- 고차원 데이터 분석에서 PCA(주성분 분석) 는 가장 많이 쓰이는 차원 축소 기법.
- 하지만 비선형 데이터에는 한계가 있음.
- 이를 해결하는 방법이 Kernel PCA.
PCA vs. Kernel PCA
| PCA | Kernel PCA | |
|---|---|---|
| 데이터 유형 | 선형 | 비선형 가능 |
| 변환 방식 | 데이터 자체 변환 | 커널 함수를 사용해 고차원으로 변환 |
| 커널 사용 | ❌ | ✅ |
| 주요 활용 | 얼굴 인식, 이미지 압축 | 복잡한 데이터 구조 분석 |
PCA는 직선적인 구조에서 강력, Kernel PCA는 비선형 패턴까지 반영 가능
Kernel PCA 핵심 개념
- 커널 함수를 사용해 데이터를 고차원 공간으로 매핑
- PCA를 적용해 주요한 주성분 찾기
- 차원 축소 후 다시 저차원 공간으로 투영
- PCA는 데이터 분산을 최대로 하는 방향을 찾음.
- Kernel PCA는 비선형 관계까지 고려해 데이터 변환 가능.
주요 커널 함수
- RBF (가우시안 커널) – 비선형 데이터에 가장 많이 사용됨
- 다항식 커널 – 차수가 높아질수록 복잡한 패턴 반영
- 시그모이드 커널 – 신경망과 유사한 방식으로 데이터 변환
코드와 출력을 아래와 같이 수정해서 Velog 스타일로 정리해줄게.
Kernel PCA 적용 – 코드 예제
와인 데이터셋을 활용해 Kernel PCA를 적용하고 시각화 진행
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.decomposition import KernelPCA
import pandas as pd
import matplotlib.pyplot as plt
# 데이터 불러오기
raw_wine = datasets.load_wine()
X = raw_wine.data
y = raw_wine.target
# 훈련 / 테스트 데이터 분리
X_tn, X_te, y_tn, y_te = train_test_split(X, y, random_state=42)
# 표준화 적용
std_scale = StandardScaler()
X_tn_std = std_scale.fit_transform(X_tn)
X_te_std = std_scale.transform(X_te)
# Kernel PCA 적용 (다항식 커널 사용)
k_pca = KernelPCA(n_components=2, kernel='poly')
X_tn_kpca = k_pca.fit_transform(X_tn_std)
X_te_kpca = k_pca.transform(X_te_std)
# 변환 후 데이터프레임 생성
kpca_columns = ['kernel_pca_component1', 'kernel_pca_component2']
X_tn_kpca_df = pd.DataFrame(X_tn_kpca, columns=kpca_columns)
X_tn_kpca_df['target'] = y_tn
# 시각화
df = X_tn_kpca_df
markers = ['o', 'x', '^']
for i, mark in enumerate(markers):
X_i = df[df['target'] == i]
target_i = raw_wine.target_names[i]
plt.scatter(X_i['kernel_pca_component1'], X_i['kernel_pca_component2'], marker=mark, label=target_i)
plt.xlabel('kernel_pca_component1')
plt.ylabel('kernel_pca_component2')
plt.legend()
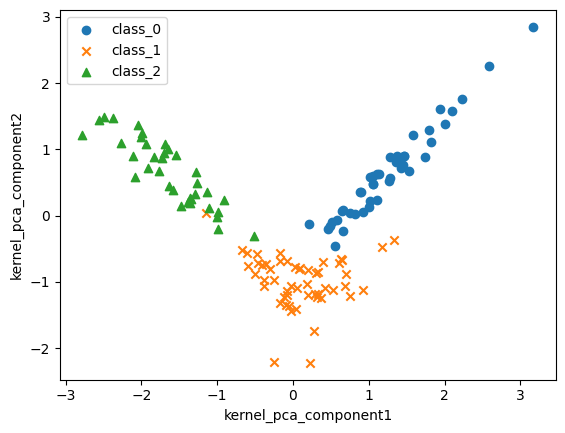
plt.show()결과
데이터 차원 변화
print(X_tn_std.shape) # (133, 13)
print(X_tn_kpca.shape) # (133, 2)13차원 → 2차원으로 축소됨
Kernel PCA 고유값 & 고유벡터
print(k_pca.eigenvalues_)[202.323155 121.59022936]가장 큰 두 개의 고유값 (데이터의 주요 방향 결정)
print(k_pca.eigenvectors_[:5]) # 일부 출력[[ 0.08989868 0.05214949]
[ 0.02198097 -0.11073412]
[-0.02172117 -0.07290967]
[-0.09518993 0.02404459]
[ 0.10222186 0.06959563]]고유벡터를 통해 데이터가 변환되는 방향 확인
차원 축소 후 데이터 일부 확인
print(X_tn_kpca_df.head(5)) kernel_pca_component1 kernel_pca_component2 target
0 0.312658 -1.221043 1
1 -0.308963 -0.803960 1
2 -1.353985 0.265135 2
3 1.454007 0.767417 0
4 -0.950987 -0.415690 1각 데이터가 새로운 2차원 공간에서 어떻게 분포하는지 확인 가능
최종 시각화
Kernel PCA 적용 후 와인 데이터셋의 3개 클래스가 명확히 구분됨
다항식 커널을 적용하여 비선형 구조도 잘 반영됨
학습
- Kernel PCA를 적용한 후 Random Forest 분류기 학습 및 평가
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 학습
clf_rf_kpca = RandomForestClassifier(max_depth=2, random_state=0)
clf_rf_kpca.fit(X_tn_kpca, y_tn)
# 예측
pred_rf_kpca = clf_rf_kpca.predict(X_te_kpca)
# Kernel PCA 적용 후 정확도
accuracy_kpca = accuracy_score(y_te, pred_rf_kpca)
print(accuracy_kpca)
out: 0.9777777777777777
언제 Kernel PCA를 써야 할까?
- 데이터가 선형적으로 분리되지 않을 때
- PCA를 적용해도 패턴이 명확하지 않을 때
- 차원 축소 후에도 복잡한 구조가 남아 있을 때
PCA만으로 부족할 때 Kernel PCA 고려!
결론
- PCA는 선형 구조 분석에 강함
- Kernel PCA는 비선형 데이터에도 효과적
- 커널 함수를 사용해 더 복잡한 데이터 구조 분석 가능
- 머신러닝 전처리, 이미지 처리, 이상 탐지 등 다양한 분야에서 활용

gpt로 다시 배우는 개발