
Chapter 10 데이터 전처리 기법
데이터 전처리(Preprocessing)
- 학습 데이터 또는 테스트 입력을 원하는 형태로 변형하는 기술
-> 입력이 벡터가 아닌 경우, 벡터로 표현하는 방법 (벡터화, 임베딩)
-> 입력의 분포나 범위가 머신 러닝 모델에 적합하지 않은 경우 (정규화, 표준화)
-> 범주형 변수(categorical variable)을 입력으로 사용하고자 하는 경우
-> 통계적인 분석을 방해하는 값을 제거하고 싶은 경우 (이상값 처리)
-> 데이터 측정의 문제나 데이터 손상이 일어난 경우 (결측 데이터 처리) - 그 외, 머신 러닝 알고리즘의 성능을 향상하기 위한 모든 데이터 처리
-> PCA, LDA 등 선형 변환/차원 감소 알고리즘
-> 입력을 분석하여 풍부한 특징(feature)를 추출하는 알고리즘
데이터 정규화(Data Normalization)
- 데이터의 값의 범위를 일정한 범위로 스케일링
-> 정규화한 값은 범위가 [0, 1]으로 제한됨
-> 단, 새로운 입력 샘플은 값의 범위 밖의 값이 될 수도 있음
-> 테스트 데이터가 범위 밖에 있을 경우 부작용을 막기 위해 보통 포화(saturate)시켜 0 또는 1로 값을 고정
-> 정규화한 값은 평균이 0이 되지는 않음(zero-centered가 아님)
-> 특징의 범위가 특정 범위에 있어야 할 때 사용

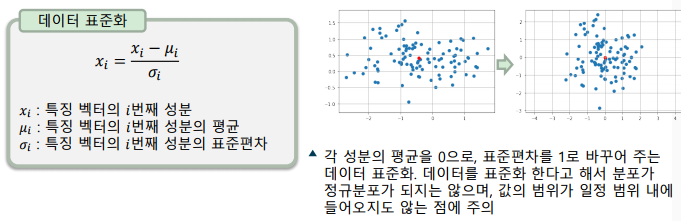
데이터 표준화(Data Standardization)
- 데이터를 정규분포로 가정하고, 표준 정규분포로 변환
-> 표준화한 특징 벡터는 각 성분의 평균이 0, 표준편차가 1이 됨
-> 값은 0-중앙(zero-centered)이 되지만, 값의 범위는 제한되지 않음
-> 주로 평균이 0인 가우시안 분포를 가정하는 입력에 사용
범주형 데이터(Categorical Data)의 전처리
- 범주형 데이터는 보통 더미 변수(dummy variable)로 처리
-> pd.get_dummies() 함수를 이용하면 편리하게 처리 가능
-> 클래스가 지나치가 많은 경우, 일부 클래스는 ‘기타’ 클래스로 처리
-> 동일 클래스가 오타/병행표기 등으로 나누어지지 않았는지 확인
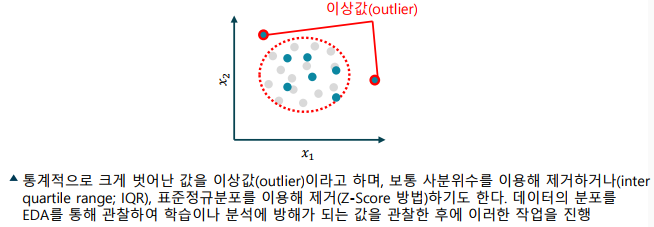
이상값(outlier) 처리
- 확보한 데이터 중 이상값은 머신 러닝에 악영향을 줌
- Garbage In, Garbage Out (GIGO)
- 주로 사분위수(quartile)를 이용하거나, 정규분포를 이용해 제거
- 이상값(outlier): 관측된 데이터의 범위에서 크게 벗어난 아주 작거나 아주 큰 값
결측 데이터 처리
-
결측 데이터는 잉ㄴ지하지 못하면 잠재적으로 버그를 일으킬 수 있음
-
처리 방법
-> Pandas 라이브러리의 isna() 메소드로 결측치 식별
-> 결측 데이터가 포함된 학습 샘플 또는 특징 제거(drop()) -
결측 데이터를 채워넣기(imputation)
-> 전체 대표값(평균, 중앙값 등)으로 대체
-> 그룹 대표값으로 대체
-> 다른 특징 성분으로 추정 (인공신경망, 선형 회귀, SVM 등)하여 대체
-> 구분되는 특별한 값(-1 등)으로 대체
Chapter 11 데이터 불균형 해소
데이터 불균형(Data Imbalance)
- 클래스 간의 학습 데이터의 수가 균형이 맞지 않는 경우
-> 클래스 별로 정률로 분배되어 있는 경우가 가장 좋음
-> 데이터 불균형을 무시하고 학습할 경우, 데이터가 부족한 클래스의 분류 성능이 크게 떨어짐 - 데이터 불균형의 해결 방법
-> 학습 시 손실 함수에 클래스별로 가중치(weight)를 두어서 해결
-> 불균형한 데이터셋을 언더샘플/오버샘플하여 해결
-> 데이터셋을 기반으로 새로운 데이터를 생성하여 해결

데이터 샘플링 기법
-
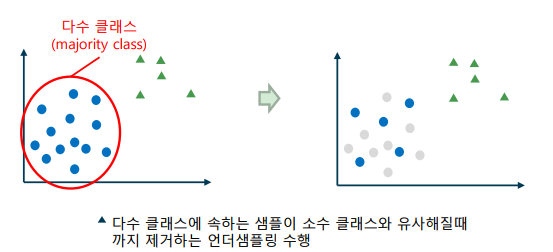
언더샘플링(Undersampling): 다수 클래스에 속하는 샘플을 줄이는 기법
-> 다수 클래스 샘플을 소수 클래스 샘플의 수와 같은 수 만큼만 추출
-> 학습 샘플에 유사한 데이터가 많은 경우 유용하며, 소수 클래스 샘플이 수 만개 이상일 경우 사용
-
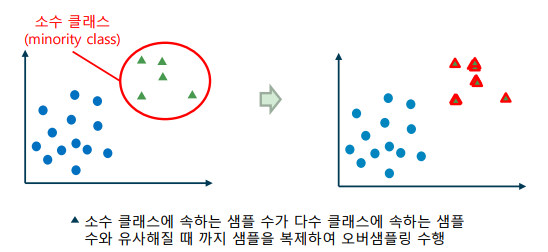
오버샘플링(Oversampling): 소수 클래스에 속하는 샘플을 늘리는 기법
-> 소수 클래스 샘플이 다수 클래스 샘플의 수에 도달할 때 까지 샘플 복제
-> 소수 클래스 샘플의 수가 적을 경우(수백 이하) 유용하며, 샘플 복제 시 특징에 약간의 에러 값을 추가하기도 함
SMOTE(Synthetic Minority Oversampling Technique) 알고리즘
- 기존 데이터를 기반으로 소수 클래스 샘플을 추가 생성하는 알고리즘
- SMOTE 알고리즘
-> 1. 소수 클래스에서 임의의 샘플 𝐱𝑖을 선택한다.
-> 2. 𝐱𝑖 의 k-최근접 이웃을 찾는다.
-> 3. 𝐱_𝑖와 각 이웃 샘플을 연결한 선 위에 있는 임의의 특징을 추가

이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
