
Chapter 14 금융 데이터
신용카드 부정 사용자 검출
- 신용카드 부정 사용자 검출 데이터
- 금융 데이터이고 기업의 기밀 보호를 위해서 대다수 특성의 이름이 삭제되어 있음
-
데이터의 불균형이 심각
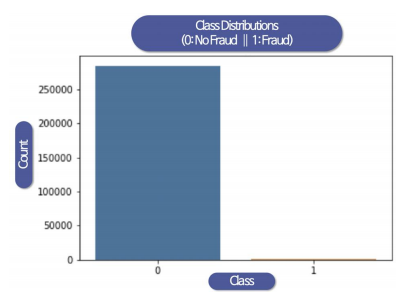
-
데이터의 불균형이 심해서 'stratify = y'를 사용
앙상블 기법 (Boosting)
- Boosting
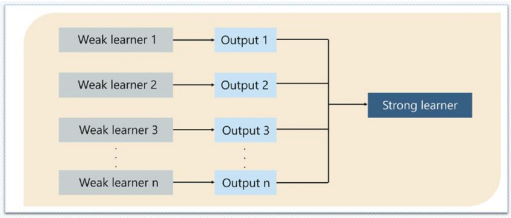
-> 여러 개의 약한 분류기(성능을 낮지만 빠른 것)가 순차적으로 학습을 하며, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해 다음 분류기가 가중치를 인가해서 학습을 이어 진행
- 배깅과 부스팅의 차이
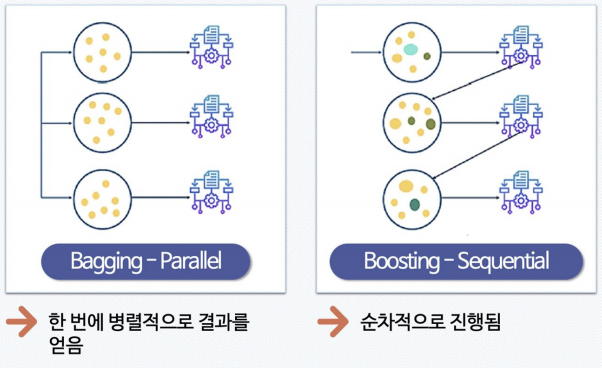
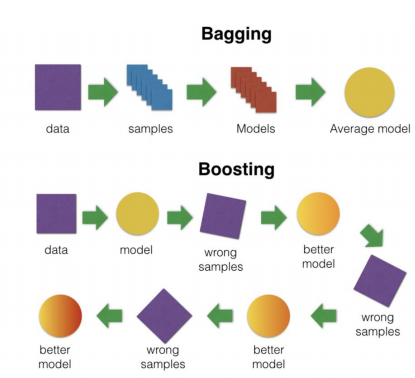
- 부스팅 기법
-> GBM: 가중치 업데이트 시 경사하강법 사용
-> XGBoost: GMB에서 PC의 파워를 효율적으로 사용하기 위한 다양한 기법에 채택, 빠른 속도와 효율 가짐
-> LightGBM: XGBoost보다 빠름
부정 사용 검출
-
accuracy는 높지만 recall이 떨어지는 문제를 가지고 있는 것이 사기 데이터의 특징
-
불균형이 매우 심함
-
Undersampling / Oversampling
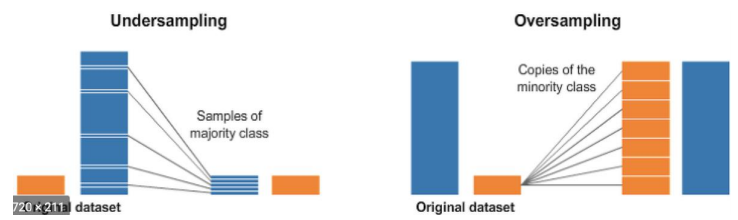
-> 데이터의 불균형이 극심할 때 불균형한 두 클래스의 분포를 강제로 맞추는 것
-> 언더샘플링: 많은 수의 데이터를 적은수를 데이터로 조정(적은 수의 데이터도 충분할 때 가능)
-> 오버샘플링: 원본데이터의 피처 값을 약간 변경하여 증식(SMOTE, k-NN 방법 등이 있음)
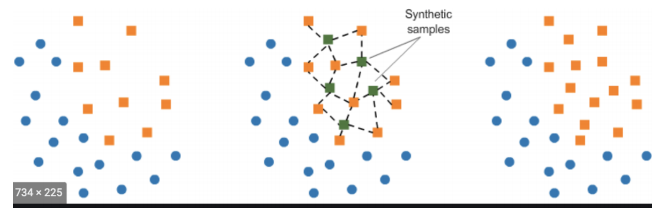
- imbalanced-learn 설치 후 SMOTE 적용
- train 데이터에서만 사용해야 함
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(x='Class', data=raw_data)
plt.show()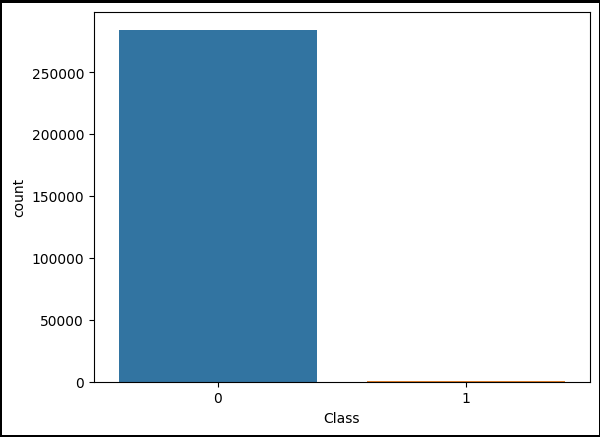
X = raw_data.iloc[:, 1:-1]
y = raw_data.iloc[:, -1]
X.shape, y.shape((284807, 29), (284807,))
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
stratify = y,
random_state=13)# train, test 간의 balance 확인
import numpy as np
np.unique(y_train, return_counts=True)
np.unique(y_test, return_counts=True)from sklearn.metrics import (accuracy_score, precision_score,
recall_score, f1_score, roc_auc_score)# 분류기 성능 평가 함수
def get_clf_eval(y_test, pred):
acc = accuracy_score(y_test, pred)
pre = precision_score(y_test, pred)
re = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
auc = roc_auc_score(y_test, pred)
return acc, pre, re, f1, aucfrom sklearn.metrics import confusion_matrix
def print_clf_eval(y_test, pred):
acc, pre, re, f1, auc = get_clf_eval(y_test, pred)
confusion = confusion_matrix(y_test, pred)
print('==> confusion matrix')
print(confusion)
print('====================')
print('==> accuracy: {0:.4f}, precision: {1:.4f}'.format(acc, pre))
print('==> recall: {0:.4f}, f1: {1:.4f}, auc: {2:.4f}'.format(re, f1, auc))from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(random_state=13, solver='liblinear')
lr_clf.fit(X_train, y_train)
lr_pred = lr_clf.predict(X_test)
print_clf_eval(y_test, lr_pred)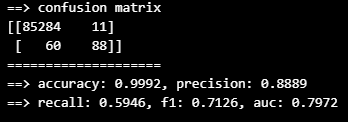
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(random_state=13, max_depth=4)
dt_clf.fit(X_train, y_train)
dt_pred = dt_clf.predict(X_test)
print_clf_eval(y_test, dt_pred)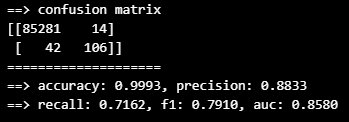
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(random_state=13, n_estimators=100)
rf_clf.fit(X_train, y_train)
rf_pred = rf_clf.predict(X_test)
print_clf_eval(y_test, rf_pred)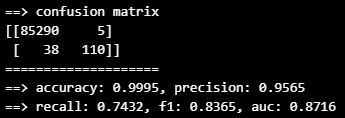
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(random_state=13, n_estimators=1000,
num_leaves=64, boost_from_average=False)
lgbm_clf.fit(X_train, y_train)
lgbm_pred = lgbm_clf.predict(X_test)
print_clf_eval(y_test, lgbm_pred)
def get_result(model, X_train, y_train, X_test, y_test):
model.fit(X_train, y_train)
pred = model.predict(X_test)
return get_clf_eval(y_test, pred)def get_result_pd(models, model_names, X_train, y_train, X_test, y_test):
col_names = ['accuracy', 'precision', 'recall', 'f1', 'roc_auc']
tmp = []
for model in models:
tmp.append(get_result(model, X_train, y_train, X_test, y_test))
return pd.DataFrame(tmp, columns=col_names, index=model_names)models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg.', 'DecisionTree', 'RandomForest', 'LightGBM']
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
results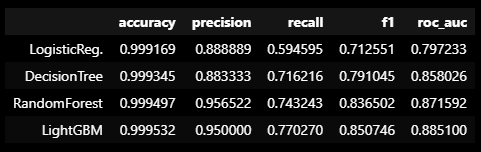
plt.figure(figsize=(10, 6))
sns.histplot(raw_data['Amount'], color='r', kde=True)
plt.ylim(0, 20000)
plt.show()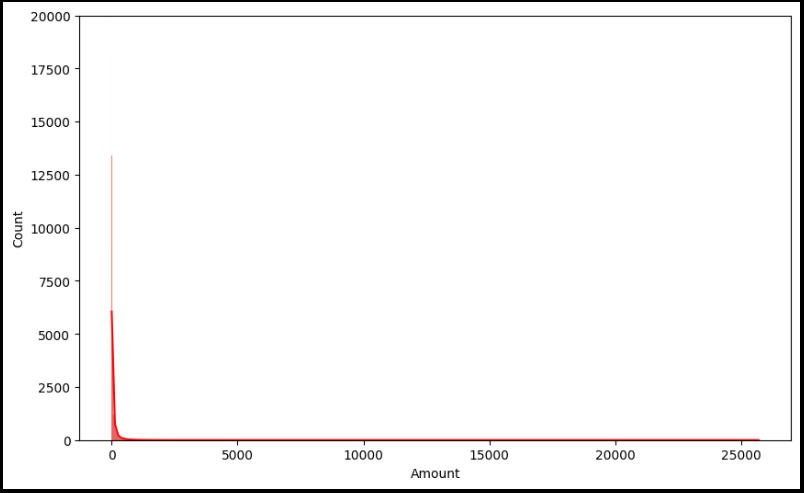
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
amount_n = scaler.fit_transform(raw_data['Amount'].values.reshape(-1, 1))
raw_data_copy = raw_data.iloc[:, 1:-2]
raw_data_copy['Amount_Scaled'] = amount_n
raw_data_copy.head()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,
stratify=y,
random_state=13)
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg.', 'DecisionTree', 'RandomForest', 'LightGBM']
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
results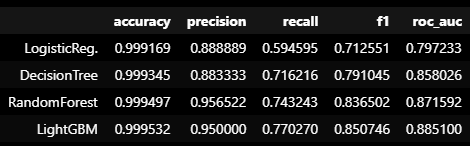
amount_log = np.log1p(raw_data['Amount'])
raw_data_copy['Amount_Scaled'] = amount_logplt.figure(figsize=(10, 6))
sns.histplot(raw_data_copy['Amount_Scaled'], color='r', kde=True)
plt.show()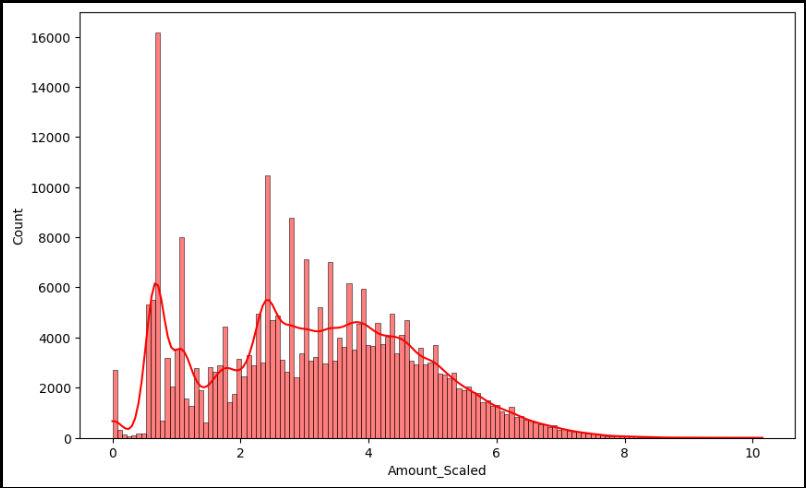
X = raw_data_copy
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,
stratify=y,
random_state=13)
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg.', 'DecisionTree', 'RandomForest', 'LightGBM']
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
results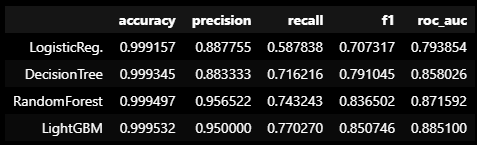
plt.figure(figsize=(10, 6))
sns.boxplot(data=raw_data[['V13', 'V14', 'V15']])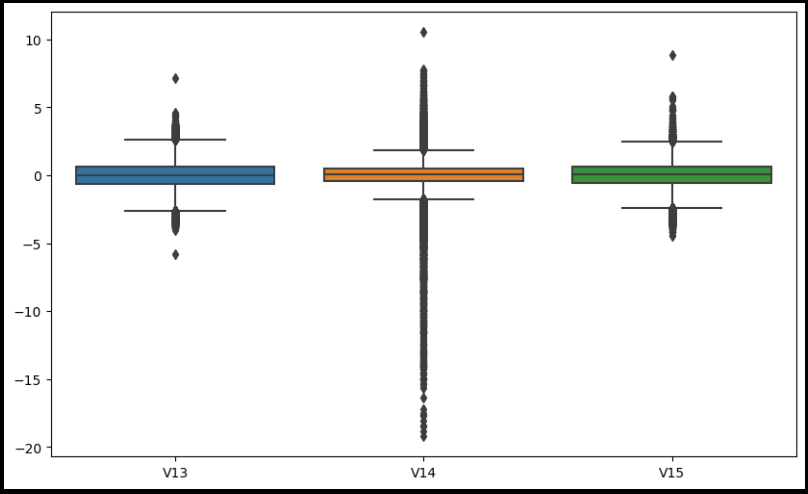
def get_outlier(df=None, column=None, weight=1.5):
fraud = df[df['Class'] == 1][column]
quantile_25 = np.percentile(fraud.values, 25)
quantile_75 = np.percentile(fraud.values, 75)
iqr = quantile_75 - quantile_25
iqr_weight = iqr * weight
lowest_val = quantile_25 - iqr_weight
highest_val = quantile_75 + iqr_weight
outlier_index = fraud[(fraud < lowest_val) | (fraud > highest_val)].index
return outlier_indexX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,
stratify=y,
random_state=13)models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg.', 'DecisionTree', 'RandomForest', 'LightGBM']
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
results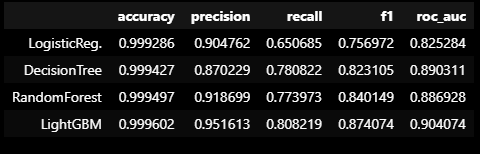
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=13)
X_train_over, y_train_over = smote.fit_resample(X_train, y_train)X_train_over.shape, y_train_over.shape((398040, 29), (398040,))
np.unique(y_train_over, return_counts=True)
np.unique(y_train, return_counts=True)(array([0, 1]), array([199020, 199020]))
(array([0, 1]), array([199020, 342]))
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg.', 'DecisionTree', 'RandomForest', 'LightGBM']
results = get_result_pd(models, model_names, X_train_over, y_train_over, X_test, y_test)
results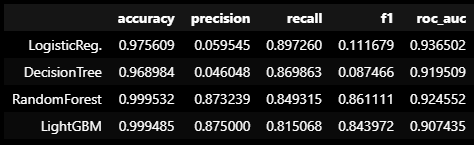
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
