Chapter 10 하이퍼파라미터 튜닝
- 특별한 학술적이거나 수학적 분포를 찾기 어려운 상태에서 변화시켜야 할 파라미터
교차검증
-
과적합: 모델이 학습데이터에만 과도하게 최적화된 현상으로, 일반화된 데이터에서는 예측 성능이 과하게 떨어짐
-
Holdout

-
k-fold cross validation
-> validation의 역할을 수행하는 부분을 계속 옮겨다니면서 확인하는 것
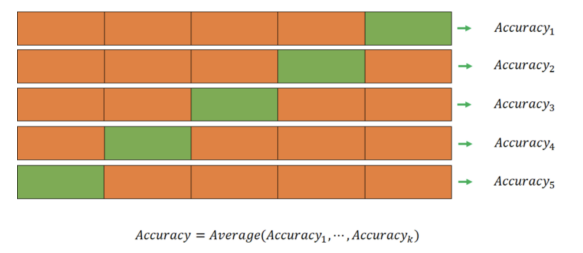
-> 대부분 5개로 나누는 경우가 많음
-
stratified k-fold cross validation
-> 전체 데이터를 나눌때 비율도 고려하는 것
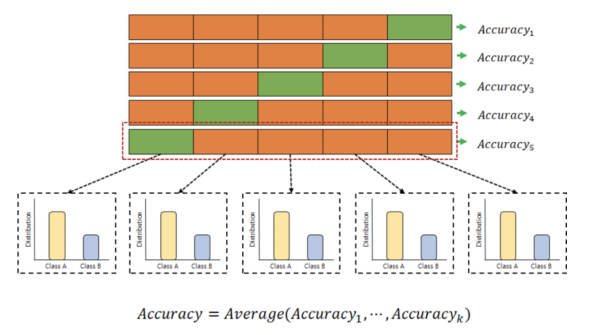
-
교차검증과 모델의 수치적 성능은 연관이 없음
-
모델의 성능을 객관적으로 관찰하기 위해 교차 검증을 적용함
-
k-fold 예시
from sklearn.model_selection import KFold
kfold = KFold(n_splits = 5)
wine_tree_cv = DecisionTreeClassifier(max_depth = 2, random_state = 13)for train_idx, test_idx in kfold.split(X):
print(len(train_idx), len(test_idx))cv_accuracy = []
for train_idx, test_idx in kfold.split(X, y):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
cv_accuracy[0.6007692307692307,
0.6884615384615385,
0.7090069284064665,
0.7628945342571208,
0.7867590454195535]
- StratifiedKFold 예시
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth = 2, random_state = 13)
cv_accuracy = []
for train_idx, test_idx in skfold.split(X, y):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
cv_accuracy[0.5523076923076923,
0.6884615384615385,
0.7143956889915319,
0.7321016166281755,
0.7567359507313318]
-
accuracy값이 더 떨어지는 건 현상
-
간단하게 cross validation
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth= 2, random_state = 13)
cross_val_score(wine_tree_cv, X ,y ,scoring = None, cv = skfold)하이퍼파라미터 튜닝
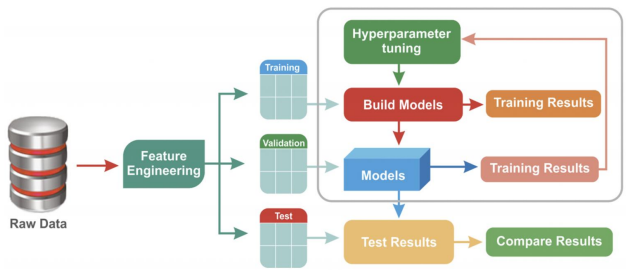
-
training data로 model 구현
-
validation data로 model 성능 확인
-
val data 성능 확인 결과를 통해 설정 값을 바꾸는데 이를 Hyperparameter tuning이라 함
-
하이퍼파라미터 튜닝을 통해 성능을 확인하고 모델을 확정하면 test data로 결과 확인
-
GridSearchCV는 최적의 파라미터를 찾아줌
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth' : [2, 4, 7, 10]}
wine_tree = DecisionTreeClassifier(max_depth = 2, random_state = 13)
gridsearch = GridSearchCV(estimator = wine_tree, param_grid = params , cv = 5)
gridsearch.fit(X, y)-> 격자를 만들어서 최적의 부분을 찾아내는 것
-> gridsearch 진행시 (pre_dispatch = '2*n+jobs') n+jobs 옵션을 높여주면 CPU 코어를 병렬로 활용하여 Core가 많을 경우 n_jobs를 높이면 속도가 빨라짐
import pprint
pp = pprint.PrettyPrinter(indent = 4)
pp.pprint(gridsearch.cv_results_)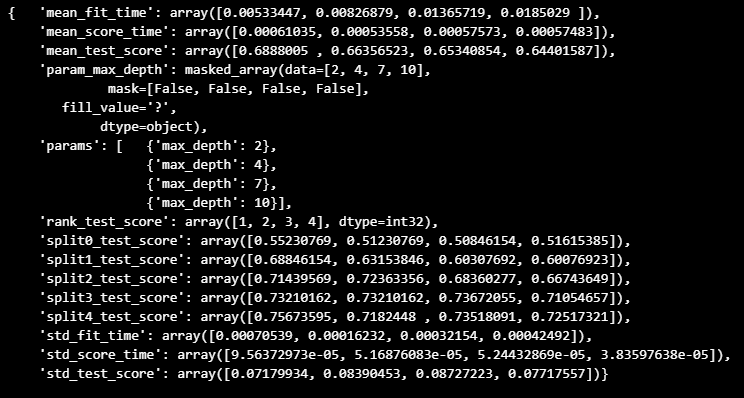
- 최적의 성능을 가진 모델 찾기
gridsearch.best_estimator_gridsearch.best_score_gridsearch.best_params_Chapter 11 정밀도와 재현율
- 정밀도와 재현율의 트레이드 오프
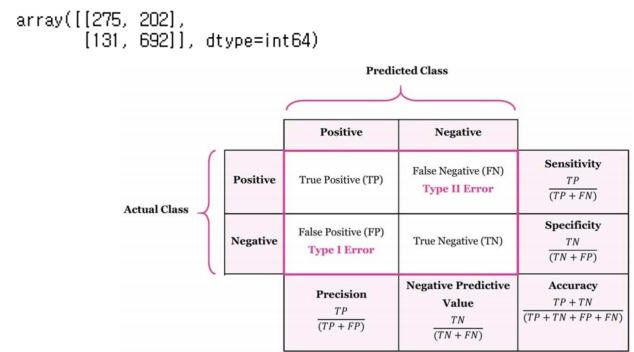
- 분류 모델에서 accuracy만 확인하는것이 부족할 때
from sklearn.metrics import classification_report, confusion_matrix
print(classification_report(y_test, y_pred_test) )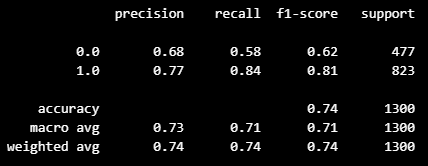
- precision_recall curve
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
plt.figure(figsize=(10, 7))
pred = lr.predict_proba(X_test)[:, 1]
precision, recall, thresholds = precision_recall_curve(y_test, pred)
plt.plot(thresholds, precision[:-1], label='precision')
plt.plot(thresholds, recall[:-1], label='recall')
plt.grid()
plt.legend()
plt.show() 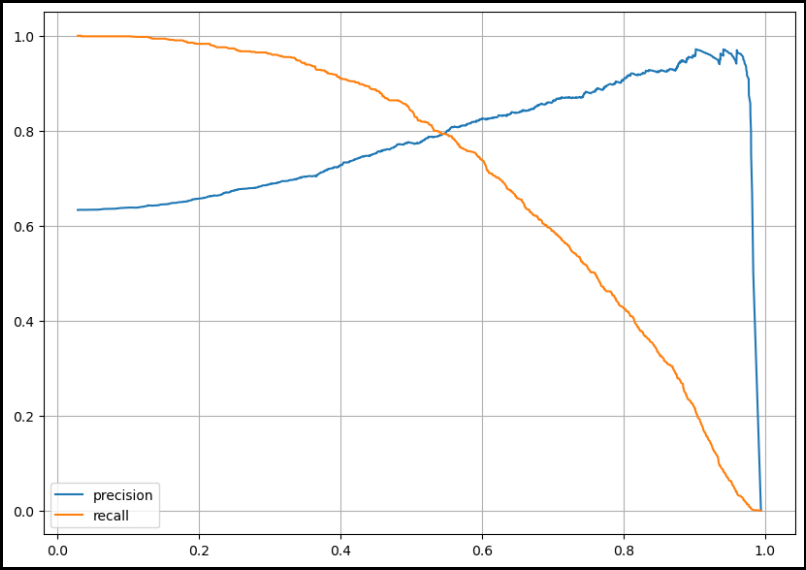
- threshold를 임의로 조정할 수는 있지만 그것이 과연 좋은지는 고민해 보아야 함
Chapter 12 kNN(최근접 이웃, k Nearest Neighbor)
-
새로운 데이터가 있을때 기존 데이터의 그룹 중 어떤 그룹에 속하는지 분류
-
k는 몇 번째 가까운 데이터까지 볼 것인가 정하는 수치
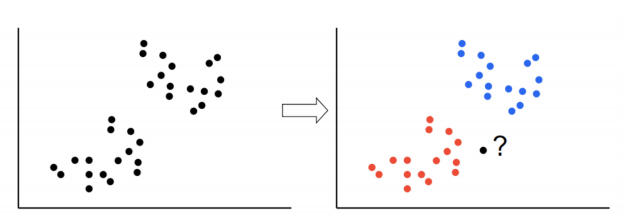
-
알고리즘은 모든 데이터와 새로운 데이터를 찾아서 계산하기 때문에 계산량이 많아짐
-
kNN 예시
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train) from sklearn.metrics import accuracy_score
pred = knn.predict(X_test)
accuracy_score(y_test, pred) from sklearn.metrics import confusion_matrix, classification_report
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred)) 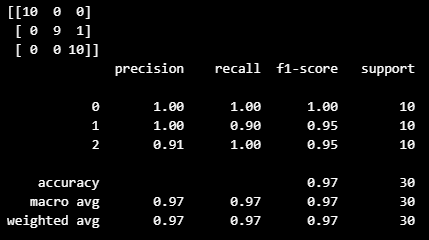
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
