해당 글은 FastCampus - '[skill-up] 처음부터 시작하는 딥러닝 유치원 강의를 듣고,
추가 학습한 내용을 덧붙여 작성하였습니다.
1. 다시, 딥러닝의 목적은?
- 우리의 목적은 데이터를 입력했을 때, 원하는 출력을 반환하는 가상의 함수를 모사하는 것
- Linear Layer를 통해 이러한 함수를 근사함
- 해당 함수가 얼마나 잘 작동하는지를 측정할 수 있는 기준이 필요함
- 이 기준이 바로 Loss Function
2. Loss란?

- Loss(손실값): 실제 출력값(ŷ)과 목표 출력값(y) 사이의 차이
- Loss가 작을수록 모델이 목표 함수에 잘 가까워진다고 볼 수 있음
- 따라서 Loss가 작은 Linear Layer를 선택하는 것이 중요
3. Loss Function의 개념
- Linear Layer의 파라미터를 바꿀 때마다 Loss 값을 계산
- Loss Function은 다음과 같은 함수로 이해할 수 있음
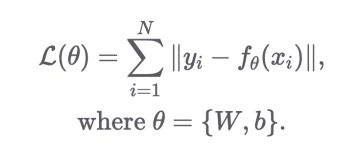
입력: Linear Layer의 파라미터
출력: 해당 파라미터에서의 Loss 값4. 대표적인 Loss 계산 방식
4.1 유클리디안 거리 (Euclidean Distance)
- L2 (L1은 절대값)
- 두 점 사이의 직선 거리

4.2 RMSE (Root Mean Square Error)
- 평균 제곱 오차의 제곱근
- 유클리디안 거리에서 차원의 크기만큼 Normalize 한 것
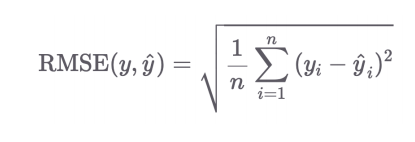
4.3 MSE (Mean Square Error)
- 가장 자주 사용되는 Loss Function
- RMSE에서 제곱근을 생략한 형태 (최적화 방향은 동일)
- 1/n도 제거해서 쓰기도 함 (어차피 최적화 방향은 바뀌지 않으니)
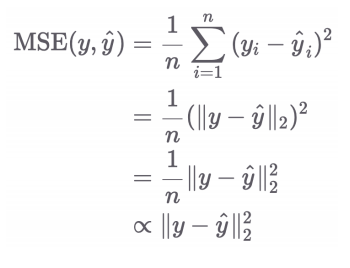
- 여러 개의 batch 경우

- pytorch 코드
# 직접 구현
def mse(x_hat, x):
# |x_hat| = (batch_size, dim)
# |x| = (batch_size, dim)
y = ((x - x_hat)**2).mean()
return y
# torch.nn.functional 라이브러리의 mse_loss 함수 사용
import torch.nn.functional as F
print(F.mse_loss(x_hat, x)) # default: mean
print(F.mse_loss(x_hat, x, reduction='sum'))
print(F.mse_loss(x_hat, x, reduction='none'))
# torch.nn.MSELoss 클래스 사용
import torch.nn as nn
mse_loss = nn.MSELoss()
mse_loss(x_hat, x)
5. Summary
-
우리가 원하는 함수를 잘 모사하려면,
- 학습용 입력 데이터를 Linear Layer에 넣고
- 그 결과 출력값(ŷ)과 목표값(y)의 차이를 계산해
- 그 차이를 최소화하는 파라미터(θ)를 찾아야 함
-
따라서, 학습의 핵심은 Loss를 최소화하도록 모델을 조정하는 것임

만두는 목말라