Chapter6 Label Encoder, Scaler
Label encoder
- 글자를 만나면 숫자로 바꿔준다
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(df['A'])le.fit_transform(df["A"])Min-Max Scaler
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
mms.fit(df)df_mms = mms.transform(df)
df_mmsmms.fit_transform(df_mms)Standard Scaler
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(df)df_ss = ss.transform(df)
df_ssss.fit_transform(df)Robust Scaler
from sklearn.preprocessing import RobustScaler
rs = RobustScaler()df_rs = rs.fit_transform(df)- 아웃라이어에 강하다는 특징이 있음
각 스케일러의 차이
df_scaler["MinMax"] = mm.fit_transform(df)
df_scaler["Standard"] = ss.fit_transform(df)
df_scaler["Robust"] = rs.fit_transform(df)
df_scaler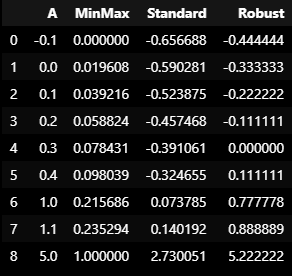
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style = 'whitegrid')
plt.figure(figsize = (16, 6))
sns.boxplot(data = df_scaler, orient = "h")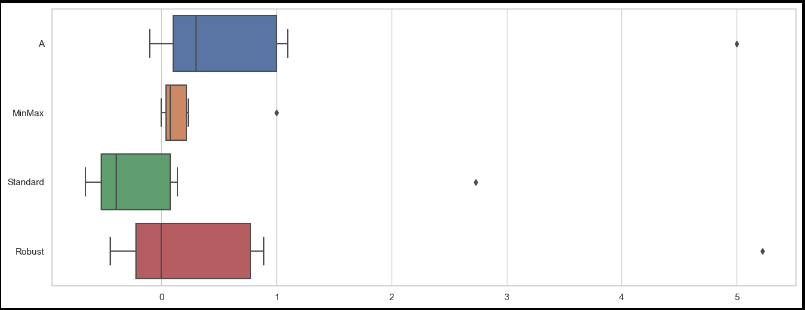
- 어느 스케일러가 어디에 좋다고 정해져 있지는 않음
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
