Chapter1
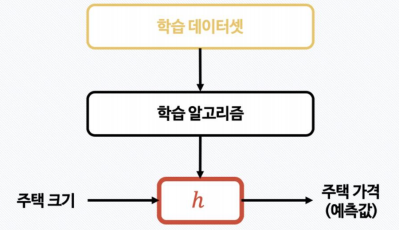
1. 머신러닝이란?
- 내가 준 데이터로 나 대신 공부하고 나 대신 대답하는 것
2. IrisClassification - 손으로 분류하기

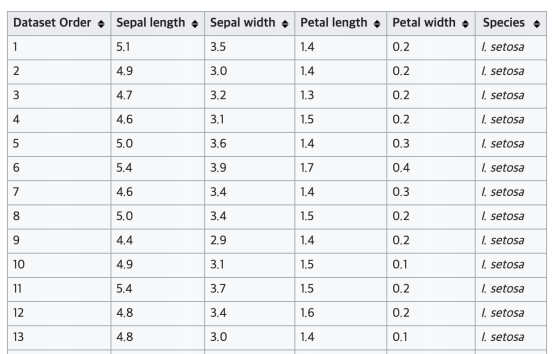
- Iris 품종 분류에서는 Versicolor, Virginica, Setosa 3종류가 있음
- 꽃잎과 꽃받침의 길이, 넓이 정보를 제공하여 주고 이를 통해 3종의 품종을 분류함
-
Iris 데이터셋에서 Sepal length, Sepal width, Petal length, Petal width는 특성, Species는 Label
-
해당 데이터에서 특성을 통해 품종을 분류한다
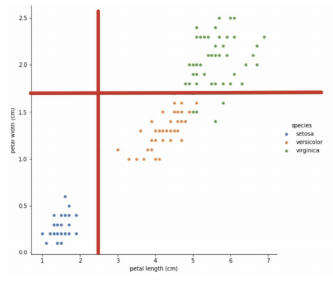
3. IrisClassifiacation - Decision Tree
- Decision Tree의 분할 기준
- 엔트로피 개념: 무질서의 정도, 불확실성

-> 질서 정연하면 낮은 엔트로피
-> 무질서해질수록 높은 엔트로피
- 자연스럽다는 것은 엔트로피가 높아지는 것
-
엔트로피가 가장 작은 곳이 경계선 즉, 분할 기준이 되는 선
-
지니 계수: log를 사용하지 않기 위해 생긴 방법
-
동일한 개념을 가지고 있기에 더 작은 숫자일수록 질서정연한 것
-
Scikit Learn을 활용
Chapter2
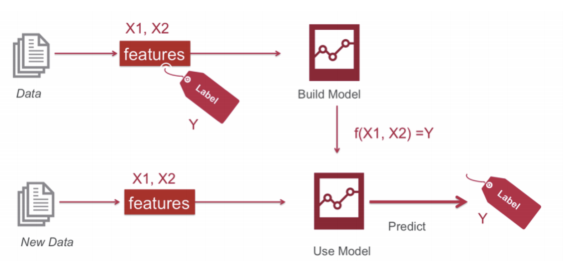
1. 이전 챕터 wrap-up
- 지도학습: 학습대상이 되는 데이터에 정답을 붙여서 학습 시키고, 모델을 얻엇 완전히 새로운 데이터에 모델을 사용해서 답을 얻고자 하는 것
2. 머신러닝 데이터는 왜 나누나요
- 과적합: 내가 훈련용으로 제공한 data에 너무 최적화 된 것
- 과적합을 해소하기 위해서는 데이터를 분리하면 된다
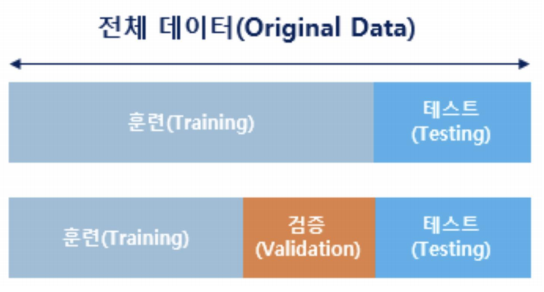
- 모델을 성능을 높이는 것이 아닌 훈련용 data에 너무 fit되는 경우를 방지하고 일반성을 확보할 수 있을지 확인하기 위한 것
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
