Chapter 6 앙상블 기법
앙상블 기법(Ensemble Methods)
-
다양한 모델을 학습한 후 이것을 모아 더 좋은 예측을 얻는 기법
-> 여러 모델의 장단점을 상호 보완적으로 결합하여 사용
-> 약한 학습기(weak learner)를 충분히 많이 결합할 경우 강한 학습기(strong learner)로 동작 -
투표를 이용한 앙상블 기법
-> 과반수 투표(majority voting): 이진 분류에서 50% 이상의 분류기에 의해 선택된 클래스를 출력하는 방법
-> 다수결 투표(plurality voting): 다중 분류에서 다수결로 출력을 결정하는 방법

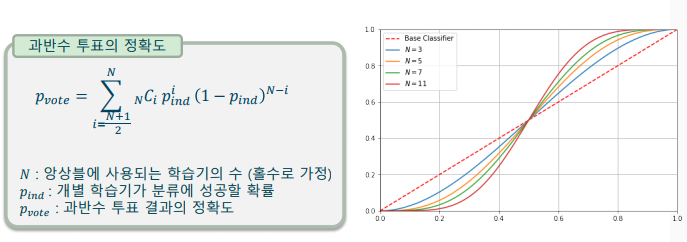
과반수 투표(Majority voting)
- 과반수 투표의 당위성: 개별 학습기와 과반수 투표 학습기의 비교
-> 가정1. 개별 학습기는 서로 독립(independent)이다
-> 가정2. 개별 학습기의 성능은 50%를 넘는다 (50%보다 작은 경우, 출력을 반대로 사용하면 된다)
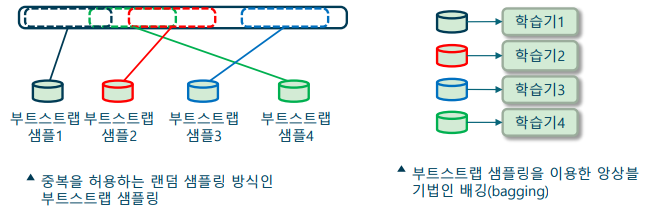
배깅(Bagging)
- 부트스트랩 샘플링을 이용한 동일 모델 학습기의 앙상블 기법
-> 과반수 투표 앙상블 방법에 부트스트랩 샘플링 기법을 추가
-> 부트스트랩(bootstrap) 샘플링: 중복을 허용한 랜덤 샘플 방식
-> Cf) 페이스팅(pasting): 중복을 허용하지 않는 랜덤 샘플 방식
-> 과대적합을 해결하고 보다 학습이 보다 안정적으로 이루어짐
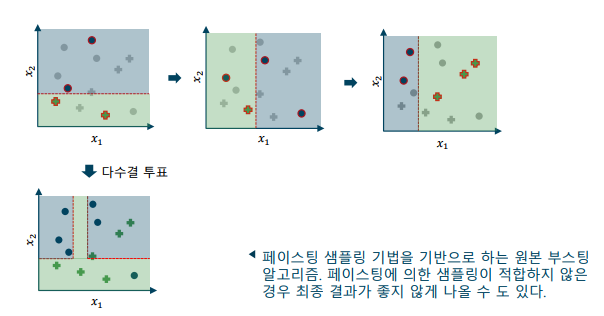
-> 실제 샘플링 시에는 몰려 있는 데이터가 아닌 섞어서 골고루 가져와야 함(편향되지 않은 데이터)
랜덤포레스트(Random Forest)
-
의사결정나무를 앙상블하는 잘 알려진 방법
-> 여러 개의 의사결정트리를 평균하는 방법을 사용
-> 일반화 성능을 높여 쉽게 과대적합이 일어나는 것을 방지
-> 배깅과 유사하나, 중복없이 특성을 나누어 학습하는 특징 -
학습 방법
-> 학습 단계
--> 1. 부트스트랩 샘플을 추출(중복을 허용하여 𝑛개 샘플링)
--> 2. 중복 없이 𝑑개의 특성을 선택하여 의사결정나무를 학습
--> 3. 1~2단계를 𝑘번 반복
-> 테스트 단계
--> 모든 의사결정나무를 모아서 다수결 투표로 타겟 예측
부스팅(Boosting)
-
부스팅 알고리즘
-> 여러 개의 약한 학습기를 조합하여 강한 학습기 구성
-> 약한 학습기(weak learner): 랜덤 추측보다 조금 성능이 좋은 수준의 매우 성능이 낮은 알고리즘(ex. 깊이가 1인 의사결정나무) -
학습 방법
-> 학습 단계
--> 1. 페이스팅(중복을 허용하지 않는 방법)으로 학습 데이터 개 뽑아 약한 학습기 학습
--> 2. 페이스팅으로 학습 데이터 개에 에서 잘못 분류한 샘플 50%를 추가해 약한 학습기 학습
--> 3. 과 가 잘못 분류한 샘플을 찾아 약한 학습기 학습
-> 테스트 단계
--> 약한 학습기 를 모아 다수결 투표로 타겟 예측
어댑티브 부스팅(AdaBoost: Adaptive boosting)
-
약분류기(weak classifier)를 결합하는 강력한 앙상블 방법
-> 이전 약분류기가 실패하는 샘플에 더 많은 중요성을 두고 반복적으로 약분류기(ex. 깊이가 1인 결정 트리)
-> 각 약분류기는 정확도에 따라 가중치(alpha)가 할당되며, 정확한 분류기일수록 높은 가중치 할당
-> 최종 강분류기(strong classifier)는 이러한 약분류기의 가중치가 적용된 합으로, 이를 통해 예측 성능 향상 -
학습
-> 1. 데이터 가중치 초기화: 학습 데이터셋의 모든 샘플에 동일한 가중치를 할당
-> 2. 약분류기 학습: 가중치가 적용된 데이터셋에서 약분류기를 학습하고 정확도를 계산
-> 3. 분류기 가중치 계산: 약분류기의 정확도에 따라 가중치(alpha) 계산
-> 4. 데이터 샘플 가중치 업데이트: 오분류된 샘플의 가중치를 증가시키고 전체 데이터 세트에 대한 가중치를 정규화
-> 5. 단계2-4 반복: 약분류기를 새로 학습하고, alpha와 샘플 가중치 업데이트
-> 6. 약한 분류기 결합: 약분류기의 결정에 가중치를 적용하여 최종 강분류기를 구성
그라디언트 부스팅(Gradient Boosting)
-
머신 러닝에서 명실상부 최고의 성능을 보여주고 있는 알고리즘
-> 순차적으로 훈련되는 약한 모델들을 결합하여 더 강력한 모델을 생성하는 앙상블 학습 방법
-> 이전 모델의 오차에 대한 그래디언트(경사)를 최소화하는 방향으로 새로운 약한 모델을 학습
-> 최종 강한 모델은 약한 모델들의 합으로 구성되며, 이를 통해 예측 성능이 향상 -
학습
-> 1. 기본 모델 설정: 초기 모델로 평균값이나 중앙값 등의 간단한 예측을 사용
-> 2. 잔차 계산: 현재 모델의 예측과 실제 값 사이의 차이(잔차)를 계산
-> 3. 약한 모델 학습: 잔차에 대한 새로운 약한 모델(예: 결정 트리)를 학습
-> 4. 모델 가중치 결합: 학습된 약한 모델의 가중치를 현재 모델에 추가
-> 5. 단계 2-4 반복: 오차를 최소화하는 방향으로 추가적인 약한 모델들을 순차적으로 훈련
-> 6. 최종 모델 생성: 모든 약한 모델들의 가중치가 적용된 합으로 최종 강력한 모델을 형성
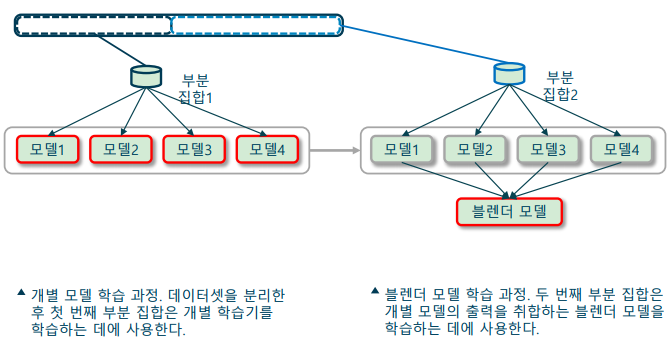
스태킹(Stacking)
-
다수결 투표대신, 블렌더(blender) 모델을 학습하는 앙상블 방법
-> 블렌더: 모델의 출력을 취합하여 하나의 출력을 생성하는 모델
-> 학습 데이터를 두 부분 집합으로 나누어 학습 수행
--> 부분 집합1: 앙상블하고자 하는 𝑁개의 모델 학습 (레이어1)
--> 부분 집합2: 1개의 블렌더 모델 학습 (레이어2) -
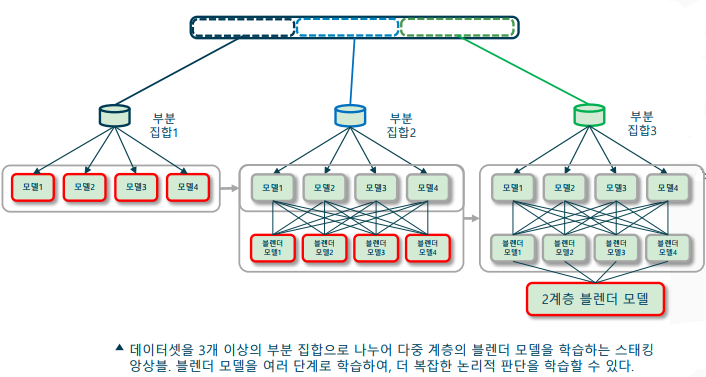
다중 계층 스태킹 앙상블(multi-layer stacking ensemble)
-> 학습 데이터를 세 부분으로 나누어 학습 수행
--> 부분 집합1: 앙상블하고자 하는 𝑁개의 모델 학습 (레이어1)
--> 부분 집합2: 𝑀개의 블렌더 모델 학습 (레이어2)
--> 부분 집합3: 1개의 블렌더 모델 학습 (레이어3) -
스태킹 앙상블 기법
-
다중 계층 스태킹 앙상블
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
