Chapter 8 군집화 기법
군집화 기법(Clustering)
- 대표적인 비지도 학습 방법으로, 데이터셋의 구조를 파악하는 기법
-> 학습 데이터셋에서 유사한 특징끼리 군집(cluster)를 구성
-> 군집: 특정 기준으로 묶여진 특징. 자동 레이블이라고도 부름
-> 대표적으로 k-평균 군집화(k-means clustering)와 계층적 군집화(hierarchical clustering) 기법이 있음

k-평균 군집화(k-Means Clustering)
- 주어진 데이터를 k개의 군집으로 묶는 알고리즘
- 각 군집 내 거리 차이의 분산을 최소화하는 방식으로 동작
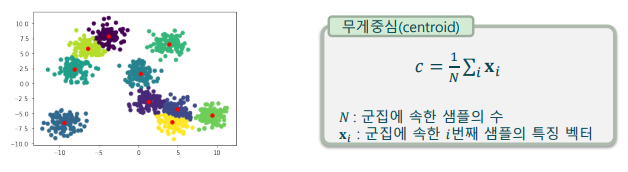
- 군집 설정과 군집 중심 재조정의 반복으로 구현
-> 1) 군집 중심과 가까운 거리로 데이터에 군집을 배당
-> 2) 앞에서 배당된 군집을 기준으로 무게중심(centroid)을 계산
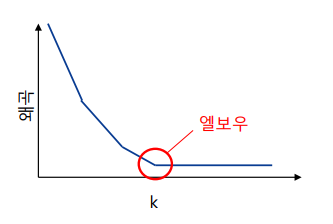
k값의 결정
-
엘보우 방법(elbow method): 클래스 내 SSE를 그래프로 나타낸 후, SSE 값이 더 이상 크게 감소하지 않는 k를 선택한느 방법
-> SSE = 왜곡(distortion) = 관성(inertia)
-
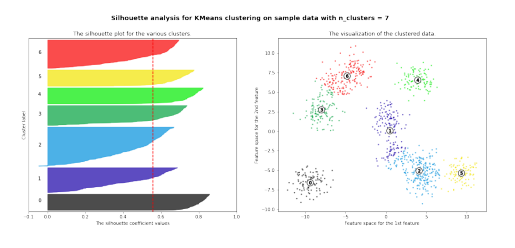
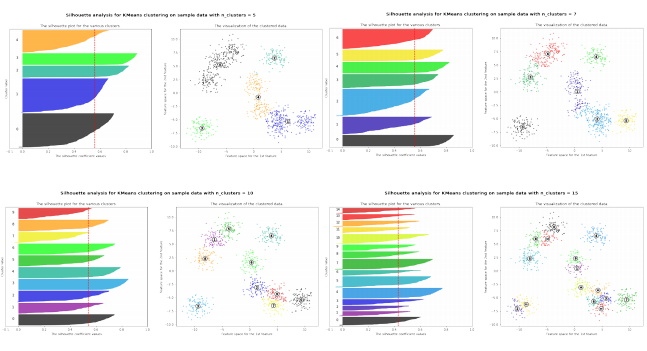
실루엣 방법(silhouette method)
-> 클러스터 내에 샘플이 얼만큼 밀집(dense)해 있는지 측정
-> 각 샘플의 실루엣 계수가 클수록(1에 가까울수록) 더 좋은 군집으로 해석
-
실루엣 방법의 구현
계층적 군집화(Hierarchical Clustering)
-
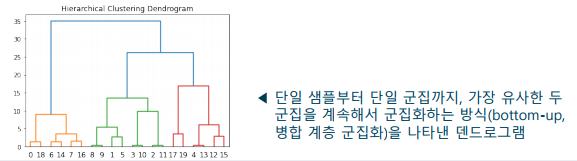
계층적인 트리를 이용한 군집화 기법으로, 군집의 개수를 미리 정할 필요가 없음
-> 병합 계층 군집화(agglomerative clustering): 상향식(bottom-up)으로 유사한 샘플을 묶어 나가는 방법
-> 분할 계층 군집화(divisive clustering): 전체를 하나의 군집으로 시작하여, 모든 샘플이 나뉠 때 까지 나누어 가는 방법 -
덴드로그램(dendrogram)으로 시각화에 유리
-
병합 계층 군집화(Agglomerative Clustering): 개별 샘플부터 가장 가까운 두 군집을 계속 합쳐 나가는 방법
-
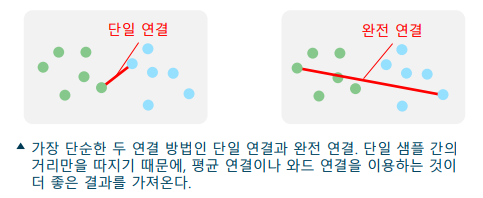
계층적 군집화의 군집 결합 방식
-> 단일 연결(single linkage): 군집 내 가장 비슷한 샘플 간의 거리 비교
-> 완전 연결(complete linkage): 군집 내 가장 먼 샘플 간의 거리 비교
-> 평균 연결(average linkage): 모든 샘플 사이의 거리의 평균 비교
-> 와드 연결(Ward’s linkage): 군집 결합 시, 군집 내 SSE 증가량 비교
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
