
Chapter 3 통계 기초
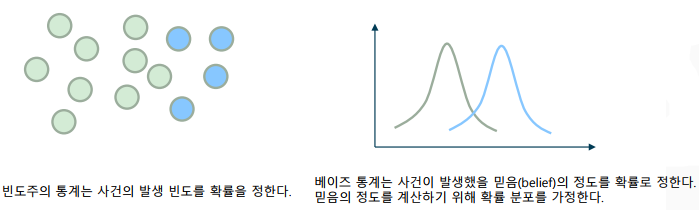
빈도주의 통계와 베이즈 통계
- 빈도주의 통계(frequentist): 실험을 시행했을 때, 전체 횟수에 확률 값을 곱한 숫자만큼 해당 사건이 발생한다고 보는 관점
- 베이지안 통계(Bayesian): 임의의 표본을 하나 선택했을 때, 해당 표본이 해당 사건이라는 주장의 신뢰도를 확률 값으로 보는 관점
베이즈 정리(Bayes' Rule)
- 베이즈 확률(Bayesian probability)을 구하는 방법으로, 종속적인 관계에 있는 사건을 기반으로 확률 계산
-> A라는 사건이 발생할 확률을 이미 알고 있을 때(사전 지식), 이를 이용해 더 적은 추가 정보로 같은 확률을 계산할 수 있음

우도 함수(가능도 함수, Likelihood Function)
- 샘플의 확률 분포를 잘 묘사하는 모델의 매개변수(모수, parameter)를 찾기 위해 사용
-> 확률 분포를 더 잘 묘사할 수록 우도 함수의 값이 큼
-> 모든 샘플에 대한 확률이 동시에 반영되어야 하므로, 각 샘플의 확률의 곱으로 계산

확률 분포의 비교
-
엔트로피(Entropy): 정보 이론에서, 정보량을 측정하는 척도
-> 어떤 확률변수가 가지는 불확실성이 높을 수록, 정보량이 높다: “드물게 일어나는 현상은 가치 있는 정보”라는 의미
-> 반대로, 불확실성이 낮을 수록 정보량이 낮다
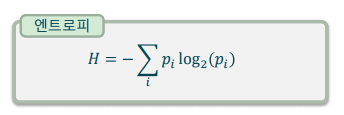
-
교차 엔트로피(Cross Entropy): 두 확률 변수의 교차 정보량을 측정하는 척도
-> 두 확률 변수 간의 확률 분포가 일치할 수록 작아짐
-> 교차 엔트로피를 최소화하면, 두 분포가 일치해 짐
-> 교차 엔트로피는 교환 법칙이 성립하지 않음
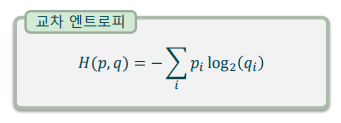
-
쿨백-라이블러 발산(KL Divergence): 두 확률 분포의 거리를 계산하는 척도
-> 상대 엔트로피(relative entropy), 정보 획득량(information gain)이라고도 부름
-> “거리” 개념으로 많이 사용되나, 교환 법칙은 성립하지 않음 cf) Jensen-Shannon divergence

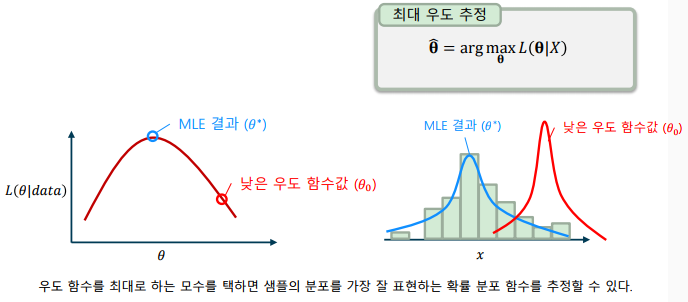
최대 우도 추정(MLE: Maximum Likelihood Estimation)
- 우도 함수가 최대가 되는 모수를 택하는 확률 분포 추정 방법: 특정한 모수를 선택한다는 뜻에서 점 추정이라 함
최대 사후 확률(MAP: Maximum a Posteriori)
- 사후 확률(a posteriori)을 최대로 하는 모수를 찾는 확률 분포 추정 방법
-> 베이즈 정리를 이용하여 MLE와 비교하면, 우도 함수를 사전 확률(a priori)로 보정하는 것과 같음

이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
