
데이터 프레임
생성 & 구조
names_sr = pd.Series(names,index=index,name='이름')
ages_sr = pd.Series(ages,index=index,name='나이')
display(names_sr)
display(ages_sr)
결과
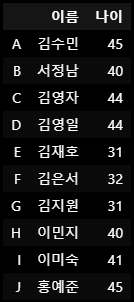
A 김수민
B 서정남
C 김영자
D 김영일
E 김재호
F 김은서
G 김지원
H 이민지
I 이미숙
J 홍예준
Name: 이름, dtype: object
A 45
B 40
C 44
D 44
E 31
F 32
G 31
H 40
I 41
J 45
Name: 나이, dtype: int64df1 = pd.DataFrame(names_sr)
df1결과

df1['나이'] = ages
df1결과
jobs = [fake.job() for _ in range(10)]
jobs
결과
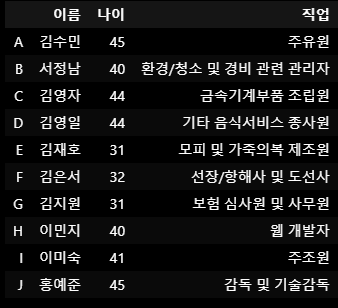
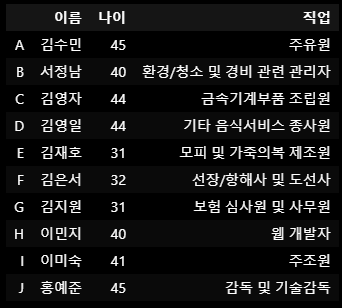
['주유원',
'환경/청소 및 경비 관련 관리자',
'금속기계부품 조립원',
'기타 음식서비스 종사원',
'모피 및 가죽의복 제조원',
'선장/항해사 및 도선사',
'보험 심사원 및 사무원',
'웹 개발자',
'주조원',
'감독 및 기술감독']df_dict = {'이름':names_sr,'나이':ages_sr,'직업':jobs}
df_dict
결과
{'이름': A 김수민
B 서정남
C 김영자
D 김영일
E 김재호
F 김은서
G 김지원
H 이민지
I 이미숙
J 홍예준
Name: 이름, dtype: object,
'나이': A 45
B 40
C 44
D 44
E 31
F 32
G 31
H 40
I 41
J 45
Name: 나이, dtype: int64,
'직업': ['주유원',
'환경/청소 및 경비 관련 관리자',
'금속기계부품 조립원',
...
'선장/항해사 및 도선사',
'보험 심사원 및 사무원',
'웹 개발자',
'주조원',
'감독 및 기술감독']}df2 = pd.DataFrame(df_dict)
df2결과
df1['직업'] = jobs
df1 == df2결과

인덱싱 & 슬라이싱
df2['나이']['A']
결과
45df2.loc['A']
df2.iloc[3]
결과
이름 김영일
나이 44
직업 기타 음식서비스 종사원
Name: D, dtype: object
df2.loc['A':'F','나이']
df2.iloc[1:4,2]
결과
B 환경/청소 및 경비 관련 관리자
C 금속기계부품 조립원
D 기타 음식서비스 종사원
Name: 직업, dtype: objectage_above_40 = df2['나이'] > 40
age_above_40
결과
A True
B False
C True
D True
E False
F False
G False
H False
I True
J True
Name: 나이, dtype: booldf2[age_above_40]
df2[df2['나이']>30]결과
속성
df2.index
결과
Index(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'], dtype='object')df2.columns
결과
Index(['이름', '나이', '직업'], dtype='object')df2.values
결과
array([['김수민', 45, '주유원'],
['서정남', 40, '환경/청소 및 경비 관련 관리자'],
['김영자', 44, '금속기계부품 조립원'],
['김영일', 44, '기타 음식서비스 종사원'],
['김재호', 31, '모피 및 가죽의복 제조원'],
['김은서', 32, '선장/항해사 및 도선사'],
['김지원', 31, '보험 심사원 및 사무원'],
['이민지', 40, '웹 개발자'],
['이미숙', 41, '주조원'],
['홍예준', 45, '감독 및 기술감독']], dtype=object)df2.dtypes
결과
이름 object
나이 int64
직업 object
dtype: objectdf2.shape
결과 (10. 3)df2.size
결과 30df2_T = df2.T
df2_T결과

df2_T.shape
결과 (3, 10)기능
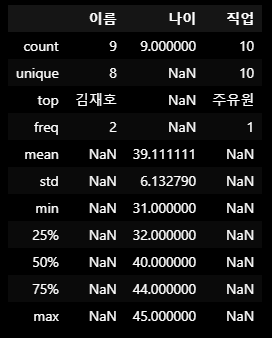
df2.describe(include='all')결과
df2.info()
결과
<class 'pandas.core.frame.DataFrame'>
Index: 10 entries, A to J
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 이름 9 non-null object
1 나이 9 non-null float64
2 직업 10 non-null object
dtypes: float64(1), object(2)
memory usage: 620.0+ bytesdf2.isna()결과

df2.dropna(subset=['이름','나이'])결과
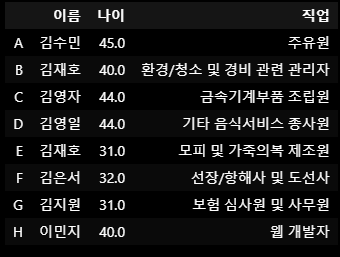
df2.drop(index=['A','C'])
df2.drop(columns=['나이'])결과
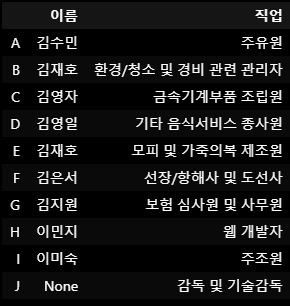
df2.sort_values(by=['나이','이름'],na_position='first',ignore_index=True)결과

이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
