Chapter 13 앙상블
-
앙상블: 다양한 모델을 사용하여 예측 성능을 보다 더 높이는 것
-
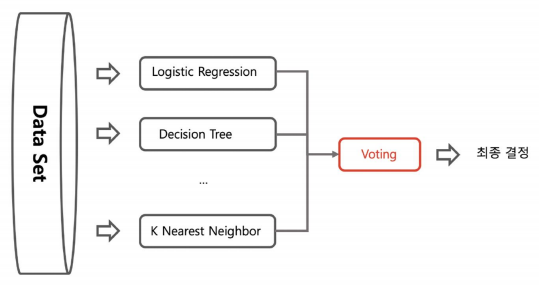
voting: 전체 데이터셋에 각각의 다른 기법을 사용하는 것
-
bagging: data set을 샘플링해서 같은 기법을 사용하는 것
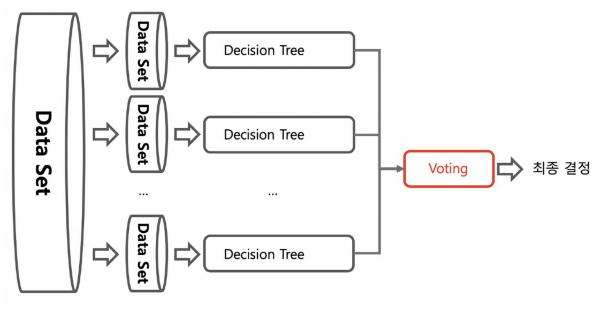
-> bagging에서는 데이터 중복을 허용해서 샘플링
-> 각각의 분류기에 데이터를 각각 샘플링해서 추출하는 방식은 부트스트래핑 분할 방식
- 랜덤포르세트 (Random Forest)는 배깅의 대표적인 방법으로 속도가 빠르고 다양한 영역에서 높은 성능을 보여줌
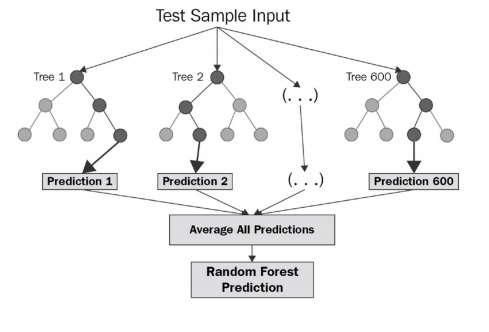
-> 결정 나무를 기본으로 하여 소프트보팅으로 최종 예측 결론을 얻음
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth':[6, 8, 10],
'n_estimators':[50, 100, 200],
}
rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(X_train, y_train) 
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
cv_results_df[['rank_test_score', 'param_max_depth', 'param_n_estimators', 'mean_test_score']]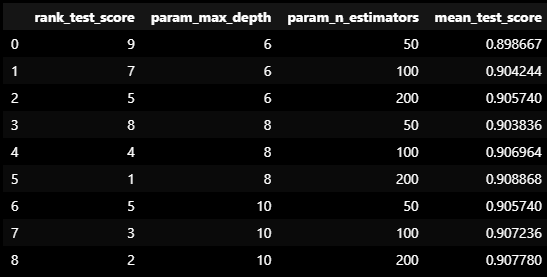
rf_clf_best = grid_cv.best_estimator_
rf_clf_best.fit(X_train, y_train) 
rf_clf_best_re = grid_cv.best_estimator_
rf_clf_best_re.fit(X_train_re, y_train) 
pred_re = rf_clf_best_re.predict(X_test_re)
accuracy = accuracy_score(y_test, pred_re)
accuracy0.8937902952154734
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
