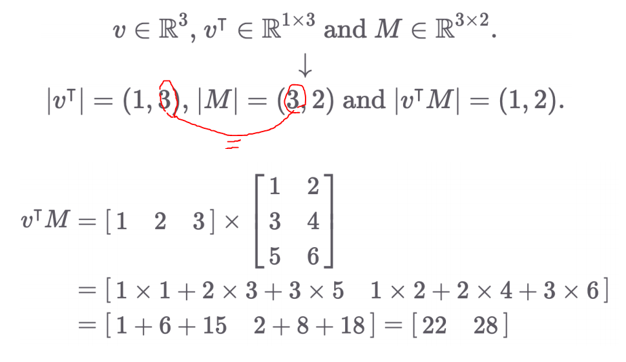
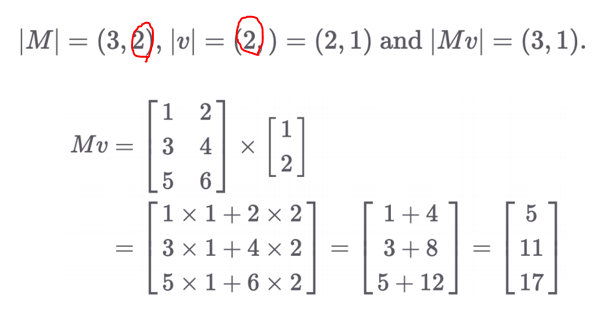
1.3 배치 행렬 곱셈 (Batch Matrix Multiplication, BMM)
- 텐서 곱이라는 건 정의되어 있지 않음 → 텐서를 여러개의 행렬 쌍이라고 생각
- 같은 갯수의 행렬 쌍들에 대해서 병렬로 행렬 곱 실행
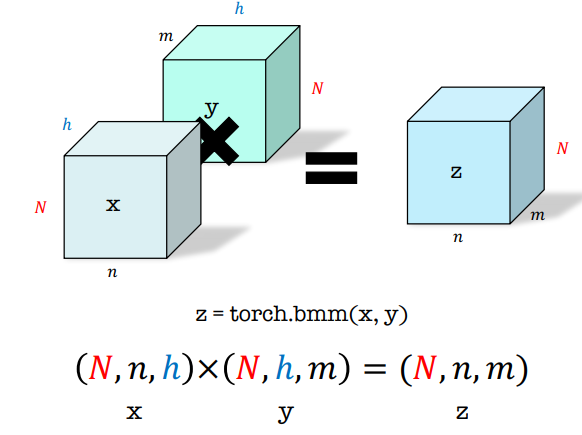
- (n, h) X (h, m) 이니까 h가 같아야 함
- N 또한 같아야 함 즉, 병렬 곱을 N번 수행하는 것
- 4차원이라면 ? 3차원과 사실 동일하게 간주 가능
(N1, N2, n, h) x (N1, N2, h, m) == (N1 N2, n, h) x (N1 N2, h, m) - 이러한 병렬 연산이 매우 많아지면서 GPU의 진가가 발휘되는 것
2. Linear Layer (선형 계층)
2.1 Linear Layer란?
- 딥러닝 신경망에서 가장 기본적인 구성 요소로, 내부 파라미터(가중치 W와 편향 b)에 따라 선형 변환을 수행하는 함수
- 즉, 가상의 함수 f*를 모사하기 위한 구성 요소!
- 모든 입력의 노드는 모든 출력의 노드와 연결이 되어있기 때문에,
Fully Connected (FC) Layer라고도 불림 - 원하는 결과를 뱉도록 하는 파라미터 값을 찾는 게 바로 학습
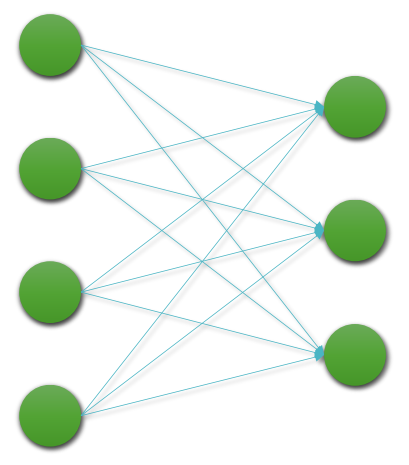
노드 == 퍼셉트론 == 뉴런
2.2 작동 방식
-
각 입력 노드들에 weight(가중치)를 곱하고 모두 합친 뒤, bias(편향)을 더함
→ 행렬 곱으로 구현 가능
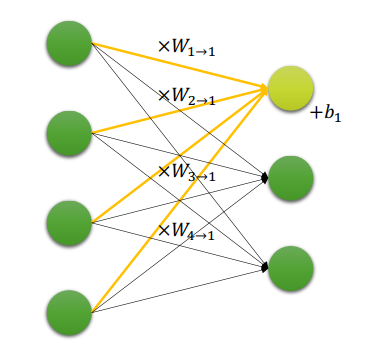
-
n차원에서 m 차원으로의 선형 변환 함수
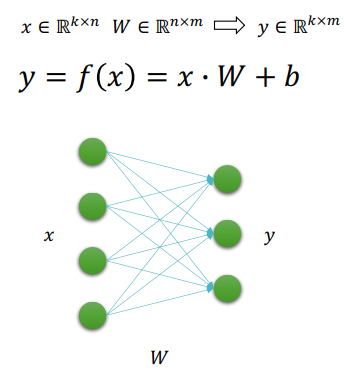
2.3 수식 표현 방법
-
x를 미니배치에 관계 없이 단순히 하나의 벡터로 볼 경우
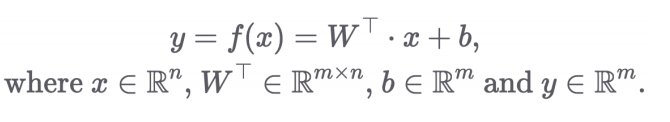
-
x를 미니배치(N개) 텐서로 표현할 경우 (주로 사용)
→ 미니배치에 대한 병렬 처리가 가능
2.4 Pytorch 코드
- 단순 Linear layer 만들어 보기
W = torch.FloatTensor([[1, 2],
[3, 4],
[5, 6]])
b = torch.FloatTensor([2, 2])
x = torch.FloatTensor([[1, 1, 1],
[2, 2, 2],
[3, 3, 3],
[4, 4, 4]])
print(W.size(), b.size(), x.size())
def linear(x, W, b):
y = torch.matmul(x, W) + b
return y
y = linear(x, W, b)
print(y.size())- 학습이 가능한 Linear layer 만들어 보기
nn.Module
- PyTorch에서 모델을 정의하기 위한 base 클래스 (추상 클래스라고 하기엔 init과 forward 함수를 제외하고는 그대로 사용 가능)
- 파라미터 관리, 파이프라인 처리, 자동 미분, 모델 훈련 및 평가 기능을 쉽게 처리하기 위해 상속 받는 클래스
- init과 forward는 override 필수!
forward
- 딥러닝 모델의 순전파 (forward pass)를 정의하는 메서드
- 입력 데이터를 네트워크를 통과시키며 출력 값을 계산하는 과정
backward
- 딥러닝 모델의 역전파 (backward pass)를 정의하는 메서드
- 출력과 실제 값의 차이를 기반으로 기울기(gradient)를 계산하여 가중치 업데이트를 위한 정보를 제공
class MyLinear(nn.Module): ## nn.Module: __init__과 forward override 필수!
def __init__(self, input_dim=3, output_dim=2):
self.input_dim = input_dim
self.output_dim = output_dim
super().__init__() #부모 클래스 초기화
self.W = nn.Parameter(torch.FloatTensor(input_dim, output_dim)) # nn.Parameter로 wrapping 해줘야 파라미터로 등록이 되고 학습이 가능함
self.b = nn.Parameter(torch.FloatTensor(output_dim))
# You should override 'forward' method to implement detail.
# The input arguments and outputs can be designed as you wish.
def forward(self, x):
# |x| = (batch_size, input_dim) # 이 dimension 주석 다는 습관이 매우 좋다!
y = torch.matmul(x, self.W) + self.b
# |y| = (batch_size, input_dim) * (input_dim, output_dim)
# = (batch_size, output_dim)
return y
linear = MyLinear(3, 2)
y = linear(x)
print(y.size())
for p in linear.parameters():
print(p)
# Parameter containing:
# tensor([[-0.4768, 0.3792, 0.2139],
# [-0.2055, -0.3338, -0.0495]], requires_grad=True)
# Parameter containing:
# tensor([-0.3775, -0.5481], requires_grad=True)- 은 사실 nn.Linear 클래스가 이미 만들어져 있음
linear = nn.Linear(3, 2)
y = linear(x) # forward도 자동으로 진행
#
#3. Summary
| 항목 | 설명 |
|---|---|
| 행렬곱 | 딥러닝의 기본 연산. 입력과 가중치의 내적 |
| BMM | 여러 행렬 쌍을 병렬로 곱하는 연산 |
| Linear Layer | 선형변환을 수행하는 신경망의 기본 구성 |
| 수식 | y = xW + b 형태의 선형함수 |
| 파라미터 | W (가중치), b (편향) |
4. 실전에서 중요한 점
- Linear Layer의 파라미터인 W와 b를 잘 학습시키는 것이 핵심
- 이 과정을 통해 신경망은 주어진 입력에 대해 원하는 출력을 내도록 학습됨

만두는 목말라