1. 알고리즘 특징
| 알고리즘 | 원리 | 장점 | 단점 | 언제 사용하면 좋은가? |
|---|---|---|---|---|
| K-Means | k개의 중심점을 설정하고, 가장 가까운 중심점으로 데이터들을 군집화. 이후 중심점을 업데이트하며 반복 | 계산 속도가 빠르고 대용량 데이터에 적합 | 클러스터 개수(k)를 미리 정해야 하며, 비선형 구조 데이터에는 부적합 | 클러스터가 원형(구형) 구조이고, 데이터가 균등하게 분포할 때 |
| K-Medoids | K-Means와 유사하지만, 중심점을 데이터 중에서 선택 | 이상치(Outlier)에 강하고, 안정적인 군집화 | K-Means보다 계산량이 많아 속도가 느림 | 이상치가 많은 데이터셋에서 K-Means보다 더 나은 성능을 원할 때 |
| Mean Shift | 데이터의 밀도가 높은 방향으로 이동하며 클러스터 중심을 찾음 | 클러스터 개수를 자동으로 결정 | 대용량 데이터에서는 느리고, 결과가 항상 명확하지 않을 수 있음 | 데이터 밀도가 중요한 경우, 군집 개수를 미리 모를 때 |
| Agglomerative Clustering | 각 데이터를 개별 클러스터로 시작해 가까운 것끼리 병합(병합 계층적 군집) | 클러스터 개수를 미리 몰라도 트리를 활용해 분석 가능 | 대규모 데이터에서 속도가 느리고, 이상치에 민감 | 클러스터 구조를 계층적으로 분석할 때 |
| Gaussian Mixture Model (GMM) | 데이터를 여러 개의 가우시안 분포로 가정하고 확률적으로 군집화 | K-Means보다 유연하며, 클러스터가 타원형일 때 더 잘 작동 | 계산량이 많고, 클러스터 개수를 미리 지정해야 함 | 데이터가 여러 개의 가우시안 분포를 따를 때 |
| DBSCAN | 밀도가 높은 지역을 클러스터로 정의하고, 밀도가 낮은 지역은 노이즈로 간주 | 클러스터 개수를 몰라도 되고, 이상치 감지가 가능 | 밀도 설정(eps, min_samples)에 따라 성능이 좌우됨 | 이상치가 많고 클러스터 크기가 일정하지 않은 경우 |
| Spectral Clustering | 데이터의 유사성을 그래프로 변환하여 군집화 | 비선형 데이터 구조를 잘 분류 | 대규모 데이터에는 속도가 느림 | 그래프 기반으로 군집화가 필요한 경우 (ex: 소셜 네트워크) |
| OPTICS | DBSCAN과 유사하지만, 밀도 변화에 따라 더 유연하게 클러스터를 형성 | 다양한 밀도 구조에서 좋은 성능 | 해석이 어렵고, DBSCAN보다 속도가 느림 | 클러스터의 밀도가 다르고, 노이즈 처리가 중요한 경우 |
- K-Means: 미리 정한 개수의 클러스터 중심을 찾고 군집화 수행.
- K-Medoids: K-Means와 유사하지만 중심을 실제 데이터 포인트에서 선택.
- Mean-Shift: 밀도가 높은 방향으로 이동하여 중심 찾음, 클러스터 개수 자동 결정.
- Agglomerative Clustering: 계층적 군집화로 가까운 데이터부터 병합.
- Gaussian Mixture Model (GMM): 데이터를 여러 개의 가우시안 분포로 혼합하여 군집화.
- DBSCAN: 밀도 기반 군집화, 이상치(노이즈) 감지 가능.
- Spectral Clustering: 그래프 기반 군집화, 복잡한 데이터 구조에서 효과적.
- OPTICS: DBSCAN 개선 버전, 다양한 밀도 분포의 데이터에 대응.
- Random Assignment: 무작위 클러스터 할당, 비교 기준용.
2. 코드 설명
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.cluster import MeanShift, OPTICS, DBSCAN, AgglomerativeClustering, SpectralClustering, KMeans
from sklearn_extra.cluster import KMedoids
from sklearn.mixture import GaussianMixture
from sklearn.metrics import adjusted_rand_score
from sklearn.preprocessing import StandardScaler- 필수 라이브러리 및 알고리즘 불러오기
X, y = make_moons(n_samples=200, noise=0.05, random_state=42)
X_scaled = StandardScaler().fit_transform(X)- 반달 모양 데이터셋 생성 및 표준화(Standardization)
algorithms = {
'Random Assignment' : None,
'Kmeans' : KMeans(n_clusters=2, random_state=42),
'KMedoids' : KMedoids(n_clusters=2, random_state=42),
'MeanShift' : MeanShift(bandwidth=0.6),
'Agglomerative Clustering' : AgglomerativeClustering(n_clusters=2),
'Gaussian Mixture Model' : GaussianMixture(n_components=2, random_state=42),
'DBSCAN' : DBSCAN(eps=0.3, min_samples=5),
'Spectral Clustering' : SpectralClustering(n_clusters=2, affinity='nearest_neighbors'),
'OPTICS' : OPTICS(min_samples=5, xi=0.05, min_cluster_size=0.05)
}여러 클러스터링 알고리즘 정의
fig, axes = plt.subplots(2, 5, figsize=(20,10))
axes = axes.ravel()2x5 서브플롯 생성
for ax, (name, algorithm) in zip(axes, algorithms.items()):
if name == 'Gaussian Mixture Model':
clusters = algorithm.fit(X_scaled).predict(X_scaled)
elif name == 'Random Assignment':
clusters = np.random.RandomState(seed=42).randint(0, 2, size=len(X_scaled))
else:
clusters = algorithm.fit_predict(X_scaled)알고리즘 실행 및 군집 결과 저장
ari = adjusted_rand_score(y, clusters)
scatter = ax.scatter(X_scaled[:,0], X_scaled[:,1], c=clusters, cmap='viridis', edgecolor='k', s=60)
if name in ['DBSCAN', 'OPTICS']:
ax.scatter(X_scaled[clusters == -1, 0], X_scaled[clusters == -1, 1], c='red', marker='x', s=100, label='Noise')
ax.legend()
ax.set_title(f'{name}\n ARI : {ari:.2f}')
ax.set_xticks([])
ax.set_yticks([])
ax.grid(True)
- ARI(Adjusted Rand Index) 계산 후 결과 시각화
- DBSCAN, OPTICS의 노이즈 포인트는 빨간색 X로 표시
plt.tight_layout()
plt.show()플롯 조정 및 출력
out :
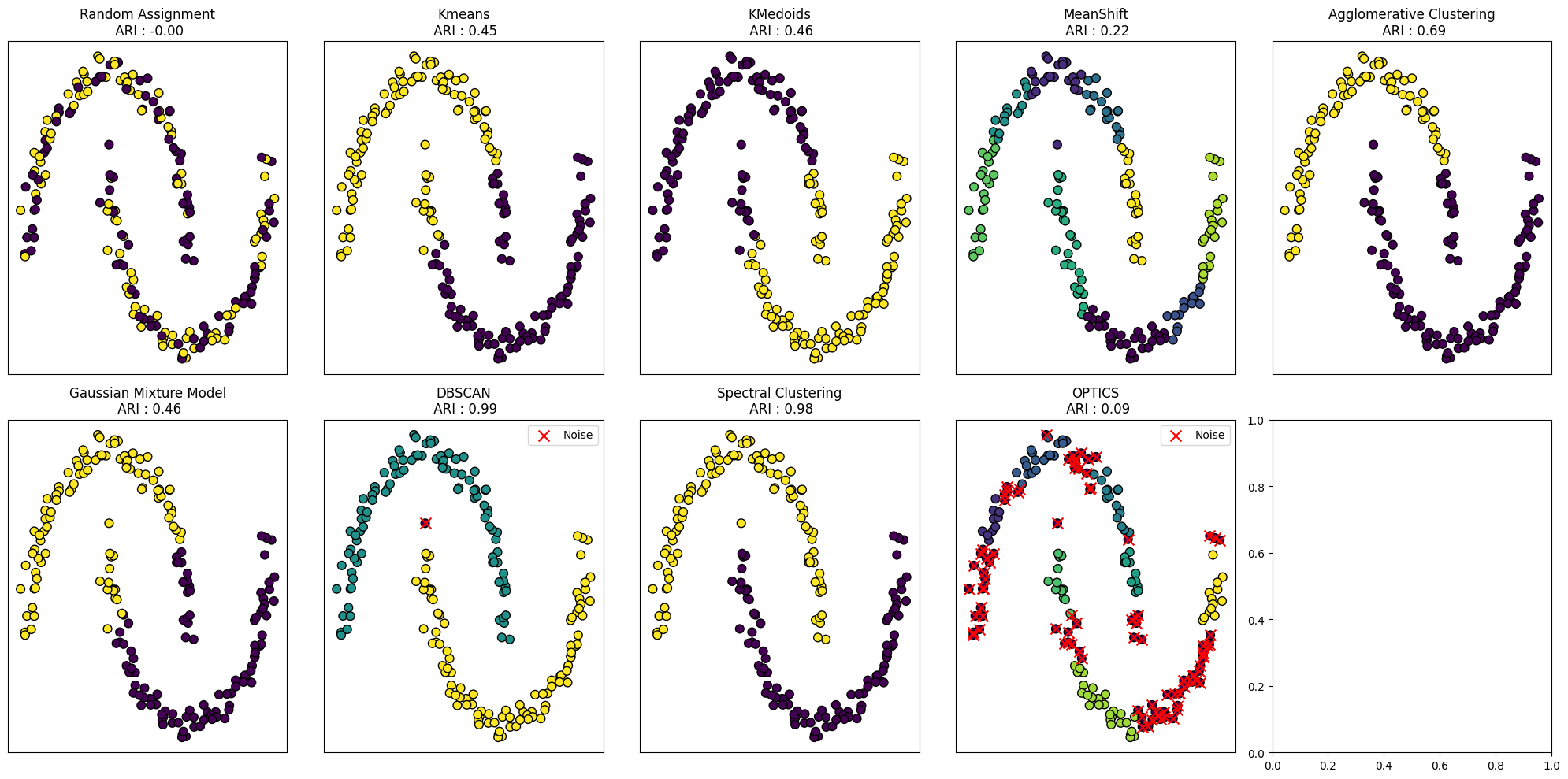
3. 실행 결과 해석
- KMeans, KMedoids: 선형 경계를 형성하여 성능이 낮음 (ARI ≈ 0.45)
- MeanShift: 클러스터 개수 자동 설정, 하지만 불완전한 군집화 (ARI ≈ 0.22)
- Agglomerative Clustering: 비교적 좋은 성능 (ARI ≈ 0.69)
- Gaussian Mixture Model: 혼합 분포 모델 적용, KMeans와 유사 (ARI ≈ 0.46)
- DBSCAN: 이상치(노이즈) 감지, 데이터 구조에 적합 (ARI ≈ 0.99)
- Spectral Clustering: 그래프 기반 접근 방식으로 높은 성능 (ARI ≈ 0.98)
- OPTICS: 밀도 기반 군집화지만 설정값에 따라 성능 변화 (ARI ≈ 0.09)
- Random Assignment: 무작위 배정으로 성능 없음 (ARI ≈ 0.00)
4. 결론
- DBSCAN, Spectral Clustering이 반달형 데이터에서는 가장 성능이 우수.
- OPTICS는 데이터 밀도에 따라 다르게 작동, 설정값 최적화 필요.
- K-Means, K-Medoids는 원형 클러스터에는 적합하지만, 비선형 구조에서는 성능 저하.
- MeanShift, GMM은 비효율적이며, 밀도 기반 알고리즘이 더 적합함.

gpt로 다시 배우는 개발